

Transformer는 의심할 여지 없이 지난 몇 년간 기계 학습 분야에서 가장 인기 있는 모델입니다.
2017년 "Attention is All You Need" 논문에서 제안된 이후, 이 새로운 네트워크 구조는 주요 번역 작업에서 폭발적으로 증가하며 많은 새로운 기록을 만들어냈습니다.
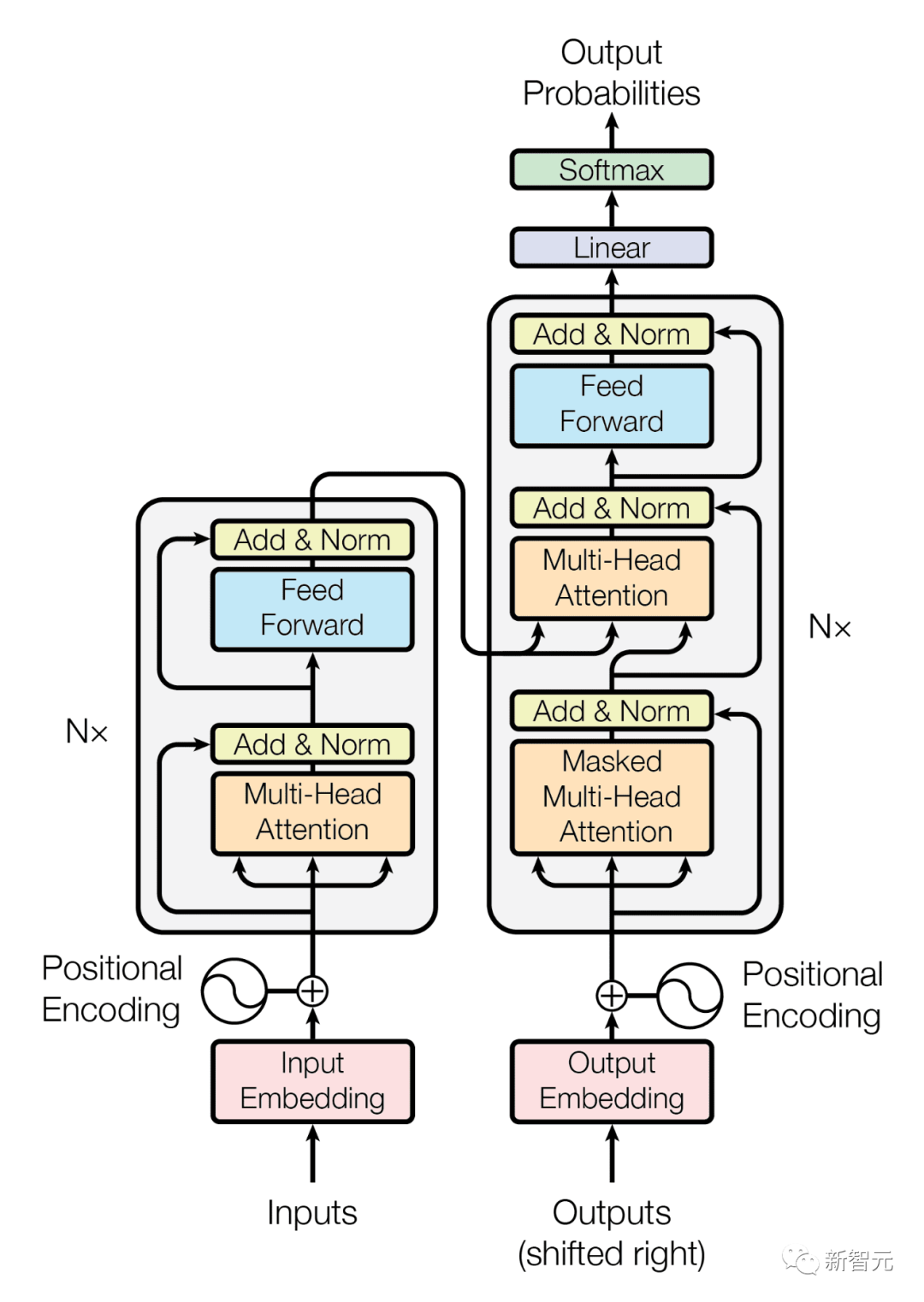
그러나 Transformer에는 긴 바이트 시퀀스를 처리할 때 결함, 즉 심각한 컴퓨팅 성능 손실이 있는데, Meta 연구진의 최신 결과는 이 결함을 잘 해결할 수 있습니다.
그들은 다양한 형식에 걸쳐 1백만 개 이상의 토큰을 생성할 수 있고 GPT-4와 같은 모델 뒤에 있는 기존 Transformer 아키텍처의 기능을 능가할 수 있는 새로운 모델 아키텍처를 출시했습니다.
이 모델은 "Megabyte"라고 불리며, 100만 바이트 이상의 시퀀스에 대해 종단 간 차별화를 수행할 수 있는 다중 규모 디코더 아키텍처입니다.

문서 링크: https://arxiv.org/abs/2305.07185
왜 Megabyte가 Transformer보다 나은가요? 먼저 Transformer의 단점을 살펴보아야 합니다.
지금까지 OpenAI의 GPT-4, Google의 Bard 등 여러 종류의 고성능 생성 AI 모델은 모두 Transformer 아키텍처를 기반으로 한 모델입니다.
그러나 Meta의 연구팀은 인기 있는 Transformer 아키텍처가 한계점에 도달했다고 믿습니다. 주된 이유는 Transformer 설계에 내재된 두 가지 중요한 결함 때문입니다.
- 입력 및 출력 바이트 길이가 증가함에 따라 비용이 증가합니다. 입력 음악, 이미지 또는 비디오 파일과 같이 self-attention도 빠르게 증가합니다. 일반적으로 수 메가바이트를 포함하지만 대규모 디코더(LLM)는 일반적으로 수천 개의 컨텍스트 태그만 사용합니다.
- 일련의 수학을 통한 피드포워드 네트워크 연산 및 변환은 언어 모델이 단어를 이해하고 처리하는 데 도움이 되지만, 위치별로 확장성을 달성하기는 어렵습니다. 이러한 네트워크는 문자 그룹이나 위치에서 독립적으로 작동하므로 계산 오버헤드가 커집니다. Transformer와 비교할 때 Megabyte 모델은 입력 및 출력 시퀀스를 개별 토큰이 아닌 패치로 나누는 독특하고 다른 아키텍처를 보여줍니다.
아래와 같이 각 패치에서 로컬 AI 모델이 결과를 생성하고, 글로벌 모델이 모든 패치의 최종 출력을 관리하고 조정합니다.
먼저, 바이트 시퀀스는 대략 토큰과 유사한 고정 크기 패치로 구분됩니다.
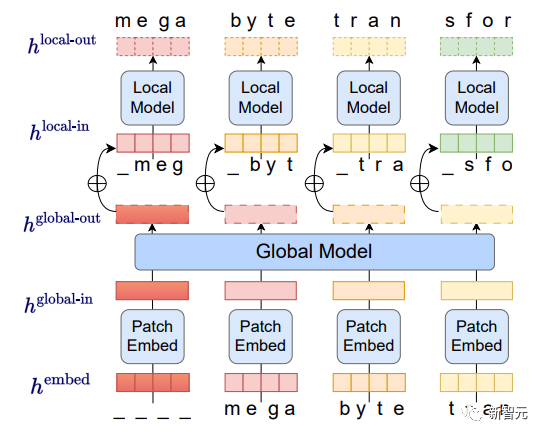
(1) 패치 임베더: 무손실 연결 각 바이트 임베딩. 간단히 패치를 인코딩하기
(2) 글로벌 모델: 입력 및 출력 패치로 표현되는 대규모 자동 회귀 변환기(3) 로컬 모델: 패치에서 예측된 단어 연구원들은 바이트 예측을 관찰했습니다. 대부분의 작업(예: 처음 몇 글자가 주어진 단어 완성)에서 상대적으로 쉽습니다. 즉, 바이트당 큰 네트워크가 필요하지 않으며 내부 예측에 더 작은 모델을 사용할 수 있습니다.
이 접근 방식은 오늘날의 AI 모델에서 널리 퍼져 있는 확장성 문제를 해결합니다. Megabyte 모델의 패치 시스템을 사용하면 여러 토큰이 포함된 패치에서 단일 피드포워드 네트워크를 실행할 수 있어 셀프 어텐션 스케일링 문제를 효과적으로 해결할 수 있습니다.
그 중 Megabyte 아키텍처는 긴 시퀀스 모델링을 위해 Transformer에 세 가지 주요 개선 사항을 적용했습니다. self-attention의 2차 비용인 반면 Megabyte는 긴 시퀀스를 두 개의 짧은 시퀀스로 분해하는데, 이는 긴 시퀀스의 경우에도 여전히 다루기 쉽습니다.
- 패치 피드포워드 레이어(Per-patch Feedforward 레이어)
GPT-3 크기 모델에서는 FLOPS의 98% 이상이 위치 피드포워드 레이어를 계산하는 데 사용되며 Megabyte는 패치 레이어당 큰 피드포워드를 사용하여 동일한 비용으로 더 크고 성능이 뛰어난 모델을 얻을 수 있습니다. 패치 크기가 P인 경우 기본 변환기는 m개의 매개변수가 있는 동일한 피드포워드 레이어를 P번 사용하고 Megabyte는 동일한 비용으로 mP 매개변수가 있는 레이어를 한 번 사용할 수 있습니다.
- 디코딩의 병렬성
각 시간 단계의 입력은 이전 시간 단계의 출력이고 패치는 병렬로 생성되기 때문에 Transformer는 생성 중에 모든 계산을 직렬로 수행해야 합니다. 메가바이트는 더 큰 계산을 허용한다고 말했습니다. 빌드 프로세스의 병렬성.
예를 들어, 1.5B 매개변수가 있는 메가바이트 모델은 표준 350MTransformer보다 40% 더 빠르게 시퀀스를 생성하는 동시에 동일한 양의 계산을 사용하여 훈련할 때 복잡성을 개선합니다.
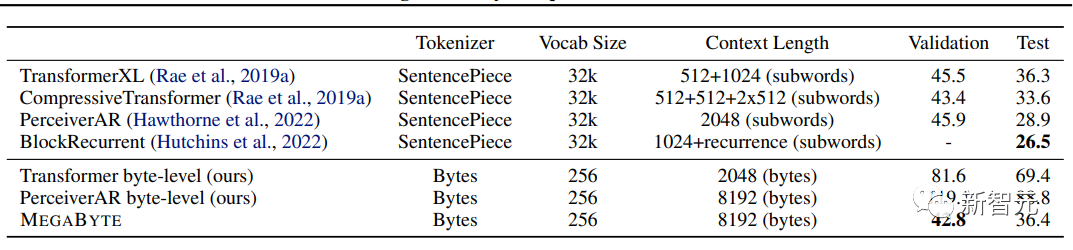
Megabyte는 다른 모델보다 훨씬 뛰어난 성능을 발휘하며 하위 단어로 훈련된 sota 모델과 경쟁력 있는 결과를 제공합니다.
이에 비해 OpenAI의 GPT-4는 32,000개의 토큰 제한이 있고 Anthropic의 Claude는 100,000개의 토큰 제한이 있습니다.
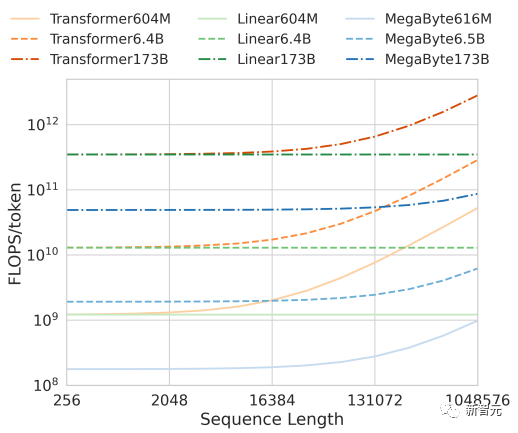
또한 계산 효율성 측면에서 고정된 모델 크기 및 시퀀스 길이 범위 내에서 Megabyte는 동일한 크기의 Transformer 및 Linear Transformer보다 적은 토큰을 사용하므로 동일한 계산 비용으로 더 큰 모델을 사용할 수 있습니다.
이러한 개선 사항을 통해 동일한 컴퓨팅 예산으로 더 크고 성능이 뛰어난 모델을 교육하고 매우 긴 시퀀스로 확장하며 배포 중에 빌드 속도를 높일 수 있습니다.
미래에는 무슨 일이 일어날까요AI 군비 경쟁이 본격화되면서 모델 성능은 점점 더 강해지고 매개변수도 점점 높아지고 있습니다.
GPT-3.5는 175B 매개변수로 훈련되었지만 일부에서는 더 강력한 GPT-4가 1조 개의 매개변수로 훈련되었다고 추측합니다.
OpenAI CEO인 Sam Altman도 최근 전략 변경을 제안했습니다. 그는 회사가 거대 모델의 훈련을 포기하고 다른 성능 최적화에 집중하는 것을 고려하고 있다고 말했습니다.
그는 AI 모델의 미래를 iPhone 칩과 동일시하지만 대부분의 소비자는 원래 기술 사양에 대해 전혀 모릅니다.
Meta 연구자들은 혁신적인 아키텍처가 적절한 시기에 나온다고 믿지만, 최적화할 수 있는 다른 방법도 있음을 인정합니다.
예를 들어 패칭 기술을 사용하는 보다 효율적인 인코더 모델, 시퀀스를 더 작은 블록으로 분해하고 시퀀스를 압축된 토큰으로 전처리하는 디코딩 모델 등이 있으며 기존 Transformer 아키텍처의 기능을 다음으로 확장할 수 있습니다. 새로운 세대의 모델을 구축하십시오.
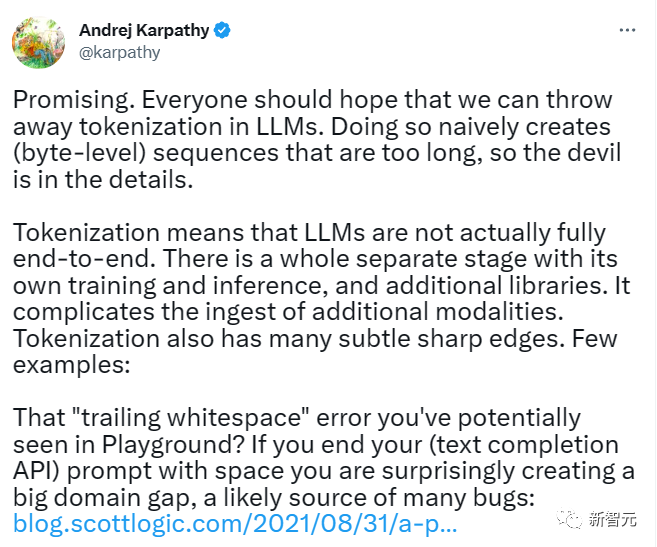
전 Tesla AI 디렉터인 Andrej Karpathy도 트위터에 다음과 같이 글을 써서 이 논문에 무게를 두었습니다.
이것은 매우 유망하며 모든 사람들은 대규모 모델에서 토큰화를 버리고 지나치게 긴 바이트 시퀀스의 필요성을 제거할 수 있기를 바라고 있습니다.
위 내용은 트랜스포머보다 40% 빠르다! Meta, 컴퓨팅 전력 손실 문제를 해결하기 위해 새로운 Megabyte 모델 출시의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!






























![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



