

손실 함수는 모델이 데이터에 얼마나 잘 맞는지 측정하는 알고리즘입니다. 손실 함수는 실제 측정값과 예측값 간의 차이를 측정하는 방법입니다. 손실 함수의 값이 높을수록 예측이 부정확해지고, 손실 함수의 값이 낮을수록 예측이 실제 값에 가까워집니다. 손실 함수는 각 개별 관찰(데이터 포인트)에 대해 계산됩니다. 모든 손실 함수의 값을 평균하는 함수를 비용 함수라고 합니다. 더 쉽게 이해하면 손실 함수는 단일 샘플에 대한 것이고 비용 함수는 모든 샘플에 대한 것입니다.
일부 손실 함수는 평가 측정항목으로도 사용할 수 있습니다. 그러나 손실 함수와 메트릭은 목적이 다릅니다. 측정항목은 최종 모델을 평가하고 다양한 모델의 성능을 비교하는 데 사용되는 반면, 손실 함수는 모델 구축 단계에서 생성되는 모델에 대한 최적화 도구로 사용됩니다. 손실 함수는 모델에 오류를 최소화하는 방법을 안내합니다.
즉, 손실 함수는 모델이 어떻게 훈련되었는지 알고 측정 지수는 모델의 성능을 설명합니다.
손실 함수는 예측 값과 예측 값의 차이를 측정하므로 실제 값이므로 모델을 훈련할 때(일반적으로 경사하강법) 모델 개선을 안내하는 데 사용할 수 있습니다. 모델을 구축하는 과정에서 특성의 가중치가 변하여 예측이 좋거나 나쁠 경우 손실 함수를 사용하여 모델 내 특성의 가중치를 변경해야 하는지 판단하고 방향을 결정해야 합니다. 변화.
우리가 해결하려는 문제의 유형, 데이터 품질 및 분포, 사용하는 알고리즘에 따라 기계 학습에서 다양한 손실 함수를 사용할 수 있습니다. 다음 그림은 우리가 컴파일한 10가지 일반적인 손실 함수를 보여줍니다. :
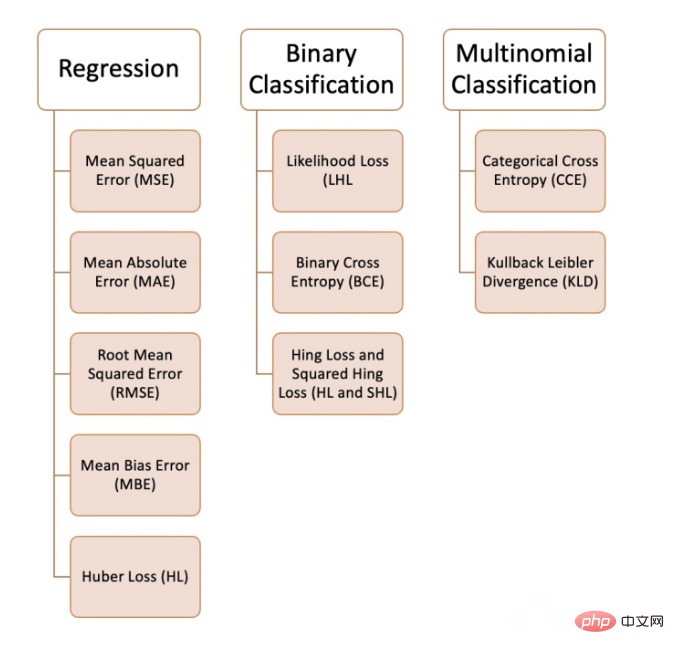
평균 제곱 오차는 모든 예측 값과 실제 값의 차이를 제곱하여 평균한 것입니다. 회귀 문제에 자주 사용됩니다.
def MSE (y, y_predicted): sq_error = (y_predicted - y) ** 2 sum_sq_error = np.sum(sq_error) mse = sum_sq_error/y.size return mse
는 예측값과 실제값의 절대차의 평균으로 계산됩니다. 이는 데이터에 이상값이 있는 경우 평균 제곱 오차보다 더 나은 측정값입니다.
def MAE (y, y_predicted): error = y_predicted - y absolute_error = np.absolute(error) total_absolute_error = np.sum(absolute_error) mae = total_absolute_error/y.size return mae
이 손실 함수는 평균 제곱 오차의 제곱근입니다. 더 큰 오류를 처벌하고 싶지 않은 경우 이는 이상적인 접근 방식입니다.
def RMSE (y, y_predicted): sq_error = (y_predicted - y) ** 2 total_sq_error = np.sum(sq_error) mse = total_sq_error/y.size rmse = math.sqrt(mse) return rmse
는 평균 절대 오차와 유사하지만 절대값을 구하지 않습니다. 이 손실 함수의 단점은 음수 오류와 양수 오류가 서로 상쇄될 수 있다는 점이므로 연구자가 오류가 한 방향으로만 진행된다는 것을 알고 있을 때 적용하는 것이 좋습니다.
def MBE (y, y_predicted): error = y_predicted -y total_error = np.sum(error) mbe = total_error/y.size return mbe
Huber 손실 함수는 평균 절대 오차(MAE)와 평균 제곱 오차(MSE)의 장점을 결합합니다. 이는 Hubber 손실이 두 가지 분기를 갖는 함수이기 때문입니다. 한 가지 분기는 예상 값과 일치하는 MAE에 적용되고 다른 분기는 이상값에 적용됩니다. Hubber Loss의 일반적인 기능은 다음과 같습니다.
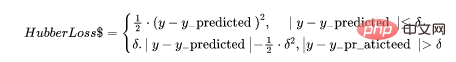
def hubber_loss (y, y_predicted, delta) delta = 1.35 * MAE y_size = y.size total_error = 0 for i in range (y_size): erro = np.absolute(y_predicted[i] - y[i]) if error < delta: hubber_error = (error * error) / 2 else: hubber_error = (delta * error) / (0.5 * (delta * delta)) total_error += hubber_error total_hubber_error = total_error/y.size return total_hubber_error
[0.3 , 0.7 , 0.8 , 0.5 , 0.6 , 0.4]
[0 , 1 , 1 , 1 , 1 , 0]
[0 , 1 , 1 , 0 , 1 , 0]
((1–0.3)+0.7+0.8+(1–0.5)+0.6+(1–0.4)) / 6 = 0.65
def LHL (y, y_predicted): likelihood_loss = (y * y_predicted) + ((1-y) * (y_predicted)) total_likelihood_loss = np.sum(likelihood_loss) lhl = - total_likelihood_loss / y.size return lhl
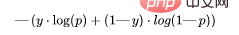
출력 확률 = [0.3, 0.7, 0.8, 0.5, 0.6, 0.4 ]
(0.155 + 0.155 + 0.097 + 0.301 + 0.222 + 0.222) / 6 = 0.192
def BCE (y, y_predicted): ce_loss = y*(np.log(y_predicted))+(1-y)*(np.log(1-y_predicted)) total_ce = np.sum(ce_loss) bce = - total_ce/y.size return bce
Hinge Loss主要用于支持向量机模型的评估。错误的预测和不太自信的正确预测都会受到惩罚。所以一般损失函数是:
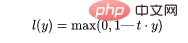
这里的t是真实结果用[1]或[-1]表示。
使用Hinge Loss的类应该是[1]或-1。为了在Hinge loss函数中不被惩罚,一个观测不仅需要正确分类而且到超平面的距离应该大于margin(一个自信的正确预测)。如果我们想进一步惩罚更高的误差,我们可以用与MSE类似的方法平方Hinge损失,也就是Squared Hinge Loss。
如果你对SVM比较熟悉,应该还记得在SVM中,超平面的边缘(margin)越高,则某一预测就越有信心。如果这块不熟悉,则看看这个可视化的例子:
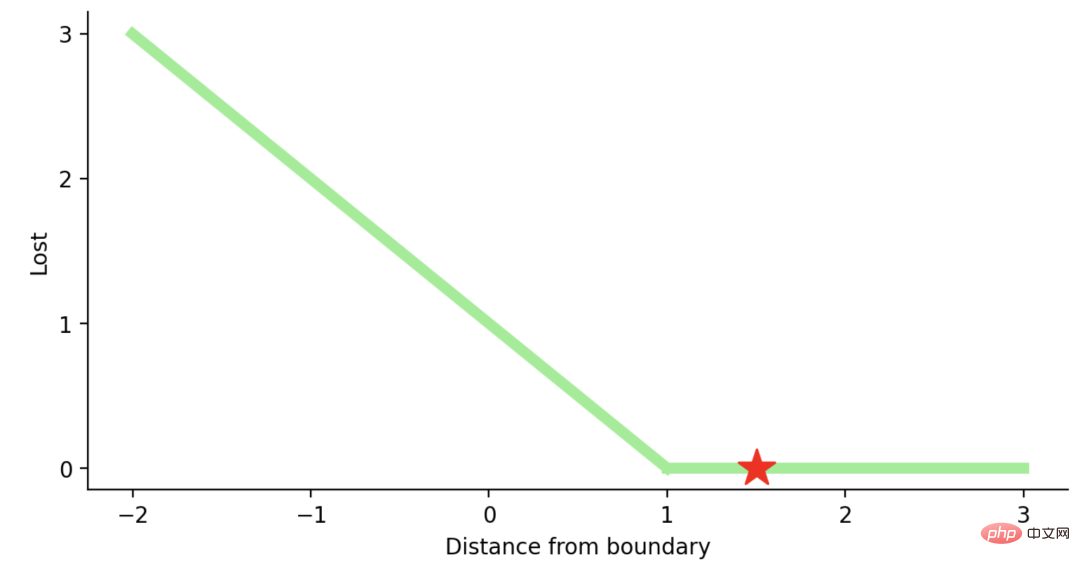
如果一个预测的结果是1.5,并且真正的类是[1],损失将是0(零),因为模型是高度自信的。
loss= Max (0,1 - 1* 1.5) = Max (0, -0.5) = 0
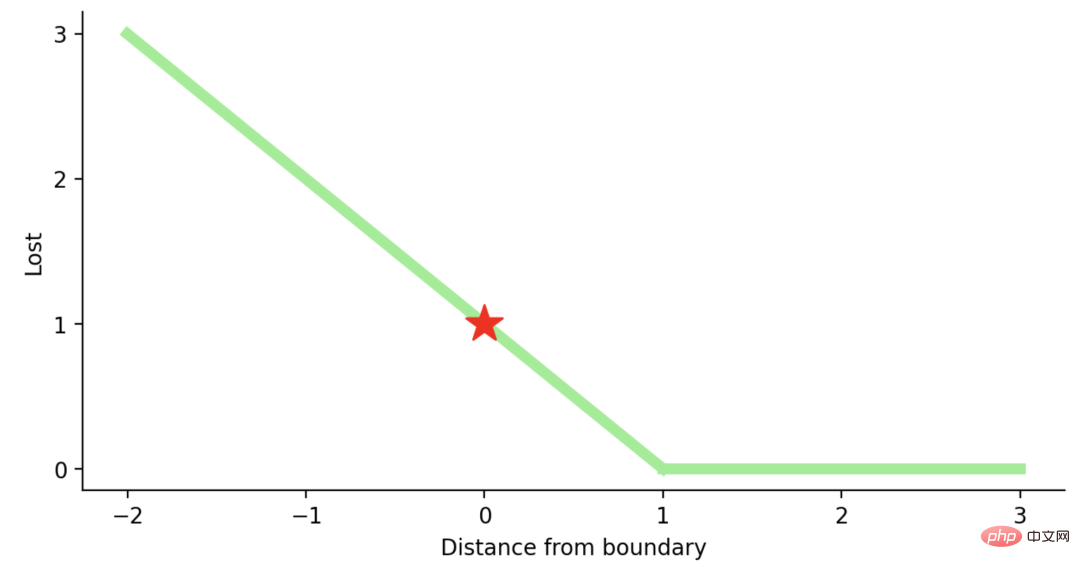
如果一个观测结果为0(0),则表示该观测处于边界(超平面),真实的类为[-1]。损失为1,模型既不正确也不错误,可信度很低。
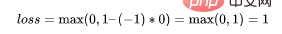
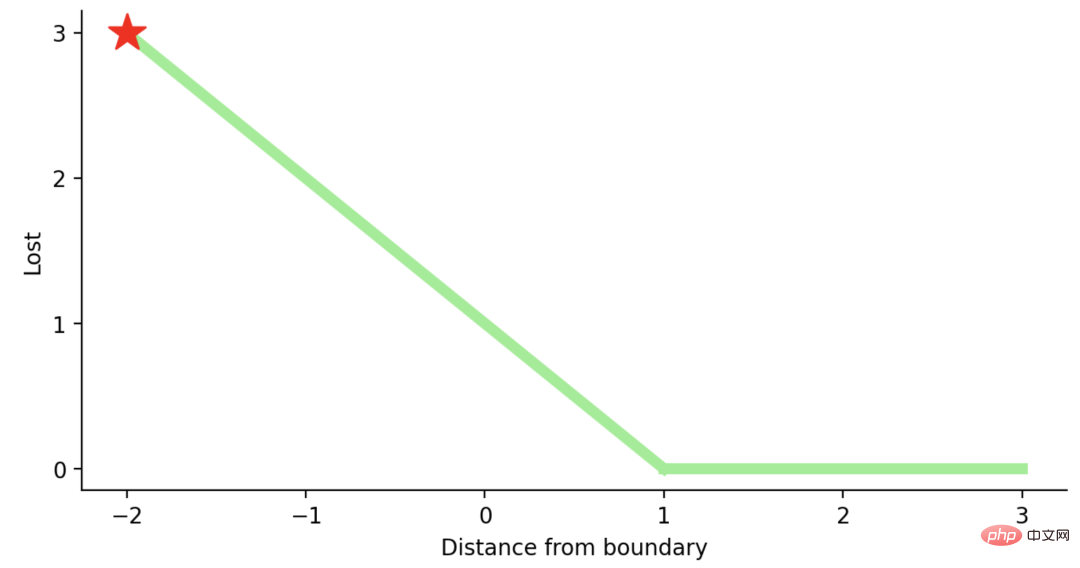
如果一次观测结果为2,但分类错误(乘以[-1]),则距离为-2。损失是3(非常高),因为我们的模型对错误的决策非常有信心(这个是绝不能容忍的)。
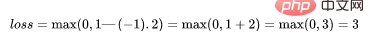
python代码如下:
#Hinge Loss def Hinge (y, y_predicted): hinge_loss = np.sum(max(0 , 1 - (y_predicted * y))) return hinge_loss #Squared Hinge Loss def SqHinge (y, y_predicted): sq_hinge_loss = max (0 , 1 - (y_predicted * y)) ** 2 total_sq_hinge_loss = np.sum(sq_hinge_loss) return total_sq_hinge_loss
在多分类中,我们使用与二元交叉熵类似的公式,但有一个额外的步骤。首先需要计算每一对[y, y_predicted]的损失,一般公式为:
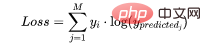
如果我们有三个类,其中单个[y, y_predicted]对的输出是:

这里实际的类3(也就是值=1的部分),我们的模型对真正的类是3的信任度是0.7。计算这损失如下:
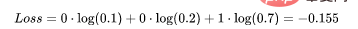
为了得到代价函数的值,我们需要计算所有单个配对的损失,然后将它们相加最后乘以[-1/样本数量]。代价函数由下式给出:
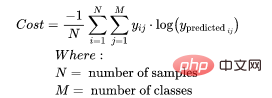
使用上面的例子,如果我们的第二对:

那么成本函数计算如下:
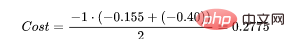
使用Python的代码示例可以更容易理解;
def CCE (y, y_predicted): cce_class = y * (np.log(y_predicted)) sum_totalpair_cce = np.sum(cce_class) cce = - sum_totalpair_cce / y.size return cce
又被简化称为KL散度,它类似于分类交叉熵,但考虑了观测值发生的概率。如果我们的类不平衡,它特别有用。
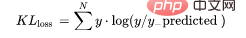
def KL (y, y_predicted): kl = y * (np.log(y / y_predicted)) total_kl = np.sum(kl) return total_kl
以上就是常见的10个损失函数,希望对你有所帮助。
위 내용은 일반적으로 사용되는 손실 함수 및 Python 구현 예의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



