


안녕하세요 여러분 J형제입니다. (기사 마지막에 책 제공)
데이터 시각화란 그래픽이나 표를 사용하여 데이터를 표현하는 것을 말합니다. 차트는 데이터의 성격과 데이터 또는 속성 간의 관계를 명확하게 표현할 수 있어 사람들이 차트를 쉽게 해석할 수 있습니다. 탐색적 그래프를 통해 사용자는 데이터의 특성을 파악하고, 데이터의 추세를 파악하며, 데이터를 이해하는 문턱을 낮출 수 있습니다.
이 장에서는 Matplotlib 모듈을 사용하는 대신 주로 Pandas를 사용하여 그래픽을 그립니다. 실제로 Pandas는 Matplotlib의 그리기 방법을 DataFrame에 통합했기 때문에 실제 응용 프로그램에서는 사용자가 Matplotlib를 직접 참조하지 않고도 그리기 작업을 완료할 수 있습니다.
꺾은선형 차트는 다양한 분야의 연속 데이터 간의 관계를 표시하는 데 사용할 수 있는 가장 기본적인 차트입니다. 꺾은선형 차트를 그리는 데는plot.line() 메소드를 사용하며, 색상, 모양 등의 매개변수를 설정할 수 있습니다. 사용 측면에서 분할선 다이어그램을 그리는 방법은 Matplotlib의 사용법을 완전히 상속하므로 그림 8.4와 같이 프로그램은 다이어그램을 생성하기 위해 마지막에 plt.show()도 호출해야 합니다.
df_iris[['sepal length (cm)']].plot.line() plt.show() ax = df[['sepal length (cm)']].plot.line(color='green',title="Demo",style='--') ax.set(xlabel="index", ylabel="length") plt.show()
분산형 차트는 다양한 분야의 개별 데이터 간의 관계를 보는 데 사용됩니다. 산포도는 그림 8.5와 같이 df.plot.scatter()를 사용하여 그려집니다.
df = df_iris
df.plot.scatter(x='sepal length (cm)', y='sepal width (cm)')
from matplotlib import cm
cmap = cm.get_cmap('Spectral')
df.plot.scatter(x='sepal length (cm)',
y='sepal width (cm)',
s=df[['petal length (cm)']]*20,
c=df['target'],
cmap=cmap,
title='different circle size by petal length (cm)')
히스토그램 차트는 일반적으로 연속 데이터의 분포를 표시하기 위해 동일한 열에 사용됩니다. 히스토그램과 유사한 또 다른 차트는 동일한 필드를 보는 데 사용되는 막대 차트입니다. , 그림 8.6과 같이.
df[['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)','petal width (cm)']].plot.hist() 2 df.target.value_counts().plot.bar()
파이 차트를 사용하면 같은 열에 있는 각 항목의 비율을 볼 수 있고, 박스 차트를 사용하면 같은 필드에 있는 데이터의 분포 차이를 비교할 수 있습니다. 또는 그림 8.7에 표시된 것처럼 다른 필드에 있습니다.
df.target.value_counts().plot.pie(legend=True) df.boxplot(column=['target'],figsize=(10,5))
이 섹션에서는 두 개의 실제 데이터 세트를 사용하여 여러 가지 데이터 탐색 방법을 실제로 보여줍니다.
미국 지역사회 조사에서는 매년 약 350만 가구에 자신이 누구인지, 어떻게 생활하는지에 대한 자세한 질문을 합니다. 설문 조사는 혈통, 교육, 직업, 교통, 인터넷 사용 및 거주를 포함한 다양한 주제를 다루고 있습니다.
데이터 출처: https://www.kaggle.com/census/2013-american-community-survey.
데이터 이름: 2013년 미국 지역사회 조사.
먼저 데이터의 모습과 특징을 살펴보고, 각 분야의 의미와 유형, 범위를 살펴보세요.
# 读取数据
df = pd.read_csv("./ss13husa.csv")
# 栏位种类数量
df.shape
# (756065,231)
# 栏位数值范围
df.describe()먼저 두 개의 ss13pusa.csv를 연결하세요. 이 데이터에는 SCHL(학교 수준), PINCP(소득), ESR(근로 상태, 근로 상태)의 3개 필드로 구성된 총 300,000개의 데이터가 포함되어 있습니다.
pusa = pd.read_csv("ss13pusa.csv") pusb = pd.read_csv("ss13pusb.csv")
# 串接两份数据
col = ['SCHL','PINCP','ESR']
df['ac_survey'] = pd.concat([pusa[col],pusb[col],axis=0)학력에 따라 데이터를 그룹화하고 학력이 다른 숫자의 비율을 관찰한 다음 평균 소득을 계산하세요.
group = df['ac_survey'].groupby(by=['SCHL']) print('学历分布:' + group.size())
group = ac_survey.groupby(by=['SCHL']) print('平均收入:' +group.mean())보스턴 주택 가격 데이터세트에는 506개의 데이터 샘플과 13개의 특징 차원을 포함하여 보스턴 지역의 주택에 대한 정보가 포함되어 있습니다.
데이터 출처: https://archive.ics.uci.edu/ml/machine-learning-databases/housing/.
데이터 이름: 보스턴 주택 가격 데이터세트.
먼저 데이터의 모습과 특징을 살펴보고, 각 분야의 의미와 유형, 범위를 살펴보세요.
주택 가격 분포(MEDV)는 그림 8.8과 같이 히스토그램 형태로 그릴 수 있습니다.
df = pd.read_csv("./housing.data")
# 栏位种类数量
df.shape
# (506, 14)
#栏位数值范围df.describe()
import matplotlib.pyplot as plt
df[['MEDV']].plot.hist()
plt.show()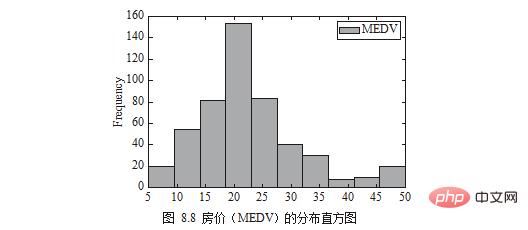
참고: 그림의 영어는 작성자가 코드나 데이터에 지정한 이름에 해당합니다. 실제로는 독자가 필요한 단어로 바꿀 수 있습니다.
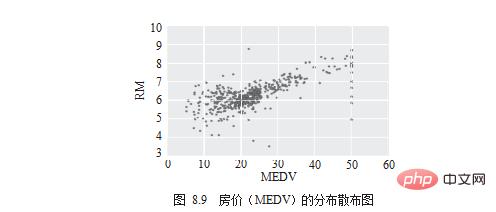
다음으로 알아야 할 것은 "집값"과 어떤 차원이 분명히 관련되어 있는지입니다. 먼저 그림 8.9와 같이 산점도를 사용하여 관찰하십시오.
# draw scatter chart df.plot.scatter(x='MEDV', y='RM') . plt.show()
最后,计算相关系数并用聚类热图(Heatmap)来进行视觉呈现,如图 8.10 所示。
# compute pearson correlation corr = df.corr() # drawheatmap import seaborn as sns corr = df.corr() sns.heatmap(corr) plt.show()
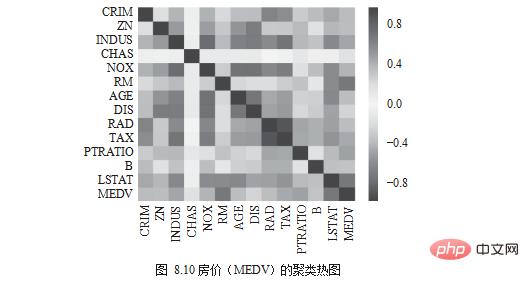
颜色为红色,表示正向关系;颜色为蓝色,表示负向关系;颜色为白色,表示没有关系。RM 与房价关联度偏向红色,为正向关系;LSTAT、PTRATIO 与房价关联度偏向深蓝, 为负向关系;CRIM、RAD、AGE 与房价关联度偏向白色,为没有关系。
声明:本文选自清华大学出版社的《深入浅出python数据分析》一书,略有修改,经出版社授权刊登于此。
위 내용은 Python 데이터 시각화 학습의 좋은 예를 공유해 보세요!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



