

수학에서 가우스 노이즈는 입력 데이터에 평균이 0이고 표준편차(σ)가 있는 정규 분포의 무작위 값을 추가하여 생성되는 노이즈의 일종입니다. 가우스 분포라고도 알려진 정규 분포는 확률 밀도 함수(PDF)로 정의된 연속 확률 분포입니다.
pdf(x) = (1 / (σ * sqrt(2 * π))) * e^(- (x — μ)² / (2 * σ²))
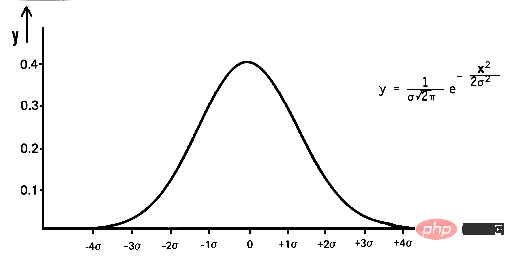
여기서 x는 확률 변수이고 μ는 평균이고 σ는 표준 편차.
정규 분포를 사용하여 임의의 값을 생성하고 이를 입력 데이터에 추가합니다. 예를 들어 이미지에 가우스 노이즈를 추가하면 이미지를 픽셀 값의 2차원 행렬로 표현한 다음 numpy 라이브러리 np.random.randn(rows,cols)를 사용하여 임의의 값을 생성할 수 있습니다. 정규 분포를 선택하고 이를 픽셀 값으로 이미지에 추가합니다. 그 결과 가우스 노이즈가 추가된 새로운 이미지가 생성됩니다.
백색 잡음이라고도 알려진 가우스 잡음은 정규 분포를 따르는 일종의 랜덤 잡음입니다. 딥러닝에서는 모델의 견고성과 일반화 능력을 향상시키기 위해 훈련 중에 입력 데이터에 가우스 노이즈가 추가되는 경우가 많습니다. 이를 데이터 증대라고 합니다. 입력 데이터에 노이즈를 추가함으로써 모델은 입력의 작은 변화에도 견고한 기능을 학습하게 되며, 이는 보이지 않는 새로운 데이터에서 더 나은 성능을 발휘하는 데 도움이 될 수 있습니다. 훈련 중에 신경망의 가중치에 가우스 노이즈를 추가하여 성능을 향상시킬 수도 있는데, 이 기술을 드롭아웃이라고 합니다.
간단한 예부터 시작해 보겠습니다.
노이즈의 표준 편차(noise_std)는 50이라는 더 큰 값으로 설정되어 이미지에 더 많은 노이즈가 추가됩니다. 노이즈가 더 뚜렷해지고 원본 이미지의 특징이 덜 뚜렷해지는 것을 볼 수 있습니다.
노이즈를 더 추가할 때 노이즈가 유효한 픽셀 값 범위(예: 0에서 255 사이)를 초과하지 않는지 확인해야 한다는 점은 주목할 가치가 있습니다. 이 예에서는 np.clip() 함수를 사용하여 노이즈가 있는 이미지의 픽셀 값이 유효한 범위 내에 있는지 확인합니다.
노이즈가 많을수록 원본 이미지와 노이즈가 있는 이미지의 차이를 더 쉽게 확인할 수 있지만, 모델이 데이터에서 유용한 특징을 학습하는 것이 더 어려워지고 과적합 또는 과소적합이 발생할 수도 있습니다. 따라서 처음에는 적은 양의 노이즈로 시작한 다음, 모델 성능을 모니터링하면서 점차적으로 노이즈를 늘리는 것이 가장 좋습니다.
import cv2
import numpy as np
# Load the image
image = cv2.imread('dog.jpg')
# Add Gaussian noise to the image
noise_std = 50
noise = np.random.randn(*image.shape) * noise_std
noisy_image = np.clip(image + noise, 0, 255).astype(np.uint8)
# Display the original and noisy images
cv2.imshow('Original Image', image)
cv2.imshow('Noisy Image', noisy_image)
cv2.waitKey(0)
cv2.destroyAllWindows()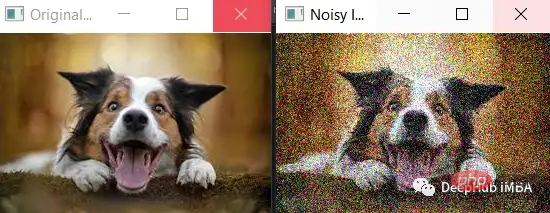
가우스 잡음이 딥 러닝에 어떻게 사용될 수 있는지 보여주는 몇 가지 예입니다.
위의 모든 예에서 가우스 노이즈는 특정 평균 및 표준 편차를 사용하여 제어된 방식으로 입력 또는 가중치에 추가됩니다. 목표는 모델이 데이터로부터 학습하는 것을 어렵게 만들지 않으면서 모델의 성능과 견고성을 향상시키는 것입니다.
여기에서는 모델에 전달하기 전에 Python 및 Keras를 사용하여 훈련하는 동안 입력 데이터에 가우스 노이즈를 추가하는 방법을 설명합니다.
from keras.preprocessing.image import ImageDataGenerator # Define the data generator datagen = ImageDataGenerator( featurewise_center=False,# set input mean to 0 over the dataset samplewise_center=False,# set each sample mean to 0 featurewise_std_normalization=False,# divide inputs by std of the dataset samplewise_std_normalization=False,# divide each input by its std zca_whitening=False,# apply ZCA whitening rotation_range=0,# randomly rotate images in the range (degrees, 0 to 180) width_shift_range=0.1,# randomly shift images horizontally (fraction of total width) height_shift_range=0.1,# randomly shift images vertically (fraction of total height) horizontal_flip=False,# randomly flip images vertical_flip=False,# randomly flip images noise_std=0.5# add gaussian noise to the data with std of 0.5 ) # Use the generator to transform the data during training model.fit_generator(datagen.flow(x_train, y_train, batch_size=32), steps_per_epoch=len(x_train) / 32, epochs=epochs)
Keras 的 ImageDataGenerator 类用于定义一个数据生成器,该数据生成器将指定的数据增强技术应用于输入数据。 我们将 noise_std 设置为 0.5,这意味着标准偏差为 0.5 的高斯噪声将添加到输入数据中。 然后在调用 model.fit_generator 期间使用生成器在训练期间将数据扩充应用于输入数据。
至于Dropout,可以使用Keras中的Dropout层,设置dropout的rate,如果设置rate为0.5,那么dropout层会drop掉50%的权重。 以下是如何向模型添加 dropout 层的示例:
from keras.layers import Dropout model = Sequential() model.add(Dense(64, input_dim=64, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(64, activation='relu')) model.add(Dense(10, activation='softmax'))
需要注意的是,标准差、Dropout的实际值将取决于具体问题和数据的特征。使用不同的值进行试验并监视模型的性能通常是一个好主意。
下面我们介绍使用Keras 在训练期间将高斯噪声添加到输入数据和权重。为了向输入数据添加噪声,我们可以使用 numpy 库生成随机噪声并将其添加到输入数据中。 这是如何执行此操作的示例:
import numpy as np # Generate some random input data x_train = np.random.rand(1000, 64) y_train = np.random.rand(1000, 10) # Add Gaussian noise to the input data noise_std = 0.5 x_train_noisy = x_train + noise_std * np.random.randn(*x_train.shape) # Train the model model.fit(x_train_noisy, y_train, epochs=10)
我们输入数据 x_train 是形状为 (1000, 64) 的二维数组,噪声是使用 np.random.randn(*x_train.shape) 生成的,它将返回具有相同形状的正态分布均值为 0,标准差为 1的随机值数组。然后将生成的噪声与噪声的标准差 (0.5) 相乘,并将其添加到输入数据中,从而将其添加到输入数据中。
为了给权重添加噪声,我们可以使用 Keras 中的 Dropout 层,它会在训练过程中随机丢弃一些权重。 高斯噪声是深度学习中广泛使用的技术,在图像分类训练时可以在图像中加入高斯噪声,提高图像分类模型的鲁棒性。 这在训练数据有限或具有很大可变性时特别有用,因为模型被迫学习对输入中的小变化具有鲁棒性的特征。
以下是如何在训练期间向图像添加高斯噪声以提高图像分类模型的鲁棒性的示例:
from keras.preprocessing.image import ImageDataGenerator # Define the data generator datagen = ImageDataGenerator( featurewise_center=False,# set input mean to 0 over the dataset samplewise_center=False,# set each sample mean to 0 featurewise_std_normalization=False,# divide inputs by std of the dataset samplewise_std_normalization=False,# divide each input by its std zca_whitening=False,# apply ZCA whitening rotation_range=0,# randomly rotate images in the range (degrees, 0 to 180) width_shift_range=0,# randomly shift images horizontally (fraction of total width) height_shift_range=0,# randomly shift images vertically (fraction of total height) horizontal_flip=False,# randomly flip images vertical_flip=False,# randomly flip images noise_std=0.5# add gaussian noise to the data with std of 0.5 ) # Use the generator to transform the data during training model.fit_generator(datagen.flow(x_train, y_train, batch_size=32), steps_per_epoch=len(x_train) / 32, epochs=epochs)
目标检测:在目标检测模型的训练过程中,可以将高斯噪声添加到输入数据中,以使其对图像中的微小变化(例如光照条件、遮挡和摄像机角度)更加鲁棒。
def add_noise(image, std): """Add Gaussian noise to an image.""" noise = np.random.randn(*image.shape) * std return np.clip(image + noise, 0, 1) # Add noise to the training images x_train_noisy = np.array([add_noise(img, 0.1) for img in x_train]) # Train the model model.fit(x_train_noisy, y_train, epochs=10)
语音识别:在训练过程中,可以在音频数据中加入高斯噪声,这可以帮助模型更好地处理音频信号中的背景噪声和其他干扰,提高语音识别模型的鲁棒性。
def add_noise(audio, std): """Add Gaussian noise to an audio signal.""" noise = np.random.randn(*audio.shape) * std return audio + noise # Add noise to the training audio x_train_noisy = np.array([add_noise(audio, 0.1) for audio in x_train]) # Train the model model.fit(x_train_noisy, y_train, epochs=10)
生成模型:在 GAN、Generative Pre-training Transformer (GPT) 和 VAE 等生成模型中,可以在训练期间将高斯噪声添加到输入数据中,以提高模型生成新的、看不见的数据的能力。
# Generate random noise noise = np.random.randn(batch_size, 100) # Generate fake images fake_images = generator.predict(noise) # Add Gaussian noise to the fake images fake_images_noisy = fake_images + 0.1 * np.random.randn(*fake_images.shape) # Train the discriminator discriminator.train_on_batch(fake_images_noisy, np.zeros((batch_size, 1)))
在这个例子中,生成器被训练为基于随机噪声作为输入生成新的图像,并且在生成的图像传递给鉴别器之前,将高斯噪声添加到生成的图像中。这提高了生成器生成新的、看不见的数据的能力。
对抗训练:在对抗训练时,可以在输入数据中加入高斯噪声,使模型对对抗样本更加鲁棒。
下面的对抗训练使用快速梯度符号法(FGSM)生成对抗样本,高斯噪声为 在训练期间将它们传递给模型之前添加到对抗性示例中。 这提高了模型对对抗性示例的鲁棒性。
# Generate adversarial examples x_adv = fgsm(model, x_train, y_train, eps=0.01) # Add Gaussian noise to the adversarial examples noise_std = 0.05 x_adv_noisy = x_adv + noise_std * np.random.randn(*x_adv.shape) # Train the model model.fit(x_adv_noisy, y_train, epochs=10)
去噪:可以将高斯噪声添加到图像或信号中,模型的目标是学习去除噪声并恢复原始信号。下面的例子中输入图像“x_train”首先用标准的高斯噪声破坏 0.1 的偏差,然后将损坏的图像通过去噪自动编码器以重建原始图像。 自动编码器学习去除噪声并恢复原始信号。
# Add Gaussian noise to the images noise_std = 0.1 x_train_noisy = x_train + noise_std * np.random.randn(*x_train.shape) # Define the denoising autoencoder input_img = Input(shape=(28, 28, 1)) x = Conv2D(32, (3, 3), activation='relu', padding='same')(input_img) x = MaxPooling2D((2, 2), padding='same')(x) x = Conv2D(32, (3, 3), activation='relu', padding='same')(x) encoded = MaxPooling2D((2, 2), padding='same')(x) # at this point the representation is (7, 7, 32) x = Conv2D(32, (3, 3), activation='relu', padding='same')(encoded) x = UpSampling2D((2, 2))(x) x = Conv2D(32, (3, 3), activation='relu', padding='same')(x) x = UpSampling2D((2, 2))(x) decoded = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(x) autoencoder = Model(input_img, decoded) autoencoder.compile(optimizer='adam', loss='binary
异常检测:高斯噪声可以添加到正常数据中,模型的目标是学习将添加的噪声作为异常检测。
# Add Gaussian noise to the normal data noise_std = 0.1 x_train_noisy = x_train + noise_std * np.random.randn(*x_train.shape) # Concatenate the normal and the noisy data x_train_concat = np.concatenate((x_train, x_train_noisy)) y_train_concat = np.concatenate((np.zeros(x_train.shape[0]), np.ones(x_train_noisy.shape[0]))) # Train the anomaly detection model model.fit(x_train_concat, y_train_concat, epochs=10)
稳健优化:在优化过程中,可以将高斯噪声添加到模型的参数中,使其对参数中的小扰动更加稳健。
Define the loss function def loss_fn(params): model.set_weights(params) return model.evaluate(x_test, y_test, batch_size=32)[0] # Define the optimizer optimizer = optimizers.Adam(1e-3) # Define the step function def step_fn(params): with tf.GradientTape() as tape: loss = loss_fn(params) grads = tape.gradient(loss, params) optimizer.apply_gradients(zip(grads, params)) return params + noise_std * np.random.randn(*params.shape) # Optimize the model params = model.get_weights()
高斯噪声是深度学习中用于为输入数据或权重添加随机性的一种技术。 它是一种通过将均值为零且标准差 (σ) 正态分布的随机值添加到输入数据中而生成的随机噪声。 向数据中添加噪声的目的是使模型对输入中的小变化更健壮,并且能够更好地处理看不见的数据。 高斯噪声可用于广泛的应用,例如图像分类、对象检测、语音识别、生成模型和稳健优化。
위 내용은 딥 러닝의 가우스 잡음: 이를 사용하는 이유 및 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



