

1, java中==andequals 그리고 hashCode 차이점 between
클래스
의 ==로 비교한 메모리 주소는 동일합니다. 비교를 통해 원래 구현도 ==입니다(예: String 등).
hashCode도 Object 클래스의 메서드로 다시 작성되었습니다. 이산형 정수를 반환합니다. 쿼리 속도를 향상시키기 위해 수집 작업에 사용됩니다. (HashMap, HashSet 등이 동일한지 비교)
두 객체가 동일하면 Java 런타임 환경은 해당 해시코드가 동일해야 한다고 생각합니다.
두 객체가 동일하지 않으면 해당 해시코드가 동일할 수 있습니다.
두 개체의 해시 코드가 같다고 해서 반드시 같은 것은 아닙니다.
두 개체의 해시 코드가 동일하지 않은 경우 동일해서는 안 됩니다.
2, int과 integer
int 기본 유형
정수 캡슐화 클래스 int
3의 차이점 String、 StringBuffer와 StringBuilder
String의 차이점: 문자열 상수는 값을 자주 변경해야 하는 상황에는 적합하지 않습니다. 각 변경은 새 객체를 생성하는 것과 같습니다. StringBuffer: 문자열 변수( 스레드 안전)
StringBuilder: 문자열 변수(스레드 안전하지 않음)는 단일 스레드에서 사용성을 보장하며 StringBuffer
4보다 약간 더 효율적입니다. 내부 클래스란 무엇입니까? 내부 클래스의 역할
내부 클래스는 외부 클래스의 속성에 직접 액세스할 수 있습니다.Java의 내부 클래스는 주로
멤버 내부 클래스, 로컬 내부 클래스(메서드 및 범위 내에 중첩됨), 익명으로 나뉩니다. 내부 클래스 Class(생성 방법 없음), 정적 내부 클래스(정적으로 수정된 클래스, 비정적 멤버 변수 및 주변 클래스의 메서드를 사용할 수 없음, 주변 클래스에 의존하지 않음)
5, 차이점 프로세스와 스레드 사이
프로세스는 CPU 자원 할당의 최소 단위이고, 스레드는 CPU 스케줄링의 최소 단위입니다.리소스는 프로세스 간에 공유될 수 없지만 스레드는 자신이 위치한 프로세스의 주소 공간과 기타 리소스를 공유합니다.
프로세스에는 여러 스레드가 있을 수 있으며 프로세스는 프로세스 또는 스레드를 시작할 수 있습니다.
스레드는 하나의 프로세스에만 속할 수 있습니다. 스레드는 동일한 프로세스의 리소스를 직접 사용할 수 있습니다.
6, final, finally, finalize
final : 클래스, 멤버 변수 및 멤버 메소드의 차이는 상속 될 수 없으며 멤버 변수를 수정합니다 immutable., 멤버 메소드는 재정의될 수 없습니다.
finally: 예외 발생 여부에 관계없이 호출될 수 있도록 try...catch...와 함께 사용됩니다.
finalize: 클래스의 메소드, 이 메소드는 이전에 호출됩니다. 가비지 수집, 하위 클래스 재작성 가능 리소스 재활용을 실현하기 위한 finalize() 메소드 작성 인터페이스 하드디스크에서 읽고 쓰는 작업을 하는 중이기 때문에 임시변수가 많이 생성되고 내부적으로 I/O 작업이 많이 실행되는 것은 매우 비효율적입니다.
8 메소드는 상속될 수 있나요? 다시 쓸 수 있나요? 그리고 왜? 상속 가능, 재정의 불가능, 숨겨진정적 메서드와 속성이 하위 클래스에 정의된 경우 이때 상위 클래스의 정적 메서드나 속성은 "숨김"이라고 합니다. 상위 클래스의 정적 메서드와 속성을 호출하려면 상위 클래스 이름, 메서드 또는 변수 이름을 통해 직접 호출하세요. 9 (메서드 및 범위 내에 중첩됨), 익명 내부 클래스(생성자 없음), 정적 내부 클래스(정적으로 수정된 클래스, 비정적 멤버 변수 및 외부 클래스의 메서드를 사용할 수 없으며 이에 의존하지 않음) 외부 클래스) )
내부 클래스를 사용하는 가장 매력적인 이유는 각 내부 클래스가 독립적으로 (인터페이스의) 구현을 상속할 수 있기 때문에 외부 클래스가 (인터페이스의) 구현을 상속했는지 여부에 관계없이 내부 계층의 영향력이 필요합니다.
Java는 다중 상속을 지원하지 않기 때문에 다중 인터페이스 구현을 지원합니다. 그러나 때로는 인터페이스를 사용하여 해결하기 어려운 몇 가지 문제가 있습니다. 이때 내부 클래스에서 제공하는 기능을 사용하여 여러 구체적 또는 추상 클래스를 상속하여 이러한 프로그래밍 문제를 해결할 수 있습니다. 인터페이스는 문제의 일부만 해결하고 내부 클래스는 다중 상속 솔루션을 더욱 완벽하게 만든다고 말할 수 있습니다.
10,
string
을
정수
String →integer Intrger.parseInt(string);Integer→string Integer.toString (); 11. 어떤 상황에서 객체가 가비지 수집 메커니즘에 의해 폐기되나요?
1. 모든 인스턴스에는 활성 스레드 액세스가 없습니다.
2. 다른 인스턴스에서 액세스할 수 없는 순환 참조 인스턴스입니다.
3.Java에는 다양한 참조 유형이 있습니다. 인스턴스가 가비지 수집에 적합한지 여부는 해당 참조 유형에 따라 결정됩니다. 어떤 종류의 물건이 쓸모없는 물건인지 판단하려면. 여기에는 두 가지 방법이 있습니다. 1. 마크 계산 방법을 사용합니다. 개체가 한 번 참조되면 개수가 1씩 증가합니다. 참조가 해제되면 개수가 증가합니다. 이 개수가 0이면 개체를 재활용할 수 있습니다. 물론 이는 문제를 야기합니다. 순환 참조가 있는 개체를 식별하고 재활용할 수 없습니다. 따라서 두 번째 방법이 있습니다. 2 루트 검색 알고리즘을 사용합니다. 루트에서 시작하여 도달 가능한 모든 개체를 검색하므로 나머지 개체는 재활용되어야 합니다.
12, 차이점은 무엇입니까? 정적 프록시와 동적 프록시는 어떤 시나리오에서 사용됩니까?
정적 프록시 클래스: 프로그래머가 생성하거나 특정 도구를 사용하여 자동으로 생성한 후 컴파일합니다. 프로그램이 실행되기 전에 프록시 클래스의 .class 파일이 이미 존재합니다. 동적 프록시 클래스: 프로그램이 실행될 때 반사 메커니즘을 사용하여 동적으로 생성됩니다. 14
, Java에서 다형성을 구현하는 메커니즘은 무엇입니까?답변: 메서드의 재정의와 오버로딩은 Java 다형성의 다른 표현입니다.
오버라이딩은 상위 클래스와 하위 클래스 간의 다형성의 표현입니다.
오버로딩은
16에서 클래스 A 다형성의 표현입니다.
Javareflection
에 대한 이해JAVA 리플렉션 메커니즘은 실행 중입니다. 모든 클래스에 대해 이 클래스의 모든 속성과 메서드를 알 수 있으며 해당 메서드와 속성을 호출할 수 있습니다. 객체에서 시작하여 리플렉션(클래스 클래스)을 통해 클래스의 전체 정보(클래스 이름, 클래스 유형, 패키지, 모든 메소드 Method[] 유형 및 메소드의 전체 정보(수정자, 반환 값 유형 포함))를 얻을 수 있습니다. , Exception, 매개변수 유형), 모든 속성 Field[], 특정 속성의 전체 정보, 생성자), 클래스 자체의 속성 또는 메소드 호출 요약: 실행 프로세스 중에 클래스, 객체, 메소드에 대한 모든 정보를 가져옵니다. .
17, Java 주석
Meta-annotations
에 대한 이해에 대해 이야기해 주세요. 메타 주석의 역할은 다른 주석을 추가하는 것입니다. Java 5.0에서는 다른 주석 유형에 대한 설명을 제공하는 데 사용되는 네 가지 표준 메타 주석 유형이 정의되었습니다.
1.@Target
2.@Retention
3.@Documented
4.@Inherited
18, JavaString에 대한 이해 at 소스 코드에서 string은 변경이나 상속이 불가능한 상수인 final로 수정됩니다.
19
, String왜 불변으로 설계해야 하나요? 1. 스트링 풀 요구 사항
스트링 풀은 메소드 구역의 특별한 저장 공간입니다. 문자열이 생성되고 해당 문자열이 풀에 있으면 문자열을 다시 생성하고 변수에 대한 참조를 반환하는 대신 문자열에 대한 참조가 즉시 변수에 반환됩니다. 문자열이 변경 불가능하지 않은 경우 한 참조(예: string2)에서 문자열을 변경하면 다른 참조(예: string1)에서 더티 데이터가 발생합니다.
2. 문자열 캐시 해시 코드 허용
문자열 해시 코드는 HashMap과 같이 Java에서 자주 사용됩니다. String의 불변성 덕분에 해시 코드가 항상 동일하므로 변경에 대해 걱정할 필요가 없습니다. 이 접근 방식은 해시 코드가 사용될 때마다 다시 계산할 필요가 없음을 의미하며 이는 훨씬 더 효율적입니다.
3. 보안
문자열은 네트워크 연결, 파일 열기 등과 같은 Java 클래스의 매개변수에 널리 사용됩니다. 문자열이 변경 불가능하지 않으면 네트워크 연결과 파일이 변경됩니다. 이로 인해 일련의 보안 위협이 발생합니다. 작동 방식은 기계와 연결되는 줄 알았으나 실제로는 그렇지 않았다. 반영되는 매개변수는 모두 문자열이므로 일련의 보안 문제도 발생합니다.
equal
및 hashCode 메소드 20, Object 클래스가 다시 작성되었습니다. 이유는 무엇입니까? 우선, 같음과 해시코드의 관계는 다음과 같습니다.
1. 두 개체가 동일한 경우(즉, 같음을 사용하여 비교하고 true를 반환하는 경우) 해당 hashCode 값은 동일해야 합니다.
2. 두 객체의 hashCode가 동일하지만 반드시 동일하지는 않은 경우(즉, 같음과 비교하면 false가 반환됨)
프로그램의 효율성을 높이기 위해 hashcode 메서드가 구현되므로, 해시 코드를 먼저 비교하십시오. 서로 다른 경우에는 같음 비교가 필요하지 않습니다. 이렇게 하면 비교해야 하는 횟수에 비해 효율성이 크게 향상됩니다. 컬렉션의. 컬렉션의 개체는 특정 방식으로 정렬되지 않으며 중복된 개체가 없습니다. Set 인터페이스는 주로 두 가지 구현 클래스를 구현합니다. HashSet: HashSet 클래스는 해시 알고리즘에 따라 집합의 개체에 액세스하며 액세스 속도가 비교적 빠릅니다.
TreeSet: TreeSet 클래스는 SortedSet 인터페이스를 구현하고 개체를 정렬할 수 있습니다. 세트.
List의 특징은 요소가 선형 방식으로 저장되고, 반복되는 객체가 컬렉션에 저장될 수 있다는 것입니다. ArrayList(): 길이가 변경될 수 있는 배열을 나타냅니다. 요소는 무작위로 액세스할 수 있으며 ArrayList()에 요소를 삽입하고 삭제하는 속도가 느립니다. LinkedList(): 구현 시 연결된 목록 데이터 구조를 사용합니다. 삽입과 삭제는 빠르고, 접근은 느리다. Map은 키 개체와 값 개체를 매핑하는 컬렉션입니다. 각 요소에는 키 개체와 값 개체 쌍이 포함되어 있습니다. Map은 Collection 인터페이스에서 상속되지 않습니다. Map 컬렉션에서 요소를 검색할 때 키 개체가 제공되는 한 해당 값 개체가 반환됩니다. HashMap: 해시 테이블의 맵 기반 구현입니다. 키-값 쌍을 삽입하고 쿼리하는 비용은 고정되어 있습니다. 용량과 부하율은 생성자를 통해 설정하여 컨테이너의 성능을 조정할 수 있습니다. LinkedHashMap: HashMap과 유사하지만 반복할 때 "키-값 쌍"을 얻는 순서는 삽입 순서 또는 가장 최근에 사용된 순서(LRU)입니다. HashMap보다 약간 느립니다. 내부 순서를 유지하기 위해 연결된 목록을 사용하므로 반복 액세스가 더 빠릅니다.
TreeMap: 레드-블랙 트리 데이터 구조를 기반으로 구현. "키" 또는 "키-값 쌍"을 볼 때 정렬됩니다(순서는 Comparabel 또는 Comparator에 의해 결정됩니다). TreeMap의 특징은 얻은 결과가 정렬되어 있다는 것입니다. TreeMap은 하위 트리를 반환할 수 있는 subMap() 메서드가 있는 유일한 Map입니다.
WeakHashMao: 약한 키 맵, 맵에 사용된 개체도 해제할 수 있습니다. 이는 특별한 문제를 해결하도록 설계되었습니다. 맵 외부에 "키"를 가리키는 참조가 없는 경우 이 "키"는 가비지 수집기에 의해 재활용될 수 있습니다.
26, ArrayMap 및 HashMap
1의 비교 1. 다양한 저장 방법
HashMap에는 HashMapEntry 2. 데이터를 추가할 때 새로운 작업이 수행되고 객체가 달라집니다. 다시 만들어지는데 비용이 많이 듭니다. ArrayMap은 복사 데이터를 사용하므로 효율성이 상대적으로 높습니다. 3. ArrayMap은 배열 축소 기능을 제공합니다. 공간이 있든 없든 배열은 다시 축소됩니다. , HashMap 및 HashTable1 HashMap의 차이점은 스레드로부터 안전하지 않고 더 효율적이며 메서드가 동기화되지 않고 외부 동기화를 제공해야 하며 containvalue 및 containKey 메서드가 있습니다. hashtable은 스레드로부터 안전하며 null 키와 값을 허용하지 않으며 약간 덜 효율적이며 방법은 동기화입니다. 메소드가 포함되어 있습니다. Hashtable은 Dictionary 클래스 에서 상속받습니다. HashMap과 HashSethashMap의 차이점은 HashMap이 Map 인터페이스를 구현하고 HashMap이 키-값 쌍을 저장한다는 것입니다. put() 메소드를 사용하여 요소를 맵에 넣습니다. HashMap에서는 고유 키를 사용하여 객체를 가져오기 때문에 HashMap이 더 빠릅니다. HashSet은 객체만 저장합니다. add() 메서드를 사용하여 요소를 집합에 넣습니다. HashSet은 해시코드 값을 계산하기 위해 두 객체에 대해 동일할 수 있습니다. 메소드 사용 객체의 동일성을 확인하기 위해 두 객체가 다른 경우 false를 반환합니다. HashSet은 HashMap보다 느립니다. , HashSet 및 HashMap설정 요소가 중복되었는지 확인하는 방법은 무엇입니까? HashSet은 중복된 요소를 추가할 수 없습니다. add(Object) 메서드가 호출되면 는 먼저 Object의 hashCode 메서드를 호출하여 hashCode가 이미 존재하는지 확인합니다. 요소가 직접 삽입됩니다. 이미 존재하는 경우 Object 개체의 hashCode 메서드가 호출됩니다. true를 반환할지 여부를 결정하는 것은 요소가 false인 경우입니다. , ArrayList 및 LinkedList과 애플리케이션 시나리오 ArrayList의 차이점은 배열을 기반으로 구현되며 ArrayList는 스레드로부터 안전하지 않습니다. LinkedList는 이중 연결 목록을 기반으로 구현됩니다. 사용 시나리오: (1) 응용 프로그램이 각 인덱스 위치의 요소에 대해 많은 수의 액세스 또는 삭제 작업을 수행하는 경우 ArrayList 개체가 LinkedList보다 훨씬 우수합니다. ( 2) 응용 프로그램이 주로 목록을 반복하고 루프 중에 삽입 또는 삭제 작업을 수행하는 경우 LinkedList 개체는 ArrayList 개체보다 훨씬 우수합니다. 목록 Array: 요소를 결합하는 것입니다. 메모리에 지속적으로 저장됩니다. 장점: 데이터가 연속적으로 저장되고 메모리 주소가 연속적이므로 데이터를 검색할 때 더 효율적입니다. 단점: 저장하기 전에, 연속적인 메모리 공간을 적용해야 하며, 그 공간의 크기는 컴파일 시 결정되어야 합니다. 작업 중 필요에 따라 공간 크기를 변경할 수 없습니다. 데이터가 상대적으로 크면 범위를 벗어날 수 있으며, 데이터가 상대적으로 작으면 메모리 공간이 낭비될 수 있습니다. 데이터 수를 변경할 때 데이터 추가, 삽입, 삭제의 효율성이 떨어집니다. 연결된 목록: 메모리 공간을 위한 동적 응용 프로그램입니다. 배열처럼 메모리 크기를 미리 적용할 필요가 없습니다. 연결 목록은 사용할 때만 적용하면 됩니다. 메모리를 동적으로 적용하거나 삭제할 수 있습니다. 필요에 따라 데이터 추가, 삭제 및 삽입을 위한 공간이 배열보다 유연합니다. 연결된 목록의 데이터는 메모리의 어느 위치에나 있을 수 있으며 데이터는 애플리케이션을 통해(즉, 기존 요소의 포인터를 통해) 세 가지 방법으로 연결된다는 사실도 있습니다. 스레드를 시작하려면? ava에는 Thread 클래스 상속, Runable 인터페이스 구현 및 스레드 풀 사용이라는 세 가지 방법으로 스레드를 생성할 수 있습니다. 36, 쓰레드와 프로세스의 차이는? 스레드는 프로세스의 하위 집합입니다. 프로세스에는 여러 스레드가 있을 수 있으며 각 스레드는 서로 다른 작업을 병렬로 수행합니다. 서로 다른 프로세스는 서로 다른 메모리 공간을 사용하며 모든 스레드는 동일한 메모리 공간을 공유합니다. 이것을 스택 메모리와 혼동하지 마십시오. 각 스레드에는 로컬 데이터를 저장하는 자체 스택 메모리가 있습니다. 38, run() 및 start()메서드 차이 이 질문은 자주 묻는 질문이지만 여전히 Java 스레드 모델 수준에 대한 면접관의 이해를 구별할 수 있습니다. start() 메서드는 새로 생성된 스레드를 시작하는 데 사용되며, start()는 내부적으로 run() 메서드를 호출하는데, 이는 run() 메서드를 직접 호출하는 것과는 다른 효과를 갖습니다. run() 메소드를 호출하면 원래 스레드에서만 호출됩니다. 새 스레드가 시작되지 않으면 start() 메소드는 새 스레드를 시작합니다. 39. 메소드에 허용되는 동시 액세스 스레드 수를 제어하는 방법은 무엇입니까? semaphore.acquire()는 세마포어를 요청하는데, 이때 세마포어 개수는 -1입니다(일단 사용 가능한 세마포어가 없으면, 즉 세마포어 개수가 음수가 되면 다시 요청할 때 차단하고, 까지 다른 스레드는 세마포어를 해제합니다) semaphore.release()는 이때 Javawait 및 에서 세마포어 수는 +1 40입니다. 스엘프 방법의 차이 Java 프로그램의 대기 및 절전 모드는 모두 일종의 일시 중지를 유발하며 서로 다른 요구 사항을 충족할 수 있습니다. wait() 메서드는 스레드 간 통신에 사용되며 대기 조건이 true이고 다른 스레드가 활성화되면 잠금을 해제하는 반면, sleep() 메서드는 CPU 리소스만 해제하거나 일정 기간 동안 현재 스레드를 중지합니다. 시간이 지나도 잠금이 해제되지는 않습니다. 41 wait/notify 키워드 Waiting 객체의 동기화 잠금을 획득해야 이 메서드를 호출할 수 있습니다. 그렇지 않으면 컴파일이 통과될 수 있지만 런타임 시 IllegalMonitorStateException 예외가 수신됩니다. 객체의 wait() 메서드를 호출하면 스레드가 차단되고 스레드가 계속 실행될 수 없으며 객체에 대한 잠금이 해제됩니다. 객체의 동기화 잠금을 기다리는 스레드를 깨웁니다(대기 중인 스레드가 여러 개인 경우 하나만 깨우기). 이 메서드를 호출할 때 대기 상태에 있는 스레드를 정확하게 깨울 수는 없지만 JVM이 결정합니다. 우선 순위가 아닌 어떤 스레드를 깨울지. 객체의 inform() 메소드를 호출하면 객체의 wait() 메소드를 호출하여 차단된 무작위로 선택된 스레드가 차단 해제됩니다(단, 잠금이 획득될 때까지 실행되지 않습니다). 42, 스레드 차단의 원인은 무엇입니까? 스레드를 닫는 방법? 차단 방법은 프로그램이 다른 작업을 수행하지 않고 해당 방법이 완료될 때까지 기다리는 것을 의미합니다. ServerSocket의 accept() 방법은 클라이언트가 연결될 때까지 기다리는 것입니다. 여기서 차단이란 호출 결과가 반환되기 전에 현재 스레드가 일시 중지되고 결과를 얻을 때까지 반환되지 않음을 의미합니다. 또한 작업이 완료되기 전에 반환되는 비동기식 및 비차단 메서드가 있습니다. 하나는 stop() 메소드를 호출하는 것이고 다른 하나는 스레드를 직접 중지하도록 표시를 설정하는 것입니다(권장) 43, 스레드 안전을 보장하는 방법은 무엇입니까? 1.synchronized; 2.wait, 이를 달성하기 위한 3.ThreadLocal 메커니즘. 44, 스레드 동기화를 달성하는 방법은 무엇입니까? 1.동기화 키워드 수정 방법. 2. 동기화된 키워드로 수정된 명령문 블록 3. 스레드 동기화를 달성하기 위해 특수 도메인 변수(휘발성) 사용 45, 스레드 간 작업 List List list = Collections.synchronizedList(new ArrayList() ); 46 Synchronized 키워드, 클래스 잠금, 메소드 잠금 및 재진입 잠금 java의 객체 잠금 및 클래스 잠금에 대한 이해에 대해 이야기해 보겠습니다. 잠금의 개념은 기본적으로 내장 잠금과 동일하지만 실제로는 매우 다릅니다. 개체 잠금은 개체 인스턴스 메서드에 사용되며 클래스 잠금은 클래스에 사용됩니다. 수업의. 우리는 클래스의 객체 인스턴스가 많이 있을 수 있다는 것을 알고 있지만 각 클래스에는 클래스 객체가 하나만 있으므로 서로 다른 객체 인스턴스의 객체 잠금은 서로 간섭하지 않지만 각 클래스에는 클래스 잠금이 하나만 있습니다. 그러나 한 가지 주목해야 할 점은 실제로 클래스 잠금은 개념적인 것일 뿐 실제로는 존재하지 않는다는 것입니다. 잠금 인스턴스 메서드와 정적 메서드의 차이점을 이해하는 데 도움이 될 뿐입니다 49, synchronized 및 휘발성 키워드 의 차이점은 휘발성의 본질은 레지스터(작업 메모리)의 현재 변수 값을 jvm에 알려주는 것입니다. )은 불확실합니다. 동기화는 현재 변수에 액세스할 수 있고 다른 스레드는 차단됩니다. 2.휘발성은 변수 수준에서만 사용할 수 있습니다. 동기화는 변수, 메서드 및 클래스 수준에서 사용할 수 있습니다. 3.휘발성은 변수의 수정 가시성만 얻을 수 있으며 원자성을 보장할 수는 없지만 동기화는 변수를 보장할 수 있습니다. 수정 가시성 및 원자성 4.휘발성은 스레드 차단을 유발하지 않으며 동기화되면 스레드 차단이 발생할 수 있습니다. 5. 휘발성으로 표시된 변수는 컴파일러에서 최적화되지 않습니다. 동기화로 표시된 변수는 컴파일러에서 최적화할 수 있습니다. 51, ReentrantLock , synchronized 및 휘발성 비교 ava는 예전부터 오랫동안 동기화 키워드를 통해서만 상호 배제를 달성할 수 있었는데, 여기에는 몇 가지 단점이 있습니다. 예를 들어 잠금 외부에서 메서드를 확장하거나 경계를 차단할 수 없으며 잠금을 획득하려고 할 때 중간에 취소할 수 없습니다. Java 5는 이러한 문제를 해결하기 위해 Lock 인터페이스를 통해 보다 복잡한 제어를 제공합니다. ReentrantLock 클래스는 동기화와 동일한 동시성 및 메모리 의미 체계를 가지지만 확장 가능한 Lock을 구현합니다. 53, 교착상태에 필요한 네 가지 조건은? 교착상태의 원인 1. 시스템 자원 경쟁 시스템 자원 경쟁은 시스템 자원 부족과 부적절한 자원 할당으로 이어져 교착 상태를 초래합니다. 2. 프로세스 실행 순서가 부적절합니다 상호 배제 조건: 리소스는 한 번에 하나의 프로세스에서만 사용할 수 있습니다. 즉, 특정 리소스는 일정 기간 내에 하나의 프로세스에서만 점유됩니다. 이때 다른 프로세스가 자원을 요청하면 요청한 프로세스는 대기만 할 수 있다. 요청 및 보유 조건: 프로세스가 하나 이상의 리소스를 유지했지만 새로운 리소스 요청을 했으며 해당 리소스는 이미 다른 프로세스에 의해 점유되었습니다. 이때 요청 프로세스는 차단되었지만 리소스는 유지됩니다. 그것은 얻었습니다. 비박탈 조건: 프로세스에서 획득한 자원은 완전히 사용되기 전에 다른 프로세스에서 강제로 가져갈 수 없습니다. 즉, 리소스를 획득한 프로세스에서만 해제할 수 있습니다(능동적으로 해제할 수만 있음). . 루프 대기 조건: 여러 프로세스가 리소스를 기다리는 종단 간 루프 관계를 형성합니다. 이 네 가지 조건은 시스템에 교착 상태가 발생하는 한 이러한 조건이 충족되어야 하며, 위의 조건 중 하나라도 충족되지 않으면 교착 상태가 발생하지 않습니다. 교착상태 방지 및 방지: 교착상태 방지의 기본 개념: 시스템은 만족할 수 있는 각 시스템에 대해 프로세스에서 발행한 자원 요청을 동적으로 확인하고, 확인 결과에 따라 자원 할당 여부를 결정합니다. 시스템이 교착 상태에 빠지면 할당되지 않고, 그렇지 않으면 할당됩니다. 이는 시스템이 교착 상태에 빠지지 않도록 하기 위한 동적 전략입니다. 교착 상태의 원인, 특히 교착 상태를 생성하는 데 필요한 4가지 조건을 이해하면 교착 상태를 최대한 피하고 방지하고 제거할 수 있습니다. 따라서 시스템 설계 및 프로세스 스케줄링 측면에서 이러한 네 가지 필수 조건이 충족되지 않도록 하는 방법과 프로세스가 시스템 리소스를 영구적으로 점유하는 것을 방지하기 위해 합리적인 리소스 할당 알고리즘을 결정하는 방법에 주의를 기울이십시오. 또한 프로세스가 대기 상태에서 리소스를 점유하는 것을 방지하는 것도 필요합니다. 그러므로 자원배분은 적절하게 계획되어야 한다. 교착 상태 방지와 교착 상태 방지의 차이점: 교착 상태 방지는 교착 상태 발생을 엄격하게 방지하기 위해 교착 상태에 필요한 네 가지 조건 중 하나 이상을 파괴하려고 시도하는 반면, 교착 상태 회피는 교착 상태에 대한 필요 조건이 덜 엄격합니다. 교착상태에 필요한 조건이 존재하더라도 반드시 교착상태가 발생하지 않을 수도 있기 때문이다. 교착상태 회피란 시스템이 작동하는 동안 교착상태가 최종적으로 발생하지 않도록 주의하는 것입니다. 56、스레드 풀이란 무엇이며 어떻게 사용하나요? 작업이 올 때만 스레드를 생성하면 응답 시간이 길어지고, 리소스와 시간이 많이 듭니다. 프로세스가 생성할 수 있는 스레드 수는 제한되어 있습니다. 이러한 문제를 방지하기 위해 프로그램이 시작될 때 처리에 응답하기 위해 여러 스레드가 생성되며 이를 스레드 풀이라고 하며 내부 스레드를 작업자 스레드라고 합니다. JDK1.5부터 Java API는 다양한 스레드 풀을 생성할 수 있도록 Executor 프레임워크를 제공합니다. 예를 들어 단일 스레드 풀은 고정된 수의 스레드 풀 또는 캐시 스레드 풀(단기 작업이 많은 프로그램에 적합한 확장 가능한 스레드 풀)을 한 번에 하나의 작업을 처리합니다. 57、Java에서 힙과 스택의 차이점은 무엇인가요? 이 질문이 멀티스레딩 및 동시성 면접 질문으로 분류되는 이유는 무엇인가요? 스택은 스레드와 밀접한 메모리 영역이기 때문입니다. 각 스레드에는 로컬 변수, 메서드 매개변수 및 스택 호출을 저장하는 데 사용되는 자체 스택 메모리가 있습니다. 힙은 모든 스레드가 공유하는 공통 메모리 영역입니다. 객체는 모두 힙에 생성되며 효율성을 높이기 위해 스레드는 이를 힙에서 자체 스택으로 캐시합니다. 이 변수를 여러 스레드에서 사용하면 이때 휘발성 변수가 작동할 수 있습니다. 스레드가 메인 스택에서 시작되어야 합니다. 메모리에서 변수 값을 읽어야 합니다. 58, 3개의 스레드 T1, T2, T3이 있는데 어떻게 순서대로 실행되는지 확인할 수 있나요? 멀티스레딩에서는 스레드가 특정 순서로 실행되도록 하는 방법이 많이 있습니다. 스레드 클래스의 Join() 메서드를 사용하여 한 스레드에서 다른 스레드를 시작하면 다른 스레드가 스레드를 완료하고 계속할 수 있습니다. 실행. 세 스레드의 순서를 보장하려면 마지막 스레드를 먼저 시작해야 합니다(T3는 T2 호출, T2는 T1 호출). 그러면 T1이 먼저 완료되고 T3이 마지막으로 완료됩니다. 스레드 간 통신 우리는 스레드가 CPU 스케줄링의 가장 작은 단위라는 것을 알고 있습니다. Android에서는 기본 스레드가 시간이 많이 걸리는 작업을 수행할 수 없으며 하위 스레드는 UI를 업데이트할 수 없습니다. 브로드캐스트, 이벤트버스, 인터페이스 콜백 등 스레드 간 통신 방법은 다양합니다. 안드로이드에서는 주로 핸들러를 사용합니다. 핸들러는 sendmessage 메소드를 호출하여 메시지가 포함된 메시지를 Messagequeue로 보내고, 루퍼 객체는 지속적으로 루프 메소드를 호출하여 메시지큐에서 메시지를 꺼내 핸들러에 넘겨 처리함으로써 스레드 간 통신이 완료됩니다. . 스레드 풀 Android에는 FixThreadPool, CachedThreadPool, ScheduledThreadPool 및 SingleThreadExecutor라는 네 가지 일반적인 스레드 풀이 있습니다. FixThreadPool 스레드 풀은 Executors의 새로운 FixThreadPool 메서드를 통해 생성됩니다. 스레드 풀의 스레드 수가 고정되어 있다는 것이 특징입니다. 스레드가 유휴 상태이더라도 스레드 풀이 닫히지 않는 한 재활용되지 않습니다. 모든 스레드가 활성화되면 스레드가 처리되기를 기다리는 새 작업이 대기열에 있습니다. FixThreadPool에는 코어 스레드만 있고 비코어 스레드는 없습니다. CachedThreadPool 스레드 풀은 Executors의 newCachedThreadPool을 통해 생성됩니다. 이는 가변 개수의 스레드가 있는 스레드 풀입니다. 코어 스레드는 없고 비코어 스레드만 있습니다. 스레드 풀의 모든 스레드가 활성화되면 새 작업을 처리하기 위해 새 스레드가 생성됩니다. 그렇지 않으면 유휴 스레드가 새 작업을 처리하는 데 사용됩니다. 스레드 풀의 스레드에는 시간 초과 메커니즘이 있습니다. 이 시간 이후에는 유휴 스레드가 재활용됩니다. 이러한 종류의 스레드 풀은 시간이 적게 소요되는 대량의 작업을 처리하는 데 적합합니다. CachedThreadPool의 작업 대기열은 기본적으로 비어 있다는 점을 여기서 언급해야 합니다. ScheduledThreadPool 스레드 풀은 Executors의 newScheduledThreadPool을 통해 생성됩니다. 코어 스레드는 고정되어 있지만 코어가 아닌 스레드의 개수는 고정되어 있지 않으며, 코어가 아닌 스레드가 유휴 상태인 경우 즉시 재활용됩니다. 이러한 종류의 스레드는 예약된 작업과 고정된 기간으로 반복되는 작업을 실행하는 데 적합합니다. SingleThreadExecutor 스레드 풀은 Executors의 newSingleThreadExecutor 메서드를 통해 생성됩니다. 이 유형의 스레드 풀에는 코어 스레드가 하나만 있으며 비코어 스레드가 없습니다. 이를 통해 모든 작업이 동일한 스레드에서 실행될 수 있습니다. 스레드 동기화 문제를 고려할 필요가 없습니다. AsyncTask작동 방식 AsyncTask는 Android 자체에서 제공하는 경량 비동기 작업 클래스입니다. 스레드 풀에서 백그라운드 작업을 실행한 다음 실행 진행 상황과 최종 결과를 기본 스레드에 전달하여 UI를 업데이트할 수 있습니다. 실제로 AsyncTask는 Thread와 Handler를 내부적으로 캡슐화합니다. AsyncTask는 백그라운드 작업을 수행하고 메인 스레드에서 UI를 업데이트하는 데 매우 편리하지만 특히 시간이 많이 걸리는 백그라운드 작업에는 AsyncTask가 적합하지 않습니다. 개인적으로 스레드 풀을 사용하는 것이 좋습니다. AsyncTask는 4가지 핵심 메소드를 제공합니다: 1.onPreExecute(): 이 메소드는 메인 스레드에서 실행되며 비동기 작업을 실행하기 전에 호출됩니다. 일반적으로 일부 준비 작업에 사용됩니다. 2.doInBackground(String... params): 이 메소드는 스레드 풀에서 실행됩니다. 이 메소드는 비동기 작업을 수행하는 데 사용됩니다. 이 메소드에서는 게시프로그레스(publishProgress) 메소드를 통해 작업 진행 상황을 업데이트할 수 있습니다. 또한, 작업 결과는 onPostExecute 메소드로 반환됩니다. 3.onProgressUpdate(Object...values): 이 메소드는 메인 스레드에서 실행되며 주로 작업 진행 상황이 업데이트될 때 사용됩니다. 4. onPostExecute(Long aLong): 메인 스레드에서 실행됩니다. 비동기 작업이 실행된 후 이 메서드의 매개변수는 백그라운드의 반환 결과입니다. 이러한 메서드 외에도 비동기 작업이 취소될 때 호출되는 onCancelled()와 같이 덜 일반적으로 사용되는 메서드도 있습니다. 소스 코드를 보면 위의 실행 메소드 내에서 Executor() 메소드가 호출된다는 것을 알 수 있습니다. 즉, ExecuteOnExecutor(sDefaultExecutor, params); sDefaultExecutor는 실제로 직렬 스레드 풀입니다. onPreExecute() 메서드가 여기에서 호출됩니다. 다음으로 이 스레드 풀을 살펴보세요. AsyncTask의 실행은 동기화된 키워드로 인해 대기되며 AsyncTask의 Params 매개변수는 FutureTask 클래스로 캡슐화됩니다. FutureTask 클래스는 동시 클래스이며 여기서는 Runnable로 작동합니다. 그런 다음 FutureTask는 SerialExecutor의 실행 메소드로 넘겨져 처리되며, SerialExecutor의 Executor 메소드는 먼저 FutureTask를 mTasks 큐에 추가합니다. 이때 작업이 없으면 ScheduleNext() 메소드가 호출됩니다. 다음 작업을 실행합니다. 작업이 있으면 실행 후 마지막에 ScheduleNext()를 호출하여 다음 작업을 실행합니다. 모든 작업이 완료될 때까지. AsyncTask의 생성자에는 call() 메소드가 있으며, 이 메소드는 FutureTask의 run 메소드에 의해 실행됩니다. 따라서 결국 이 호출 메서드는 스레드 풀에서 실행됩니다. doInBackground 메소드가 여기에서 호출됩니다. 이 call() 메소드를 자세히 살펴보겠습니다. mTaskInvoked.set(true); 현재 작업이 실행되었음을 나타냅니다. 그런 다음 doInBackground 메서드를 실행하고 마지막으로 postResult(result) 메서드를 통해 결과를 전달합니다. postResult() 메소드에서는 sHandler를 통해 메시지를 보냅니다. sHandler에서는 메시지 유형에 따라 MESSAGE_POST_RESULT를 판단합니다. 이 경우 onPostExecute(result) 메소드 또는 onCancelled(result)가 호출됩니다. 또 다른 메시지 유형은 onProgressUpdate를 호출하여 진행 상황을 업데이트하는 MESSAGE_POST_PROGRESS입니다. Binder 작동 메커니즘 직관적으로 Binder는 IPC 관점에서 IBinder 인터페이스를 구현하는 Android의 클래스이며 Android 방식의 크로스 프로세스 통신 유형으로 이해될 수도 있습니다. 가상 물리적 장치이며 해당 장치 드라이버는 /dev/binder/입니다. 프레임워크 관점에서 Binder는 ServiceManager의 브리지입니다. 애플리케이션 계층에서 바인더는 클라이언트와 서버 간의 통신 매체입니다. 먼저 이 클래스의 각 메서드의 의미를 이해해 보겠습니다. DESCRIPTOR: 바인더의 고유 식별자로 일반적으로 현재 바인더 클래스 이름을 나타내는 데 사용됩니다. asInterface(android.os.IBinder obj): 서버의 Binder 객체를 클라이언트가 요구하는 AIDL 인터페이스 유형 객체로 변환하는 데 사용됩니다. 이 변환 프로세스는 클라이언트와 서버가 동일한 프로세스에 있는 경우입니다. 이면 이 메서드는 서버의 스텁 개체 자체를 반환하고, 그렇지 않으면 시스템 캡슐화된 Stub.proxy 개체를 반환합니다. asBinder(): 현재 바인더 개체를 반환하는 데 사용됩니다. onTransact: 이 메서드는 서버 측 바인더 스레드 풀에서 실행됩니다. 클라이언트가 프로세스 간 통신 요청을 시작하면 원격 요청이 시스템의 하위 계층에 의해 캡슐화되어 처리를 위해 이 메서드로 전달됩니다. 이 메서드 public boolean onTransact(int code, android.os.Parcel data, android.os.Parcel reply, int flags)에 주의하세요. 서버는 코드를 통해 클라이언트가 요청한 대상 메서드를 확인한 다음 대상을 검색할 수 있습니다. 데이터에서 메서드에 필요한 매개변수를 가져온 다음 대상 메서드를 실행합니다. 대상 메서드가 실행되면 반환 값이 응답으로 기록됩니다. 이것이 메소드가 실행되는 방식입니다. 이 메서드가 false를 반환하면 클라이언트는 요청에 실패하므로 이 메서드에서 몇 가지 보안 확인을 수행할 수 있습니다. Binder의 작동 메커니즘이지만 주의해야 할 몇 가지 문제가 있습니다. 1. 클라이언트가 요청을 시작할 때 현재 스레드는 서버가 데이터를 반환할 때까지 일시 중지됩니다. 시간이 오래 걸리는 경우 이 원격 요청은 UI 스레드, 즉 기본 스레드에서 시작될 수 없습니다. 2. Service의 Binder 메소드는 스레드 풀에서 실행되기 때문에 Binder 메소드는 이미 스레드에서 실행 중이기 때문에 시간 소모 여부에 관계없이 동기화되어야 합니다. view 이벤트 배포 및 view 작동 원리 Android 사용자 정의 보기, 우리 모두는 구현이 onMeasure(), onLayout(), onDraw()의 세 부분으로 구성되어 있다는 것을 알고 있습니다. View의 그리기 프로세스는 viewRoot의 perfromTraversal 메서드에서 시작됩니다. 측정, 레이아웃, 그리기 메소드를 통해 뷰를 그릴 수 있습니다. 그 중 Measure는 너비와 높이를 측정하고, 레이아웃은 상위 컨테이너의 뷰 위치를 결정하며, draw는 뷰를 화면에 그립니다. Measure: view 측정에는 32비트 int 값을 나타내는 MeasureSpc(측정 사양)가 필요하며, 상위 2비트는 SpecMode(측정 모드)를 나타내고, 하위(30)비트는 SpecSize(a)를 나타냅니다. 특정 측정 모드) 사양은 아래 참조). SpecMode와 SpeSize의 집합을 MeasureSpec으로 패키징할 수 있고, 반대로 MeasureSpec을 언패킹하여 SpecMode와 SpeSize의 값을 얻을 수 있습니다. SpecMode에는 세 가지 유형이 있습니다. unSpecified: 상위 컨테이너에는 원하는 만큼 크거나 작은 보기에 대한 제한이 없습니다. 이는 주로 일반 시스템에서 사용됩니다. 정확히: 상위 컨테이너가 뷰에 필요한 정확한 크기를 감지했습니다. 이때 뷰의 크기는 레이아웃 레이아웃의 math_parent에 해당하는 SpecSize 또는 특정 값입니다. 상위 컨테이너는 사용 가능한 크기 SpecSize를 지정하며, 뷰의 크기는 이 레이아웃의 wrao_content에 해당하는 이 값보다 클 수 없습니다. 일반 뷰의 경우 해당 MeasureSpec은 상위 컨테이너의 MeasureSpec과 자체 뷰에 의해 결정됩니다. layoutParam.MeasureSpec이 결정되면 onMeasure는 뷰의 너비와 높이를 결정할 수 있습니다. View의 측정 프로세스: onMeasure 메소드에는 뷰의 너비 및 높이 측정 값을 설정하는 setMeasureDimenSion 메소드가 있고, setMeasureDimenSion에는 getDefaultSize() 메소드가 매개변수로 있습니다. 일반적인 상황에서는 at_most 및 정확한 상황에만 주의하면 됩니다. getDefaultSize의 반환 값은 MeasureSpec의 SpecSize이며 이 값은 기본적으로 뷰의 측정된 크기입니다. UnSpecified의 경우 일반적으로 시스템 내 측정 프로세스로 뷰의 배경과 같은 요소를 고려해야 합니다. 앞서 이야기한 것은 view의 측정 프로세스와 viewGroup의 측정 프로세스입니다. viewGroup의 경우 자체 측정 프로세스를 완료하는 것 외에도 하위 클래스의 측정 메서드를 호출하기 위해 순회해야 합니다. 각 하위 요소는 이를 재귀적으로 수행합니다. Process, viewGroup은 추상 클래스이며 onMeasure 메서드를 제공하지 않지만 MeasureChildren 메서드를 제공합니다. MeasureChild 메서드의 아이디어는 자식 요소의layoutParams를 꺼낸 다음 getChildMeasureSpec을 통해 자식 요소의 MeasureSpec을 가져온 다음 전기영동 측정 메서드에서 자식 요소를 측정하는 것입니다. viewGroup 하위 클래스는 레이아웃 방법이 다르기 때문에 측정 세부 사항이 다르기 때문에 viewGroup은 view와 같은 측정을 위해 onMeasure 메서드를 호출할 수 없습니다. 참고: 활동 수명 주기 동안 뷰의 너비와 높이를 정확하게 얻을 수 있는 방법은 없습니다. 그 이유는 뷰가 측정되지 않았기 때문입니다. 일반 뷰의 경우 setFrame 메서드를 사용하여 뷰의 네 정점 위치를 가져올 수 있으며, 이는 상위 컨테이너에서 뷰의 위치를 결정한 다음 onLayout 메서드를 호출합니다. 하위 요소의 위치는 상위 컨테이너에 의해 결정됩니다. 화면에 뷰를 그리는 방법입니다. 다음 단계로 나누어 보세요: 휴대폰 하드웨어의 한계로 인해 메모리와 CPU는 PC만큼 큰 메모리를 가질 수 없습니다. Android 휴대폰에서는 메모리를 과도하게 사용하면 쉽게 oom, CPU 사용이 과도해집니다. 리소스로 인해 전화기가 정지되거나 심지어 anr이 발생할 수도 있습니다. 저는 주로 다음과 같은 부분에서 최적화를 합니다: 레이아웃 최적화, 도면 최적화, 메모리 누수 최적화, 응답 속도 최적화, 리스트뷰 최적화, 비트맵 최적화, 스레드 최적화 레이아웃 최적화: 도구 계층 뷰어, 솔루션: 1. 수준. 2. Relativelayout과 같이 성능이 낮은 뷰그룹을 선택하세요. Relativelayout이나 LinearLayout을 선택할 수 있다면 먼저 LinearLayout을 사용하세요. Relativelayout 기능은 상대적으로 복잡하고 더 많은 CPU 리소스를 차지하기 때문입니다. 3. 레이아웃을 재사용하려면 드로잉 최적화는 ondraw 메서드가 자주 호출될 수 있기 때문에 뷰가 ondraw 메서드에서 시간이 많이 걸리는 작업을 방지한다는 의미입니다. 1. ondraw 메서드에서는 새로운 지역 변수를 생성하지 마세요. ondraw 메서드는 자주 호출되므로 GC가 발생하기 쉽습니다. 2. Ondraw 방식에서는 시간이 많이 걸리는 작업을 수행하지 마세요. 메모리 최적화: 참조 메모리 누수. 응답 최적화: 메인 스레드는 시간이 많이 걸리는 작업을 수행할 수 없으며 터치 이벤트는 5초, 브로드캐스트는 10초, 서비스는 20초가 걸립니다. Listview 최적화: 1. getview 메서드에서 시간이 많이 걸리는 작업을 피하세요. 2. 뷰 재사용 및 뷰홀더 사용. 3. 슬라이딩은 비동기 로딩을 활성화하는 데 적합하지 않습니다. 4. 페이지 단위로 데이터를 처리합니다. 5. 이미지는 레벨 3 캐시를 사용합니다. 비트맵 최적화: 1. 이미지를 동일한 비율로 압축합니다. 2. 사용하지 않는 사진을 제때 재활용 스레드 최적화 스레드 최적화의 아이디어는 스레드 풀을 사용하여 스레드를 관리하고 재사용하는 동시에 프로그램에서 많은 스레드가 발생하지 않도록 하는 것입니다. 리소스를 점유하면 스레드 차단이 발생하지 않도록 동시 스레드 수를 제어할 수 있습니다. 기타 최적화 1. 많은 공간을 차지하는 열거형을 적게 사용하세요. 2. hashMap 대신 SparseArray와 같은 Android 전용 데이터 구조를 사용하세요. 3. 소프트 참조와 약한 참조를 적절하게 사용하세요. base64, MD5, 대칭 암호화 및 비대칭 암호화) 및 사용 시나리오. Rsa 암호화란 무엇인가요? RSA 알고리즘은 길이가 다양할 수 있는 키를 사용하는 가장 널리 사용되는 공개 키 암호화 알고리즘입니다. RSA는 데이터 암호화와 디지털 서명 모두에 사용할 수 있는 최초의 알고리즘입니다. RSA 알고리즘의 원리는 다음과 같습니다. 1. 두 개의 큰 소수 p와 q를 무작위로 선택합니다. p는 q와 같지 않습니다. N=pq를 계산합니다. 2. 1이고 N보다 작은 경우, e는 (p -1)(q-1)이 상대적으로 소수와 같아야 합니다. 3. 공식 d×e = 1(mod (p-1)(q-1))을 사용하여 d를 계산합니다. 4. p와 q를 파괴하세요. 마지막 N과 e는 "공개 키"이고, d는 "개인 키"입니다. 보낸 사람은 N을 사용하여 데이터를 암호화하고, 받는 사람은 d를 사용하여 데이터 내용을 해독할 수 있습니다. RSA의 보안은 큰 숫자 분해에 의존합니다. 1024비트보다 작은 N은 안전하지 않은 것으로 입증되었으며 RSA 알고리즘은 큰 숫자 계산을 수행하기 때문에 가장 빠른 RSA도 DES보다 몇 배 느립니다. RSA는 일반적으로 소량의 데이터나 암호화 키를 암호화하는 데만 사용할 수 있지만 RSA는 여전히 강력한 알고리즘입니다. 사용 시나리오: 프로젝트에서는 로그인, 결제 및 기타 인터페이스를 제외하고 RSA 비대칭 암호화가 사용되며, 기타 인터페이스에는 AES 대칭 암호화가 사용됩니다. MD5 암호화란 무엇인가요? MD5의 정식 영어 이름은 "Message-Digest Algorithm 5"입니다. 이는 "Message Digest Algorithm 5"를 의미합니다. MD2, MD3, MD4에서 발전한 단방향 암호화 알고리즘이며 되돌릴 수 없는 암호화 방식입니다. MD5 암호화의 특징은 무엇인가요? 압축성: 모든 길이의 데이터에 대해 계산된 MD5 값의 길이는 고정됩니다. 계산 용이성: 원본 데이터에서 MD5 값을 계산하는 것은 쉽습니다. 수정에 대한 저항성: 원본 데이터가 변경되면 1바이트만 수정되더라도 결과 MD5 값은 매우 달라집니다. 강력한 충돌 방지: 원본 데이터와 해당 MD5 값을 고려할 때 동일한 MD5 값을 갖는 데이터(즉, 위조된 데이터)를 찾기가 매우 어렵습니다. MD5 적용 시나리오: 일관성 검증 디지털 서명 보안 액세스 인증 AES 암호화란 무엇인가요? 암호화 분야의 Rijndael 암호화 방식이라고도 알려진 Advanced Encryption Standard(영어: Advanced Encryption Standard, 약어: AES)는 미국 연방 정부에서 채택한 블록 암호화 표준입니다. 이 표준은 원래 DES를 대체하는 데 사용되었으며 많은 당사자에서 분석되었으며 전 세계적으로 널리 사용됩니다. HashMap 구현 원칙: HashMap은 해시 테이블을 기반으로 하는 맵 인터페이스의 비동기 구현으로, null 값을 키와 값으로 사용할 수 있습니다. Java 프로그래밍 언어에는 가장 기본적인 두 가지 구조가 있는데, 하나는 배열이고 다른 하나는 시뮬레이션된 포인터(참조)입니다. 모든 데이터 구조는 이 두 가지 기본 구조를 사용하여 구성할 수 있으며 HashMap도 예외는 아닙니다. HashMap은 실제로 "연결된 목록 해시" 데이터 구조입니다. 배열과 연결리스트를 합친 것입니다. HashMap의 맨 아래 레이어는 데이터 구조이고 배열의 각 항목은 연결 목록입니다. 충돌: Hashclde 값을 계산하기 위해 Hashcode() 메서드가 HashMap에서 호출됩니다. Java의 서로 다른 두 객체가 동일한 Hashcode를 가질 수 있기 때문입니다. 이로 인해 갈등이 발생했습니다. 해결책: HashMap을 넣으면 기본 소스 코드를 볼 수 있습니다. 프로그램이 키-값 개체를 HashMap에 넣으려고 하면 먼저 hashCode() 반환을 기반으로 항목의 저장 위치가 결정됩니다. 두 Entry 키의 hashCode() 메서드가 동일한 값을 반환하면 저장 위치가 동일합니다. 두 Entry 키가 같음 비교를 통해 true를 반환하면 새로 추가된 Entry 값이 덮어쓰여집니다. 값은 원래 항목이지만 키는 덮어쓰지 않습니다. 반대로 false가 반환되면 새로 추가된 항목은 컬렉션의 원래 항목과 함께 항목 체인을 형성합니다. HashMap의 구현 원리: 1. 활동주기? onCreate() -> onResume() -> onStop() -> onDetroy() 서비스를 시작하는 방법에는 두 가지가 있습니다. 하나는 startService()를 통해 시작하는 것이고, 다른 하나는 binService()를 통해 시작하는 것입니다. 시작 방법마다 수명 주기가 다릅니다. startService()를 통해 시작된 서비스의 수명 주기는 다음과 같습니다. startService() --> onCreate()--> onStartConmon()--> 이렇게 시작한다면 몇 가지 문제에 주의해야 합니다. 첫째, startService를 통해 호출할 때 startService()를 여러 번 호출하면 onCreate() 메서드가 한 번만 호출되고 onStartConmon()이 호출됩니다. stopService()를 호출하면 onDestroy()가 호출되어 서비스가 파괴됩니다. 둘째: startService를 통해 시작하여 인텐트를 통해 값을 전달하고 onStartConmon() 메서드에서 값을 가져올 때 먼저 인텐트가 null인지 확인해야 합니다. bindService()를 통해 바인드합니다. 서비스를 바인드하는 방법, 수명 주기 방법:bindService-->onCreate()-->onBind()-->unBind()-->onDestroy() bingservice 장점 이런 방식으로 서비스를 시작하는 것은 액티비티에서 서비스를 운영하는 것이 더 편리하다는 것입니다. 예를 들어, 서비스에 참여하는 방법에는 a, b가 있습니다. Activity에서 ServiceConnection 객체를 얻고 ServiceConnection을 통해 이를 얻은 다음, 이 클래스 객체를 통해 클래스의 메서드를 호출할 수 있습니다. 물론 이 클래스는 Binder 객체를 상속해야 합니다. 3. 활동 시작 프로세스(라이프 사이클에 답하지 않음) 앱 시작에는 두 가지 프로세스가 있습니다. 이 경우 첫 번째는 데스크톱 런처에서 해당 애플리케이션 아이콘을 클릭하는 것이고, 두 번째는 앱을 시작하는 것입니다. 활동에서 startActivity를 호출하여 새 활동. 새 프로젝트를 생성합니다. 기본 루트 활동은 MainActivity이며 모든 활동은 스택에 저장됩니다. 새 활동을 시작하면 이전 활동 위에 배치되고 바탕 화면 아이콘에서 적용을 클릭합니다. , 런처 자체도 애플리케이션이기 때문에 아이콘을 클릭하면 시스템이 startActivitySately()를 호출합니다. 일반적인 상황에서는 우리가 시작하는 활동의 관련 정보(액션, 카테고리 등)가 인텐트에 저장됩니다. . 이 애플리케이션을 설치하면 시스템은 PackaManagerService 관리 서비스도 시작합니다. 이 관리 서비스는 AndroidManifest.xml 파일을 구문 분석하여 애플리케이션에서 서비스, 활동, 브로드캐스트 등과 같은 관련 정보를 얻은 다음 관련 정보를 얻습니다. 관련 구성 요소. 애플리케이션 아이콘을 클릭하면 startActivitySately() 메서드가 호출되고 이 메서드 내에서 startActivty()가 호출되며 결국 startActivity() 메서드는 startActivityForResult() 메서드를 호출하게 됩니다. 그리고 startActivityForResult() 메서드에서. startActivityForResult() 메서드가 결과를 반환하기 때문에 시스템은 직접 -1을 제공합니다. 이는 반환하는 데 결과가 필요하지 않음을 의미합니다. startActivityForResult() 메서드는 실제로 Instrumentation 클래스의 execStartActivity() 메서드를 통해 활동을 시작합니다. Instrumentation 클래스의 주요 기능은 프로그램과 시스템 간의 상호 작용을 모니터링하는 것입니다. 이 execStartActivity() 메서드에서는 ActivityManagerService의 프록시 개체를 가져오고 이 프록시 개체를 통해 활동이 시작됩니다. checkStartActivityResult() 메서드는 시작 중에 호출됩니다. 이 구성 요소가 구성 목록에 구성되어 있지 않으면 이 메서드에서 예외가 발생합니다. 물론 마지막으로 호출하는 것은 활동을 시작하기 위한 Application.scheduleLaunchActivity()입니다. 이 메서드에서는 ActivityClientRecord 개체를 가져오고 이 ActivityClientRecord는 핸들러를 사용하여 메시지를 보냅니다. Description, ActivityClientRecord 개체는 LoaderApk 개체를 저장하며, 이를 통해 Activity 구성 요소를 시작하기 위해 handlerLaunchActivity가 호출되고 이 메서드에서 페이지의 수명 주기 메서드가 호출됩니다. 4. 방송 등록 방법 및 차이점 여기서 확장: 동적 등록을 사용하는 경우 방송 방송에는 두 가지 주요 등록 방법이 있습니다. 첫 번째는 영구 방송이 될 수도 있는 정적 등록입니다. 이러한 브로드캐스트는 Androidmanifest.xml에 등록되어야 합니다. 이렇게 등록된 브로드캐스트는 페이지 수명 주기에 영향을 받지 않습니다. 페이지를 종료하더라도 브로드캐스트는 일반적으로 자동 시작에 사용됩니다. 등, 이 등록 방법의 방송은 상주 방송이므로 CPU 자원을 차지하게 됩니다. 두 번째 유형은 동적 등록이며, 이 등록 방법은 비거주 방송이라고도 합니다. 페이지를 종료한 후에는 방송을 수신할 수 없습니다. 일반적으로 UI를 업데이트하는 데 사용합니다. 이 등록 방법은 우선순위가 더 높습니다. 마지막으로 메모리 누수를 방지하려면 바인딩을 해제해야 합니다. 브로드캐스팅은 순서가 지정된 브로드캐스트와 순서가 지정되지 않은 브로드캐스트로 구분됩니다. 5. HttpClient와 HttpUrlConnection의 차이점 여기서 확장: Volley에서 사용되는 요청 방법(2.3 이전의 HttpClient, 2.3 이후의 HttpUrlConnection) 우선 HttpClient와 HttpUrlConnection은 모두 Https 프로토콜을 지원합니다. 둘 다 스트림 형태로 데이터를 업로드하거나 다운로드하며, IPv6, 연결 풀링 및 기타 기능도 제공한다고 할 수 있습니다. . HttpClient에는 API가 많기 때문에 호환성을 훼손하지 않고 확장하려면 확장하기가 어렵습니다. 이러한 이유로 Google은 Android 6.0에서 이 HttpClient를 직접 포기했습니다. HttpUrlConnection은 상대적으로 가볍고 API는 확장이 쉽고 대부분의 Android 데이터 전송을 충족할 수 있습니다. 비교적 고전적인 프레임워크인 Volley는 버전 2.3 이전에는 HttpClient를 사용했고, 버전 2.3 이후에는 HttpUrlConnection을 사용했습니다. 6. Java 가상 머신과 Dalvik 가상 머신의 차이점 Java 가상 머신: 1. Java 가상 머신은 스택을 기반으로 합니다. 스택 기반 머신은 스택에 데이터를 로드하고 연산하기 위해 명령어를 사용해야 하며, 더 많은 명령어가 필요합니다. 2. Java 가상 머신은 Java 바이트코드를 실행합니다. (Java 클래스는 하나 이상의 바이트코드 .class 파일로 컴파일됩니다.) Dalvik 가상 머신: 1 Dalvik 가상 머신은 레지스터 기반입니다. 2. Dalvik은 사용자 정의 .dex 바이트 코드 형식을 실행합니다. (Java 클래스가 .class 파일로 컴파일된 후 dx 도구를 사용하여 모든 .class 파일을 .dex 파일로 변환한 다음 dalvik 가상 머신이 이 파일의 명령과 데이터를 읽습니다 3. 4. 하나의 애플리케이션, 하나의 가상 머신 인스턴스 및 하나의 프로세스(모든 Android 애플리케이션 스레드는 하나의 Linux 스레드에 해당하고 서로 다른 자체 샌드박스에서 실행됨)로 상수 풀이 수정되었습니다. 애플리케이션은 서로 다른 프로세스에서 실행됩니다. 각 Android dalvik 애플리케이션에는 독립적인 Linux PID(app_*)가 제공됩니다. 7. 프로세스 유지(언데드 프로세스) 여기서 확장: 프로세스의 우선 순위는 무엇입니까 현재 Android 프로세스 업계의 연결 유지 방법은 주로 검정, 흰색, 회색의 세 가지 유형으로 나뉩니다. 일반적인 구현 아이디어는 다음과 같습니다. 검정 연결 유지: 서로 다른 앱 프로세스가 브로드캐스트를 사용하여 서로 깨웁니다(제공되는 브로드캐스트 사용 포함). White keep-alive: 포그라운드 서비스 시작 Gray keep-alive: 시스템 취약점을 이용하여 프런트 엔드 서비스 시작 Black keep-alive 소위 블랙 Keep-alive는 서로 다른 앱 프로세스를 사용하여 서로를 깨우는 일반적인 시나리오입니다. 시나리오 1: 부팅, 네트워크 전환, 사진 촬영 등을 할 때 시스템에서 생성된 브로드캐스트를 사용하여 앱을 깨웁니다. 또는 동영상 촬영 시나리오 2: 타사 SDK에 연결하면 WeChat SDK와 같은 해당 앱 프로세스가 WeChat을 깨우고 Alipay SDK가 Alipay를 깨우게 됩니다. 직접 실행 시나리오 3: 휴대전화에 Alipay, Taobao, Tianbao가 설치되어 있는 경우 Mao, UC 및 기타 Alibaba 기반 앱을 연 후 다른 Alibaba 기반 앱을 실행할 수 있습니다. (Alibaba를 예로 들자면 사실 BAT 시스템도 비슷합니다.) White keep-alive White keep-alive 방법은 매우 간단합니다. 시스템 API를 호출하여 포그라운드 서비스 프로세스를 시작하는 것입니다. 현재 앱이 백그라운드로 돌아가더라도 사용자에게 해당 앱이 실행 중임을 알리기 위해 시스템 알림 표시줄에 알림을 생성합니다. LBE 및 QQ Music에 대해 아래와 같이 표시됩니다. Gray keep-alive Gray Keep-alive 방식은 가장 널리 사용되는 방식으로, 시스템 취약점을 이용해 포그라운드 서비스 프로세스를 시작합니다. 일반적인 시작 방식과 다른 점은 시스템 알림 표시줄에 알림으로 표시되지 않는다는 점입니다. 이는 백그라운드 서비스 프로세스가 실행 중인 것처럼 보입니다. 이것의 장점은 사용자가 포그라운드 프로세스를 실행하고 있음을 감지할 수 없지만(알림을 볼 수 없기 때문에) 프로세스 우선순위가 일반 백그라운드 프로세스보다 높다는 것입니다. 따라서 시스템의 취약점을 활용하는 방법, 일반적인 구현 아이디어 및 코드는 다음과 같습니다. 아이디어 1: API 아이디어 2: API >= 18, 동일한 ID로 두 개의 프런트 엔드 서비스를 동시에 시작하고 나중에 시작된 서비스를 중지합니다 안드로이드 시스템에 익숙한 아동용 신발은 모두 아시다시피 경험과 성능을 위해 시스템은 앱이 백그라운드로 돌아갈 때 실제로 프로세스를 종료하지는 않지만 캐시합니다. 더 많은 앱을 열수록 더 많은 프로세스가 백그라운드에 캐시됩니다. 시스템 메모리가 부족하면 시스템은 필요한 앱을 제공하기 위해 메모리를 확보하기 위해 자체 프로세스 재활용 메커니즘 세트를 기반으로 종료할 프로세스를 결정하기 시작합니다. 프로세스를 종료하고 메모리를 회수하는 이 메커니즘을 Low Memory Killer라고 합니다. 이는 Linux 커널의 OOM Killer(메모리 부족 킬러) 메커니즘을 기반으로 합니다. 프로세스의 중요성은 5단계로 나뉩니다: 포그라운드 프로세스 가시적 프로세스 서비스 프로세스 백그라운드 프로세스 빈 프로세스 ) Low Memory Killer를 이해한 후 oom_adj에 대해 자세히 알아보겠습니다. oom_adj란 무엇인가요? 이는 Linux 커널이 각 시스템 프로세스에 할당한 값으로, 프로세스의 우선순위를 나타냅니다. 프로세스 재활용 메커니즘은 이 우선순위에 따라 재활용할지 여부를 결정합니다. oom_adj의 역할과 관련하여 다음 사항만 기억하면 됩니다. 프로세스의 oom_adj가 클수록 프로세스의 우선 순위가 낮아지고, oom_adj가 작을수록 프로세스가 더 쉽게 종료되고 재활용됩니다. 프로세스의 oom_adj만 일부 모바일에서는 oom_adj가 일 수 있습니다. 휴대폰 제조업체는 이러한 잘 알려진 앱을 자체 화이트리스트에 넣어 프로세스가 중단되지 않고 사용자 경험을 향상할 수 있도록 했습니다(예: WeChat, QQ 및 Momo는 모두 Xiaomi의 화이트리스트에 있습니다). 화이트리스트에서 삭제되더라도 일반 앱처럼 죽는 운명을 피할 수는 있겠지만, 최대한 죽지 않으려면 정직하게 최적화 작업을 하는 것이 좋습니다. 따라서 프로세스를 유지하는 근본적인 해결책은 결국 성능 최적화로 돌아옵니다. 결국 프로세스의 불멸성은 완전한 잘못된 제안입니다! 8. 컨텍스트 설명 컨텍스트는 추상 기본 클래스입니다. 컨텍스트로 번역하면 일부 프로그램의 실행 환경에 대한 기본 정보를 제공하는 환경으로도 이해할 수 있습니다. Context 아래에는 두 개의 하위 클래스가 있습니다. ContextWrapper는 컨텍스트 함수의 캡슐화 클래스이고 ContextImpl은 컨텍스트 함수의 구현 클래스입니다. ContextWrapper에는 ContextThemeWrapper, Service 및 Application의 세 가지 직접 하위 클래스가 있습니다. 그 중 ContextThemeWrapper는 테마가 있는 패키지 클래스이고, 그 직계 하위 클래스 중 하나가 Activity이므로 Activity, Service, Application의 Context가 다르기 때문에 Activity에만 테마가 필요하고 Service에는 테마가 필요하지 않습니다. 컨텍스트에는 애플리케이션, 활동, 서비스의 세 가지 유형이 있습니다. 이 세 가지 클래스는 서로 다른 역할을 수행하지만 모두 Context 유형에 속하며 특정 Context 기능은 ContextImpl 클래스에 의해 구현됩니다. 따라서 대부분의 시나리오에서 Activity, Service 및 Application 이 세 가지 유형의 Context는 모두 보편적입니다. 그러나 활동 시작 및 대화 상자 팝업과 같은 몇 가지 특수 시나리오가 있습니다. 보안상의 이유로 Android는 활동이나 대화 상자가 갑자기 나타나는 것을 허용하지 않습니다. 활동의 시작은 이에 의해 형성된 반환 스택인 다른 활동을 기반으로 해야 합니다. 대화 상자는 활동에 팝업되어야 하므로(시스템 경고 유형 대화 상자가 아닌 경우) 이 시나리오에서는 활동 유형 컨텍스트만 사용할 수 있습니다. 그렇지 않으면 오류가 발생합니다. getApplicationContext() 및 getApplication() 메소드로 얻은 객체는 동일한 애플리케이션 객체이지만 객체 유형이 다릅니다. 컨텍스트 수 = 활동 수 + 서비스 수 + 1(1은 애플리케이션) 9. 활동, 뷰, 창 간의 관계 이해 이 질문은 정말 대답하기 어렵습니다. 그래서 여기에 그들의 관계를 설명하는 데 더 적절한 비유가 있습니다. Activity는 장인(제어 장치)과 같고, Window는 창(모델을 운반하는 것)과 같으며, View는 창 그릴과 같으며(뷰를 표시하는 것), LayoutInflater는 가위와 같으며, Xml 구성은 창 그릴 그림과 같습니다. 1: Activity가 생성되면 Window, 정확하게는 PhoneWindow가 초기화됩니다. 2: 이 PhoneWindow에는 "ViewRoot"가 있고, 이 "ViewRoot"는 초기 루트 뷰인 View 또는 ViewGroup입니다. 3: "ViewRoot"는 addView 메소드를 통해 뷰를 하나씩 추가합니다. 예를 들어 TextView, Button 등이 있습니다. 4: 이러한 뷰의 이벤트 모니터링은 WindowManagerService에서 수행되어 메시지를 수신하고 Activity 함수를 콜백합니다. 예를 들어 onClickListener, onKeyDown 등이 있습니다. 10. 네 가지 LaunchMode 및 해당 사용 시나리오 여기서 확장: 스택(선입 선출)과 대기열(선입 선출)의 차이점 스택과 대기열의 차이점: 1. out , 스택은 먼저 들어오고 마지막에 나옵니다 2. 삽입 및 삭제 작업에 대한 "제한 사항". 스택은 삽입 및 삭제 작업을 목록의 한쪽 끝으로만 제한하는 선형 목록입니다. 대기열은 테이블의 한쪽 끝으로 삽입을 제한하고 다른 쪽 끝으로 삭제를 제한하는 선형 목록입니다. 3. 데이터 이동 속도가 다릅니다. 표준 모드 액티비티가 활성화될 때마다 액티비티 인스턴스가 생성되어 작업 스택에 배치됩니다. 사용 시나리오: 대부분의 활동. singleTop 모드 작업 스택의 최상위에 Activity 인스턴스가 있으면 해당 인스턴스가 재사용되고(인스턴스의 onNewIntent()가 호출됨), 그렇지 않으면 새 인스턴스가 생성되어 배치됩니다. 이미 스택에 있더라도 스택 상단에 이 활동의 인스턴스가 있습니다. 스택 상단에 있지 않은 한 새 인스턴스가 생성됩니다. 사용 시나리오에는 뉴스 콘텐츠 페이지나 독서 앱이 포함됩니다. singleTask 모드 스택에 Activity의 인스턴스가 이미 있으면 해당 인스턴스가 재사용됩니다(인스턴스의 onNewIntent()가 호출됩니다). 재사용되면 인스턴스가 스택의 맨 위로 반환되므로 그 위에 있는 인스턴스는 스택에서 제거됩니다. 스택에 인스턴스가 없으면 새 인스턴스가 생성되어 스택에 배치됩니다. 사용 시나리오에는 브라우저의 기본 인터페이스가 포함됩니다. 브라우저를 시작하는 애플리케이션 수에 관계없이 기본 인터페이스는 한 번만 시작됩니다. 다른 경우에는 onNewIntent가 사용되고 기본 인터페이스의 다른 페이지가 지워집니다. singleInstance 모드 새 스택에 Activity 인스턴스를 생성하고 여러 애플리케이션이 스택의 Activity 인스턴스를 공유하도록 합니다. 이 모드의 활동 인스턴스가 이미 스택에 존재하면 활동을 활성화하는 모든 애플리케이션은 스택의 인스턴스를 재사용합니다(인스턴스의 onNewIntent()가 호출됨). 이 효과는 누가 활동을 활성화하든 관계없이 하나의 애플리케이션을 공유하는 여러 애플리케이션과 동일합니다. 알람 알림과 같은 시나리오를 사용하여 알람 알림을 알람 설정과 분리하세요. 중간 페이지에 SingleInstance를 사용하지 마세요. 중간 페이지에 사용하면 A -> B(singleInstance) -> C와 같은 점프 문제가 발생합니다. 완전히 종료한 후 여기에서 시작하면 B가 먼저 열립니다. . 11. 그리기 프로세스 보기 사용자 정의 컨트롤: 1. 이러한 종류의 사용자 정의 컨트롤은 우리가 직접 그릴 필요가 없고 기본 컨트롤로 구성된 새로운 컨트롤입니다. 제목 표시줄 등. 2. 원래 컨트롤을 상속받습니다. 이러한 종류의 사용자 정의 컨트롤은 기본 컨트롤에서 제공하는 메서드 외에 자체적으로 일부 메서드를 추가할 수 있습니다. 모서리를 둥글게 만들고 원형 그림을 만드는 것과 같은 것입니다. 3. 완전히 맞춤화된 컨트롤: 이 뷰에 표시되는 모든 콘텐츠는 직접 그린 것입니다. 예를 들어 물 잔물결 진행 표시줄을 만들어 보세요. 뷰 그리기 과정: OnMeasure()——>OnLayout()——>OnDraw() 1단계: OnMeasure(): 뷰의 크기를 측정합니다. 측정 메서드는 최상위 상위 뷰에서 하위 뷰로 재귀적으로 호출되고 측정 메서드는 OnMeasure를 다시 호출합니다. 2단계: OnLayout(): 보기 위치를 결정하고 페이지 레이아웃을 지정합니다. 최상위 상위 View에서 하위 View로 view.layout 메소드를 반복적으로 호출하는 프로세스는 상위 View가 하위 View를 측정하여 얻은 레이아웃 크기 및 레이아웃 매개변수를 기반으로 하위 View를 적절한 위치에 배치한다는 것을 의미합니다. 이전 단계. 3단계: OnDraw(): 뷰를 그립니다. ViewRoot는 Canvas 객체를 생성한 다음 OnDraw()를 호출합니다. 6단계: ①, 뷰의 배경 그리기, ②, 캔버스 레이어 저장(레이어), ③, 뷰의 내용 그리기, 그렇지 않은 경우에는 사용하지 마세요. ⑤, 레이어(Layer) )를 복원하고, 스크롤바를 그립니다. 12. View, ViewGroup 이벤트 분류 1. Touch 이벤트 배포에는 ViewGroup과 View 두 가지 주체가 있습니다. ViewGroup에는 onInterceptTouchEvent, dispatchTouchEvent 및 onTouchEvent라는 세 가지 관련 이벤트가 포함되어 있습니다. View에는 두 가지 관련 이벤트(dispatchTouchEvent 및 onTouchEvent)가 포함되어 있습니다. 그 중 ViewGroup은 View를 상속받습니다. 2. ViewGroup과 View는 트리 구조를 형성하며, 루트 노드는 Activity 내에 포함된 ViwGroup입니다. 3. 터치 이벤트는 Action_Down, Action_Move, Aciton_UP으로 구성됩니다. 완전한 터치 이벤트에는 Down과 Up이 하나만 있고 Move는 여러 개 있으며 0이 될 수 있습니다. 4. Activty는 Touch 이벤트를 수신하면 하위 뷰를 순회하여 Down 이벤트를 배포합니다. ViewGroup 순회는 재귀적으로 볼 수 있습니다. 배포의 목적은 이 전체 터치 이벤트를 실제로 처리하는 보기를 찾는 것입니다. 이 보기는 onTouchuEvent 결과에서 true를 반환합니다. 5. 하위 뷰가 true를 반환하면 Down 이벤트 배포가 중지되고 하위 뷰가 ViewGroup에 기록됩니다. 후속 Move 및 Up 이벤트는 하위 뷰에서 직접 처리됩니다. 하위 View는 ViewGroup에 저장되므로 다층 ViewGroup 노드 구조에서는 상위 ViewGroup은 실제로 이벤트를 처리하는 View가 위치한 ViewGroup 객체를 저장합니다. 예를 들어 ViewGroup0-ViewGroup1 구조에서 -TextView, TextView는 true를 반환하여 ViewGroup1에 저장되고, ViewGroup1도 true를 반환하여 ViewGroup0에 저장됩니다. Move 및 UP 이벤트가 발생하면 먼저 ViewGroup0에서 ViewGroup1로 전달된 다음 ViewGroup1에서 TextView로 전달됩니다. 6. ViewGroup의 모든 하위 뷰가 Down 이벤트를 캡처하지 않으면 ViewGroup 자체의 onTouch 이벤트가 트리거됩니다. 트리거하는 방법은 상위 클래스 View의 dispatchTouchEvent 메서드인 super.dispatchTouchEvent 함수를 호출하는 것입니다. 모든 하위 뷰가 처리되지 않으면 Activity의 onTouchEvent 메서드가 트리거됩니다. 7.onInterceptTouchEvent에는 두 가지 기능이 있습니다. 1. Down 이벤트 배포를 차단합니다. 2. 대상 뷰가 위치한 ViewGroup이 Up 및 Move 이벤트를 캡처하도록 대상 뷰에 대한 Up 및 Move 이벤트 전달을 중지합니다. 13. 활동 상태 저장 onSaveInstanceState(Bundle)은 활동이 백그라운드 상태로 들어가기 전, 즉 onStop() 메서드 이전과 onPause 메서드 이후에 호출됩니다. 14. Android의 여러 애니메이션 프레임; 애니메이션 : 듣고 싶은 리듬바 등 각 프레임의 영상과 재생시간을 지정하고 순서대로 재생하여 형성된 애니메이션 효과를 말합니다. Tween 애니메이션: 애니메이션 효과를 형성하기 위해 뷰의 초기 상태, 변경 시간 및 방법을 지정하여 일련의 알고리즘을 통해 그래픽을 변환하는 것을 말합니다. 주로 알파, 크기 조정, 이동 및 회전의 네 가지 효과가 있습니다. 참고: 애니메이션 효과는 뷰 레이어에서만 구현되며 목록 슬라이딩, 제목 표시줄 투명도 변경 등 뷰의 속성을 실제로 변경하지 않습니다. 속성 애니메이션: Android 3.0에서만 지원됩니다. 애니메이션 효과는 뷰의 속성을 지속적으로 변경하고 다시 그려서 형성됩니다. 뷰 애니메이션과 비교하면 뷰의 속성이 실제로 변경됩니다. 예를 들어 뷰 회전, 확대, 축소 등이 있습니다. 15. Android에서 프로세스 간 통신을 수행하는 여러 가지 방법 Intent, contentProvider, Broadcast 및 Service와 같은 Android 크로스 프로세스 통신은 모두 프로세스 간에 통신할 수 있습니다. intent: 이 크로스 프로세스 방법은 메모리 액세스 형식이 아닙니다. 전화 통화와 같이 URI를 전달해야 합니다. contentProvider: 이 양식은 데이터 공유를 위해 데이터 공유를 사용합니다. service: 원격 서비스,aidl broadcast 16. AIDL 이해 Extension here: Binder에 대한 간략한 설명 AIDL: 각 프로세스에는 자체 Dalvik VM 인스턴스와 자체 독립 메모리가 있습니다. 자신의 기억 속에 자신의 작업을 수행하고, 자신의 작은 공간에서 평생을 보냅니다. Aidl은 두 프로세스 간 데이터 전송을 허용하는 브리지와 같습니다. BroadcastReceiver, Messenger 등과 같은 프로세스 간 통신을 위한 다양한 옵션이 있지만 BroadcastReceiver는 빈번하게 교차하는 경우 더 많은 시스템 리소스를 차지합니다. 프로세스 통신은 분명히 바람직하지 않습니다. 메신저가 프로세스 간 통신을 수행할 때 요청 큐는 동기적으로 수행되며 동시에 실행될 수 없습니다. 바인드 메커니즘에 대한 간단한 이해: 안드로이드 시스템의 바인더 메커니즘에서는 사용자 공간에서 실행되는 클라이언트, 서비스, 서비스 관리자 및 바인더 드라이버로 구성됩니다. 드라이버는 커널에서 실행됩니다. 바인더는 이 네 가지 구성 요소를 하나로 묶는 접착제입니다. 핵심 구성 요소는 서비스 관리자로 보조적인 관리 기능을 제공하며, 클라이언트와 서비스는 바인더 드라이버와 서비스 관리자를 기반으로 시설 내에서 통신을 구현합니다. 바인더 드라이버는 사용자 컨트롤과 상호 작용하기 위해 장치 파일 /dev/binder를 제공합니다. 클라이언트, 서비스 및 서비스 관리자는 해당 열기 및 ioctl 파일 작업 방법을 통해 바인더 드라이버와 통신합니다. 클라이언트와 서비스 간의 프로세스 간 통신은 바인더 드라이버를 통해 간접적으로 구현됩니다. 바인더 관리자는 서비스를 관리하고 클라이언트에게 서비스 인터페이스를 쿼리할 수 있는 기능을 제공하는 데몬 프로세스입니다. 17. 핸들러의 원리 Android의 메인 스레드는 시간이 많이 걸리는 작업을 수행할 수 없으며 하위 스레드는 UI를 업데이트할 수 없습니다. 따라서 스레드 간의 통신을 구현하는 역할을 하는 핸들러가 있습니다. Handler 전체 프로세스에는 주로 Handler, Message, MessageQueue 및 Looper의 네 가지 개체가 있습니다. 애플리케이션이 생성되면 메인 스레드에 핸들러 객체가 생성됩니다. 메시지에 보낼 메시지를 저장합니다. 핸들러는 sendMessage 메소드를 호출하여 메시지를 MessageQueue로 보냅니다. loop( ) 메소드 는 지속적으로 MessageQueue에서 메시지를 가져와 처리를 위해 핸들러에 전달합니다. 이를 통해 스레드 간의 통신이 가능해집니다. 18. 바인더 메커니즘의 원리 안드로이드 시스템의 바인더 메커니즘에서는 클라이언트, 서비스, 서비스 관리자로 구성되어 사용자 공간에서 실행되며 바인더 드라이버가 실행됩니다. 커널에서. 바인더는 이 네 가지 구성 요소를 하나로 묶는 접착제입니다. 핵심 구성 요소는 서비스 관리자로 보조적인 관리 기능을 제공하며, 클라이언트와 서비스는 바인더 드라이버와 서비스 관리자를 기반으로 시설 내에서 통신을 구현합니다. 바인더 드라이버는 사용자 컨트롤과 상호 작용하기 위해 장치 파일 /dev/binder를 제공합니다. 클라이언트, 서비스 및 서비스 관리자는 해당 열기 및 ioctl 파일 작업 방법을 통해 바인더 드라이버와 통신합니다. 클라이언트와 서비스 간의 프로세스 간 통신은 바인더 드라이버를 통해 간접적으로 구현됩니다. 바인더 관리자는 서비스를 관리하고 클라이언트에게 서비스 인터페이스를 쿼리할 수 있는 기능을 제공하는 데몬 프로세스입니다. 19. 핫 복구의 원리 우리는 Java 가상 머신인 JVM이 클래스의 클래스 파일을 로드하는 반면 Android 가상 머신인 Dalvik/ART VM은 클래스의 dex 파일을 로드한다는 것을 알고 있습니다. ClassLoader 클래스 로드는 항상 필요합니다. ClassLoader에는 하위 클래스 BaseDexClassLoader가 있으며 BaseDexClassLoader - DexPathList 아래에 dex 파일을 저장하는 데 사용되는 배열이 있습니다. BaseDexClassLoader가 findClass 메서드를 호출하면 실제로 배열을 탐색하여 해당 dex 파일을 찾습니다. , 발견되면 직접 반환하세요. 핫 리페어에 대한 해결책은 컬렉션에 새로운 덱스를 추가하는 것인데, 기존 덱스보다 앞에 있으므로 먼저 꺼내서 반납하게 된다. 20. 안드로이드 메모리 누수 및 관리 (1) 메모리 오버플로(OOM)와 메모리 누수(객체를 재활용할 수 없음)의 차이점. (2) 메모리 누수의 원인 (3) 메모리 누수 감지 도구------>LeakCanary Memory Overflow out of memory: 프로그램이 메모리를 적용할 때 메모리 공간이 충분하지 않음을 의미합니다. 예를 들어 정수를 적용했지만 long에만 저장할 수 있는 숫자를 저장하면 메모리 오버플로가 발생합니다. 평신도의 관점에서 메모리 오버플로는 메모리가 충분하지 않음을 의미합니다. 메모리 누수: 프로그램이 메모리를 신청한 후 할당된 메모리 공간을 해제할 수 없음을 의미합니다. 메모리 누수로 인한 피해는 무시할 수 있지만, 메모리 누수가 아무리 많아도 그 결과는 심각합니다. 나중에는 꽉 차게 될 거예요 메모리 누수 원인: 1. 핸들러로 인한 메모리 누수. 해결책: Handler를 정적 내부 클래스로 선언하면 외부 클래스 SecondActivity에 대한 참조를 보유하지 않으며 수명 주기는 외부 클래스와 아무 관련이 없습니다. Handler에 컨텍스트가 필요한 경우 외부 클래스는 클래스는 약한 참조를 통해 참조될 수 있습니다 2. 싱글톤 모드로 인한 메모리 누수. 해결책: Context는 ApplicationContext입니다. ApplicationContext의 수명 주기는 앱과 일치하므로 메모리 누수가 발생하지 않습니다. 3. 비정적 내부 클래스의 정적 인스턴스 생성으로 인해 메모리 누수가 발생합니다. 해결책: 메모리 누수를 방지하려면 내부 클래스를 정적으로 수정하세요 4. 비정적 익명 내부 클래스로 인해 메모리 누수가 발생합니다. 해결책: 익명 내부 클래스를 정적으로 설정합니다. 5. 페어링되지 않은 등록/등록 해제 사용으로 인해 메모리 누수가 발생합니다. 방송 수신기, EventBus 등을 등록하고 바인딩을 해제하는 것을 잊지 마세요. 6. 리소스 개체가 닫히지 않아 메모리 누수가 발생합니다. 이러한 리소스를 사용하지 않을 때는 close(), destroy(), recycler(), release() 등과 같은 해당 메서드를 호출하여 해제하는 것을 잊지 마세요. 7. 수집 개체를 제때 정리하지 못해 메모리 누수가 발생합니다. 일반적으로 일부 개체는 컬렉션에 로드됩니다. 사용하지 않을 때는 관련 개체가 더 이상 참조되지 않도록 제때에 컬렉션을 정리해야 합니다. 21. Fragment가 Fragment 및 Activity와 통신하는 방법 1. 하나의 Fragment에서 다른 Fragment의 메서드를 직접 호출합니다 3. Fragment가 Activity 공개 메서드를 직접 호출합니다. 1. WebView의 loadUrl()을 사용하면 이 방법이 더 간단하고 편리합니다. 그러나 효율성이 상대적으로 낮고 반환 값을 얻기가 어렵습니다. 2. WebView의 estimateJavascript()를 통해 이 방법은 매우 효율적이지만 4.4 이상 버전에서만 지원되고 4.4 미만 버전에서는 지원되지 않습니다. 따라서 두 가지를 혼합하여 사용하는 것이 좋습니다. JS는 Android 코드를 호출합니다 1. WebView의 addJavascriptInterface()를 통해 객체 매핑을 수행합니다. 이 방법은 사용이 간단하고 Android 객체와 JS 객체만 매핑합니다. 취약점의 원인은 JS가 Android 개체를 가져오면 시스템 클래스(java.lang.Runtime 클래스)를 포함하여 Android 개체의 모든 메서드를 호출하여 임의의 코드를 실행할 수 있다는 것입니다. 해결책: (1) Google은 Android 4.2에서 취약점 공격을 방지하기 위해 호출된 함수에 @JavascriptInterface 주석을 달도록 규정하고 있습니다. (2) Android 4.2 버전 이전에는 Intercept Prompt()를 사용하여 취약점을 수정하세요. 2. WebViewClient의 shouldOverrideUrlLoading() 메소드 콜백을 통해 URL을 차단합니다. 이 방법의 장점: 방법 1에는 허점이 없습니다. 단점: JS가 Android 메서드의 반환 값을 가져오는 것이 복잡합니다. (ios는 주로 이 방법을 사용합니다) (1) 안드로이드는 WebViewClient의 shouldOverrideUrlLoading() 콜백 메소드를 통해 URL을 가로챕니다 (2) URL의 프로토콜을 파싱합니다 (3) 미리 합의된 프로토콜을 감지하면, 해당 메소드를 호출하기만 하면 됩니다 3. WebChromeClient의 onJsAlert(), onJsConfirm(), onJsPrompt() 메소드 콜백을 통해 JS 대화 상자 경고(), 확인(), 프롬프트() 메시지를 차단합니다. 이 메소드의 장점: 그렇지 않습니다. 메소드 1의 취약점 존재 단점: JS가 Android 메소드의 반환 값을 얻는 것이 복잡합니다. 26. JAVA GC 원리 가비지 수집 알고리즘의 핵심 아이디어는 가상 머신의 사용 가능한 메모리 공간, 즉 힙 공간에서 객체를 식별하는 것입니다. 살아있는 객체 , 그 반대의 경우도 마찬가지입니다. 객체가 더 이상 참조되지 않으면 가비지 객체이며, 객체가 차지하는 공간은 재할당을 위해 회수될 수 있습니다. 가비지 수집 알고리즘의 선택과 가비지 수집 시스템 매개변수의 합리적인 조정은 시스템 성능에 직접적인 영향을 미칩니다. 27, ANR ANR의 전체 이름은 Application Not Responding, 즉 "Application Not Responding"입니다. 일정 시간 내에 시스템에서 작업을 처리할 수 없는 경우 위와 같은 ANR 대화 상자가 나타납니다. 원인: (1) 5초 이내에 사용자 입력 이벤트(예: 키보드 입력, 터치 스크린 등)에 응답할 수 없습니다. (2) BroadcastReceiver가 10초 이내에 종료될 수 없습니다. 3) 20초 이내에 서비스가 종료되지 않습니다. (낮은 확률) 해결 방법: (1) 시간이 많이 걸리는 작업을 메인 스레드에서 수행하지 말고 하위 스레드에서 구현하십시오. 예를 들어 onCreate() 및 onResume()에서는 생성 작업을 가능한 한 적게 수행합니다. (2) 애플리케이션은 BroadcastReceiver에서 시간이 많이 걸리는 작업이나 계산을 수행하지 않아야 합니다. (3) 인텐트 수신기에서 활동을 시작하지 마세요. 새 화면이 생성되고 현재 사용자가 실행 중인 프로그램에서 포커스를 훔치게 되기 때문입니다. (4) 서비스는 메인 스레드에서 실행되므로 서비스에서 시간이 많이 걸리는 작업은 하위 스레드에 배치되어야 합니다. 28. 디자인 패턴 여기서 확장: Double Check를 작성해야 합니다. 싱글 케이스 모드: 나쁜 남자 스타일과 게으른 남자 스타일로 구분 나쁜 남자 스타일: 게으른 남자 스타일: 29, RxJava 30, MVP, MVC, MVVM 여기 확장: 손으로 쓴 mvp 예를 들어, mvp MVP 모드의 장점인 mvc와 mvp의 차이점은 Model에 해당합니다.-비즈니스 로직과 엔터티 모델, view-액티비티에 해당하고, View 그리기 및 사용자와의 상호 작용을 담당하는 Presenter- -View와 Model 사이의 상호 작용을 담당하는 MVP 모드는 MVC 모드를 기반으로 하며, Model과 View를 완전히 분리하여 프로젝트의 결합을 줄여줍니다. Mvc에서 프로젝트의 활동은 C-에 해당합니다. - mvc의 Controller, 그리고 프로젝트의 논리적 처리는 이 C에서 처리하며, View와 Model 간의 상호 작용, 즉 MVC의 모든 논리적 상호 작용과 사용자 상호 작용은 Controller, 즉 Activity에 배치됩니다. 뷰와 모델은 직접 통신할 수 있습니다. MVP 모델은 더욱 완벽하게 분리되어 업무 구분이 더 명확해졌습니다. 모델(비즈니스 로직과 엔터티 모델, 뷰)은 사용자와의 상호 작용을 담당하고, 프레젠터는 뷰와 모델 간의 상호 작용을 완료하는 역할을 담당합니다. MVC는 MVC에서 Model과 View의 상호 작용을 허용하며 MVP에서는 Model과 View 간의 상호 작용이 Presenter에 의해 완료된다는 것이 분명합니다. 또 다른 점은 Presenter와 View 간의 상호 작용이 인터페이스를 통해 이루어진다는 것입니다. 31. 필기 알고리즘(버블링 선택 방법을 알아야 함) 32. JNI (1) Cygwin 설치 및 다운로드, Android NDK 다운로드 ( 2 ) ndk 프로젝트의 JNI 인터페이스 설계 (3) C/C++를 사용하여 로컬 메서드 구현 (4) JNI가 동적 링크 라이브러리 .so 파일 생성 (5) 호출에서 동적 링크 라이브러리를 Java 프로젝트에 복사 33. RecyclerView와 ListView의 차이점 RecyclerView는 ListView와 GridView의 효과를 완성할 수 있고, Waterfall Flow의 효과도 완성할 수 있습니다. 동시에 목록의 스크롤 방향(세로 또는 가로)을 설정할 수도 있습니다. RecyclerView에서 뷰를 재사용하려면 개발자가 자신의 코드를 작성할 필요가 없으며 시스템이 이미 코드를 패키지해 놓았습니다. RecyclerView는 부분 새로 고침을 수행할 수 있습니다. RecyclerView는 아이템 애니메이션 효과를 구현하기 위한 API를 제공합니다. 성능 측면에서: 데이터를 자주 새로 고치고 애니메이션을 추가해야 하는 경우 RecyclerView가 더 큰 이점을 갖습니다. 그냥 목록으로 표시한다면 둘의 차이는 그리 크지 않습니다. 34. Universal-ImageLoader, Picasso, Fresco 및 Glide 비교 Fresco는 Facebook에서 출시한 오픈 소스 이미지 캐싱 도구입니다. 주요 기능은 다음과 같습니다. 두 개의 메모리 캐시와 기본 캐시가 3단계 캐시를 구성합니다. : 1. 사진은 가상 머신의 힙 메모리 대신 Android 시스템의 익명 공유 메모리에 저장됩니다. 사진의 중간 버퍼 데이터도 로컬 힙 메모리에 저장됩니다. OOM을 발생시키고, Bitmap을 재활용하기 위한 가비지 컬렉터의 빈번한 호출로 인해 발생하는 인터페이스 지연을 줄여 성능을 향상시킵니다. 2. JPEG 이미지의 점진적 로딩으로 흐린 이미지에서 선명한 이미지 로딩을 지원합니다. 3. 그림은 그림 중앙뿐만 아니라 어떤 중앙 지점에서도 ImageView에 표시될 수 있습니다. 4. JPEG 이미지의 크기 변경도 가상 머신의 힙 메모리가 아닌 기본에서 수행되므로 OOM도 줄어듭니다. 5. GIF 이미지 표시를 매우 잘 지원합니다. 단점: 1. 프레임워크가 커서 APK 크기에 영향을 미칩니다. 2. 사용이 번거롭습니다. Universal-ImageLoader: (Google에서 HttpClient를 포기했기 때문에 작성자가 유지 관리를 포기한 것으로 추정됩니다. 이 프레임워크) 장점: 1. 다운로드 진행률 모니터링 지원 2. 보기 스크롤 중에 이미지 로드를 일시 중지할 수 있으며, PauseOnScrollListener 인터페이스를 통해 보기 스크롤 중에 이미지 로드를 일시 중지할 수 있습니다. 3. 이러한 이미지 캐시는 모두 캐싱 알고리즘으로 구성할 수 있지만 ImageLoader는 기본적으로 가장 큰 크기 먼저 삭제, 가장 적게 사용한 항목 삭제, 가장 최근에 사용한 항목부터 삭제 등 다양한 캐싱 알고리즘을 기본적으로 구현합니다. . , 가장 긴 것을 먼저 삭제하십시오. 4. 로컬 캐시 파일 이름 규칙 정의 지원 Picasso의 장점 1. 캐시 적중률, 사용된 메모리 크기, 저장된 트래픽 등을 포함한 이미지 캐시 사용량 모니터링을 지원합니다. 2. 우선순위 처리를 지원합니다. 각 작업을 예약하기 전에 우선 순위가 더 높은 작업이 선택됩니다. 예를 들어 앱 페이지의 배너 우선 순위가 아이콘의 우선 순위보다 높을 때 매우 적합합니다. 3. 이미지 크기 계산이 완료되고 로딩될 때까지의 지연 지원 4. 비행 모드를 지원하며, 네트워크 유형에 따라 동시 스레드 수가 변경됩니다. 전화기가 비행기 모드로 전환되거나 네트워크 유형이 변경되면 스레드 풀의 최대 동시성 수가 자동으로 조정됩니다. 예를 들어 Wi-Fi의 최대 동시성 수는 4, 4g는 3, 3g는 2입니다. 여기서 Picasso는 CPU 코어 수가 아닌 네트워크 유형을 기반으로 최대 동시성 수를 결정합니다. 5. "없음" 로컬 캐시. "아니요" 로컬 캐시가 없다는 것은 로컬 캐시가 없다는 것을 의미하지는 않지만 Picasso 자체가 이를 구현하지 않고 이를 구현하기 위해 Square의 다른 네트워크 라이브러리인 okhttp에 넘겼습니다. 이것의 장점은 이미지를 제어할 수 있다는 것입니다. Response Header에서 Cache-Control 및 Expired를 요청하여 Glide의 장점 1. Glide는 이미지 캐시뿐만 아니라 Gif, WebP도 지원합니다. 썸네일 및 비디오까지 미디어 캐시로 사용해야 합니다. 2. 우선순위 처리 지원 3. TrimMemory는 각 컨텍스트에 대해 RequestManager를 유지하고 일관성을 유지합니다. Activity/Fragment 라이프 사이클을 통해 호출에 대해 TrimMemory 인터페이스 구현이 가능합니다. 4. Glide는 기본적으로 UrlConnection을 통해 데이터를 얻고 okhttp 또는 Volley와 함께 사용할 수 있습니다. 메모리 캐시는 활성 설계를 가지고 있습니다. 메모리 캐시에서 데이터를 가져올 때 일반 구현에서는 get을 사용하는 대신 제거를 사용하고 캐시된 데이터는 값이 소프트 참조인 activeResources 맵에 저장됩니다. 참조 개수는 이미지가 로드된 후에 판단됩니다. 참조 개수가 비어 있으면 메모리가 더 작은 이미지를 캐시합니다. Glide는 url, view_width, view_height, 화면 해상도 등을 캐시에 사용합니다. 메모리 캐시에서 처리된 이미지는 원본 이미지 대신 크기가 Activity/Fragment 수명 주기와 일치합니다. TrimMemory는 기본적으로 ARGB_888 대신 RGB_565로 설정됩니다. ARGB_888로 구성할 수도 있습니다. 6. Glide는 서명을 통해 또는 로컬 캐시를 사용하지 않고 URL 만료를 지원할 수 있습니다 42. Xutils, OKhttp, Volley, Retrofit 비교 Xutils는 네트워크 요청, 이미지 로딩을 수행할 수 있는 매우 포괄적인 프레임워크입니다. 이 프레임워크를 사용하면 매우 편리하지만 단점도 매우 분명합니다. 이 프레임워크에 문제가 생기면 프로젝트가 이 프레임워크에 크게 의존하게 됩니다. , 프로젝트에 큰 영향을 미칠 것입니다. , OKhttp: Android 개발에서는 기성 API를 직접 사용하여 네트워크 요청을 할 수 있습니다. 작동하려면 HttpClient 및 HttpUrlConnection을 사용하면 됩니다. Java 및 Android 프로그램의 경우 okhttp는 동기화 및 비동기성을 지원하는 고성능 http 요청 라이브러리를 캡슐화합니다. 또한 okhttp는 스레드 풀, 데이터 변환, 매개변수 사용, 오류 처리 등도 캡슐화합니다. API를 사용하는 것이 더 편리합니다. 하지만 프로젝트에서 사용할 때는 더 원활하게 사용할 수 있도록 캡슐화 레이어를 직접 만들어야 합니다. Volley: Volley는 Google에서 공식적으로 제작한 작고 정교한 비동기 요청 라이브러리 세트입니다. 프레임워크는 확장성이 뛰어나고 HttpClient, HttpUrlConnection 및 심지어 OkHttp도 지원하며 Volley는 ImageLoader도 캡슐화하므로 원할 경우 그럴 필요가 없습니다. 이미지 로딩 프레임워크를 사용해야 할 수도 있지만 이 기능은 일부 특수한 이미지 로딩 프레임워크만큼 강력하지는 않습니다. 단순한 요구 사항에는 사용할 수 있지만 더 복잡한 요구 사항에는 여전히 특수한 이미지 로딩 프레임워크를 사용해야 합니다. 발리 역시 포스트 빅데이터를 지원하지 않는 등의 단점이 있어 파일 업로드에는 적합하지 않다. 그러나 Volley 설계 자체의 원래 의도는 작은 데이터 볼륨으로 빈번한 네트워크 요청을 위한 것입니다. Retrofit: Retrofit은 기본적으로 OkHttp 캡슐화를 기반으로 Square에서 제작한 RESTful 네트워크 요청 프레임워크입니다. RESTful은 현재 널리 사용되는 API 디자인 스타일이며 표준이 아닙니다. Retrofit의 캡슐화는 매우 강력하다고 할 수 있습니다. 요청은 주석을 통해 직접 구성할 수 있습니다. 기본적으로 http가 사용되지만 데이터를 직렬화하는 데는 다른 Json 변환기를 사용할 수 있습니다. 동시에 Retrofit + OkHttp + RxJava + Dagger2를 사용하여 RxJava에 대한 지원을 제공합니다. 이는 현재 비교적 유행하는 프레임워크라고 할 수 있지만 상대적으로 높은 임계값이 필요합니다. Volley VS OkHttp Volley의 장점은 더 잘 캡슐화된다는 것입니다. 반면 OkHttp를 사용하려면 다시 캡슐화할 수 있는 충분한 능력이 필요합니다. OkHttp의 장점은 성능이 높다는 것입니다. OkHttp는 NIO와 Okio를 기반으로 하기 때문에 Volley보다 성능이 빠릅니다. IO와 NIO는 모두 Java의 개념입니다. 하드 디스크에서 데이터를 읽는 경우 첫 번째 방법은 작업을 계속하기 전에 데이터를 읽을 때까지 기다리는 것입니다. 한 가지 방법은 IO 차단이라고도 합니다. 데이터를 읽으면 프로그램이 계속 실행되며, 데이터가 처리된 후 나에게 알리고 콜백을 처리합니다. 두 번째 방법은 Non-Blocking인 NIO이므로 당연히 NIO가 IO보다 성능이 좋습니다. Okio는 IO와 NIO를 기반으로 Square에서 만든 라이브러리로 데이터 스트림 처리가 더 간단하고 효율적입니다. 이론적으로 Volley를 OkHttp와 비교하면 Volley를 사용하는 경향이 더 큽니다. 왜냐하면 Volley는 내부적으로 OkHttp 사용도 지원하므로 OkHttp의 성능 이점은 사라지고 Volley 자체는 사용하기 쉽게 패키징되고 확장성이 더 좋기 때문입니다. OkHttp VS Retrofit Retrofit이 기본적으로 OkHttp를 기반으로 하는 패키지라는 점은 의심의 여지가 없으며 Retrofit이 확실히 선호됩니다. Volley VS Retrofit 두 라이브러리 모두 잘 캡슐화되어 있지만 특히 Retrofit 2.0이 출시되면서 Jake는 이전 1.0 디자인의 불합리한 부분을 많이 리팩토링했으며 그의 책임은 더 커졌습니다. 자세히 설명되어 있으며 Retrofit은 기본적으로 OkHttp를 사용하므로 성능 측면에서 Volley보다 유리합니다. 또한 프로젝트가 RxJava를 사용하는 경우 Retrofit을 사용해야 합니다. 따라서 이 두 라이브러리에 비해 Retrofit은 더 많은 장점을 가지고 있습니다. 두 프레임워크를 모두 마스터할 수 있다면 먼저 Retrofit을 사용해야 합니다. 그러나 Retrofit의 임계값은 Volley보다 약간 높습니다. 그 원리와 다양한 용도를 이해하려면 약간의 노력이 필요하므로 상용 프로젝트에서는 Volley를 사용하는 것이 좋습니다. Java 1. 스레드에서 sleep과 wait의 차이점 (1) 이 두 메서드는 서로 다른 클래스에서 왔고, sleep은 Thread에서 오고, wait는 Object에서 옵니다. (2) sleep 메서드는 잠금 및 대기 메소드가 잠금을 해제합니다. (3) wait, inform, informAll은 동기화 제어 방법이나 동기화 제어 블록에서만 사용할 수 있는 반면 sleep은 어디에서나 사용할 수 있습니다. 2. Thread의 start() 메소드와 run() 메소드의 차이점은 무엇인가요? start() 메소드는 새로 생성된 스레드를 시작하는 데 사용되며 start()는 내부적으로 run() 메소드를 호출하는 방식입니다. run() 메서드를 직접 호출하는 것과는 다릅니다. run() 메서드를 직접 호출하면 일반 메서드와 다르지 않습니다. 3. 키워드 final 및 static을 사용하는 방법. 2. 최종 메서드는 하위 클래스로 재정의될 수 없습니다. 3. 최종 클래스는 상속할 수 없습니다. static: 1. 정적 변수: 메모리에 정적 변수 복사본이 하나만 있습니다(메모리 절약을 위해). JVM은 정적 변수에 대해 메모리를 한 번만 할당합니다. 정적 변수의 메모리 할당은 프로세스 중에 완료됩니다. 사용 가능한 클래스 이름으로 직접 액세스(편리함). 물론 객체를 통해 액세스할 수도 있습니다(권장하지는 않음). 2. 정적 코드 블록 정적 코드 블록은 클래스가 로드될 때 초기화 중에 자동으로 실행됩니다. 3. 정적 메서드 정적 메서드는 클래스 이름을 통해 직접 호출할 수 있으며, 모든 인스턴스도 호출할 수 있으므로 정적 메서드에서는 this 및 super 키워드를 사용할 수 없습니다. 자신이 속한 클래스의 인스턴스 변수와 인스턴스 메소드(즉, static이 없는 멤버 변수와 멤버 메소드)에는 직접 접근할 수 없으며, 자신이 속한 클래스의 static 멤버 변수와 멤버 메소드에만 접근할 수 있습니다. 4. String, StringBuffer 및 StringBuilder의 차이점 1. 세 가지의 실행 속도: StringBuilder > StringBuffer > String(String은 상수이고 변경할 수 없으므로 접합 중에 새 객체가 다시 생성됩니다.) ). 2. StringBuffer는 스레드로부터 안전하고 StringBuilder는 스레드로부터 안전하지 않습니다. (StringBuffer에는 버퍼가 있기 때문입니다) 5. Java에서 오버로딩과 다시 쓰기의 차이점: 1. 오버로딩: 클래스에는 동일한 이름을 가진 메서드가 여러 개 있을 수 있지만 매개 변수 유형과 번호가 다릅니다. 이것은 과부하입니다. 2. 재작성: 하위 클래스가 상위 클래스를 상속하는 경우 하위 클래스는 상위 클래스의 메서드를 구현할 수 있으므로 새 메서드가 상위 클래스의 이전 메서드를 덮어씁니다. 6. Http https 차이 여기서 확장: https 구현 원칙 1. https 프로토콜은 ca에서 인증서를 신청해야 합니다. 일반적으로 무료 인증서가 적으므로 특정 수수료가 필요합니다. 2. http는 하이퍼텍스트 전송 프로토콜이며 정보는 일반 텍스트로 전송되는 반면 https는 안전한 SSL 암호화 전송 프로토콜입니다. 3. http와 https는 전혀 다른 연결 방식을 사용하며, 전자는 80이고 후자는 443입니다. 4. http 연결은 매우 간단하고 상태가 없습니다. HTTPS 프로토콜은 암호화된 전송 및 ID 인증을 수행할 수 있는 SSL+HTTP 프로토콜로 구축된 네트워크 프로토콜이며 http 프로토콜보다 더 안전합니다. https 구현 원칙: (1) 고객은 https URL을 사용하여 웹 서버에 액세스하고 웹 서버와 SSL 연결을 설정해야 합니다. (2) 웹 서버는 클라이언트의 요청을 받은 후 웹사이트의 인증서 정보(인증서에는 공개 키가 포함되어 있음) 사본을 클라이언트에게 보냅니다. (3) 클라이언트의 브라우저와 웹 서버는 SSL 연결의 보안 수준, 즉 정보 암호화 수준을 협상하기 시작합니다. (4) 클라이언트의 브라우저는 양측이 합의한 보안 수준에 따라 세션 키를 설정한 후 웹 사이트의 공개 키를 사용하여 세션 키를 암호화하여 웹 사이트에 전송합니다. (5) 웹 서버는 자체 개인 키를 사용하여 세션 키를 해독합니다. (6) 웹 서버는 세션 키를 사용하여 클라이언트와의 통신을 암호화합니다. 7. TCP/IP 모델의 어느 계층에 HTTP가 위치하나요? HTTP가 신뢰할 수 있는 데이터 전송 프로토콜인 이유는 무엇입니까? tcp/ip의 5계층 모델: 아래에서 위로: 물리 계층->데이터 링크 계층->네트워크 계층->전송 계층->응용 계층 여기서 tcp/ip는 모델 동일한 계층에 있는 네트워크 계층은 ICMP(Network Control Message Protocol)입니다. http는 모델의 애플리케이션 계층에 위치합니다 tcp/ip는 안정적인 연결 지향 프로토콜이고 http는 전송 계층의 tcp/ip 프로토콜을 기반으로 하므로 http는 안정적인 데이터 전송 프로토콜입니다. 8. HTTP 링크의 특징 HTTP 연결의 가장 중요한 특징은 클라이언트가 보낸 각 요청이 요청이 완료된 후 서버에서 응답을 다시 보내야 한다는 것입니다. 연결 설정부터 연결 종료까지의 과정을 "하나의 연결"이라고 합니다. 9. TCP와 UDP tcp의 차이점은 연결 지향입니다. TCP 연결에는 세 번의 핸드셰이크가 필요하므로 위험을 최소화하고 연결의 안정성을 보장할 수 있습니다. udp는 연결 지향적이지 않습니다. UDP는 연결을 설정하기 전에 개체와 연결을 설정할 필요가 없습니다. 전송 중인지 수신 중인지 확인 신호가 전송되지 않습니다. 그래서 udp는 신뢰할 수 없습니다. UDP는 연결을 확인할 필요가 없기 때문에 UDP는 오버헤드가 적고 전송 속도가 높으므로 실시간 작동이 더 좋습니다. 10. 소켓이 네트워크 연결을 설정하는 단계 소켓 연결을 설정하려면 최소한 한 쌍의 소켓이 필요합니다. 그 중 하나는 클라이언트에서 실행되고, 다른 하나는 서버에서 실행됩니다. 1. 서버 모니터링: 서버 측 소켓은 특정 클라이언트 소켓을 찾아주는 것이 아니라 연결을 기다리는 상태로, 네트워크 상태를 실시간으로 모니터링하며 클라이언트의 연결 요청을 기다리는 상태이다. 2. 클라이언트 요청: 연결을 요청하는 클라이언트의 소켓을 말하며, 연결 대상은 서버의 소켓입니다. 참고: 클라이언트의 소켓은 연결하려는 서버의 소켓을 설명해야 하며, 서버 소켓의 주소와 포트 번호를 지정한 다음 서버 측 소켓과 마찬가지로 연결 요청을 해야 합니다. 3. 연결 확인: 서버 측 소켓이 클라이언트 소켓의 연결 요청을 모니터링하면 클라이언트 소켓의 요청에 응답하고 새 스레드를 설정하고 서버 측 소켓에 대한 설명을 작성합니다 보내기 클라이언트가 이 설명을 확인하면 두 당사자는 공식적으로 연결을 설정합니다. 서버 소켓은 계속 수신 대기 상태에 있으며 다른 클라이언트 소켓으로부터 연결 요청을 계속 수신합니다. 11. Tcp/IP 3방향 핸드셰이크, 4개의 파도 위 내용은 중급 및 고급 Android 면접 질문(답변 포함)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!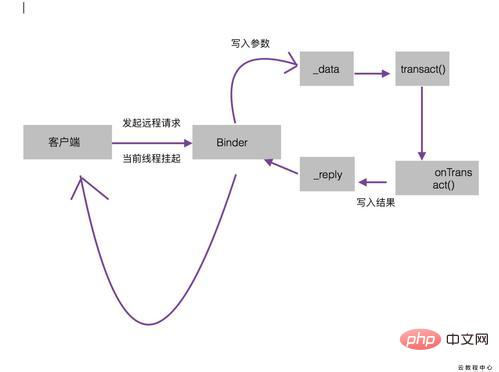
onLayout
Android의 성능 최적화
public class Singleton
{
private static Singleton instance = new Singleton();
public static Singleton getInstance()
{
return instance ;
}
}로그인 후 복사public class Singleton02
{
private static Singleton02 instance;
public static Singleton02 getInstance()
{
if (instance == null)
{
synchronized (Singleton02.class)
{
if (instance == null)
{
instance = new Singleton02();
}
}
}
return instance;
}
}로그인 후 복사
1. Final 변수는 상수이며 한 번만 할당할 수 있습니다.


















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



