

급하게 작성한 테스트케이스는 모두 실행 가능합니다. 하지만 메모리나 효율성을 고려하면 아직 개선이 필요한 부분이 많으니 많은 조언 부탁드립니다
# 🎜🎜#
이진 트리가 주어지면 루트 노드는 레벨 1이고 깊이는 1입니다. 값이 v인 노드 행을 d번째 수준에 추가합니다. 규칙 추가: 깊이 값 d(양의 정수)가 주어지면 깊이 d-1 레이어의 비어 있지 않은 각 노드 N에 대해 값 v와 오른쪽 하위 트리를 사용하여 두 개의 왼쪽 하위 트리를 만듭니다. N의 원래 왼쪽 하위 트리를 새 노드 v의 왼쪽 하위 트리에 연결 N의 원래 오른쪽 하위 트리를 새 노드 v 트리의 오른쪽 하위 트리에 연결합니다. . d의 값이 1이고 깊이 d - 1이 존재하지 않으면 새로운 루트 노드 v가 생성되고 원래 전체 트리는 v의 왼쪽 하위 트리 역할을 합니다.Example【관련 강좌 추천:
JavaScript 비디오 튜토리얼】
Input: A binary tree as following: 4 / \ 2 6 / \ / 3 1 5 v = 1d = 2Output: 4 / \ 1 1 / \ 2 6 / \ / 3 1 5
이진 트리의 선주문 순회
#🎜 🎜##🎜 🎜#최종 구조가 아니라 일반 구조/**
* @param {number} cd:current depth,递归当前深度
* @param {number} td:target depth, 目标深度
*/
var traversal = function (node, v, cd, td) {
// 递归到目标深度,创建新节点并返回
if (cd === td) {
// return 新节点
}
// 向左子树递归
if (node.left) {
node.left = traversal (node.left, v, cd + 1, td);
}
// 向右子树递归
if (node.right) {
node.right = traversal (node.right, v, cd + 1, td);
}
// 返回旧节点
return node;
};
/**
* Definition for a binary tree node.
* function TreeNode(val) {
* this.val = val;
* this.left = this.right = null;
* }
*/
/**
* @param {TreeNode} root
* @param {number} v
* @param {number} d
* @return {TreeNode}
*/
var addOneRow = function (root, v, td) {
// 从根节点开始递归
traversal (root, v, 1, td);
return root;
};로그인 후 복사
분류하고 세 가지 유형으로 나누어 논의한다. 상황 처리
처리 방법: val 노드는 깊이에 해당하는 대상 노드를 대체하고 ● 대상 노드가 원래 왼쪽 하위 트리인 경우 재설정 후 대상 노드는 val 노드
#의 왼쪽 하위 트리입니다. 🎜🎜#● 대상 노드가 원래 오른쪽 하위 트리인 경우 재설정 후 대상 노드는 Val 노드의 오른쪽 하위 트리입니다# 🎜🎜#Case 2: Target Depth> ;현재 재귀 경로의 최대 깊이
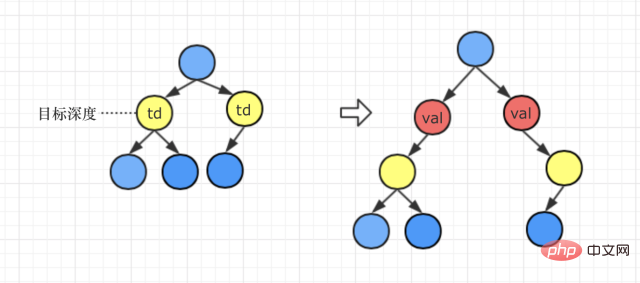 질문을 읽은 후 다음과 같은 설명이 있는 것을 발견했습니다. "입력 깊이의 범위 값 d는 다음과 같습니다: [1, 이진 트리의 최대 깊이 + 1]" #🎜 🎜#
질문을 읽은 후 다음과 같은 설명이 있는 것을 발견했습니다. "입력 깊이의 범위 값 d는 다음과 같습니다: [1, 이진 트리의 최대 깊이 + 1]" #🎜 🎜#
하단 레이어 노드의 왼쪽 및 오른쪽 분기 추가 val node
Case 3: 목표 깊이는 1입니다추가로 분석하겠습니다. 질문의 의미는 다음과 같습니다. "d의 값이 1이고 깊이 d - 1이 그렇지 않은 경우 존재하고 새 루트 노드 v를 생성하면 원래 전체 트리는 v의 왼쪽 하위 트리가 됩니다." 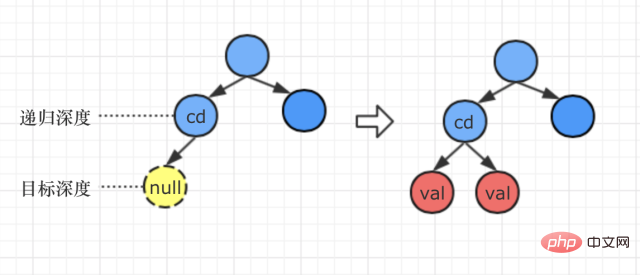 # 🎜🎜#이것은 대상 깊이가 1일 때 처리 방법은 다음과 같습니다 #🎜🎜 #
# 🎜🎜#이것은 대상 깊이가 1일 때 처리 방법은 다음과 같습니다 #🎜🎜 #
모든 코드
/**
* @param {v} val,插入节点携带的值
* @param {cd} current depth,递归当前深度
* @param {td} target depth, 目标深度
* @param {isLeft} 判断原目标深度的节点是在左子树还是右子树
*/
var traversal = function (node, v, cd, td, isLeft) {
debugger;
if (cd === td) {
const newNode = new TreeNode (v);
// 如果原来是左子树,重置后目标节点还是在左子树上,否则相反
if (isLeft) {
newNode.left = node;
} else {
newNode.right = node;
}
return newNode;
}
// 处理上述的第1和第2种情况
if (node.left || (node.left === null && cd + 1 === td)) {
node.left = traversal (node.left, v, cd + 1, td, true);
}
if (node.right || (node.right === null && cd + 1 === td)) {
node.right = traversal (node.right, v, cd + 1, td, false);
}
return node;
};
/**
* Definition for a binary tree node.
* function TreeNode(val) {
* this.val = val;
* this.left = this.right = null;
* }
*/
/**
* @param {TreeNode} root
* @param {number} v
* @param {number} d
* @return {TreeNode}
*/
var addOneRow = function (root, v, td) {
// 处理目标深度为1的情况,也就是上述的第3种情况
if (td === 1) {
const n = new TreeNode (v);
n.left = root;
return n;
}
traversal (root, v, 1, td);
return root;
};단어 분할
문제 설명 
비어 있지 않은 문자열 s와 빈 단어 목록의 사전 wordDict가 아닌 문자열이 주어지면 s가 공백으로 분할되어 나타나는 하나 이상의 단어로 분할될 수 있는지 여부가 결정됩니다. 사전에.
지침: 1. 사전에 있는 단어는 분할 시 재사용할 수 있습니다.
2.你可以假设字典中没有重复的单词。
Example
example1 输入: s = "applepenapple", wordDict = ["apple", "pen"] 输出: true解释: 返回 true 因为 "applepenapple" 可以被拆分成 "apple pen apple"。 注意: 你可以重复使用字典中的单词。 example2 输入: s = "catsandog", wordDict = ["cats", "dog", "sand", "and", "cat"] 输出: false来源:力扣(LeetCode) 链接:https://leetcode-cn.com/problems/word-break
基本思想
动态规划
具体分析
动态规划的关键点是:寻找状态转移方程
有了这个状态转移方程,我们就可以根据上一阶段状态和决策结果,去求出本阶段的状态和结果
然后,就可以从初始值,不断递推求出最终结果。
在这个问题里,我们使用一个一维数组来存放动态规划过程的递推数据
假设这个数组为dp,数组元素都为true或者false,
dp[N] 存放的是字符串s中从0到N截取的子串是否是“可拆分”的布尔值
让我们从一个具体的中间场景出发来思考计算过程
假设我们有
wordDict = ['ab','cd','ef'] s ='abcdef'
并且假设目前我们已经得出了N=1到N=5的情况,而现在需要计算N=6的情况
或者说,我们已经求出了dp[1] 到dp[5]的布尔值,现在需要计算dp[6] = ?
该怎么计算呢?
现在新的字符f被加入到序列“abcde”的后面,如此以来,就新增了以下几种6种需要计算的情况
A序列 + B序列1.abcdef + "" 2.abcde + f3.abcd + ef4.abc + def5.ab + cdef6.a + bcdef 注意:当A可拆且B可拆时,则A+B也是可拆分的
从中我们不难发现两点
1. 当A可拆且B可拆时,则A+B也是可拆分的
2. 这6种情况只要有一种组合序列是可拆分的,abcdef就一定是可拆的,也就得出dp[6] = true了
下面是根据根据已有的dp[1] 到dp[5]的布尔值,动态计算dp[6] 的过程
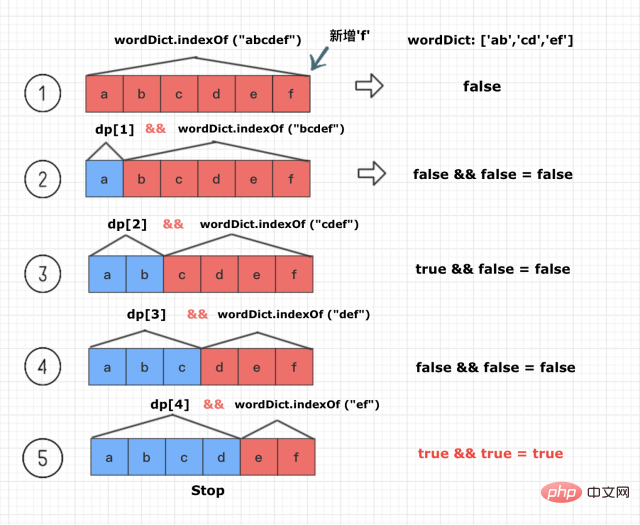
(注意只要计算到可拆,就可以break循环了)
具体代码
var initDp = function (len) {
let dp = new Array (len + 1).fill (false);
return dp;
};
/**
* @param {string} s
* @param {string[]} wordDict
* @return {boolean}
*/
var wordBreak = function (s, wordDict) {
// 处理空字符串
if (s === '' && wordDict.indexOf ('') === -1) {
return false;
}
const len = s.length;
// 默认初始值全部为false
const dp = initDp (len);
const a = s.charAt (0);
// 初始化动态规划的初始值
dp[0] = wordDict.indexOf (a) === -1 ? false : true;
dp[1] = wordDict.indexOf (a) === -1 ? false : true;
// i:end
// j:start
for (let i = 1; i < len; i++) {
for (let j = 0; j <= i; j++) {
// 序列[0,i] = 序列[0,j] + 序列[j,i]
// preCanBreak表示序列[0,j]是否是可拆分的
const preCanBreak = dp[j];
// 截取序列[j,i]
const str = s.slice (j, i + 1);
// curCanBreak表示序列[j,i]是否是可拆分的
const curCanBreak = wordDict.indexOf (str) !== -1;
// 情况1: 序列[0,j]和序列[j,i]都可拆分,那么序列[0,i]肯定也是可拆分的
const flag1 = preCanBreak && curCanBreak;
// 情况2: 序列[0,i]本身就存在于字典中,所以是可拆分的
const flag2 = curCanBreak && j === 0;
if (flag1 || flag2) {
// 设置bool值,本轮计算结束
dp[i + 1] = true;
break;
}
}
}
// 返回最后结果
return dp[len];
};全排列
题目描述
给定一个没有重复数字的序列,返回其所有可能的全排列。
Example
输入: [1,2,3] 输出: [ [1,2,3], [1,3,2], [2,1,3], [2,3,1], [3,1,2], [3,2,1] ]
基本思想
回溯法
具体分析
1. 深度优先搜索搞一波,index在递归中向前推进
2. 当index等于数组长度的时候,结束递归,收集到results中(数组记得要深拷贝哦)
3. 两次数字交换的运用,计算出两种情况
总结
想不通没关系,套路一波就完事了
具体代码
var swap = function (nums, i, j) {
const temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
};
var recursion = function (nums, results, index) {
// 剪枝
if (index >= nums.length) {
results.push (nums.concat ());
return;
}
// 初始化i为index
for (let i = index; i < nums.length; i++) {
// index 和 i交换??
// 统计交换和没交换的两种情况
swap (nums, index, i);
recursion (nums, results, index + 1);
swap (nums, index, i);
}
};
/**
* @param {number[]} nums
* @return {number[][]}
*/
var permute = function (nums) {
const results = [];
recursion (nums, results, 0);
return results;
};本文来自 js教程 栏目,欢迎学习!
위 내용은 JavaScript의 이진 트리, 동적 프로그래밍 및 역추적 방법(사례 분석)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



