

本篇文章给大家带来的内容是关于NotePad++正则表达式如何进行替换(图文),有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。
NotePad++ 正则表达式替换 高级用法
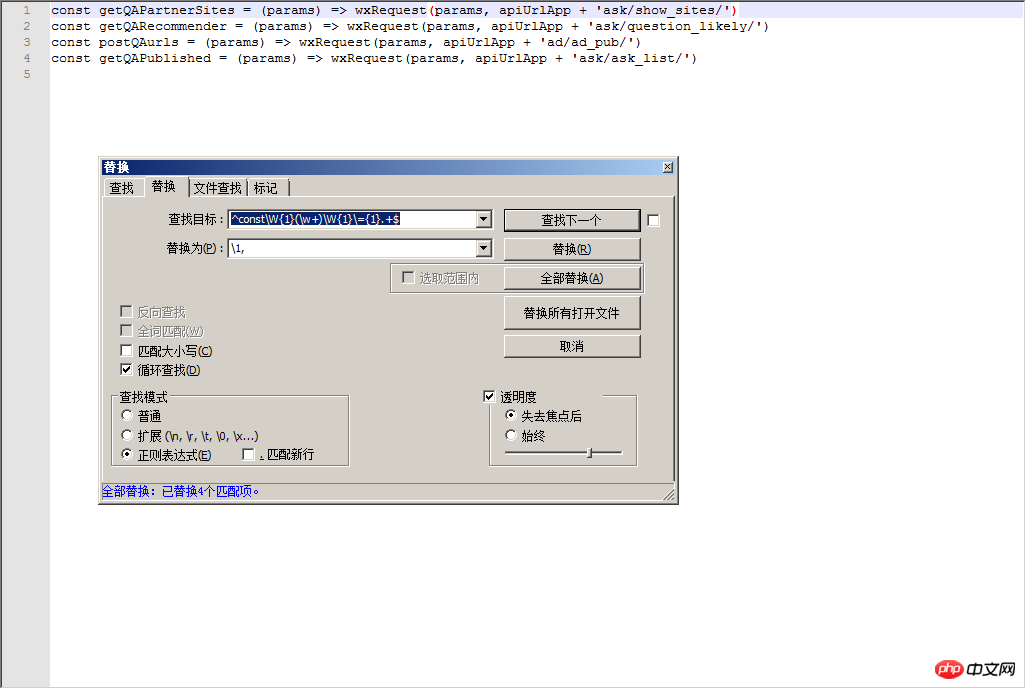
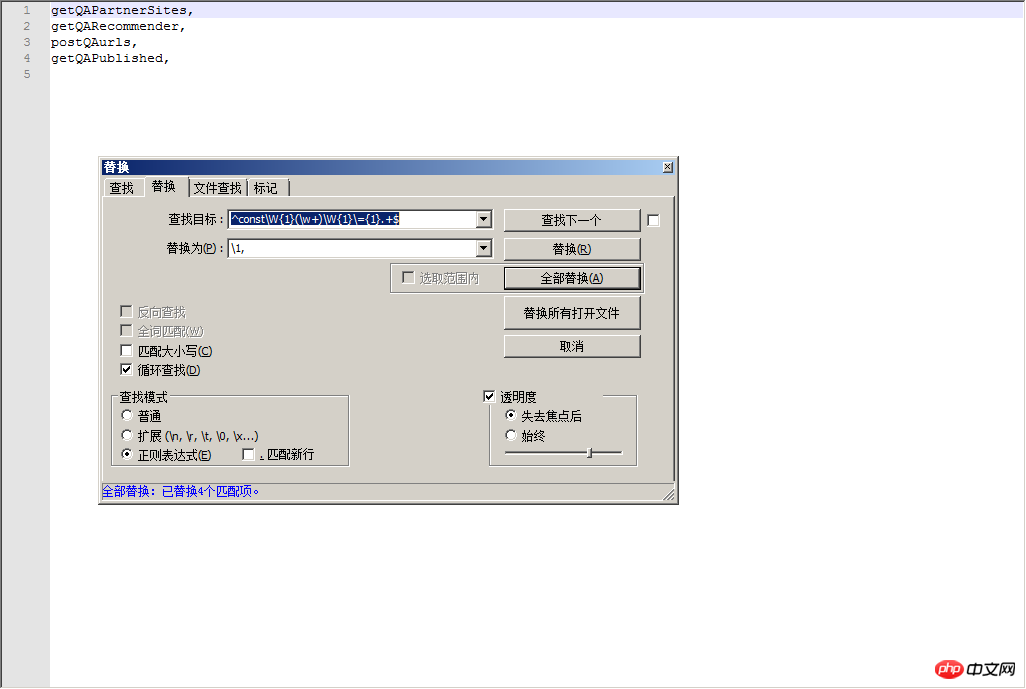
const getQAPartnerSites = (params) => wxRequest(params, apiUrlApp + 'ask/show_sites/') const getQARecommender = (params) => wxRequest(params, apiUrlApp + 'ask/question_likely/') const postQAurls = (params) => wxRequest(params, apiUrlApp + 'ad/ad_pub/') const getQAPublished = (params) => wxRequest(params, apiUrlApp + 'ask/ask_list/')
^const\W{1}(\w+)\W{1}\={1}.+$
\1,getQAPartnerSites, getQARecommender, postQAurls, getQAPublished,
在我们处理文件时,很多时候会用到查找与替换。当我们想将文件中某一部分替换替换文件中另一部分时,怎么办呢? 下面正则表达式 给我提供方法。
正则表达式,提供复杂 并且弹性的查找与替换
注意: 不支持多行表达式 (involving \n, \r, etc).
| 符号 | 解释 |
|---|---|
| . | 匹配任意字符,除了新一行(\n)。也就是说 “.”可以匹配 \r ,当文件中同时含有\r and \n时,会引起混乱。要匹配所有的字符,使用\s\S。 |
| (…) | 这个匹配一个标签区域. 这个标签可以被访问,通过语法 \1访问第一个标签, \2 访问第二个, 同理 \3 \4 … \9。 这些标签可以用在当前正则表达式中,或则替search和replace中的换字符串。 |
| \1, \2, etc | 在替换中代表1到9的标签区域(\1 to \9)。例如, 查找字符串 Fred([1-9])XXX 并替换为字符串 Sam\1YYY的方法,当在文件中找到Fred2XXX的字符串时,会替换为Sam2YYY。注意: 只有9个区域能使用,所以我们在使用时很安全,像\10\2 表示区域1和文本”0”以及区域2。 |
| […] | 表示一个字符集合, 例如 [abc]表示任意字符 a, b or c.我们也可以使用范围例如[a-z] 表示所以的小写字母。 |
| [^…] | 表示字符补集. 例如, [^A-Za-z] 表示任意字符除了字母表。 |
| ^ | 匹配一行的开始(除非在集合中, 如下). |
| $ | 匹配行尾. |
| * | 匹配0或多次, 例如 Sa*m 匹配 Sm, Sam, Saam, Saaam 等等. |
| + | 匹配1次或多次,例如 Sa+m 匹配 Sam, Saam, Saaam 等等. |
| ? | 匹配0或者1次, 例如 Sa?m 匹配 Sm, Sam. |
| {n} | 匹配确定的 n 次.例如, ‘Sa{2}m’ 匹配 Saam. |
| {m,n} | 匹配至少m次,至多n次(如果n缺失,则任意次数).例如, ‘Sa{2,3}m’ 匹配 Saam or Saaam. ‘Sa{2,}m’ 与 ‘Saa+m’相同 |
| *?, +?, ??, {n,m}? | 非贪心匹配,匹配第一个有效的匹配,通常 ‘<.>’ 会匹配整个 ‘content’字符串 –但 ‘<.?>’ 只匹配 ” .这个标记一个标签区域,这些区域可以用语法\1 \2 等访问多个对应1-9区域。 |
| 符号 | 解释 |
|---|---|
| (…) | 一组捕获. 可以通过\1 访问第一个组, \2 访问第二个. |
| (?:…) | 非捕获组. |
| (?=…) | 非捕获组 – 向前断言. 例如’(.*)(?=ton)’ 表达式,当 遇到’Appleton’字符串时,会匹配为’Apple’. |
| (?<=…) | 非捕获组 – 向后断言. 例如’(?<=sir) (.*)’ 表示式,当遇到’sir William’ 字符串时,匹配为’ William’. |
| (?!…) | 非捕获组 – 消极的向前断言. 例如’.(?!e)’ 表达式,当遇到’Apple’时,会找到每个字母除了 ‘l’,因为它紧跟着 ‘e’. |
| (? | 非捕获组 – 消极向后断言. 例如 ‘(? |
| (?P…) | 命名所捕获的组. 提交一个名称到组中供后续使用,例如’(?PA[^\s]+)\s(?P=first)’ 会找到 ‘Apple Apple’. 类似的 ‘(A[^\s]+)\s\1’ 使用组名而不是数字. |
| (?=name) | 匹配名为name的组. (?P…). |
| (?#comment) | 批注 –括号中的内容在匹配时将被忽略。 |
| Symbol | 설명 |
|---|---|
| 은 공백과 일치합니다. 새 줄과 일치하지 않으려면 [[:blank:]]를 사용하세요. | |
| 은 공백이 아닌 일치 | |
| # 🎜🎜#단어 문자 일치 | |
| 단어가 아닌 문자 일치 | # 🎜🎜 #d |
| D | |
| #🎜🎜 ##🎜 🎜# | b단어 경계와 일치합니다. 'bWw+'는 W로 시작하는 단어를 찾습니다. |
| B | # 🎜🎜# 비단어 경계와 일치합니다. - Scintilla의 단어 정의를 사용하여 단어 중간에서 문자 'e'를 찾습니다. 🎜# 다른 의미를 가질 수 있는 문자를 표현하려면 x를 실행하세요. 예를 들어, [는 문자 집합의 시작 부분이 아닌 [로 텍스트에 삽입하는 데 사용됩니다. |
| 4 문자 클래스 | # 🎜🎜# |
| 설명 | |
| #🎜 🎜#[ [:alpha :]] | 알파벳 문자 일치: [A-Za-z] |
| [[:digit:]]#🎜 🎜## 🎜🎜# 일치하는 숫자 문자: [0-9] |
| 일치하는 영숫자 문자: [0-9A-Za -z] | |
|---|---|
| # 🎜🎜# | [[:upper:]]대문자 일치: [A-Z] |
| [[:blank: ]] | 공백과 일치합니다(공백 또는 탭):[ t] |
| [[:space:]] | # 🎜 🎜# 공백 문자 일치: [trnvf] |
| [[:punct:]] | 구두점 문자 일치: [-!" #$ %&'()*+,./:;<=>?@[]_`{ |
| [[:graph:]]# 🎜🎜 # | 그래픽 문자 일치: [x21-x7E]|
| 인쇄 가능한 문자 일치 (그래픽 문자 및 공백) | |
| 제어 문자 일치 | #🎜 🎜# |
| 정규식 태그를 사용하고 사용하려는 문자를 ()로 묶은 다음 문자열을 첫 번째인 1로 바꿉니다. 텍스트 일치 . 🎜🎜#문자열 바꾸기 | Result |
| 안녕하세요 제 이름은 프레드입니다 | |
| 내 이름은 1이 아닙니다 | 안녕하세요 내 이름은 프레드가 아닙니다 |
| brown(.+)이 (.+)를 뛰어넘었습니다 | brown 2가 1을 뛰어넘었습니다 |
| 6 제한사항 |
위 내용은 NotePad++에서 정규식을 바꾸는 방법(그림 및 텍스트)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!





















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



