

수집은 PHP 프로그램을 사용하여 다른 웹사이트의 정보를 자체 데이터베이스와 웹사이트로 수집하는 것입니다. 이 기사에서는 모든 사람에게 도움이 되기를 바라면서 주로 PHP의 데이터 수집 방법을 여러분과 공유합니다.
PHP 제작 및 수집 기술:
기본 소켓부터 고급 파일 연산 기능까지 수집을 달성하는 방법은 총 3가지가 있습니다.
1. 소켓 기술을 사용한 수집:
소켓 수집은 단지 긴 연결을 설정한 다음 요청을 보내기 위해 http 프로토콜 문자열을 직접 구성해야 합니다.
예를 들어 이 페이지의 콘텐츠를 얻으려면 http://tv.youku.com/?spm=a2hww.20023042.topNav.5~1~3!2~A를 사용하세요.
<?php
//连接,$error错误编号,$errstr错误的字符串,30s是连接超时时间
$fp=fsockopen("www.youku.com",80,$errno,$errstr,30);
if(!$fp) die("连接失败".$errstr);
//构造http协议字符串,因为socket编程是最底层的,它还没有使用http协议
$http="GET /?spm=a2hww.20023042.topNav.5~1~3!2~A HTTP/1.1\r\n"; // \r\n表示前面的是一个命令
$http.="Host:www.youku.com\r\n"; //请求的主机
$http.="Connection:close\r\n\r\n"; // 连接关闭,最后一行要两个\r\n
//发送这个字符串到服务器
fwrite($fp,$http,strlen($http));
//接收服务器返回的数据
$data='';
while (!feof($fp)) {
$data.=fread($fp,4096); //fread读取返回的数据,一次读取4096字节
}
//关闭连接
fclose($fp);
var_dump($data);
?>반환된 헤더 정보와 페이지의 소스 코드를 포함하여 인쇄된 결과는 다음과 같습니다.

2. 함수
curl을 사용하여 HTTP 프로토콜을 변환합니다. 모두 많은 함수로 캡슐화되어 있으며 해당 매개변수를 직접 전달할 수 있으므로 HTTP 프로토콜 문자열 작성의 어려움이 줄어듭니다.
전제 조건: php.ini에서 컬 확장이 활성화되어 있어야 합니다.
//生成一个curl对象 $curl=curl_init(); //设置URL和相应的选项 curl_setopt($curl, CURLOPT_URL, "http://www.youku.com"); curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1); //将curl_exec()获取的信息以字符串返回,而不是直接输出。 //执行curl操作 $data=curl_exec($curl); var_dump($data);
페이지의 소스 코드만 포함하여 인쇄된 결과는 다음과 같습니다. 
3 file_get_contents 직접 사용(최상위 수준)
전제 조건: in php.ini 네트워크를 열 수 있는 URL 주소를 설정하세요.

//使用file_get_contents()
$data=file_get_contents("http://www.youku.com");
var_dump($data);
3가지 방법 중 선택
위 3가지 방법은 주로 네트워크 간 통신에 사용됩니다. 그 중 후자의 두 가지가 더 일반적으로 사용됩니다. 많은 양의 데이터를 일괄적으로 수집하려면 성능과 안정성이 좋은 두 번째 [CURL]를 사용하세요.
몇 가지 요청을 가끔 보내지만 자주 보내지는 않을 때 세 번째 옵션을 사용하세요.
확장: 사진의 도난 방지 링크를 끊는 방법은 무엇입니까?
예를 들어 7060 웹사이트의 사진은 핫링크로부터 보호됩니다. 사진은 그의 웹사이트에서 볼 수 있지만 사이트 외부에서는 액세스할 수 없습니다.

원리: HTTP 프로토콜에는 요청의 소스 주소를 나타내는 리퍼러 항목이 있습니다. 서버는 요청이 이 웹사이트에서 나온 것이 아니라면 요청을 필터링할 것이라고 판단합니다. :

해결 방법: HTTP를 보낼 때 리퍼러를 직접 시뮬레이션하세요.
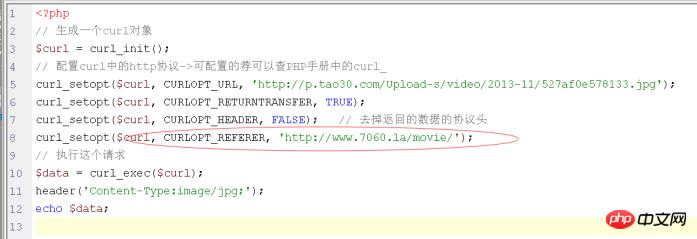
扩展:有些要采集数据时时必须先登录,可以使用模拟的试模拟在登录状态下的采集:
a. 先用浏览登录一下,登录完,浏览器的COOKIE中就会有SESSIONID
b. 发PHP发HTTP协议时,把浏览器中的SESSIONID放到PHP的HTTP协议请求里,这样就在以登录的状态发请求。
总结:所有客户端发过来的数据都可以被模拟,所以服务器上的程序必须要必要的地方过滤客户端的数据。
什么时候用以上东西?接口开发时、采集时。
二、数据采集
例如我要采集这个url里的所有美国电影的信息,
http://list.youku.com/category/show/c_96_a_%E7%BE%8E%E5%9B%BD_s_1_d_1_p_3.html
则先要知道电影所在的节点的结构,我们使用firebug查看。
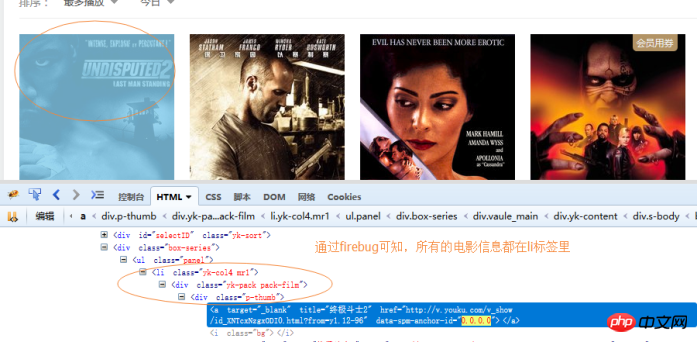
然后开始写代码:完整代码如下
/**
* 发一个GET请求获取数据
*/
function get($url)
{
global $curl;
// 配置curl中的http协议->可配置的荐可以查PHP手册中的curl_
curl_setopt($curl, CURLOPT_URL, $url);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, TRUE);
curl_setopt($curl, CURLOPT_HEADER, FALSE);
// 执行这个请求
return curl_exec($curl);
}
// 生成一个curl对象
$curl = curl_init();
$url='http://list.youku.com/category/show/c_96_a_%E7%BE%8E%E5%9B%BD_s_1_d_1_p_3.html';
$data=get($url);
// 匹配电影所在位置
$list_preg = '/<li class="yk-col4 mr1">.+<\/li>/Us';
// 匹配img标签上的src和alt
$img_preg = '/<img class="quic" _src="(.*)" src="(.*)" alt="(.*)" \/>/U';
//匹配电影的url
$video_preg='/<a href="(.*)" title="(.*)" target="(.*)"><\/a>/U';
//把所有的li存到$list里,$list是个二维数组
preg_match_all($list_preg,$data,$list);
//var_dump($list);
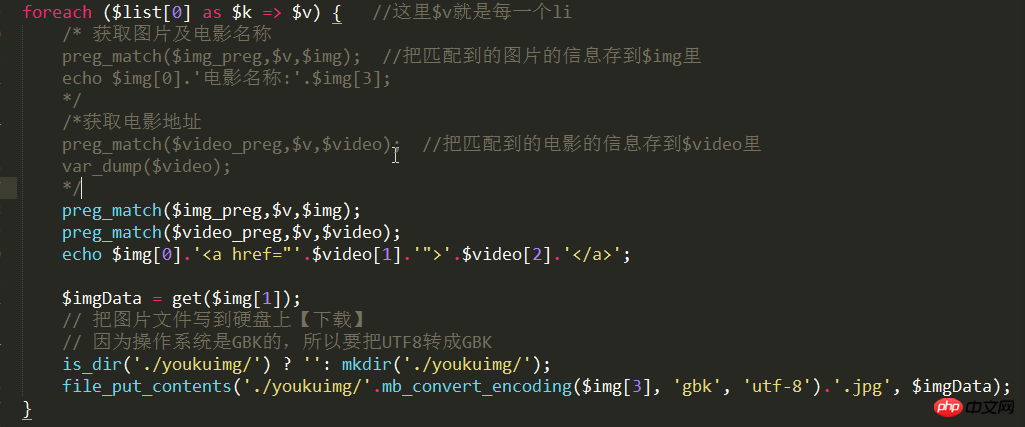
foreach ($list[0] as $k => $v) { //这里$v就是每一个li标签
/* 获取图片及电影名称
preg_match($img_preg,$v,$img); //把匹配到的图片的信息存到$img里
var_dump($img);
*/
/*获取电影地址
preg_match($video_preg,$v,$video); //把匹配到的电影的信息存到$video里
var_dump($video);
*/
preg_match($img_preg,$v,$img);
preg_match($video_preg,$v,$video);
echo $img[0].'<a href="'.$video[1].'">'.$video[2].'</a>';
}测试:
打印$list;

打印$img

打印$video

最终效果:

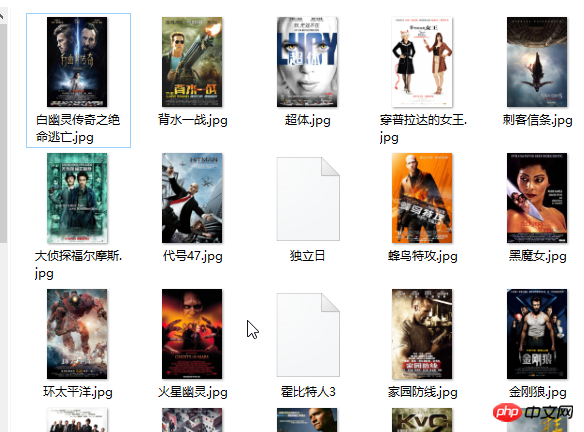
如果需要把图片拷贝到硬盘上,则在foreach循环里加上以下代码:
$imgData = get($img[1]); // 把图片文件写到硬盘上【下载】 // 因为操作系统是GBK的,所以要把UTF8转成GBK is_dir('./youkuimg/') ? '': mkdir('./youkuimg/'); file_put_contents('./youkuimg/'.mb_convert_encoding($img[3], 'gbk', 'utf-8').'.jpg', $imgData);
效果如下:在当前目录下的youkuimg目录下就会有下载好的图片。
相关推荐:
위 내용은 PHP에서 데이터 수집을 구현하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!






























![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



