

1. 크롤러 프로세스
우리의 최종 목표는 Lima Financial Management의 일일 매출을 크롤링하여 어떤 제품이 판매되었는지, 각 제품을 언제 구입했는지 파악하는 것입니다. 먼저 크롤링의 주요 단계를 소개하겠습니다.
페이지 데이터를 크롤링하려는 첫 번째 단계는 물론 페이지 구조를 명확하게 분석하고, 크롤링할 페이지가 무엇인지를 분석하는 것입니다. 페이지 구조, 로그인이 필요합니까? Ajax 인터페이스가 있습니까? 어떤 종류의 데이터가 반환됩니까?
크롤링할 페이지와 Ajax를 명확하게 분석한 후 데이터를 캡처할 차례입니다. 오늘날의 웹페이지 데이터는 크게 동기화 페이지와 Ajax 인터페이스로 나누어집니다. 페이지 데이터를 동기적으로 캡처하려면 먼저 웹 페이지의 구조를 분석해야 합니다. Python은 일반적으로 정규식 일치를 통해 데이터를 캡처하여 필요한 데이터를 얻습니다. jquery의 강력한 dom API를 사용하여 노드 관련 데이터를 얻을 수 있습니다. 실제로 소스 코드를 살펴보면 이러한 API의 본질은 정기적인 일치입니다. Ajax 인터페이스 데이터는 일반적으로 json 형식이며 처리가 비교적 간단합니다.
데이터를 수집한 후 간단한 필터링이 수행된 후 후속 분석 및 처리를 위해 필요한 데이터가 저장됩니다. 물론 MySQL, Mongodb와 같은 데이터베이스를 사용하여 데이터를 저장할 수 있습니다. 여기서는 편의상 파일 저장소를 직접 사용합니다.
우리는 궁극적으로 데이터를 표시하고 싶기 때문에 원본 데이터를 특정 차원에 따라 처리하고 분석한 다음 클라이언트에 반환해야 합니다. 이 프로세스는 저장 중에 처리될 수도 있고 표시 중에 프런트 엔드에서 요청을 보내고 백그라운드에서 저장된 데이터를 검색하여 다시 처리할 수도 있습니다. 이는 데이터를 표시하려는 방법에 따라 다릅니다.
이렇게 많은 작업을 했는데도 전혀 출력이 안되는데 어떻게 그럴 수가 있겠습니까? 이것은 우리의 예전 사업으로 돌아가서 모두가 프런트엔드 디스플레이 페이지에 익숙해져야 합니다. 데이터를 표시하는 것이 더 직관적이고 통계 분석을 더 쉽게 해줍니다.
Superagent는 nodejs에서 매우 편리한 클라이언트 요청 프록시 모듈입니다. 요청하면 시도해 보세요.
Cheerio는 CSS 선택기를 사용하여 웹페이지에서 데이터를 가져오는 데 사용되는 Node.js 버전으로 이해될 수 있습니다.
Async는 직접적이고 강력한 비동기 기능인 mapLimit(arr,limit,iterator,callback)을 제공하는 프로세스 제어 툴킷입니다. 공식 홈페이지에서 API를 확인하실 수 있습니다.
arr-del은 배열 요소를 삭제하기 위해 제가 직접 작성한 도구입니다. 삭제할 배열 요소의 인덱스로 구성된 배열을 전달하여 일회성 삭제를 수행할 수 있습니다.
arr-sort는 제가 직접 작성한 배열 정렬 도구입니다. 정렬은 하나 이상의 속성을 기반으로 할 수 있으며 중첩된 속성이 지원됩니다. 또한, 각 조건별로 정렬 방향을 지정할 수 있고, 비교 함수를 전달할 수도 있습니다.
먼저 크롤링 아이디어를 검토해 보겠습니다. 리마 재무 관리 온라인의 상품은 주로 정기 및 리마 재무부(중국 Everbright Bank의 최신 재무 관리 상품은 처리가 어렵고 초기 투자 금액이 높아 구매하는 사람이 거의 없으므로 여기에는 통계가 없습니다) ). 정기적으로 재무 관리 페이지의 Ajax 인터페이스를 크롤링할 수 있습니다: https://www.lmlc.com/web/product/product_list?pageSize=10&pageNo=1&type=0. (업데이트: 일반 제품은 조만간 품절되어 데이터를 보실 수 없을 수도 있습니다.) 데이터는 아래와 같습니다.
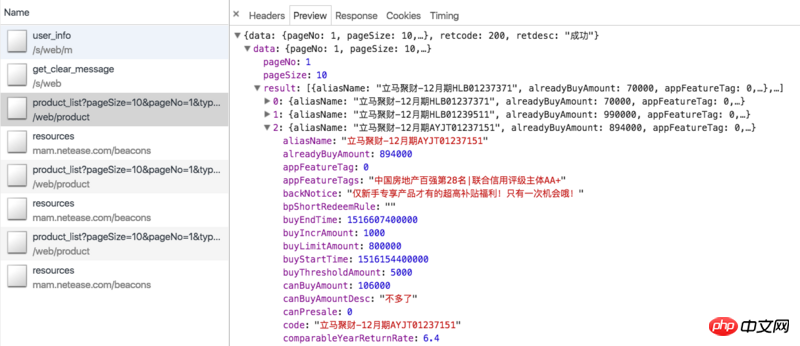
여기에는 온라인에서 판매되는 모든 일반 제품이 포함되어 있습니다. ajax 데이터에는 제품 ID, 모금 금액, 현재 판매량, 연간 수익률, 투자 일수 등 제품 자체와 관련된 정보만 있을 뿐, 어떤 사용자가 제품을 구매했는지에 대한 정보는 없습니다. 따라서 Jucai 즉시(12월호 HLB01239511)와 같은 제품 세부정보 페이지를 크롤링하려면 id 매개변수를 사용해야 합니다. 세부 정보 페이지에는 아래 그림과 같이 필요한 정보가 포함된 투자 기록 열이 있습니다.
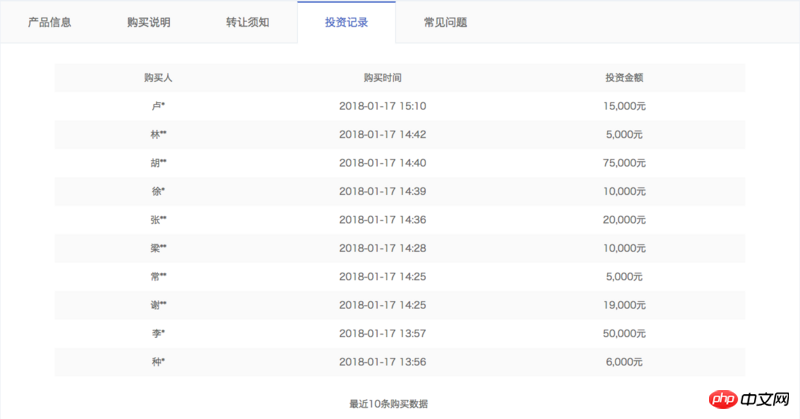
그러나 세부 정보 페이지를 보려면 로그인해야 합니다. 쿠키에 액세스하고 쿠키에 유효 기간이 있는 경우 쿠키를 로그인 상태로 유지하는 방법은 무엇입니까? 아래를 참조하십시오.
실제로 Lima Treasury에도 비슷한 Ajax 인터페이스가 있습니다(https://www.lmlc.com/web/product/product_list?pageSize=10&pageNo=1&type=1). 하지만 내부의 관련 데이터는 다음과 같습니다. 하드 코딩됨 예, 말도 안 돼요. 또한, 볼트 상세 페이지에는 투자 기록 정보가 없습니다. 이를 위해서는 처음에 언급한 홈페이지(https://www.lmlc.com/s/web/home/user_buying)의 Ajax 인터페이스를 크롤링해야 합니다. 하지만 나중에 이 인터페이스가 3분마다 업데이트된다는 사실을 발견했습니다. 이는 백그라운드가 3분마다 서버에서 데이터를 요청한다는 의미입니다. 한번에 10개의 데이터가 있으므로, 3분 이내에 구매한 상품의 기록 개수가 10개를 초과할 경우 데이터가 생략됩니다. 이 문제를 해결할 방법이 없으므로 리마 재무부의 통계는 실제 통계보다 낮을 것입니다. https://www.lmlc.com/web/product/product_list?pageSize=10&pageNo=1&type=1,但是里边的相关数据都是写死的,没有意义。而且金库的详情页也没有投资记录信息。这就需要我们爬取一开始说的首页的ajax接口:https://www.lmlc.com/s/web/home/user_buying。但是后来才发现这个接口是三分钟更新一次,就是说后台每隔三分钟向服务器请求一次数据。而一次是10条数据,所以如果在三分钟内,购买产品的记录数超过10条,数据就会有遗漏。这是没有办法的,所以立马金库的统计数据会比真实的偏少。
因为产品详情页需要登录,所以我们要先拿到登录的cookie才行。getCookie方法如下:
function getCookie() {
superagent.post('https://www.lmlc.com/user/s/web/logon')
.type('form')
.send({
phone: phone,
password: password,
productCode: "LMLC",
origin: "PC"
})
.end(function(err, res) {
if (err) {
handleErr(err.message);
return;
}
cookie = res.header['set-cookie']; //从response中得到cookie
emitter.emit("setCookeie");
})
}phone和password参数是从命令行里传进来的,就是立马理财用手机号登录的账号和密码。我们用superagent去模拟请求立马理财登录接口:https://www.lmlc.com/user/s/web/logon。传入相应的参数,在回调中,我们拿到header的set-cookie信息,并发出一个setCookeie事件。因为我们设置了监听事件:emitter.on("setCookie", requestData),所以一旦获取cookie,我们就会去执行requestData方法。
requestData方法的代码如下:
function requestData() {
superagent.get('https://www.lmlc.com/web/product/product_list?pageSize=100&pageNo=1&type=0')
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
// 在这里清空数据,避免一个文件被同时写入
if(clearProd){
fs.writeFileSync('data/prod.json', JSON.stringify([]));
clearProd = false;
}
let addData = JSON.parse(pres.text).data;
let formatedAddData = formatData(addData.result);
let pageUrls = [];
if(addData.totalPage > 1){
handleErr('产品个数超过100个!');
return;
}
for(let i=0,len=addData.result.length; i<len; i++){
if(+new Date() < addData.result[i].buyStartTime){
if(preIds.indexOf(addData.result[i].id) == -1){
preIds.push(addData.result[i].id);
setPreId(addData.result[i].buyStartTime, addData.result[i].id);
}
}else{
pageUrls.push('https://www.lmlc.com/web/product/product_detail.html?id=' + addData.result[i].id);
}
}
function setPreId(time, id){
cache[id] = setInterval(function(){
if(time - (+new Date()) < 1000){
// 预售产品开始抢购,直接修改爬取频次为1s,防止丢失数据
clearInterval(cache[id]);
clearInterval(timer);
delay = 1000;
timer = setInterval(function(){
requestData();
}, delay);
// 同时删除id记录
let index = preIds.indexOf(id);
sort.delArrByIndex(preIds, [index]);
}
}, 1000)
}
// 处理售卖金额信息
let oldData = JSON.parse(fs.readFileSync('data/prod.json', 'utf-8'));
for(let i=0, len=formatedAddData.length; i<len; i++){
let isNewProduct = true;
for(let j=0, len2=oldData.length; j<len2; j++){
if(formatedAddData[i].productId === oldData[j].productId){
isNewProduct = false;
}
}
if(isNewProduct){
oldData.push(formatedAddData[i]);
}
}
fs.writeFileSync('data/prod.json', JSON.stringify(oldData));
let time = (new Date()).format("yyyy-MM-dd hh:mm:ss");
console.log((`理财列表ajax接口爬取完毕,时间:${time}`).warn);
if(!pageUrls.length){
delay = 32*1000;
clearInterval(timer);
timer = setInterval(function(){
requestData();
}, delay);
return
}
getDetailData();
});
}代码很长,getDetailData函数代码后面分析。
请求的ajax接口是个分页接口,因为一般在售的总产品数不会超过10条,我们这里设置参数pageSize为100,这样就可以一次性获取所有产品。
clearProd是全局reset信号,每天0点整的时候,会清空prod(定期产品)和user(首页用户)数据。
因为有时候产品较少会采用抢购的方式,比如每天10点,这样在每天10点的时候数据会更新很快,我们必须要增加爬取的频次,以防丢失数据。所以针对预售产品即buyStartTime大于当前时间,我们要记录下,并设定计时器,当开售时,调整爬取频次为1次/秒,见setPreId方法。
如果没有正在售卖的产品,即pageUrls为空,我们将爬取的频次设置为最大32s。
requestData函数的这部分代码主要记录下是否有新产品,如果有的话,新建一个对象,记录产品信息,push到prod数组里。prod.json数据结构如下:
[{
"productName": "立马聚财-12月期HLB01230901",
"financeTotalAmount": 1000000,
"productId": "201801151830PD84123120",
"yearReturnRate": 6.4,
"investementDays": 364,
"interestStartTime": "2018年01月23日",
"interestEndTime": "2019年01月22日",
"getDataTime": 1516118401299,
"alreadyBuyAmount": 875000,
"records": [
{
"username": "刘**",
"buyTime": 1516117093472,
"buyAmount": 30000,
"uniqueId": "刘**151611709347230,000元"
},
{
"username": "刘**",
"buyTime": 1516116780799,
"buyAmount": 50000,
"uniqueId": "刘**151611678079950,000元"
}]
}]是一个对象数组,每个对象表示一个新产品,records属性记录着售卖信息。
我们再看下getDetailData的代码:
function getDetailData(){
// 请求用户信息接口,来判断登录是否还有效,在产品详情页判断麻烦还要造成五次登录请求
superagent
.post('https://www.lmlc.com/s/web/m/user_info')
.set('Cookie', cookie)
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
let retcode = JSON.parse(pres.text).retcode;
if(retcode === 410){
handleErr('登陆cookie已失效,尝试重新登陆...');
getCookie();
return;
}
var reptileLink = function(url,callback){
// 如果爬取页面有限制爬取次数,这里可设置延迟
console.log( '正在爬取产品详情页面:' + url);
superagent
.get(url)
.set('Cookie', cookie)
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
var $ = cheerio.load(pres.text);
var records = [];
var $table = $('.buy-records table');
if(!$table.length){
$table = $('.tabcontent table');
}
var $tr = $table.find('tr').slice(1);
$tr.each(function(){
records.push({
username: $('td', $(this)).eq(0).text(),
buyTime: parseInt($('td', $(this)).eq(1).attr('data-time').replace(/,/g, '')),
buyAmount: parseFloat($('td', $(this)).eq(2).text().replace(/,/g, '')),
uniqueId: $('td', $(this)).eq(0).text() + $('td', $(this)).eq(1).attr('data-time').replace(/,/g, '') + $('td', $(this)).eq(2).text()
})
});
callback(null, {
productId: url.split('?id=')[1],
records: records
});
});
};
async.mapLimit(pageUrls, 10 ,function (url, callback) {
reptileLink(url, callback);
}, function (err,result) {
let time = (new Date()).format("yyyy-MM-dd hh:mm:ss");
console.log(`所有产品详情页爬取完毕,时间:${time}`.info);
let oldRecord = JSON.parse(fs.readFileSync('data/prod.json', 'utf-8'));
let counts = [];
for(let i=0,len=result.length; i<len; i++){
for(let j=0,len2=oldRecord.length; j<len2; j++){
if(result[i].productId === oldRecord[j].productId){
let count = 0;
let newRecords = [];
for(let k=0,len3=result[i].records.length; k<len3; k++){
let isNewRec = true;
for(let m=0,len4=oldRecord[j].records.length; m<len4; m++){
if(result[i].records[k].uniqueId === oldRecord[j].records[m].uniqueId){
isNewRec = false;
}
}
if(isNewRec){
count++;
newRecords.push(result[i].records[k]);
}
}
oldRecord[j].records = oldRecord[j].records.concat(newRecords);
counts.push(count);
}
}
}
let oldDelay = delay;
delay = getNewDelay(delay, counts);
function getNewDelay(delay, counts){
let nowDate = (new Date()).toLocaleDateString();
let time1 = Date.parse(nowDate + ' 00:00:00');
let time2 = +new Date();
// 根据这次更新情况,来动态设置爬取频次
let maxNum = Math.max(...counts);
if(maxNum >=0 && maxNum <= 2){
delay = delay + 1000;
}
if(maxNum >=8 && maxNum <= 10){
delay = delay/2;
}
// 每天0点,prod数据清空,排除这个情况
if(maxNum == 10 && (time2 - time1 >= 60*1000)){
handleErr('部分数据可能丢失!');
}
if(delay <= 1000){
delay = 1000;
}
if(delay >= 32*1000){
delay = 32*1000;
}
return delay
}
if(oldDelay != delay){
clearInterval(timer);
timer = setInterval(function(){
requestData();
}, delay);
}
fs.writeFileSync('data/prod.json', JSON.stringify(oldRecord));
})
});
}我们先去请求用户信息接口,来判断登录是否还有效,因为在产品详情页判断麻烦还要造成五次登录请求。带cookie请求很简单,在post后面set下我们之前得到的cookie即可:.set('Cookie', cookie)
function requestData1() {
superagent.get(ajaxUrl1)
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
let newData = JSON.parse(pres.text).data;
let formatNewData = formatData1(newData);
// 在这里清空数据,避免一个文件被同时写入
if(clearUser){
fs.writeFileSync('data/user.json', '');
clearUser = false;
}
let data = fs.readFileSync('data/user.json', 'utf-8');
if(!data){
fs.writeFileSync('data/user.json', JSON.stringify(formatNewData));
let time = (new Date()).format("yyyy-MM-dd hh:mm:ss");
console.log((`首页用户购买ajax爬取完毕,时间:${time}`).silly);
}else{
let oldData = JSON.parse(data);
let addData = [];
// 排重算法,如果uniqueId不一样那肯定是新生成的,否则看时间差如果是0(三分钟内请求多次)或者三分钟则是旧数据
for(let i=0, len=formatNewData.length; i<len; i++){
let matchArr = [];
for(let len2=oldData.length, j=Math.max(0,len2 - 20); j<len2; j++){
if(formatNewData[i].uniqueId === oldData[j].uniqueId){
matchArr.push(j);
}
}
if(matchArr.length === 0){
addData.push(formatNewData[i]);
}else{
let isNewBuy = true;
for(let k=0, len3=matchArr.length; k<len3; k++){
let delta = formatNewData[i].time - oldData[matchArr[k]].time;
if(delta == 0 || (Math.abs(delta - 3*60*1000) < 1000)){
isNewBuy = false;
// 更新时间,这样下一次判断还是三分钟
oldData[matchArr[k]].time = formatNewData[i].time;
}
}
if(isNewBuy){
addData.push(formatNewData[i]);
}
}
}
fs.writeFileSync('data/user.json', JSON.stringify(oldData.concat(addData)));
let time = (new Date()).format("yyyy-MM-dd hh:mm:ss");
console.log((`首页用户购买ajax爬取完毕,时间:${time}`).silly);
}
});
}https://www.lmlc.com/user/s/web/logon)에 대한 요청을 시뮬레이션합니다. 해당 매개변수를 전달합니다. 콜백에서 헤더의 set-cookie 정보를 가져오고 setCookeie 이벤트를 보냅니다. 수신 이벤트(emitter.on("setCookie", requestData))를 설정했기 때문에 쿠키가 획득되면 requestData 메서드를 실행합니다. 2. 재무 관리 페이지의 Ajax 크롤링requestData 메소드의 코드는 다음과 같습니다. [
{
"payAmount": 5067.31,
"productId": "jsfund",
"productName": "立马金库",
"productType": 6,
"time": 1548489,
"username": "郑**",
"buyTime": 1516118397758,
"uniqueId": "5067.31jsfund郑**"
}, {
"payAmount": 30000,
"productId": "201801151830PD84123120",
"productName": "立马聚财-12月期HLB01230901",
"productType": 0,
"time": 1306573,
"username": "刘**",
"buyTime": 1516117199684,
"uniqueId": "30000201801151830PD84123120刘**"
}]let globalTimer = setInterval(function(){
let nowTime = +new Date();
let nowStr = (new Date()).format("hh:mm:ss");
let max = nowTime;
let min = nowTime - 24*60*60*1000;
// 每天00:00分的时候写入当天的数据
if(nowStr === "00:00:00"){
// 先保存数据
let prod = JSON.parse(fs.readFileSync('data/prod.json', 'utf-8'));
let user = JSON.parse(fs.readFileSync('data/user.json', 'utf-8'));
let lmlc = JSON.parse(JSON.stringify(prod));
// 清空缓存数据
clearProd = true;
clearUser = true;
// 不足一天的不统计
// if(nowTime - initialTime < 24*60*60*1000) return
// 筛选prod.records数据
for(let i=0, len=prod.length; i<len; i++){
let delArr1 = [];
for(let j=0, len2=prod[i].records.length; j<len2; j++){
if(prod[i].records[j].buyTime < min || prod[i].records[j].buyTime >= max){
delArr1.push(j);
}
}
sort.delArrByIndex(lmlc[i].records, delArr1);
}
// 删掉prod.records为空的数据
let delArr2 = [];
for(let i=0, len=lmlc.length; i<len; i++){
if(!lmlc[i].records.length){
delArr2.push(i);
}
}
sort.delArrByIndex(lmlc, delArr2);
// 初始化lmlc里的立马金库数据
lmlc.unshift({
"productName": "立马金库",
"financeTotalAmount": 100000000,
"productId": "jsfund",
"yearReturnRate": 4.0,
"investementDays": 1,
"interestStartTime": (new Date(min)).format("yyyy年MM月dd日"),
"interestEndTime": (new Date(max)).format("yyyy年MM月dd日"),
"getDataTime": min,
"alreadyBuyAmount": 0,
"records": []
});
// 筛选user数据
for(let i=0, len=user.length; i<len; i++){
if(user[i].productId === "jsfund" && user[i].buyTime >= min && user[i].buyTime < max){
lmlc[0].records.push({
"username": user[i].username,
"buyTime": user[i].buyTime,
"buyAmount": user[i].payAmount,
});
}
}
// 删除无用属性,按照时间排序
lmlc[0].records.sort(function(a,b){return a.buyTime - b.buyTime});
for(let i=1, len=lmlc.length; i<len; i++){
lmlc[i].records.sort(function(a,b){return a.buyTime - b.buyTime});
for(let j=0, len2=lmlc[i].records.length; j<len2; j++){
delete lmlc[i].records[j].uniqueId
}
}
// 爬取金库收益,写入前一天的数据,清空user.json和prod.json
let dateStr = (new Date(nowTime - 10*60*1000)).format("yyyyMMdd");
superagent
.get('https://www.lmlc.com/web/product/product_list?pageSize=10&pageNo=1&type=1')
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
var data = JSON.parse(pres.text).data;
var rate = data.result[0].yearReturnRate||4.0;
lmlc[0].yearReturnRate = rate;
fs.writeFileSync(`data/${dateStr}.json`, JSON.stringify(lmlc));
})
}
}, 1000);var gulp = require('gulp');
var uglify = require("gulp-uglify");
var less = require("gulp-less");
var minifyCss = require("gulp-minify-css");
var livereload = require('gulp-livereload');
var connect = require('gulp-connect');
var minimist = require('minimist');
var babel = require('gulp-babel');
var knownOptions = {
string: 'env',
default: { env: process.env.NODE_ENV || 'production' }
};
var options = minimist(process.argv.slice(2), knownOptions);
// js文件压缩
gulp.task('minify-js', function() {
gulp.src('src/js/*.js')
.pipe(babel({
presets: ['es2015']
}))
.pipe(uglify())
.pipe(gulp.dest('dist/'));
});
// js移动文件
gulp.task('move-js', function() {
gulp.src('src/js/*.js')
.pipe(babel({
presets: ['es2015']
}))
.pipe(gulp.dest('dist/'))
.pipe(connect.reload());
});
// less编译
gulp.task('compile-less', function() {
gulp.src('src/css/*.less')
.pipe(less())
.pipe(gulp.dest('dist/'))
.pipe(connect.reload());
});
// less文件编译压缩
gulp.task('compile-minify-css', function() {
gulp.src('src/css/*.less')
.pipe(less())
.pipe(minifyCss())
.pipe(gulp.dest('dist/'));
});
// html页面自动刷新
gulp.task('html', function () {
gulp.src('views/*.html')
.pipe(connect.reload());
});
// 页面自动刷新启动
gulp.task('connect', function() {
connect.server({
livereload: true
});
});
// 监测文件的改动
gulp.task('watch', function() {
gulp.watch('src/css/*.less', ['compile-less']);
gulp.watch('src/js/*.js', ['move-js']);
gulp.watch('views/*.html', ['html']);
});
// 激活浏览器livereload友好提示
gulp.task('tip', function() {
console.log('\n<----- 请用chrome浏览器打开 http://localhost:5000 页面,并激活livereload插件 ----->\n');
});
if (options.env === 'development') {
gulp.task('default', ['move-js', 'compile-less', 'connect', 'watch', 'tip']);
}else{
gulp.task('default', ['minify-js', 'compile-minify-css']);
}.set('Cookie', cookie)). 백그라운드에서 반환된 retcode가 410이면 로그인 쿠키가 만료되었으며 getCookie()를 다시 실행해야 함을 의미합니다. 이렇게 하면 크롤러가 항상 로그인되어 있습니다. 🎜🎜async의 mapLimit 메서드는 pageUrls에 대한 동시 요청을 수행하며 동시성은 한 번에 10개입니다. ReppetLink 메소드는 각 pageUrl에 대해 실행됩니다. 콜백 함수를 실행하기 전에 모든 비동기 실행이 완료될 때까지 기다리십시오. 콜백 함수의 결과 매개변수는 각 파충류링크 함수가 반환한 데이터로 구성된 배열입니다. 🎜🎜ReplyLink 기능은 상품 상세 페이지의 투자 기록 목록 정보를 가져오는 기능입니다. UniqueId는 알려진 사용자 이름, buyTime, buyAmount 매개변수로 구성된 문자열로, 중복을 제거하는 데 사용됩니다. 🎜🎜async의 콜백은 주로 최신 투자 기록 정보를 해당 제품 객체에 기록하는 동시에 카운트 배열을 생성하는 것입니다. counts 배열은 이번에 크롤링된 상품별 신규 판매 기록 개수로 구성된 배열로, 지연과 함께 getNewDelay 함수에 전달됩니다. getNewDelay는 크롤링 빈도를 동적으로 조정하며 개수는 지연 조정을 위한 유일한 기초입니다. 지연이 너무 크면 데이터 손실이 발생할 수 있고, 너무 작으면 서버에 부담이 가중되어 관리자가 IP 주소를 차단할 수 있습니다. 여기서는 Delay의 최대값을 32로, 최소값을 1로 설정했습니다. 🎜🎜4. 홈페이지 사용자 ajax 크롤링 🎜🎜먼저 코드로 가보겠습니다: 🎜rrreee🎜user.js의 크롤링은 prod.js와 유사합니다. 여기서는 주로 중복을 제거하는 방법에 대해 이야기하고 싶습니다. user.json 데이터 형식은 다음과 같습니다. 🎜[
{
"payAmount": 5067.31,
"productId": "jsfund",
"productName": "立马金库",
"productType": 6,
"time": 1548489,
"username": "郑**",
"buyTime": 1516118397758,
"uniqueId": "5067.31jsfund郑**"
}, {
"payAmount": 30000,
"productId": "201801151830PD84123120",
"productName": "立马聚财-12月期HLB01230901",
"productType": 0,
"time": 1306573,
"username": "刘**",
"buyTime": 1516117199684,
"uniqueId": "30000201801151830PD84123120刘**"
}]和产品详情页类似,我们也生成一个uniqueId参数用来排除,它是payAmount、productId、username参数的拼成的字符串。如果uniqueId不一样,那肯定是一条新的记录。如果相同那一定是一条新记录吗?答案是否定的。因为这个接口数据是三分钟更新一次,而且给出的时间是相对时间,即数据更新时的时间减去购买的时间。所以每次更新后,即使是同一条记录,时间也会不一样。那如何排重呢?其实很简单,如果uniqueId一样,我们就判断这个buyTime,如果buyTime的差正好接近180s,那么几乎可以肯定是旧数据。如果同一个人正好在三分钟后购买同一个产品相同的金额那我也没辙了,哈哈。
每天零点我们需要整理user.json和prod.json数据,生成最终的数据。代码:
let globalTimer = setInterval(function(){
let nowTime = +new Date();
let nowStr = (new Date()).format("hh:mm:ss");
let max = nowTime;
let min = nowTime - 24*60*60*1000;
// 每天00:00分的时候写入当天的数据
if(nowStr === "00:00:00"){
// 先保存数据
let prod = JSON.parse(fs.readFileSync('data/prod.json', 'utf-8'));
let user = JSON.parse(fs.readFileSync('data/user.json', 'utf-8'));
let lmlc = JSON.parse(JSON.stringify(prod));
// 清空缓存数据
clearProd = true;
clearUser = true;
// 不足一天的不统计
// if(nowTime - initialTime < 24*60*60*1000) return
// 筛选prod.records数据
for(let i=0, len=prod.length; i<len; i++){
let delArr1 = [];
for(let j=0, len2=prod[i].records.length; j<len2; j++){
if(prod[i].records[j].buyTime < min || prod[i].records[j].buyTime >= max){
delArr1.push(j);
}
}
sort.delArrByIndex(lmlc[i].records, delArr1);
}
// 删掉prod.records为空的数据
let delArr2 = [];
for(let i=0, len=lmlc.length; i<len; i++){
if(!lmlc[i].records.length){
delArr2.push(i);
}
}
sort.delArrByIndex(lmlc, delArr2);
// 初始化lmlc里的立马金库数据
lmlc.unshift({
"productName": "立马金库",
"financeTotalAmount": 100000000,
"productId": "jsfund",
"yearReturnRate": 4.0,
"investementDays": 1,
"interestStartTime": (new Date(min)).format("yyyy年MM月dd日"),
"interestEndTime": (new Date(max)).format("yyyy年MM月dd日"),
"getDataTime": min,
"alreadyBuyAmount": 0,
"records": []
});
// 筛选user数据
for(let i=0, len=user.length; i<len; i++){
if(user[i].productId === "jsfund" && user[i].buyTime >= min && user[i].buyTime < max){
lmlc[0].records.push({
"username": user[i].username,
"buyTime": user[i].buyTime,
"buyAmount": user[i].payAmount,
});
}
}
// 删除无用属性,按照时间排序
lmlc[0].records.sort(function(a,b){return a.buyTime - b.buyTime});
for(let i=1, len=lmlc.length; i<len; i++){
lmlc[i].records.sort(function(a,b){return a.buyTime - b.buyTime});
for(let j=0, len2=lmlc[i].records.length; j<len2; j++){
delete lmlc[i].records[j].uniqueId
}
}
// 爬取金库收益,写入前一天的数据,清空user.json和prod.json
let dateStr = (new Date(nowTime - 10*60*1000)).format("yyyyMMdd");
superagent
.get('https://www.lmlc.com/web/product/product_list?pageSize=10&pageNo=1&type=1')
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
var data = JSON.parse(pres.text).data;
var rate = data.result[0].yearReturnRate||4.0;
lmlc[0].yearReturnRate = rate;
fs.writeFileSync(`data/${dateStr}.json`, JSON.stringify(lmlc));
})
}
}, 1000);globalTimer是个全局定时器,每隔1s执行一次,当时间为00:00:00时,clearProd和clearUser全局参数为true,这样在下次爬取过程时会清空user.json和prod.json文件。没有同步清空是因为防止多处同时修改同一文件报错。取出user.json里的所有金库记录,获取当天金库相关信息,生成一条立马金库的prod信息并unshift进prod.json里。删除一些无用属性,排序数组最终生成带有当天时间戳的json文件,如:20180101.json。
前端总共就两个页面,首页和详情页,首页主要展示实时销售额、某一时间段内的销售情况、具体某天的销售情况。详情页展示某天的具体某一产品销售情况。页面有两个入口,而且比较简单,这里我们采用gulp来打包压缩构建前端工程。后台用express搭建的,匹配到路由,从data文件夹里取到数据再分析处理再返回给前端。
Echarts
Echarts是一个绘图利器,百度公司不可多得的良心之作。能方便的绘制各种图形,官网已经更新到4.0了,功能更加强大。我们这里主要用到的是直方图。
DataTables
Datatables是一款jquery表格插件。它是一个高度灵活的工具,可以将任何HTML表格添加高级的交互功能。功能非常强大,有丰富的API,大家可以去官网学习。
Datepicker
Datepicker是一款基于jquery的日期选择器,需要的功能基本都有,主要样式比较好看,比jqueryUI官网的Datepicker好看太多。
gulp配置比较简单,代码如下:
var gulp = require('gulp');
var uglify = require("gulp-uglify");
var less = require("gulp-less");
var minifyCss = require("gulp-minify-css");
var livereload = require('gulp-livereload');
var connect = require('gulp-connect');
var minimist = require('minimist');
var babel = require('gulp-babel');
var knownOptions = {
string: 'env',
default: { env: process.env.NODE_ENV || 'production' }
};
var options = minimist(process.argv.slice(2), knownOptions);
// js文件压缩
gulp.task('minify-js', function() {
gulp.src('src/js/*.js')
.pipe(babel({
presets: ['es2015']
}))
.pipe(uglify())
.pipe(gulp.dest('dist/'));
});
// js移动文件
gulp.task('move-js', function() {
gulp.src('src/js/*.js')
.pipe(babel({
presets: ['es2015']
}))
.pipe(gulp.dest('dist/'))
.pipe(connect.reload());
});
// less编译
gulp.task('compile-less', function() {
gulp.src('src/css/*.less')
.pipe(less())
.pipe(gulp.dest('dist/'))
.pipe(connect.reload());
});
// less文件编译压缩
gulp.task('compile-minify-css', function() {
gulp.src('src/css/*.less')
.pipe(less())
.pipe(minifyCss())
.pipe(gulp.dest('dist/'));
});
// html页面自动刷新
gulp.task('html', function () {
gulp.src('views/*.html')
.pipe(connect.reload());
});
// 页面自动刷新启动
gulp.task('connect', function() {
connect.server({
livereload: true
});
});
// 监测文件的改动
gulp.task('watch', function() {
gulp.watch('src/css/*.less', ['compile-less']);
gulp.watch('src/js/*.js', ['move-js']);
gulp.watch('views/*.html', ['html']);
});
// 激活浏览器livereload友好提示
gulp.task('tip', function() {
console.log('\n<----- 请用chrome浏览器打开 http://localhost:5000 页面,并激活livereload插件 ----->\n');
});
if (options.env === 'development') {
gulp.task('default', ['move-js', 'compile-less', 'connect', 'watch', 'tip']);
}else{
gulp.task('default', ['minify-js', 'compile-minify-css']);
}开发和生产环境都是将文件打包到dist目录。不同的是:开发环境只是编译es6和less文件;生产环境会再压缩混淆。支持livereload插件,在开发环境下,文件改动会自动刷新页面。
相关推荐:
위 내용은 NodeJS 크롤러에 대한 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



