

이 글은 코딩을 위해 스트림을 사용한 Node.js 디자인 패턴을 주로 공유합니다.
Streams는 Node.js의 가장 중요한 구성 요소 및 패턴 중 하나입니다. 커뮤니티에는 "모든 것을 스트리밍하라(Steam is all)"라는 모토가 있는데, 이것만으로도 Node.js의 스트림 상태를 설명하기에 충분합니다. Dominic TarrNode.js 커뮤니티의 가장 큰 기여자로서 그는 흐름을 Node.js의 최고이자 가장 이해하기 어려운 개념으로 정의합니다. . Streams是Node.js最重要的组件和模式之一。 社区中有一句格言“Stream all the things(Steam就是所有的)”,仅此一点就足以描述流在Node.js中的地位。 Dominic Tarr作为Node.js社区的最大贡献者,它将流定义为Node.js最好,也是最难以理解的概念。
使Node.js的Streams如此吸引人还有其它原因; 此外,Streams不仅与性能或效率等技术特性有关,更重要的是它们的优雅性以及它们与Node.js的设计理念完美契合的方式。
在本章中,将会学到以下内容:
Streams对于Node.js的重要性。
如何创建并使用Streams。
Streams作为编程范式,不只是对于I/O而言,在多种应用场景下它的应用和强大的功能。
管道模式和在不同的配置中连接Streams。
在基于事件的平台(如Node.js)中,处理I / O的最有效的方法是实时处理,一旦有输入的信息,立马进行处理,一旦有需要输出的结果,也立马输出反馈。
在本节中,我们将首先介绍Node.js的Streams和它的优点。 请记住,这只是一个概述,因为本章后面将会详细介绍如何使用和组合Streams。
我们在本书中几乎所有看到过的异步API都是使用的Buffer模式。 对于输入操作,Buffer模式会将来自资源的所有数据收集到Buffer区中; 一旦读取完整个资源,就会把结果传递给回调函数。 下图显示了这个范例的一个真实的例子:
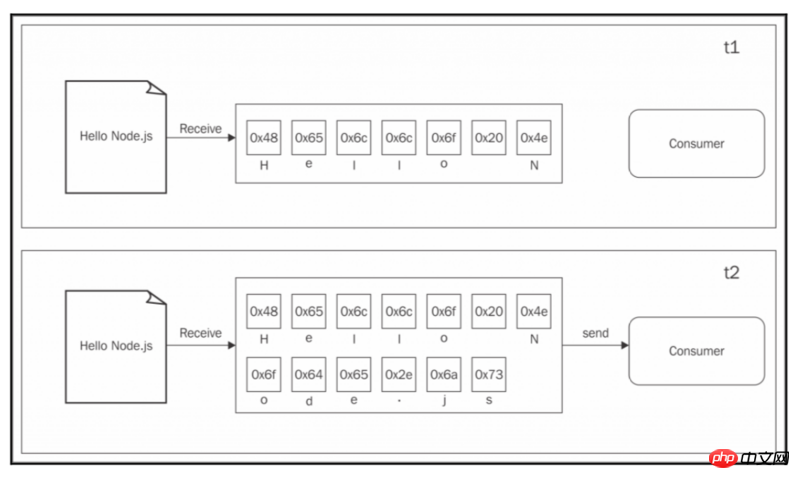
从上图我们可以看到,在t1时刻,一些数据从资源接收并保存到缓冲区。 在t2时刻,最后一段数据被接收到另一个数据块,完成读取操作,这时,把整个缓冲区的内容发送给消费者。
另一方面,Streams允许你在数据到达时立即处理数据。 如下图所示:
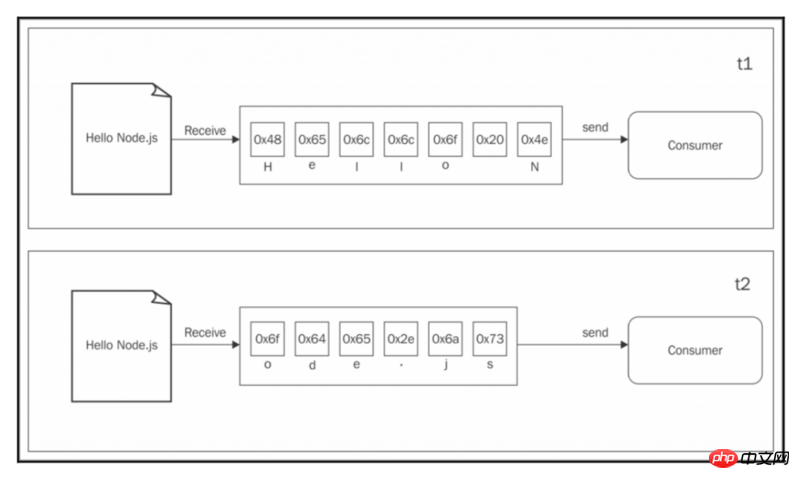
这一张图显示了Streams如何从资源接收每个新的数据块,并立即提供给消费者,消费者现在不必等待缓冲区中收集所有数据再处理每个数据块。
但是这两种方法有什么区别呢? 我们可以将它们概括为两点:
空间效率
时间效率
此外,Node.js的Streams具有另一个重要的优点:可组合性(composability)。 现在让我们看看这些属性对我们设计和编写应用程序的方式会产生什么影响。
首先,Streams允许我们做一些看起来不可能的事情,通过缓冲数据并一次性处理。 例如,考虑一下我们必须读取一个非常大的文件,比如说数百MB甚至千MB。 显然,等待完全读取文件时返回大Buffer的API不是一个好主意。 想象一下,如果并发读取一些大文件, 我们的应用程序很容易耗尽内存。 除此之外,V8中的Buffer不能大于0x3FFFFFFF字节(小于1GB)。 所以,在耗尽物理内存之前,我们可能会碰壁。
举一个具体的例子,让我们考虑一个简单的命令行接口(CLI)的应用程序,它使用Gzip格式压缩文件。 使用Buffered的API,这样的应用程序在Node.js中大概这么编写(为简洁起见,省略了异常处理):
const fs = require('fs');
const zlib = require('zlib');
const file = process.argv[2];
fs.readFile(file, (err, buffer) => {
zlib.gzip(buffer, (err, buffer) => {
fs.writeFile(file + '.gz', buffer, err => {
console.log('File successfully compressed');
});
});
});现在,我们可以尝试将前面的代码放在一个叫做gzip.js的文件中,然后执行下面的命令:
node gzip <path to file>
如果我们选择一个足够大的文件,比如说大于1GB
Node.js의 Streams를 매력적으로 만드는 다른 이유도 있습니다. 게다가 Streams는 성능이나 성능 같은 기술적인 기능에 관한 것이 아닙니다. 효율성, 더 중요한 것은 우아함과 Node.js의 디자인 철학에 완벽하게 들어맞는 방식입니다. 이 장에서는 다음 내용을 배우게 됩니다: Node.js 중요성에 대한 
스트림.
스트림을 만들고 사용하는 방법. 🎜I/O뿐만 아니라 다양한 응용 프로그램 시나리오의 해당 응용 프로그램 및 강력한 기능에 대한 프로그래밍 패러다임으로서의 스트림. 🎜스트림 연결. 🎜Node.js와 같은 이벤트 기반 플랫폼에서 I/O의 효과적인 방법은 입력된 정보가 있으면 즉시 처리하고, 출력해야 할 결과가 있으면 즉시 피드백을 출력하는 것입니다. 🎜🎜이 섹션에서는 먼저 <code>Node.js의 Streams와 그 장점을 소개하겠습니다. 이 장의 뒷부분에서 스트림 사용 및 결합에 대해 자세히 알아보게 되므로 이는 단지 개요일 뿐이라는 점을 명심하세요. 🎜버퍼 모드를 사용합니다. 입력 작업의 경우 버퍼 모드는 리소스의 모든 데이터를 버퍼 영역으로 수집합니다. 전체 리소스를 읽은 후 결과가 콜백 함수에 전달됩니다. 아래 이미지는 이 패러다임의 실제 예를 보여줍니다. 🎜🎜🎜🎜 🎜 🎜위 그림을 보면 t1 순간에 리소스로부터 일부 데이터를 수신하여 버퍼에 저장하는 것을 볼 수 있습니다. t2에서는 마지막 데이터 조각이 다른 데이터 블록으로 수신되고 읽기 작업이 완료됩니다. 이때 전체 버퍼 내용이 소비자에게 전송됩니다. 🎜🎜 반면 Streams를 사용하면 데이터가 도착하자마자 처리할 수 있습니다. 아래 사진과 같습니다: 🎜🎜🎜🎜🎜🎜이 사진은 스트림리소스에서 각각의 새로운 데이터 블록을 수신하여 소비자에게 즉시 제공하는 방법. 이제 소비자는 각 데이터 블록을 처리하기 전에 모든 데이터가 버퍼에 수집될 때까지 기다릴 필요가 없습니다. 🎜🎜그런데 이 두 가지 방법의 차이점은 무엇인가요? 이를 두 가지로 요약할 수 있습니다: 🎜Node.js의 Streams에는 구성 가능성이라는 또 다른 중요한 이점이 있습니다. 이제 이러한 속성이 애플리케이션을 디자인하고 작성하는 방식에 어떤 영향을 미치는지 살펴보겠습니다. 🎜Streams를 사용하면 데이터를 버퍼링하고 한 번에 처리함으로써 불가능해 보이는 일을 할 수 있습니다. 예를 들어 수백 MB 또는 수천 MB와 같은 매우 큰 파일을 읽어야 한다고 가정해 보겠습니다. 분명히, 파일이 완전히 읽힐 때까지 기다리는 동안 API가 큰 버퍼를 반환할 때까지 기다리는 것은 좋은 생각이 아닙니다. 몇 개의 큰 파일을 동시에 읽는 경우 애플리케이션의 메모리가 쉽게 부족해질 수 있다고 상상해 보십시오. 또한 V8의 버퍼는 0x3FFFFFFFF바이트(1GB 미만)보다 클 수 없습니다. 따라서 물리적 메모리가 부족해지기 전에 벽에 부딪힐 수 있습니다. 🎜 Gzip 형식을 사용하는 간단한 명령줄 인터페이스(CLI) 애플리케이션을 고려해 보겠습니다. 압축 파일. Buffered의 API를 사용하면 이러한 애플리케이션은 대략 Node.js에서 다음과 같이 작성됩니다(간결함을 위해 예외 처리는 생략됨). 🎜 RangeError: File size is greater than possible Buffer:0x3FFFFFFF
gzip.js라는 파일에 넣은 후 다음 명령을 실행할 수 있습니다. 🎜const fs = require('fs');
const zlib = require('zlib');
const file = process.argv[2];
fs.createReadStream(file)
.pipe(zlib.createGzip())
.pipe(fs.createWriteStream(file + '.gz'))
.on('finish', () => console.log('File successfully compressed'));1GB 파일을 읽으면 아래와 같이 읽으려는 파일이 허용되는 최대 버퍼 크기보다 크다는 오류 메시지를 받게 됩니다. 🎜const http = require('http');
const fs = require('fs');
const zlib = require('zlib');
const server = http.createServer((req, res) => {
const filename = req.headers.filename;
console.log('File request received: ' + filename);
req
.pipe(zlib.createGunzip())
.pipe(fs.createWriteStream(filename))
.on('finish', () => {
res.writeHead(201, {
'Content-Type': 'text/plain'
});
res.end('That\'s it\n');
console.log(`File saved: ${filename}`);
});
});
server.listen(3000, () => console.log('Listening'));上面的例子中,没找到一个大文件,但确实对于大文件的读取速率慢了许多。
正如我们所预料到的那样,使用Buffer来进行大文件的读取显然是错误的。
我们必须修复我们的Gzip应用程序,并使其处理大文件的最简单方法是使用Streams的API。 让我们看看如何实现这一点。 让我们用下面的代码替换刚创建的模块的内容:
const fs = require('fs');
const zlib = require('zlib');
const file = process.argv[2];
fs.createReadStream(file)
.pipe(zlib.createGzip())
.pipe(fs.createWriteStream(file + '.gz'))
.on('finish', () => console.log('File successfully compressed'));“是吗?”你可能会问。是的;正如我们所说的,由于Streams的接口和可组合性,因此我们还能写出这样的更加简洁,优雅和精炼的代码。 我们稍后会详细地看到这一点,但是现在需要认识到的重要一点是,程序可以顺畅地运行在任何大小的文件上,理想情况是内存利用率不变。 尝试一下(但考虑压缩一个大文件可能需要一段时间)。
现在让我们考虑一个压缩文件并将其上传到远程HTTP服务器的应用程序的例子,该远程HTTP服务器进而将其解压缩并保存到文件系统中。如果我们的客户端是使用Buffered的API实现的,那么只有当整个文件被读取和压缩时,上传才会开始。 另一方面,只有在接收到所有数据的情况下,解压缩才会在服务器上启动。 实现相同结果的更好的解决方案涉及使用Streams。 在客户端机器上,Streams只要从文件系统中读取就可以压缩和发送数据块,而在服务器上,只要从远程对端接收到数据块,就可以解压每个数据块。 我们通过构建前面提到的应用程序来展示这一点,从服务器端开始。
我们创建一个叫做gzipReceive.js的模块,代码如下:
const http = require('http');
const fs = require('fs');
const zlib = require('zlib');
const server = http.createServer((req, res) => {
const filename = req.headers.filename;
console.log('File request received: ' + filename);
req
.pipe(zlib.createGunzip())
.pipe(fs.createWriteStream(filename))
.on('finish', () => {
res.writeHead(201, {
'Content-Type': 'text/plain'
});
res.end('That\'s it\n');
console.log(`File saved: ${filename}`);
});
});
server.listen(3000, () => console.log('Listening'));服务器从网络接收数据块,将其解压缩,并在接收到数据块后立即保存,这要归功于Node.js的Streams。
我们的应用程序的客户端将进入一个名为gzipSend.js的模块,如下所示:
在前面的代码中,我们再次使用Streams从文件中读取数据,然后在从文件系统中读取的同时压缩并发送每个数据块。
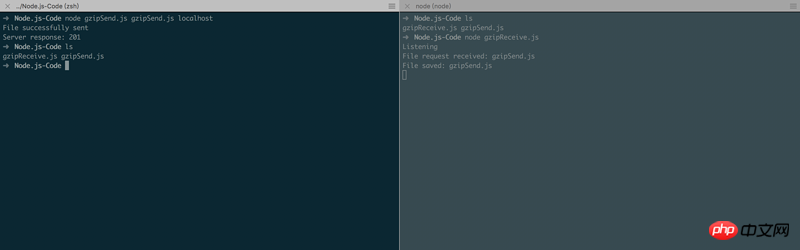
现在,运行这个应用程序,我们首先使用以下命令启动服务器:
node gzipReceive
然后,我们可以通过指定要发送的文件和服务器的地址(例如localhost)来启动客户端:
node gzipSend <path to file> localhost
如果我们选择一个足够大的文件,我们将更容易地看到数据如何从客户端流向服务器,但为什么这种模式下,我们使用Streams,比使用Buffered的API更有效率? 下图应该给我们一个提示:
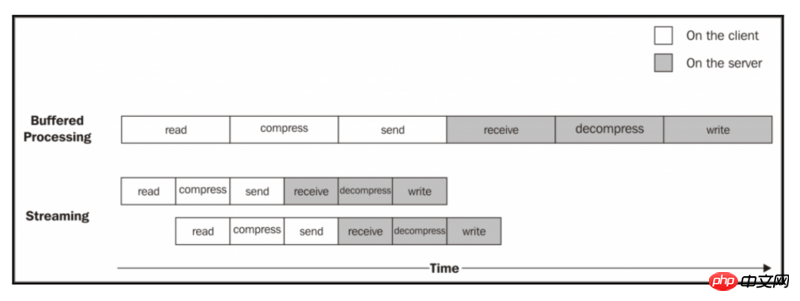
一个文件被处理的过程,它经过以下阶段:
客户端从文件系统中读取
客户端压缩数据
客户端将数据发送到服务器
服务端接收数据
服务端解压数据
服务端将数据写入磁盘
为了完成处理,我们必须按照流水线顺序那样经过每个阶段,直到最后。在上图中,我们可以看到,使用Buffered的API,这个过程完全是顺序的。为了压缩数据,我们首先必须等待整个文件被读取完毕,然后,发送数据,我们必须等待整个文件被读取和压缩,依此类推。当我们使用Streams时,只要我们收到第一个数据块,流水线就会被启动,而不需要等待整个文件的读取。但更令人惊讶的是,当下一块数据可用时,不需要等待上一组任务完成;相反,另一条装配线是并行启动的。因为我们执行的每个任务都是异步的,这样显得很完美,所以可以通过Node.js来并行执行Streams的相关操作;唯一的限制就是每个阶段都必须保证数据块的到达顺序。
从前面的图可以看出,使用Streams的结果是整个过程花费的时间更少,因为我们不用等待所有数据被全部读取完毕和处理。
到目前为止,我们已经看到的代码已经告诉我们如何使用pipe()方法来组装Streams的数据块,Streams允许我们连接不同的处理单元,每个处理单元负责单一的职责(这是符合Node.js风格的)。这是可能的,因为Streams具有统一的接口,并且就API而言,不同Streams也可以很好的进行交互。唯一的先决条件是管道的下一个Streams必须支持上一个Streams生成的数据类型,可以是二进制,文本甚至是对象,我们将在后面的章节中看到。
为了证明Streams组合性的优势,我们可以尝试在我们先前构建的gzipReceive / gzipSend应用程序中添加加密功能。
为此,我们只需要通过向流水线添加另一个Streams来更新客户端。 确切地说,由crypto.createChipher()返回的流。 由此产生的代码应如下所示:
const fs = require('fs');
const zlib = require('zlib');
const crypto = require('crypto');
const http = require('http');
const path = require('path');
const file = process.argv[2];
const server = process.argv[3];
const options = {
hostname: server,
port: 3000,
path: '/',
method: 'PUT',
headers: {
filename: path.basename(file),
'Content-Type': 'application/octet-stream',
'Content-Encoding': 'gzip'
}
};
const req = http.request(options, res => {
console.log('Server response: ' + res.statusCode);
});
fs.createReadStream(file)
.pipe(zlib.createGzip())
.pipe(crypto.createCipher('aes192', 'a_shared_secret'))
.pipe(req)
.on('finish', () => {
console.log('File successfully sent');
});使用相同的方式,我们更新服务端的代码,使得它可以在数据块进行解压之前先解密:
const http = require('http');
const fs = require('fs');
const zlib = require('zlib');
const crypto = require('crypto');
const server = http.createServer((req, res) => {
const filename = req.headers.filename;
console.log('File request received: ' + filename);
req
.pipe(crypto.createDecipher('aes192', 'a_shared_secret'))
.pipe(zlib.createGunzip())
.pipe(fs.createWriteStream(filename))
.on('finish', () => {
res.writeHead(201, {
'Content-Type': 'text/plain'
});
res.end('That\'s it\n');
console.log(`File saved: ${filename}`);
});
});
server.listen(3000, () => console.log('Listening'));crypto是Node.js的核心模块之一,提供了一系列加密算法。
只需几行代码,我们就在应用程序中添加了一个加密层。 我们只需要简单地通过把已经存在的Streams模块和加密层组合到一起,就可以。类似的,我们可以添加和合并其他Streams,如同在玩乐高积木一样。
显然,这种方法的主要优点是可重用性,但正如我们从目前为止所介绍的代码中可以看到的那样,Streams也可以实现更清晰,更模块化,更加简洁的代码。 出于这些原因,流通常不仅仅用于处理纯粹的I / O,而且它还是简化和模块化代码的手段。
在前面的章节中,我们了解了为什么Streams如此强大,而且它在Node.js中无处不在,甚至在Node.js的核心模块中也有其身影。 例如,我们已经看到,fs模块具有用于从文件读取的createReadStream()和用于写入文件的createWriteStream(),HTTP请求和响应对象本质上是Streams,并且zlib模块允许我们使用Streams式API压缩和解压缩数据块。
现在我们知道为什么Streams是如此重要,让我们退后一步,开始更详细地探索它。
Node.js中的每个Streams都是Streams核心模块中可用的四个基本抽象类之一的实现:
stream.Readable
stream.Writable
stream.Duplex
stream.Transform
每个stream类也是EventEmitter的一个实例。实际上,Streams可以产生几种类型的事件,比如end事件会在一个可读的Streams完成读取,或者错误读取,或其过程中产生异常时触发。
请注意,为简洁起见,在本章介绍的例子中,我们经常会忽略适当的错误处理。但是,在生产环境下中,总是建议为所有Stream注册错误事件侦听器。
Streams之所以如此灵活的原因之一是它不仅能够处理二进制数据,而且几乎可以处理任何JavaScript值。实际上,Streams可以支持两种操作模式:
二进制模式:以数据块形式(例如buffers或strings)流式传输数据
对象模式:将流数据视为一系列离散对象(这使得我们几乎可以使用任何JavaScript值)
这两种操作模式使我们不仅可以使用I / O流,而且还可以作为一种工具,以函数式的风格优雅地组合处理单元,我们将在本章后面看到。
在本章中,我们将主要使用在Node.js 0.11中引入的Node.js流接口,也称为版本3。 有关与旧接口差异的更多详细信息,请参阅StrongLoop在https://strongloop.com/strong...。
一个可读的Streams表示一个数据源,在Node.js中,它使用stream模块中的Readableabstract类实现。
从可读Streams接收数据有两种方式:non-flowing模式和flowing模式。 我们来更详细地分析这些模式。
从可读的Streams中读取数据的默认模式是为其附加一个可读事件侦听器,用于指示要读取的新数据的可用性。然后,在一个循环中,我们读取所有的数据,直到内部buffer被清空。这可以使用read()方法完成,该方法同步从内部缓冲区中读取数据,并返回表示数据块的Buffer或String对象。read()方法以如下使用模式:
readable.read([size]);
使用这种方法,数据随时可以直接从Streams中按需提取。
为了说明这是如何工作的,我们创建一个名为readStdin.js的新模块,它实现了一个简单的程序,它从标准输入(一个可读流)中读取数据,并将所有数据回送到标准输出:
process.stdin
.on('readable', () => {
let chunk;
console.log('New data available');
while ((chunk = process.stdin.read()) !== null) {
console.log(
`Chunk read: (${chunk.length}) "${chunk.toString()}"`
);
}
})
.on('end', () => process.stdout.write('End of stream'));read()方法是一个同步操作,它从可读Streams的内部Buffers区中提取数据块。如果Streams在二进制模式下工作,返回的数据块默认为一个Buffer对象。
在以二进制模式工作的可读的Stream中,我们可以通过在Stream上调用setEncoding(encoding)来读取字符串而不是Buffer对象,并提供有效的编码格式(例如utf8)。
数据是从可读的侦听器中读取的,只要有新的数据,就会调用这个侦听器。当内部缓冲区中没有更多数据可用时,read()方法返回null;在这种情况下,我们不得不等待另一个可读的事件被触发,告诉我们可以再次读取或者等待表示Streams读取过程结束的end事件触发。当一个流以二进制模式工作时,我们也可以通过向read()方法传递一个size参数来指定我们想要读取的数据大小。这在实现网络协议或解析特定数据格式时特别有用。
现在,我们准备运行readStdin模块并进行实验。让我们在控制台中键入一些字符,然后按Enter键查看回显到标准输出中的数据。要终止流并因此生成一个正常的结束事件,我们需要插入一个EOF(文件结束)字符(在Windows上使用Ctrl + Z或在Linux上使用Ctrl + D)。
我们也可以尝试将我们的程序与其他程序连接起来;这可以使用管道运算符(|),它将程序的标准输出重定向到另一个程序的标准输入。例如,我们可以运行如下命令:
cat <path to a file> | node readStdin
这是流式范例是一个通用接口的一个很好的例子,它使得我们的程序能够进行通信,而不管它们是用什么语言写的。
从Streams中读取的另一种方法是将侦听器附加到data事件;这会将Streams切换为flowing模式,其中数据不是使用read()函数来提取的,而是一旦有数据到达data监听器就被推送到监听器内。例如,我们之前创建的readStdin应用程序将使用流动模式:
process.stdin
.on('data', chunk => {
console.log('New data available');
console.log(
`Chunk read: (${chunk.length}) "${chunk.toString()}"`
);
})
.on('end', () => process.stdout.write('End of stream'));flowing模式是旧版Streams接口(也称为Streams1)的继承,其灵活性较低,API较少。随着Streams2接口的引入,flowing模式不是默认的工作模式,要启用它,需要将侦听器附加到data事件或显式调用resume()方法。 要暂时中断Streams触发data事件,我们可以调用pause()方法,导致任何传入数据缓存在内部buffer中。
调用pause()不会导致Streams切换回non-flowing模式。
现在我们知道如何从Streams中读取数据,下一步是学习如何实现一个新的Readable数据流。为此,有必要通过继承stream.Readable的原型来创建一个新的类。 具体流必须提供_read()方法的实现:
readable._read(size)
Readable类的内部将调用_read()方法,而该方法又将启动
使用push()填充内部缓冲区:
请注意,read()是Stream消费者调用的方法,而_read()是一个由Stream子类实现的方法,不能直接调用。下划线通常表示该方法为私有方法,不应该直接调用。
为了演示如何实现新的可读Streams,我们可以尝试实现一个生成随机字符串的Streams。 我们来创建一个名为randomStream.js的新模块,它将包含我们的字符串的generator的代码:
const stream = require('stream');
const Chance = require('chance');
const chance = new Chance();
class RandomStream extends stream.Readable {
constructor(options) {
super(options);
}
_read(size) {
const chunk = chance.string(); //[1]
console.log(`Pushing chunk of size: ${chunk.length}`);
this.push(chunk, 'utf8'); //[2]
if (chance.bool({
likelihood: 5
})) { //[3]
this.push(null);
}
}
}
module.exports = RandomStream;在文件顶部,我们将加载我们的依赖关系。除了我们正在加载一个chance的npm模块之外,没有什么特别之处,它是一个用于生成各种随机值的库,从数字到字符串到整个句子都能生成随机值。
下一步是创建一个名为RandomStream的新类,并指定stream.Readable作为其父类。 在前面的代码中,我们调用父类的构造函数来初始化其内部状态,并将收到的options参数作为输入。通过options对象传递的可能参数包括以下内容:
用于将Buffers转换为Strings的encoding参数(默认值为null)
是否启用对象模式(objectMode默认为false)
存储在内部buffer区中的数据的上限,一旦超过这个上限,则暂停从data source读取(highWaterMark默认为16KB)
好的,现在让我们来解释一下我们重写的stream.Readable类的_read()方法:
该方法使用chance生成随机字符串。
它将字符串push内部buffer。 请注意,由于我们push的是String,此外我们还指定了编码为utf8(如果数据块只是一个二进制Buffer,则不需要)。
以5%的概率随机中断stream的随机字符串产生,通过push null到内部Buffer来表示EOF,即stream的结束。
我们还可以看到在_read()函数的输入中给出的size参数被忽略了,因为它是一个建议的参数。 我们可以简单地把所有可用的数据都push到内部的buffer中,但是如果在同一个调用中有多个推送,那么我们应该检查push()是否返回false,因为这意味着内部buffer已经达到了highWaterMark限制,我们应该停止添加更多的数据。
以上就是RandomStream模块,我们现在准备好使用它。我们来创建一个名为generateRandom.js的新模块,在这个模块中我们实例化一个新的RandomStream对象并从中提取一些数据:
const RandomStream = require('./randomStream');
const randomStream = new RandomStream();
randomStream.on('readable', () => {
let chunk;
while ((chunk = randomStream.read()) !== null) {
console.log(`Chunk received: ${chunk.toString()}`);
}
});现在,一切都准备好了,我们尝试新的自定义的stream。 像往常一样简单地执行generateRandom模块,观察随机的字符串在屏幕上流动。
一个可写的stream表示一个数据终点,在Node.js中,它使用stream模块中的Writable抽象类来实现。
把一些数据放在可写入的stream中是一件简单的事情, 我们所要做的就是使用write()方法,它具有以下格式:
writable.write(chunk, [encoding], [callback])
encoding参数是可选的,其在chunk是String类型时指定(默认为utf8,如果chunk是Buffer,则忽略);当数据块被刷新到底层资源中时,callback就会被调用,callback参数也是可选的。
为了表示没有更多的数据将被写入stream中,我们必须使用end()方法:
writable.end([chunk], [encoding], [callback])
我们可以通过end()方法提供最后一块数据。在这种情况下,callbak函数相当于为finish事件注册一个监听器,当数据块全部被写入stream中时,会触发该事件。
现在,让我们通过创建一个输出随机字符串序列的小型HTTP服务器来演示这是如何工作的:
const Chance = require('chance');
const chance = new Chance();
require('http').createServer((req, res) => {
res.writeHead(200, {
'Content-Type': 'text/plain'
}); //[1]
while (chance.bool({
likelihood: 95
})) { //[2]
res.write(chance.string() + '\n'); //[3]
}
res.end('\nThe end...\n'); //[4]
res.on('finish', () => console.log('All data was sent')); //[5]
}).listen(8080, () => console.log('Listening on http://localhost:8080'));我们创建了一个HTTP服务器,并把数据写入res对象,res对象是http.ServerResponse的一个实例,也是一个可写入的stream。下面来解释上述代码发生了什么:
我们首先写HTTP response的头部。请注意,writeHead()不是Writable接口的一部分,实际上,这个方法是http.ServerResponse类公开的辅助方法。
我们开始一个5%的概率终止的循环(进入循环体的概率为chance.bool()产生,其为95%)。
在循环内部,我们写入一个随机字符串到stream。
一旦我们不在循环中,我们调用stream的end(),表示没有更多
数据块将被写入。另外,我们在结束之前提供一个最终的字符串写入流中。
最后,我们注册一个finish事件的监听器,当所有的数据块都被刷新到底层socket中时,这个事件将被触发。
我们可以调用这个小模块称为entropyServer.js,然后执行它。要测试这个服务器,我们可以在地址http:// localhost:8080打开一个浏览器,或者从终端使用curl命令,如下所示:
curl localhost:8080
此时,服务器应该开始向您选择的HTTP客户端发送随机字符串(请注意,某些浏览器可能会缓冲数据,并且流式传输行为可能不明显)。
类似于在真实管道系统中流动的液体,Node.js的stream也可能遭受瓶颈,数据写入速度可能快于stream的消耗。 解决这个问题的机制包括缓冲输入数据;然而,如果数据stream没有给生产者任何反馈,我们可能会产生越来越多的数据被累积到内部缓冲区的情况,导致内存泄露的发生。
为了防止这种情况的发生,当内部buffer超过highWaterMark限制时,writable.write()将返回false。 可写入的stream具有highWaterMark属性,这是write()方法开始返回false的内部Buffer区大小的限制,一旦Buffer区的大小超过这个限制,表示应用程序应该停止写入。 当缓冲器被清空时,会触发一个叫做drain的事件,通知再次开始写入是安全的。 这种机制被称为back-pressure。
本节介绍的机制同样适用于可读的stream。事实上,在可读stream中也存在back-pressure,并且在_read()内调用的push()方法返回false时触发。 但是,这对于stream实现者来说是一个特定的问题,所以我们将不经常处理它。
我们可以通过修改之前创建的entropyServer模块来演示可写入的stream的back-pressure:
const Chance = require('chance');
const chance = new Chance();
require('http').createServer((req, res) => {
res.writeHead(200, {
'Content-Type': 'text/plain'
});
function generateMore() { //[1]
while (chance.bool({
likelihood: 95
})) {
const shouldContinue = res.write(
chance.string({
length: (16 * 1024) - 1
}) //[2]
);
if (!shouldContinue) { //[3]
console.log('Backpressure');
return res.once('drain', generateMore);
}
}
res.end('\nThe end...\n', () => console.log('All data was sent'));
}
generateMore();
}).listen(8080, () => console.log('Listening on http://localhost:8080'));前面代码中最重要的步骤可以概括如下:
我们将主逻辑封装在一个名为generateMore()的函数中。
为了增加获得一些back-pressure的机会,我们将数据块的大小增加到16KB-1Byte,这非常接近默认的highWaterMark限制。
在写入一大块数据之后,我们检查res.write()的返回值。 如果它返回false,这意味着内部buffer已满,我们应该停止发送更多的数据。在这种情况下,我们从函数中退出,然后新注册一个写入事件的发布者,当drain事件触发时调用generateMore。
如果我们现在尝试再次运行服务器,然后使用curl生成客户端请求,则很可能会有一些back-pressure,因为服务器以非常高的速度生成数据,速度甚至会比底层socket更快。
我们可以通过继承stream.Writable类来实现一个新的可写入的流,并为_write()方法提供一个实现。实现一个我们自定义的可写入的Streams类。
让我们构建一个可写入的stream,它接收对象的格式如下:
{
path: <path to a file>
content: <string or buffer>
}这个类的作用是这样的:对于每一个对象,我们的stream必须将content部分保存到在给定路径中创建的文件中。 我们可以立即看到,我们stream的输入是对象,而不是Strings或Buffers,这意味着我们的stream必须以对象模式工作。
调用模块toFileStream.js:
const stream = require('stream');
const fs = require('fs');
const path = require('path');
const mkdirp = require('mkdirp');
class ToFileStream extends stream.Writable {
constructor() {
super({
objectMode: true
});
}
_write(chunk, encoding, callback) {
mkdirp(path.dirname(chunk.path), err => {
if (err) {
return callback(err);
}
fs.writeFile(chunk.path, chunk.content, callback);
});
}
}
module.exports = ToFileStream;作为第一步,我们加载所有我们所需要的依赖包。注意,我们需要模块mkdirp,正如你应该从前几章中所知道的,它应该使用npm安装。
我们创建了一个新类,它从stream.Writable扩展而来。
我们不得不调用父构造函数来初始化其内部状态;我们还提供了一个option对象作为参数,用于指定流在对象模式下工作(objectMode:true)。stream.Writable接受的其他选项如下:
highWaterMark(默认值是16KB):控制back-pressure的上限。
decodeStrings(默认为true):在字符串传递给_write()方法之前,将字符串自动解码为二进制buffer区。 在对象模式下这个参数被忽略。
最后,我们为_write()方法提供了一个实现。正如你所看到的,这个方法接受一个数据块,一个编码方式(只有在二进制模式下,stream选项decodeStrings设置为false时才有意义)。
另外,该方法接受一个回调函数,该函数在操作完成时需要调用;而不必要传递操作的结果,但是如果需要的话,我们仍然可以传递一个error对象,这将导致stream触发error事件。
现在,为了尝试我们刚刚构建的stream,我们可以创建一个名为writeToFile.js的新模块,并对该流执行一些写操作:
const ToFileStream = require('./toFileStream.js');
const tfs = new ToFileStream();
tfs.write({path: "file1.txt", content: "Hello"});
tfs.write({path: "file2.txt", content: "Node.js"});
tfs.write({path: "file3.txt", content: "Streams"});
tfs.end(() => console.log("All files created"));有了这个,我们创建并使用了我们的第一个自定义的可写入流。 像往常一样运行新模块来检查其输出;你会看到执行后会创建三个新文件。
双重的stream既是可读的,也可写的。 当我们想描述一个既是数据源又是数据终点的实体时(例如socket),这就显得十分有用了。 双工流继承stream.Readable和stream.Writable的方法,所以它对我们来说并不新鲜。这意味着我们可以read()或write()数据,或者可以监听readable和drain事件。
要创建一个自定义的双重stream,我们必须为_read()和_write()提供一个实现。传递给Duplex()构造函数的options对象在内部被转发给Readable和Writable的构造函数。options参数的内容与前面讨论的相同,options增加了一个名为allowHalfOpen值(默认为true),如果设置为false,则会导致只要stream的一方(Readable和Writable)结束,stream就结束了。
为了使双重的stream在一方以对象模式工作,而在另一方以二进制模式工作,我们需要在流构造器中手动设置以下属性:
this._writableState.objectMode this._readableState.objectMode
转换的Streams是专门设计用于处理数据转换的一种特殊类型的双重Streams。
在一个简单的双重Streams中,从stream中读取的数据和写入到其中的数据之间没有直接的关系(至少stream是不可知的)。 想想一个TCP socket,它只是向远程节点发送数据和从远程节点接收数据。TCP socket自身没有意识到输入和输出之间有任何关系。
下图说明了双重Streams中的数据流:
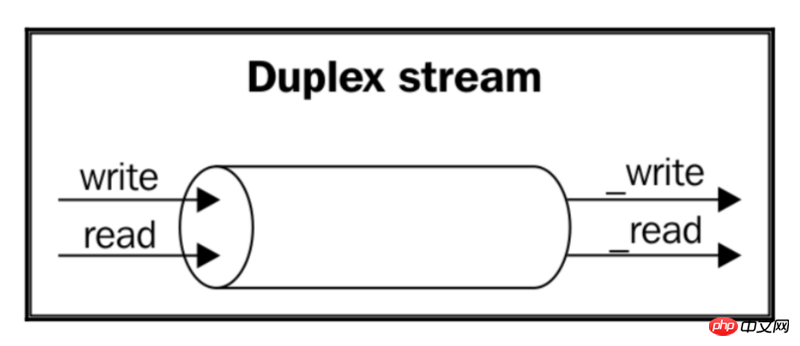
另一方面,转换的Streams对从可写入端接收到的每个数据块应用某种转换,然后在其可读端使转换的数据可用。
下图显示了数据如何在转换的Streams中流动:
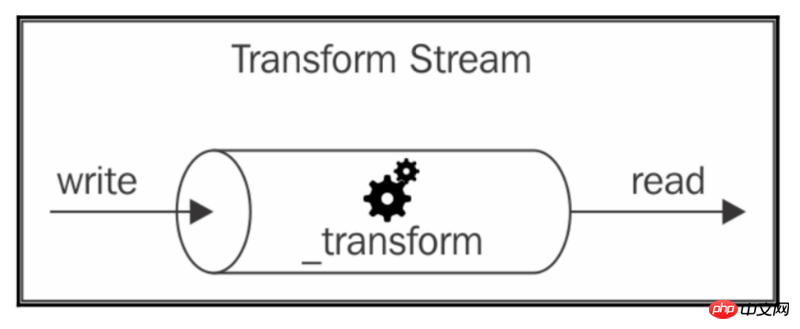
从外面看,转换的Streams的接口与双重Streams的接口完全相同。但是,当我们想要构建一个新的双重Streams时,我们必须提供_read()和_write()方法,而为了实现一个新的变换流,我们必须填写另一对方法:_transform()和_flush())。
我们来演示如何用一个例子来创建一个新的转换的Streams。
我们来实现一个转换的Streams,它将替换给定所有出现的字符串。 要做到这一点,我们必须创建一个名为replaceStream.js的新模块。 让我们直接看怎么实现它:
const stream = require('stream');
const util = require('util');
class ReplaceStream extends stream.Transform {
constructor(searchString, replaceString) {
super();
this.searchString = searchString;
this.replaceString = replaceString;
this.tailPiece = '';
}
_transform(chunk, encoding, callback) {
const pieces = (this.tailPiece + chunk) //[1]
.split(this.searchString);
const lastPiece = pieces[pieces.length - 1];
const tailPieceLen = this.searchString.length - 1;
this.tailPiece = lastPiece.slice(-tailPieceLen); //[2]
pieces[pieces.length - 1] = lastPiece.slice(0,-tailPieceLen);
this.push(pieces.join(this.replaceString)); //[3]
callback();
}
_flush(callback) {
this.push(this.tailPiece);
callback();
}
}
module.exports = ReplaceStream;与往常一样,我们将从其依赖项开始构建模块。这次我们没有使用第三方模块。
然后我们创建了一个从stream.Transform基类继承的新类。该类的构造函数接受两个参数:searchString和replaceString。 正如你所想象的那样,它们允许我们定义要匹配的文本以及用作替换的字符串。 我们还初始化一个将由_transform()方法使用的tailPiece内部变量。
现在,我们来分析一下_transform()方法,它是我们新类的核心。_transform()方法与可写入的stream的_write()方法具有几乎相同的格式,但不是将数据写入底层资源,而是使用this.push()将其推入内部buffer,这与我们会在可读流的_read()方法中执行。这显示了转换的Streams的双方如何实际连接。
ReplaceStream的_transform()方法实现了我们这个新类的核心。正常情况下,搜索和替换buffer区中的字符串是一件容易的事情;但是,当数据流式传输时,情况则完全不同,可能的匹配可能分布在多个数据块中。代码后面的程序可以解释如下:
我们的算法使用searchString函数作为分隔符来分割块。
然后,它取出分隔后生成的数组的最后一项lastPiece,并提取其最后一个字符searchString.length - 1。结果被保存到tailPiece变量中,它将会被作为下一个数据块的前缀。
最后,所有从split()得到的片段用replaceString作为分隔符连接在一起,并推入内部buffer区。
当stream结束时,我们可能仍然有最后一个tailPiece变量没有被压入内部缓冲区。这正是_flush()方法的用途;它在stream结束之前被调用,并且这是我们最终有机会完成流或者在完全结束流之前推送任何剩余数据的地方。
_flush()方法只需要一个回调函数作为参数,当所有的操作完成后,我们必须确保调用这个回调函数。完成了这个,我们已经完成了我们的ReplaceStream类。
现在,是时候尝试新的stream。我们可以创建另一个名为replaceStreamTest.js的模块来写入一些数据,然后读取转换的结果:
const ReplaceStream = require('./replaceStream');
const rs = new ReplaceStream('World', 'Node.js');
rs.on('data', chunk => console.log(chunk.toString()));
rs.write('Hello W');
rs.write('orld!');
rs.end();为了使得这个例子更复杂一些,我们把搜索词分布在两个不同的数据块上;然后,使用flowing模式,我们从同一个stream中读取数据,记录每个已转换的块。运行前面的程序应该产生以下输出:
Hel lo Node.js !
有一个值得提及是,第五种类型的stream:stream.PassThrough。 与我们介绍的其他流类不同,PassThrough不是抽象的,可以直接实例化,而不需要实现任何方法。实际上,这是一个可转换的stream,它可以输出每个数据块,而不需要进行任何转换。
Unix管道的概念是由Douglas Mcllroy发明的;这使程序的输出能够连接到下一个的输入。看看下面的命令:
echo Hello World! | sed s/World/Node.js/g
在前面的命令中,echo会将Hello World!写入标准输出,然后被重定向到sed命令的标准输入(因为有管道操作符 |)。 然后sed用Node.js替换任何World,并将结果打印到它的标准输出(这次是控制台)。
以类似的方式,可以使用可读的Streams的pipe()方法将Node.js的Streams连接在一起,它具有以下接口:
readable.pipe(writable, [options])
非常直观地,pipe()方法将从可读的Streams中发出的数据抽取到所提供的可写入的Streams中。 另外,当可读的Streams发出end事件(除非我们指定{end:false}作为options)时,可写入的Streams将自动结束。 pipe()方法返回作为参数传递的可写入的Streams,如果这样的stream也是可读的(例如双重或可转换的Streams),则允许我们创建链式调用。
将两个Streams连接到一起时,则允许数据自动流向可写入的Streams,所以不需要调用read()或write()方法;但最重要的是不需要控制back-pressure,因为它会自动处理。
举个简单的例子(将会有大量的例子),我们可以创建一个名为replace.js的新模块,它接受来自标准输入的文本流,应用替换转换,然后将数据返回到标准输出:
const ReplaceStream = require('./replaceStream');
process.stdin
.pipe(new ReplaceStream(process.argv[2], process.argv[3]))
.pipe(process.stdout);上述程序将来自标准输入的数据传送到ReplaceStream,然后返回到标准输出。 现在,为了实践这个小应用程序,我们可以利用Unix管道将一些数据重定向到它的标准输入,如下所示:
echo Hello World! | node replace World Node.js
运行上述程序,会输出如下结果:
Hello Node.js
这个简单的例子演示了Streams(特别是文本Streams)是一个通用接口,管道几乎是构成和连接所有这些接口的通用方式。
error事件不会通过管道自动传播。举个例子,看如下代码片段:
stream1
.pipe(stream2)
.on('error', function() {});在前面的链式调用中,我们将只捕获来自stream2的错误,这是由于我们给其添加了erorr事件侦听器。这意味着,如果我们想捕获从stream1生成的任何错误,我们必须直接附加另一个错误侦听器。 稍后我们将看到一种可以实现共同错误捕获的另一种模式(合并Streams)。 此外,我们应该注意到,如果目标Streams(读取的Streams)发出错误,它将会对源Streams通知一个error,之后导致管道的中断。
到目前为止,我们创建自定义Streams的方式并不完全遵循Node定义的模式;实际上,从stream基类继承是违反small surface area的,并需要一些示例代码。 这并不意味着Streams设计得不好,实际上,我们不应该忘记,因为Streams是Node.js核心的一部分,所以它们必须尽可能地灵活,广泛拓展Streams以致于用户级模块能够将它们充分运用。
然而,大多数情况下,我们并不需要原型继承可以给予的所有权力和可扩展性,但通常我们想要的仅仅是定义新Streams的一种快速开发的模式。Node.js社区当然也为此创建了一个解决方案。 一个完美的例子是through2,一个使得我们可以简单地创建转换的Streams的小型库。 通过through2,我们可以通过调用一个简单的函数来创建一个新的可转换的Streams:
const transform = through2([options], [_transform], [_flush]);
类似的,from2也允许我们像下面这样创建一个可读的Streams:
const readable = from2([options], _read);
接下来,我们将在本章其余部分展示它们的用法,那时,我们会清楚使用这些小型库的好处。
through和from是基于Stream1规范的顶层库。
通过我们已经介绍的例子,应该清楚的是,Streams不仅可以用来处理I / O,而且可以用作处理任何类型数据的优雅编程模式。 但优点并不止这些;还可以利用Streams来实现异步控制流,在本节将会看到。
默认情况下,Streams将按顺序处理数据;例如,转换的Streams的_transform()函数在前一个数据块执行callback()之后才会进行下一块数据块的调用。这是Streams的一个重要属性,按正确顺序处理每个数据块至关重要,但是也可以利用这一属性将Streams实现优雅的传统控制流模式。
代码总是比太多的解释要好得多,所以让我们来演示一下如何使用流来按顺序执行异步任务的例子。让我们创建一个函数来连接一组接收到的文件作为输入,确保遵守提供的顺序。我们创建一个名为concatFiles.js的新模块,并从其依赖开始:
const fromArray = require('from2-array');
const through = require('through2');
const fs = require('fs');我们将使用through2来简化转换的Streams的创建,并使用from2-array从一个对象数组中创建可读的Streams。
接下来,我们可以定义concatFiles()函数:
function concatFiles(destination, files, callback) {
const destStream = fs.createWriteStream(destination);
fromArray.obj(files) //[1]
.pipe(through.obj((file, enc, done) => { //[2]
const src = fs.createReadStream(file);
src.pipe(destStream, {end: false});
src.on('end', done); //[3]
}))
.on('finish', () => { //[4]
destStream.end();
callback();
});
}
module.exports = concatFiles;前面的函数通过将files数组转换为Streams来实现对files数组的顺序迭代。 该函数所遵循的程序解释如下:
首先,我们使用from2-array从files数组创建一个可读的Streams。
接下来,我们使用through来创建一个转换的Streams来处理序列中的每个文件。对于每个文件,我们创建一个可读的Streams,并通过管道将其输入到表示输出文件的destStream中。 在源文件完成读取后,通过在pipe()方法的第二个参数中指定{end:false},我们确保不关闭destStream。
当源文件的所有内容都被传送到destStream时,我们调用through.obj公开的done函数来传递当前处理已经完成,在我们的情况下这是需要触发处理下一个文件。
所有文件处理完后,finish事件被触发。我们最后可以结束destStream并调用concatFiles()的callback()函数,这个函数表示整个操作的完成。
我们现在可以尝试使用我们刚刚创建的小模块。让我们创建一个名为concat.js的新文件来完成一个示例:
const concatFiles = require('./concatFiles');
concatFiles(process.argv[2], process.argv.slice(3), () => {
console.log('Files concatenated successfully');
});我们现在可以运行上述程序,将目标文件作为第一个命令行参数,接着是要连接的文件列表,例如:
node concat allTogether.txt file1.txt file2.txt
执行这一条命令,会创建一个名为allTogether.txt的新文件,其中按顺序保存file1.txt和file2.txt的内容。
使用concatFiles()函数,我们能够仅使用Streams实现异步操作的顺序执行。正如我们在Chapter3 Asynchronous Control Flow Patters with Callbacks中看到的那样,如果使用纯JavaScript实现,或者使用async等外部库,则需要使用或实现迭代器。我们现在提供了另外一个可以达到同样效果的方法,正如我们所看到的,它的实现方式非常优雅且可读性高。
模式:使用Streams或Streams的组合,可以轻松地按顺序遍历一组异步任务。
我们刚刚看到Streams按顺序处理每个数据块,但有时这可能并不能这么做,因为这样并没有充分利用Node.js的并发性。如果我们必须对每个数据块执行一个缓慢的异步操作,那么并行化执行这一组异步任务完全是有必要的。当然,只有在每个数据块之间没有关系的情况下才能应用这种模式,这些数据块可能经常发生在对象模式的Streams中,但是对于二进制模式的Streams很少使用无序的并行执行。
注意:当处理数据的顺序很重要时,不能使用无序并行执行的Streams。
为了并行化一个可转换的Streams的执行,我们可以运用Chapter3 Asynchronous Control Flow Patters with Callbacks所讲到的无序并行执行的相同模式,然后做出一些改变使它们适用于Streams。让我们看看这是如何更改的。
让我们用一个例子直接说明:我们创建一个叫做parallelStream.js的模块,然后自定义一个普通的可转换的Streams,然后给出一系列可转换流的方法:
const stream = require('stream');
class ParallelStream extends stream.Transform {
constructor(userTransform) {
super({objectMode: true});
this.userTransform = userTransform;
this.running = 0;
this.terminateCallback = null;
}
_transform(chunk, enc, done) {
this.running++;
this.userTransform(chunk, enc, this._onComplete.bind(this), this.push.bind(this));
done();
}
_flush(done) {
if(this.running > 0) {
this.terminateCallback = done;
} else {
done();
}
}
_onComplete(err) {
this.running--;
if(err) {
return this.emit('error', err);
}
if(this.running === 0) {
this.terminateCallback && this.terminateCallback();
}
}
}
module.exports = ParallelStream;我们来分析一下这个新的自定义的类。正如你所看到的一样,构造函数接受一个userTransform()函数作为参数,然后将其另存为一个实例变量;我们也调用父构造函数,并且我们默认启用对象模式。
接下来,来看_transform()方法,在这个方法中,我们执行userTransform()函数,然后增加当前正在运行的任务个数; 最后,我们通过调用done()来通知当前转换步骤已经完成。_transform()方法展示了如何并行处理另一项任务。我们不用等待userTransform()方法执行完毕再调用done()。 相反,我们立即执行done()方法。另一方面,我们提供了一个特殊的回调函数给userTransform()方法,这就是this._onComplete()方法;以便我们在userTransform()完成的时候收到通知。
在Streams终止之前,会调用_flush()方法,所以如果仍有任务正在运行,我们可以通过不立即调用done()回调函数来延迟finish事件的触发。相反,我们将其分配给this.terminateCallback变量。为了理解Streams如何正确终止,来看_onComplete()方法。
在每组异步任务最终完成时,_onComplete()方法会被调用。首先,它会检查是否有任务正在运行,如果没有,则调用this.terminateCallback()函数,这将导致Streams结束,触发_flush()方法的finish事件。
利用刚刚构建的ParallelStream类可以轻松地创建一个无序并行执行的可转换的Streams实例,但是有个注意:它不会保留项目接收的顺序。实际上,异步操作可以在任何时候都有可能完成并推送数据,而跟它们开始的时刻并没有必然的联系。因此我们知道,对于二进制模式的Streams并不适用,因为二进制的Streams对顺序要求较高。
现在,让我们使用ParallelStream模块实现一个具体的例子。让我们想象以下我们想要构建一个简单的服务来监控一个大URL列表的状态,让我们想象以下,所有的这些URL包含在一个单独的文件中,并且每一个URL占据一个空行。
Streams能够为这个场景提供一个高效且优雅的解决方案。特别是当我们使用我们刚刚写的ParallelStream类来无序地审核这些URL。
接下来,让我们创建一个简单的放在checkUrls.js模块的应用程序。
const fs = require('fs');
const split = require('split');
const request = require('request');
const ParallelStream = require('./parallelStream');
fs.createReadStream(process.argv[2]) //[1]
.pipe(split()) //[2]
.pipe(new ParallelStream((url, enc, done, push) => { //[3]
if(!url) return done();
request.head(url, (err, response) => {
push(url + ' is ' + (err ? 'down' : 'up') + '\n');
done();
});
}))
.pipe(fs.createWriteStream('results.txt')) //[4]
.on('finish', () => console.log('All urls were checked'))
;正如我们所看到的,通过流,我们的代码看起来非常优雅,直观。 让我们看看它是如何工作的:
首先,我们通过给定的文件参数创建一个可读的Streams,便于接下来读取文件。
我们通过split将输入的文件的Streams的内容输出一个可转换的Streams到管道中,并且分隔了数据块的每一行。
然后,是时候使用我们的ParallelStream来检查URL了,我们发送一个HEAD请求然后等待请求的response。当请求返回时,我们把请求的结果push到stream中。
最后,通过管道把结果保存到results.txt文件中。
node checkUrls urlList.txt
这里的文件urlList.txt包含一组URL,例如:
http://www.mariocasciaro.me/
http://loige.co/
http://thiswillbedownforsure.com/
当应用执行完成后,我们可以看到一个文件results.txt被创建,里面包含有操作的结果,例如:
http://thiswillbedownforsure.com is down
http://loige.co is up
http://www.mariocasciaro.me is up
输出的结果的顺序很有可能与输入文件中指定URL的顺序不同。这是Streams无序并行执行任务的明显特征。
出于好奇,我们可能想尝试用一个正常的through2流替换ParallelStream,并比较两者的行为和性能(你可能想这样做的一个练习)。我们将会看到,使用through2的方式会比较慢,因为每个URL都将按顺序进行检查,而且文件results.txt中结果的顺序也会被保留。
如果运行包含数千或数百万个URL的文件的checkUrls应用程序,我们肯定会遇到麻烦。我们的应用程序将同时创建不受控制的连接数量,并行发送大量数据,并可能破坏应用程序的稳定性和整个系统的可用性。我们已经知道,控制负载的无序限制并行执行是一个极好的解决方案。
让我们通过创建一个limitedParallelStream.js模块来看看它是如何工作的,这个模块是改编自上一节中创建的parallelStream.js模块。
让我们看看它的构造函数:
class LimitedParallelStream extends stream.Transform {
constructor(concurrency, userTransform) {
super({objectMode: true});
this.concurrency = concurrency;
this.userTransform = userTransform;
this.running = 0;
this.terminateCallback = null;
this.continueCallback = null;
}
// ...
}我们需要一个concurrency变量作为输入来限制并发量,这次我们要保存两个回调函数,continueCallback用于任何挂起的_transform方法,terminateCallback用于_flush方法的回调。
接下来看_transform()方法:
_transform(chunk, enc, done) {
this.running++;
this.userTransform(chunk, enc, this.push.bind(this), this._onComplete.bind(this));
if(this.running < this.concurrency) {
done();
} else {
this.continueCallback = done;
}
}这次在_transform()方法中,我们必须在调用done()之前检查是否达到了最大并行数量的限制,如果没有达到了限制,才能触发下一个项目的处理。如果我们已经达到最大并行数量的限制,我们可以简单地将done()回调保存到continueCallback变量中,以便在任务完成后立即调用它。
_flush()方法与ParallelStream类保持完全一样,所以我们直接转到实现_onComplete()方法:
_onComplete(err) {
this.running--;
if(err) {
return this.emit('error', err);
}
const tmpCallback = this.continueCallback;
this.continueCallback = null;
tmpCallback && tmpCallback();
if(this.running === 0) {
this.terminateCallback && this.terminateCallback();
}
}每当任务完成,我们调用任何已保存的continueCallback()将导致stream解锁,触发下一个项目的处理。
这就是limitedParallelStream模块。 我们现在可以在checkUrls模块中使用它来代替parallelStream,并且将我们的任务的并发限制在我们设置的值上。
我们以前创建的并行Streams可能会使得数据的顺序混乱,但是在某些情况下这是不可接受的。有时,实际上,有那种需要每个数据块都以接收到的相同顺序发出的业务场景。我们仍然可以并行运行transform函数。我们所要做的就是对每个任务发出的数据进行排序,使其遵循与接收数据相同的顺序。
这种技术涉及使用buffer,在每个正在运行的任务发出时重新排序块。为简洁起见,我们不打算提供这样一个stream的实现,因为这本书的范围是相当冗长的;我们要做的就是重用为了这个特定目的而构建的npm上的一个可用包,例如through2-parallel。
我们可以通过修改现有的checkUrls模块来快速检查一个有序的并行执行的行为。 假设我们希望我们的结果按照与输入文件中的URL相同的顺序编写。 我们可以使用通过through2-parallel来实现:
const fs = require('fs');
const split = require('split');
const request = require('request');
const throughParallel = require('through2-parallel');
fs.createReadStream(process.argv[2])
.pipe(split())
.pipe(throughParallel.obj({concurrency: 2}, function (url, enc, done) {
if(!url) return done();
request.head(url, (err, response) => {
this.push(url + ' is ' + (err ? 'down' : 'up') + '\n');
done();
});
}))
.pipe(fs.createWriteStream('results.txt'))
.on('finish', () => console.log('All urls were checked'))
;正如我们所看到的,through2-parallel的接口与through2的接口非常相似;唯一的不同是在through2-parallel还可以为我们提供的transform函数指定一个并发限制。如果我们尝试运行这个新版本的checkUrls,我们会看到results.txt文件列出结果的顺序与输入文件中
URLs的出现顺序是一样的。
通过这个,我们总结了使用Streams实现异步控制流的分析;接下来,我们研究管道模式。
就像在现实生活中一样,Node.js的Streams也可以按照不同的模式进行管道连接。事实上,我们可以将两个不同的Streams合并成一个Streams,将一个Streams分成两个或更多的管道,或者根据条件重定向流。 在本节中,我们将探讨可应用于Node.js的Streams最重要的管道技术。
在本章中,我们强调Streams提供了一个简单的基础结构来模块化和重用我们的代码,但是却漏掉了一个重要的部分:如果我们想要模块化和重用整个流水线?如果我们想要合并多个Streams,使它们看起来像外部的Streams,那该怎么办?下图显示了这是什么意思:
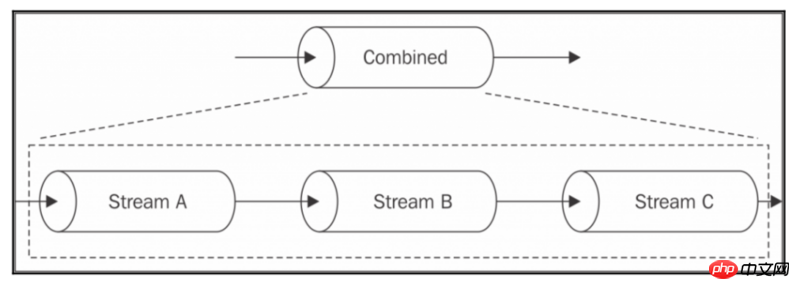
从上图中,我们看到了如何组合几个流的了:
当我们写入组合的Streams的时候,实际上我们是写入组合的Streams的第一个单元,即StreamA。
当我们从组合的Streams中读取信息时,实际上我们从组合的Streams的最后一个单元中读取。
一个组合的Streams通常是一个多重的Streams,通过连接第一个单元的写入端和连接最后一个单元的读取端。
要从两个不同的Streams(一个可读的Streams和一个可写入的Streams)中创建一个多重的Streams,我们可以使用一个npm模块,例如duplexer2。
但上述这么做并不完整。实际上,组合的Streams还应该做到捕获到管道中任意一段Streams单元产生的错误。我们已经说过,任何错误都不会自动传播到管道中。 所以,我们必须有适当的错误管理,我们将不得不显式附加一个错误监听器到每个Streams。但是,组合的Streams实际上是一个黑盒,这意味着我们无法访问管道中间的任何单元,所以对于管道中任意单元的异常捕获,组合的Streams也充当聚合器的角色。
总而言之,组合的Streams具有两个主要优点:
管道内部是一个黑盒,对使用者不可见。
简化了错误管理,因为我们不必为管道中的每个单元附加一个错误侦听器,而只需要给组合的Streams自身附加上就可以了。
组合的Streams是一个非常通用和普遍的做法,所以如果我们没有任何特殊的需要,我们可能只想重用现有的解决方案,如multipipe或combine-stream。
为了说明一个简单的例子,我们来考虑下面两个组合的Streams的情况:
压缩和加密数据
解压和解密数据
使用诸如multipipe之类的库,我们可以通过组合一些核心库中已有的Streams(文件combinedStreams.js)来轻松地构建组合的Streams:
const zlib = require('zlib');
const crypto = require('crypto');
const combine = require('multipipe');
module.exports.compressAndEncrypt = password => {
return combine(
zlib.createGzip(),
crypto.createCipher('aes192', password)
);
};
module.exports.decryptAndDecompress = password => {
return combine(
crypto.createDecipher('aes192', password),
zlib.createGunzip()
);
};例如,我们现在可以使用这些组合的数据流,如同黑盒,这些对我们均是不可见的,可以创建一个小型应用程序,通过压缩和加密来归档文件。 让我们在一个名为archive.js的新模块中做这件事:
const fs = require('fs');
const compressAndEncryptStream = require('./combinedStreams').compressAndEncrypt;
fs.createReadStream(process.argv[3])
.pipe(compressAndEncryptStream(process.argv[2]))
.pipe(fs.createWriteStream(process.argv[3] + ".gz.enc"));我们可以通过从我们创建的流水线中构建一个组合的Stream来进一步改进前面的代码,但这次并不只是为了获得对外不可见的黑盒,而是为了进行异常捕获。 实际上,正如我们已经提到过的那样,写下如下的代码只会捕获最后一个Stream单元发出的错误:
fs.createReadStream(process.argv[3])
.pipe(compressAndEncryptStream(process.argv[2]))
.pipe(fs.createWriteStream(process.argv[3] + ".gz.enc"))
.on('error', function(err) {
// 只会捕获最后一个单元的错误
console.log(err);
});但是,通过把所有的Streams结合在一起,我们可以优雅地解决这个问题。重构后的archive.js如下:
const combine = require('multipipe');
const fs = require('fs');
const compressAndEncryptStream =
require('./combinedStreams').compressAndEncrypt;
combine(
fs.createReadStream(process.argv[3])
.pipe(compressAndEncryptStream(process.argv[2]))
.pipe(fs.createWriteStream(process.argv[3] + ".gz.enc"))
).on('error', err => {
// 使用组合的Stream可以捕获任意位置的错误
console.log(err);
});正如我们所看到的,我们现在可以将一个错误侦听器直接附加到组合的Streams,它将接收任何内部流发出的任何error事件。
现在,要运行archive模块,只需在命令行参数中指定password和file参数,即压缩模块的参数:
node archive mypassword /path/to/a/file.text
通过这个例子,我们已经清楚地证明了组合的Stream是多么重要; 从一个方面来说,它允许我们创建流的可重用组合,从另一方面来说,它简化了管道的错误管理。
Streams
我们可以通过将单个可读的Stream管道化为多个可写入的Stream来执行Stream的分支。当我们想要将相同的数据发送到不同的目的地时,这便体现其作用了,例如,两个不同的套接字或两个不同的文件。当我们想要对相同的数据执行不同的转换时,或者当我们想要根据一些标准拆分数据时,也可以使用它。如图所示:
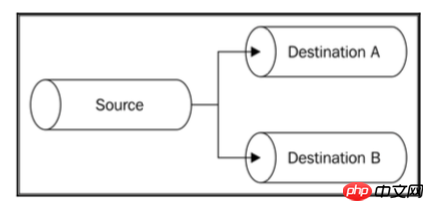
在Node.js中分开的Stream是一件小事。举例说明。
让我们创建一个输出给定文件的sha1和md5散列的小工具。我们来调用这个新模块generateHashes.js,看如下的代码:
const fs = require('fs');
const crypto = require('crypto');
const sha1Stream = crypto.createHash('sha1');
sha1Stream.setEncoding('base64');
const md5Stream = crypto.createHash('md5');
md5Stream.setEncoding('base64');目前为止没什么特别的 该模块的下一个部分实际上是我们将从文件创建一个可读的Stream,并将其分叉到两个不同的流,以获得另外两个文件,其中一个包含sha1散列,另一个包含md5校验和:
const inputFile = process.argv[2]; const inputStream = fs.createReadStream(inputFile); inputStream .pipe(sha1Stream) .pipe(fs.createWriteStream(inputFile + '.sha1')); inputStream .pipe(md5Stream) .pipe(fs.createWriteStream(inputFile + '.md5'));
这很简单:inputStream变量通过管道一边输入到sha1Stream,另一边输入到md5Stream。但是要注意:
当inputStream结束时,md5Stream和sha1Stream会自动结束,除非当调用pipe()时指定了end选项为false。
Stream的两个分支会接受相同的数据块,因此当对数据执行一些副作用的操作时我们必须非常谨慎,因为那样会影响另外一个分支。
黑盒外会产生背压,来自inputStream的数据流的流速会根据接收最慢的分支的流速作出调整。
Streams
合并与分开相对,通过把一组可读的Streams合并到一个单独的可写的Stream里,如图所示:
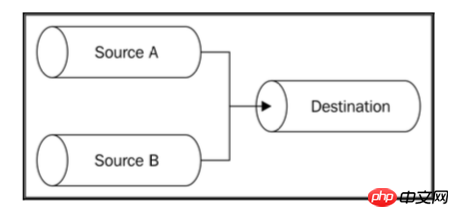
将多个Streams合并为一个通常是一个简单的操作; 然而,我们必须注意我们处理end事件的方式,因为使用自动结束选项的管道系统会在一个源结束时立即结束目标流。 这通常会导致错误,因为其他还未结束的源将继续写入已终止的Stream。 解决此问题的方法是在将多个源传输到单个目标时使用选项{end:false},并且只有在所有源完成读取后才在目标Stream上调用end()。
举一个简单的例子,我们来实现一个小程序,它根据两个不同目录的内容创建一个压缩包。 为此,我们将介绍两个新的npm模块:
tar用来创建压缩包
fstream从文件系统文件创建对象streams的库
我们创建一个新模块mergeTar.js,如下开始初始化:
var tar = require('tar');
var fstream = require('fstream');
var path = require('path');
var destination = path.resolve(process.argv[2]);
var sourceA = path.resolve(process.argv[3]);
var sourceB = path.resolve(process.argv[4]);在前面的代码中,我们只加载全部依赖包和初始化包含目标文件和两个源目录(sourceA和sourceB)的变量。
接下来,我们创建tar的Stream并通过管道输出到一个可写入的Stream:
const pack = tar.Pack(); pack.pipe(fstream.Writer(destination));
现在,我们开始初始化源Stream
let endCount = 0;
function onEnd() {
if (++endCount === 2) {
pack.end();
}
}
const sourceStreamA = fstream.Reader({
type: "Directory",
path: sourceA
})
.on('end', onEnd);
const sourceStreamB = fstream.Reader({
type: "Directory",
path: sourceB
})
.on('end', onEnd);在前面的代码中,我们创建了从两个源目录(sourceStreamA和sourceStreamB)中读取的Stream那么对于每个源Stream,我们附加一个end事件订阅者,只有当这两个目录被完全读取时,才会触发pack的end事件。
最后,合并两个Stream:
sourceStreamA.pipe(pack, {end: false});
sourceStreamB.pipe(pack, {end: false});我们将两个源文件都压缩到pack这个Stream中,并通过设定pipe()的option参数为{end:false}配置终点Stream的自动触发end事件。
这样,我们已经完成了我们简单的TAR程序。我们可以通过提供目标文件作为第一个命令行参数,然后是两个源目录来尝试运行这个实用程序:
node mergeTar dest.tar /path/to/sourceA /path/to/sourceB
在npm中我们可以找到一些可以简化Stream的合并的模块:
merge-stream
multistream-merge
要注意,流入目标Stream的数据是随机混合的,这是一个在某些类型的对象流中可以接受的属性(正如我们在上一个例子中看到的那样),但是在处理二进制Stream时通常是一个不希望这样。
然而,我们可以通过一种模式按顺序合并Stream; 它包含一个接一个地合并源Stream,当前一个结束时,开始发送第二段数据块(就像连接所有源Stream的输出一样)。在npm上,我们可以找到一些也处理这种情况的软件包。其中之一是multistream。
合并Stream模式有一个特殊的模式,我们并不是真的只想将多个Stream合并在一起,而是使用一个共享通道来传送一组数据Stream。与之前的不一样,因为源数据Stream在共享通道内保持逻辑分离,这使得一旦数据到达共享通道的另一端,我们就可以再次分离数据Stream。如图所示:
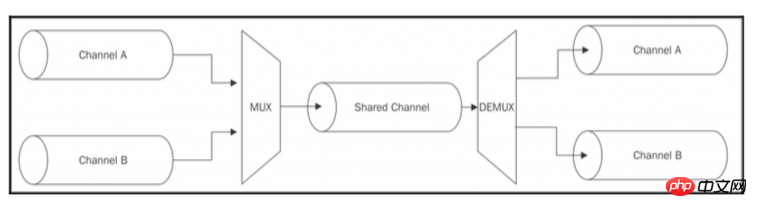
将多个Stream组合在单个Stream上传输的操作被称为多路复用,而相反的操作(即,从共享Stream接收数据重构原始的Stream)则被称为多路分用。执行这些操作的设备分别称为多路复用器和多路分解器(。 这是一个在计算机科学和电信领域广泛研究的话题,因为它是几乎任何类型的通信媒体,如电话,广播,电视,当然还有互联网本身的基础之一。 对于本书的范围,我们不会过多解释,因为这是一个很大的话题。
我们想在本节中演示的是,如何使用共享的Node.js Streams来传送多个逻辑上分离的Stream,然后在共享Stream的另一端再次分离,即实现一次多路复用和多路分解。
举例说明,我们希望有一个小程序来启动子进程,并将其标准输出和标准错误都重定向到远程服务器,服务器接受它们然后保存为两个单独的文件。因此,在这种情况下,共享介质是TCP连接,而要复用的两个通道是子进程的stdout和stderr。 我们将利用分组交换的技术,这种技术与IP,TCP或UDP等协议所使用的技术相同,包括将数据封装在数据包中,允许我们指定各种源信息,这对多路复用,路由,控制 流程,检查损坏的数据都十分有帮助。
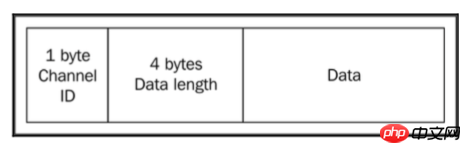
如图所示,这个例子的协议大概是这样,数据被封装成具有以下结构的数据包:
先说客户端,创建一个名为client.js的模块,这是我们这个应用程序的一部分,它负责启动一个子进程并实现Stream多路复用。
开始定义模块,首先加载依赖:
const child_process = require('child_process');
const net = require('net');然后开始实现多路复用的函数:
function multiplexChannels(sources, destination) {
let totalChannels = sources.length;
for(let i = 0; i < sources.length; i++) {
sources[i]
.on('readable', function() { // [1]
let chunk;
while ((chunk = this.read()) !== null) {
const outBuff = new Buffer(1 + 4 + chunk.length); // [2]
outBuff.writeUInt8(i, 0);
outBuff.writeUInt32BE(chunk.length, 1);
chunk.copy(outBuff, 5);
console.log('Sending packet to channel: ' + i);
destination.write(outBuff); // [3]
}
})
.on('end', () => { //[4]
if (--totalChannels === 0) {
destination.end();
}
});
}
}multiplexChannels()函数接受要复用的源Stream作为输入
和复用接口作为参数,然后执行以下步骤:
对于每个源Stream,它会注册一个readable事件侦听器,我们使用non-flowing模式从流中读取数据。
每读取一个数据块,我们将其封装到一个首部中,首部的顺序为:channel ID为1字节(UInt8),数据包大小为4字节(UInt32BE),然后为实际数据。
数据包准备好后,我们将其写入目标Stream。
我们为end事件注册一个监听器,以便当所有源Stream结束时,end事件触发,通知目标Stream触发end事件。
注意,我们的协议最多能够复用多达256个不同的源流,因为我们只有1个字节来标识channel。
const socket = net.connect(3000, () => { // [1]
const child = child_process.fork( // [2]
process.argv[2],
process.argv.slice(3), {
silent: true
}
);
multiplexChannels([child.stdout, child.stderr], socket); // [3]
});在最后,我们执行以下操作:
我们创建一个新的TCP客户端连接到地址localhost:3000。
我们通过使用第一个命令行参数作为路径来启动子进程,同时我们提供剩余的process.argv数组作为子进程的参数。我们指定选项{silent:true},以便子进程不会继承父级的stdout和stderr。
我们使用mutiplexChannels()函数将stdout和stderr多路复用到socket里。
现在来看服务端,创建server.js模块,在这里我们将来自远程连接的Stream多路分解,并将它们传送到两个不同的文件中。
首先创建一个名为demultiplexChannel()的函数:
function demultiplexChannel(source, destinations) {
let currentChannel = null;
let currentLength = null;
source
.on('readable', () => { //[1]
let chunk;
if(currentChannel === null) { //[2]
chunk = source.read(1);
currentChannel = chunk && chunk.readUInt8(0);
}
if(currentLength === null) { //[3]
chunk = source.read(4);
currentLength = chunk && chunk.readUInt32BE(0);
if(currentLength === null) {
return;
}
}
chunk = source.read(currentLength); //[4]
if(chunk === null) {
return;
}
console.log('Received packet from: ' + currentChannel);
destinations[currentChannel].write(chunk); //[5]
currentChannel = null;
currentLength = null;
})
.on('end', () => { //[6]
destinations.forEach(destination => destination.end());
console.log('Source channel closed');
})
;
}上面的代码可能看起来很复杂,仔细阅读并非如此;由于Node.js可读的Stream的拉动特性,我们可以很容易地实现我们的小协议的多路分解,如下所示:
我们开始使用non-flowing模式从流中读取数据。
首先,如果我们还没有读取channel ID,我们尝试从流中读取1个字节,然后将其转换为数字。
下一步是读取首部的长度。我们需要读取4个字节,所以有可能在内部Buffer还没有足够的数据,这将导致this.read()调用返回null。在这种情况下,我们只是中断解析,然后重试下一个readable事件。
当我们最终还可以读取数据大小时,我们知道从内部Buffer中拉出多少数据,所以我们尝试读取所有数据。
当我们读取所有的数据时,我们可以把它写到正确的目标通道,一定要记得重置currentChannel和currentLength变量(这些变量将被用来解析下一个数据包)。
最后,当源channel结束时,一定不要忘记调用目标Stream的end()方法。
既然我们可以多路分解源Stream,进行如下调用:
net.createServer(socket => {
const stdoutStream = fs.createWriteStream('stdout.log');
const stderrStream = fs.createWriteStream('stderr.log');
demultiplexChannel(socket, [stdoutStream, stderrStream]);
})
.listen(3000, () => console.log('Server started'))
;在上面的代码中,我们首先在3000端口上启动一个TCP服务器,然后对于我们接收到的每个连接,我们将创建两个可写入的Stream,指向两个不同的文件,一个用于标准输出,另一个用于标准错误; 这些是我们的目标channel。 最后,我们使用demultiplexChannel()将套接字流解复用为stdoutStream和stderrStream。
现在,我们准备尝试运行我们的新的多路复用/多路分解应用程序,但首先让我们创建一个小的Node.js程序来产生一些示例输出; 我们把它叫做generateData.js:
console.log("out1");
console.log("out2");
console.error("err1");
console.log("out3");
console.error("err2");首先,让我们开始运行服务端:
node server
然后运行客户端,需要提供作为子进程的文件参数:
node client generateData.js
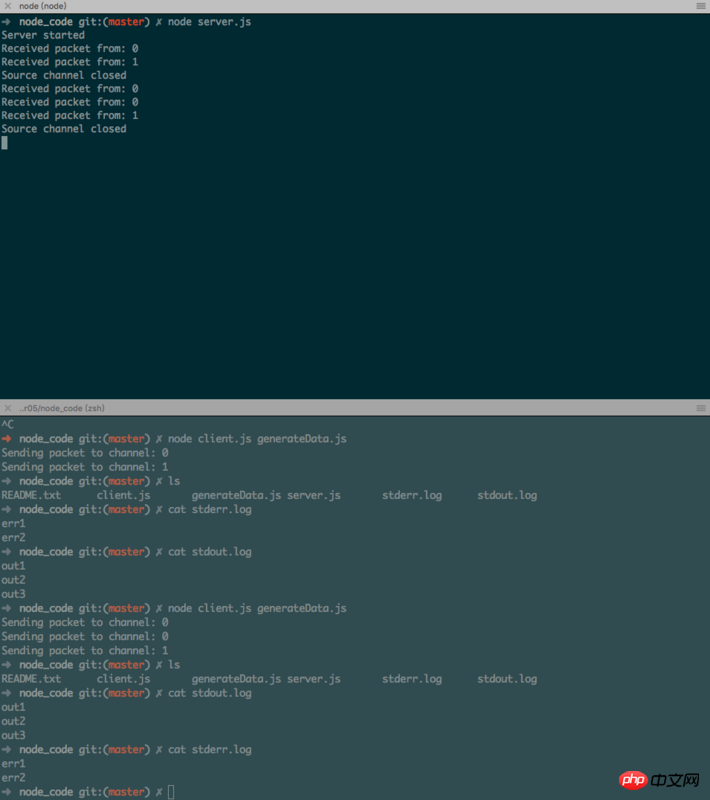
客户端几乎立马运行,但是进程结束时,generateData应用程序的标准输入和标准输出经过一个TCP连接,然后在服务器端,被多路分解成两个文件。
注意,当我们使用child_process.fork()时,我们的客户端能够启动别的Node.js模块。
我们刚刚展示的例子演示了如何复用和解复用二进制/文本Stream,但值得一提的是,相同的规则也适用于对象Stream。 最大的区别是,使用对象,我们已经有了使用原子消息(对象)传输数据的方法,所以多路复用就像设置一个属性channel ID到每个对象一样简单,而多路分解只需要读·channel ID属性,并将每个对象路由到正确的目标Stream。
还有一种模式是取一个对象上的几个属性并分发到多个目的Stream的模式 通过这种模式,我们可以实现复杂的流程,如下图所示:
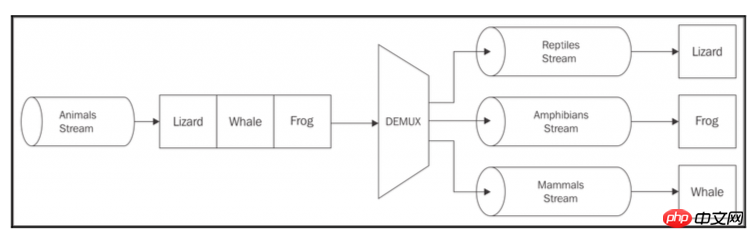
如上图所示,取一个对象Stream表示animals,然后根据动物类型:reptiles,amphibians和mammals,然后分发到正确的目标Stream中。
在本章中,我们已经对Node.js Streams及其使用案例进行了阐述,但同时也应该为编程范式打开一扇大门,几乎具有无限的可能性。我们了解了为什么Stream被Node.js社区赞誉,并且我们掌握了它们的基本功能,使我们能够利用它做更多有趣的事情。我们分析了一些先进的模式,并开始了解如何将不同配置的Streams连接在一起,掌握这些特性,从而使流如此多才多艺,功能强大。
如果我们遇到不能用一个Stream来实现的功能,我们可以通过将其他Streams连接在一起来实现,这是Node.js的一个很好的特性;Streams在处理二进制数据,字符串和对象都十分有用,并具有鲜明的特点。
相关推荐:
위 내용은 스트림을 사용한 인코딩을 위한 Node.js 디자인 패턴의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



