

2024 년 2 월에 발표 된이 획기적인 설문 조사, "대형 언어 모델 데이터 세트 : 포괄적 인 설문 조사"는 LLM (Langues Model) 개발을 위해 400 개가 넘는 400 개가 넘는 데이터 세트의 보물을 공개합니다. Yang Liu, Jiahuan Cao, Chongyu Liu, Kai Ding 및 Lianwen Jin이 편집 한이 리소스는 연구원과 개발자를위한 금광입니다. 그것은 단지 정적 컬렉션이 아닙니다. 정기적으로 업데이트되어 지속적인 관련성을 보장합니다.
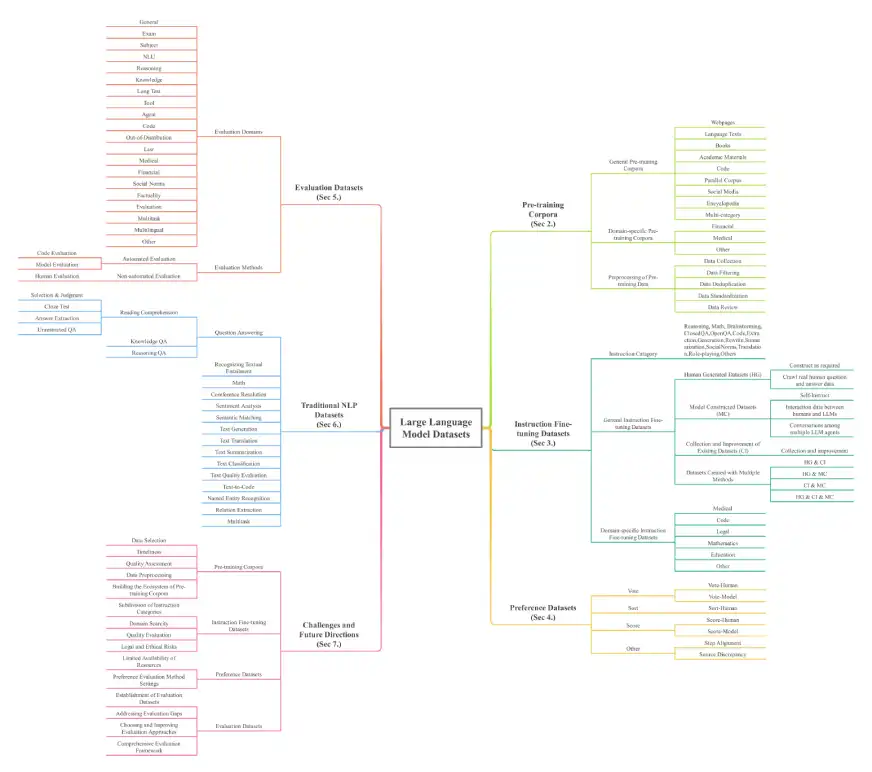
이 논문은 이러한 강력한 모델의 기초를 이해하는 데 필수적인 LLM 데이터 세트에 대한 포괄적 인 개요를 제공합니다. 데이터 세트는 사전 훈련 Corpora, 명령 미세 조정 데이터 세트, 선호도 데이터 세트, 평가 데이터 세트, 기존 NLP 대형 언어 모델 (MLLMS) 데이터 세트 및 검색 증강 생성 (RAG) 데이터 세트의 7 가지 주요 차원에 따라 분류됩니다. 사전 훈련 단독에 대한 774.5 TB의 데이터와 다른 범주에서 7 억 7 천만 개의 인스턴스 (32 개의 도메인과 8 개 언어에 걸쳐 774.5 TB가 넘는 데이터)가 인상적입니다.

주요 데이터 세트 범주 및 예제 :
설문 조사는 다음을 포함하여 다양한 데이터 세트 유형에 대해 자세히 설명합니다.
사전 훈련 Corpora : 초기 LLM 교육을위한 대규모 텍스트 컬렉션. 예로는 Madlad-400 (2.8t 토큰), FineWeb (15TB 토큰) 및 BookCorpusopen (17,868 권)이 있습니다. 이것들은 일반 Corpora (웹 페이지, 서적, 언어 텍스트)와 도메인 별 코퍼레이 (Finance, Medical, Mathematics)로 더 나뉩니다.
명령 미세 조정 데이터 세트 : 모델 동작을 개선하기위한 지침 쌍 및 해당 답변. 예로는 Databricks-dolly-15K 및 Alpaca_data가 있습니다. 이것들은 또한 일반 및 도메인 별 (의료, 코드) 데이터 세트로 분류됩니다.
기본 설정 데이터 세트 : 여러 응답을 비교하여 모델 출력을 평가하고 개선하는 데 사용됩니다. 예제로는 chatbot_arena_conversations 및 hh-rlhf가 있습니다.
평가 데이터 세트 : 다양한 작업에서 LLM 성능을 벤치마킹하도록 특별히 설계되었습니다. 예로는 Alpacaeval 및 Bayling-80이 있습니다.
기존 NLP 데이터 세트 : Pre-LLM NLP 작업에 사용되는 데이터 세트. 예로는 Boolq, Cosmosqa 및 PubMedqa가 있습니다.
멀티 모달 대형 언어 모델 (MLLMS) 데이터 세트 : 텍스트와 기타 양식 (이미지, 비디오)을 결합한 데이터 세트. 예로는 Moscar 및 MMRS-1M이 있습니다.
검색 증강 생성 (RAG) 데이터 세트 : 외부 데이터 검색 기능으로 LLM을 향상시키는 데이터 세트. 예를 들어 Crud-Rag 및 Wikieval이 있습니다.

출처 : 대형 언어 모델에 대한 데이터 세트 : 포괄적 인 설문 조사
설문 조사의 아키텍처는 다음과 같습니다.
결론 및 추가 탐색 :
이 설문 조사는 LLM 분야의 연구원과 개발자를 안내하는 중요한 자원으로 사용됩니다. 제공된 저장소 (Awesome-Llms-Datasets)는 이러한 귀중한 데이터 세트에 액세스하고 활용하기위한 완벽한 로드맵을 제공합니다. 자세한 분류 및 포괄적 인 통계는 LLM을 사용하거나 연구하는 사람에게 필수적인 도구가됩니다. 이 논문은 또한 주요 과제를 해결하고 미래의 연구 방향을 제안합니다.
위 내용은 400 개의 대형 언어 모델 데이터 세트에 대한 안내서의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



