Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Die Autoren dieses Papiers sind Lehrer und Studenten des Instituts für Multi-Agent und verkörperte Intelligenz des Pengcheng Laboratory der Southern University of Science Technologie und Sun Yat-sen-Universität. Zum Team gehören Professor Lin Liang (Direktor des Instituts, National Distinguished Young Scholar, IEEE Fellow), Professor Zheng Feng, Professor Liang Xiaodan, Wang Zhiqiang (Southern University of Science and Technology) und Zheng Hao (Southern University of Science and Technology), Nie Yunshuang (CUHK), Xu Wenjun (Pengcheng), Ye Hua (Pengcheng) usw. Das Team von Professor Lin Liang am Pengcheng Laboratory widmet sich dem Aufbau allgemeiner Basisplattformen wie Multi-Agenten-Kollaborations- und Simulationstrainingsplattformen sowie cloudbasierten, kollaborativen, multimodalen Großmodellen, um wichtige Anwendungsanforderungen wie das industrielle Internet sowie soziale Governance und Dienste zu erfüllen . Seit diesem Jahr entwickelt sich verkörperte Intelligenz zu einem heißen Feld in Wissenschaft und Industrie, und verwandte Produkte und Ergebnisse entstehen nacheinander. Heute hat das Institute of Multi-Agent and Embodied Intelligence des Pengcheng Laboratory (im Folgenden als Pengcheng Embodied Institute bezeichnet) zusammen mit der Southern University of Science and Technology und der Sun Yat-sen University seine neuesten akademischen Errungenschaften auf dem Gebiet offiziell veröffentlicht und als Open Source bereitgestellt Verkörperte Intelligenz – Der verkörperte große Datensatz von ARIO (All Robots In One) zielt darauf ab, die Datenerfassungsprobleme zu lösen, mit denen derzeit im Bereich der verkörperten Intelligenz konfrontiert ist. 

Papiertitel: All Robots in One: A New Standard and Unified Dataset for Versatile.General-Purpose Embodied Agents
Link zum Papier: http://arxiv.org/abs/2408.10899
Projekt-Homepage: https://imaei.github.io/project_pages/ario/
Link zur Website des Pengcheng Laboratory Embodiment Institute: https://imaei.github.io/
체형 로봇의 두뇌로서, 체형 대형 모델의 성능을 향상시키기 위한 핵심은 고품질의 체형 빅데이터를 확보하는 것입니다. 대형 언어 모델이나 대형 시각적 모델에서 사용되는 텍스트나 이미지 데이터와 달리, 구현된 데이터는 인터넷의 방대한 콘텐츠에서 직접 얻을 수 없으며, 실제 로봇 작동을 통해 수집하거나 고급 시뮬레이션 플랫폼을 통해 생성되어야 합니다. 구체화된 데이터의 수집에는 많은 시간과 비용이 소요되며, 대규모화도 어렵다. 동시에 현재 오픈 소스 데이터 세트에도 많은 단점이 있습니다. 위 표에서 볼 수 있듯이 JD ManiData, ManiWAV 및 RH20T의 데이터 양은 크지 않으며 DROID에 사용되는 로봇 하드웨어 플랫폼입니다. Open-X 구현 데이터의 양은 많지만 감각 데이터 형식이 충분하지 않으며 하위 데이터 세트 간의 데이터 형식이 균일하지 않고 품질도 고르지 않습니다. 데이터를 사용하기 전에 필터링하고 처리하는 데 많은 시간이 소요되며, 복잡한 시나리오에서 구현된 지능형 모델의 효율적이고 목표화된 교육에 대한 요구 사항을 충족하기가 어렵습니다. 이에 비해 이번에 공개된 ARIO 데이터 세트에는 5개 양식의 감각 데이터: 2D, 3D, 텍스트, 터치, 사운드가 포함되어 있으며 두 가지 주요 범주인 조작 및 내비게이션 작업에는 다음이 포함됩니다. 시뮬레이션 데이터와 실제 현장 데이터를 모두 담고 있으며, 다양한 로봇 하드웨어를 담고 있어 매우 풍부합니다. 데이터 규모가 300만 개에 달하면서 데이터의 통일된 형식도 보장합니다. 이는 현재 구현 지능 분야에서 높은 품질, 다양성 및 대규모를 동시에 달성하는 오픈 소스 데이터 세트입니다. 실체지능 데이터셋의 경우 로봇은 외팔, 양팔, 휴머노이드, 네다리 등 다양한 형태를 갖고 있고 인식 및 제어 방식도 다르기 때문에 일부는 관절 각도를 통해 제어되고 일부는 신체 또는 끝 포즈 좌표에 의해 구동되므로 구현된 데이터 자체는 단순한 이미지 및 텍스트 데이터보다 훨씬 복잡하며 많은 제어 매개변수를 기록해야 합니다. 그리고 통일된 형식이 없으면 여러 유형의 로봇 데이터를 하나로 통합할 때 추가 전처리에 많은 에너지가 소비됩니다. 따라서 Pengcheng 연구소의 구현 연구소는 먼저 구현된 빅 데이터에 대한 형식 표준 세트를 설계했습니다. 이 표준은 다양한 형태의 로봇 제어 매개 변수를 기록할 수 있고 명확하게 구조화된 데이터 구성 형식을 가지며 또한 가능합니다. 다양한 프레임 속도의 센서와 호환되며 해당 타임스탬프를 기록하여 감지 및 제어 타이밍을 위한 내장형 지능형 대형 모델의 정확한 요구 사항을 충족합니다. 아래 그림은 ARIO 데이터 세트의 전반적인 디자인을 보여줍니다. O 그림 1. ARIO 데이터 세트 디자인 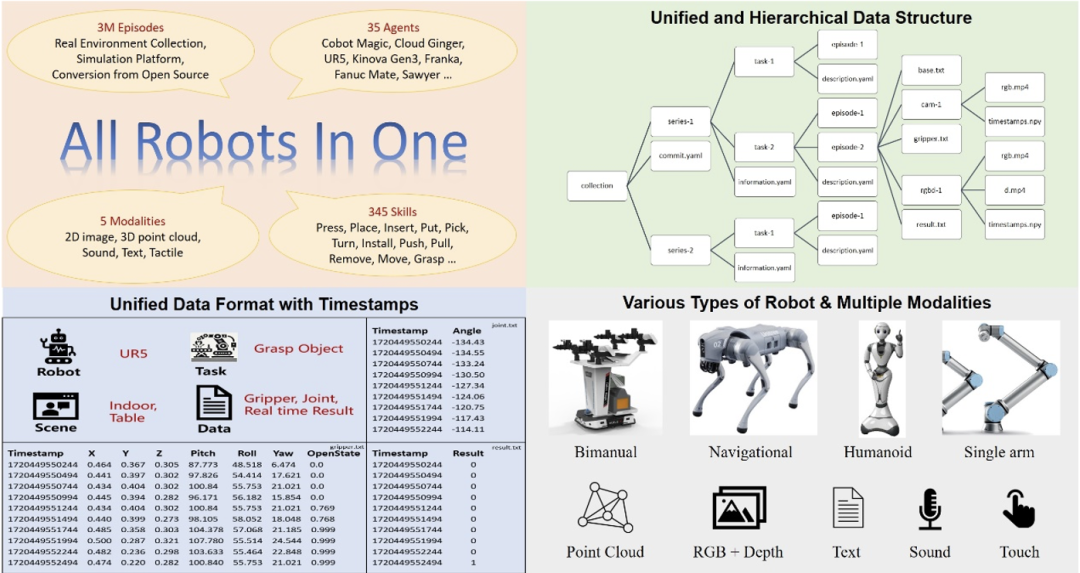
Ario 데이터세트는 총 258개의 장면 시퀀스, 32,1064개의 태스크, 303만 개의 샘플을 포함합니다. ARIO의 데이터는 세 가지 주요 소스에서 나옵니다. 하나는 실제 환경에서 장면과 작업을 배열하여 수집한 것이며, 다른 하나는 MuJoCo 및 Habitat과 같은 시뮬레이션 엔진을 기반으로 가상 장면 및 개체 모델을 설계하고 로봇을 구동하는 것입니다. 세 번째 단계는 현재 오픈소스로 구현된 데이터 세트를 하나씩 분석, 가공하여 ARIO 형식 표준에 맞는 데이터로 변환하는 것이다. 다음은 ARIO 데이터 세트의 구체적인 구성과 3가지 소스의 프로세스 및 예를 보여줍니다. ㅋㅋㅋ Pengcheng 연구소는 Cobot Magic 마스터-슬레이브 이중 팔 로봇을 기반으로 3가지 작업 난이도(단순 - 중간 - 어려움)를 포함하여 30개 이상의 작업을 설계했으며, 간섭 물체를 추가하여 물체와 로봇의 위치를 무작위로 변경하고, 레이아웃 변경 샘플의 다양성을 높이기 위해 환경 및 기타 방법을 사용하여 최종적으로 3대의 RGBD 카메라가 포함된 3,000개 이상의 궤적 데이터를 획득했습니다. 다양한 작업에 대한 컬렉션 예시와 컬렉션 영상이 아래에 나와 있습니다.
O Abbildung 3. Beispiel für die Datenerfassung eines echten Ario-Roboters  Simulationsdaten zur Generierung von Beispielvideos der Plattform
Simulationsdaten zur Generierung von Beispielvideos der Plattform  平 平 平 basierend auf der Habitat-Plattform zur Generierung von Daten zur Generierung von Beispielvideos
平 平 平 basierend auf der Habitat-Plattform zur Generierung von Daten zur Generierung von Beispielvideos  Daten, die zum Beispiel aus RH20T-Konvertierungsdaten konvertiert wurden ifiziertes Format Das Design der Daten erleichtert die Durchführung statistischer Analysen ihrer Datenzusammensetzung. Die folgende Abbildung zeigt die Statistik der Verteilung von ARIO-Szenen (Abbildung a) und Fähigkeiten (Abbildung b) aus den drei Ebenen Serie, Aufgabe und Episode. Es ist ersichtlich, dass sich die meisten verkörperten Daten derzeit auf Szenen und Fähigkeiten im Innenleben und in häuslichen Umgebungen konzentrieren.
Daten, die zum Beispiel aus RH20T-Konvertierungsdaten konvertiert wurden ifiziertes Format Das Design der Daten erleichtert die Durchführung statistischer Analysen ihrer Datenzusammensetzung. Die folgende Abbildung zeigt die Statistik der Verteilung von ARIO-Szenen (Abbildung a) und Fähigkeiten (Abbildung b) aus den drei Ebenen Serie, Aufgabe und Episode. Es ist ersichtlich, dass sich die meisten verkörperten Daten derzeit auf Szenen und Fähigkeiten im Innenleben und in häuslichen Umgebungen konzentrieren.  Zusätzlich zu Szenarien und Fähigkeiten können ARIO-Daten auch statistische Analysen aus der Perspektive des Roboters selbst durchführen und einige der aktuellen Entwicklungstrends der Roboterindustrie kennenlernen. Der ARIO-Datensatz liefert statistische Daten zur Roboterform, sich bewegenden Objekten, physikalischen Steuervariablen, Sensortypen und Installationsorten, der Anzahl visueller Sensoren, dem Anteil der Steuerungsmethoden, dem Anteil der Datenerfassungsmethoden und dem Anteil der Anzahl der Freiheitsgrade des Roboterarms, entsprechend den Abbildungen a-i unten.
Zusätzlich zu Szenarien und Fähigkeiten können ARIO-Daten auch statistische Analysen aus der Perspektive des Roboters selbst durchführen und einige der aktuellen Entwicklungstrends der Roboterindustrie kennenlernen. Der ARIO-Datensatz liefert statistische Daten zur Roboterform, sich bewegenden Objekten, physikalischen Steuervariablen, Sensortypen und Installationsorten, der Anzahl visueller Sensoren, dem Anteil der Steuerungsmethoden, dem Anteil der Datenerfassungsmethoden und dem Anteil der Anzahl der Freiheitsgrade des Roboterarms, entsprechend den Abbildungen a-i unten.  Nehmen Sie Abbildung a unten als Beispiel. Daraus können wir erkennen, dass die meisten aktuellen Daten von einarmigen Robotern stammen. Es gibt nur sehr wenige Open-Source-Daten für humanoide Roboter und diese stammen hauptsächlich aus echten Sammlungen und Simulationsgenerierung des Pengcheng-Labors. Originalpapier und Projekthomepage.
Nehmen Sie Abbildung a unten als Beispiel. Daraus können wir erkennen, dass die meisten aktuellen Daten von einarmigen Robotern stammen. Es gibt nur sehr wenige Open-Source-Daten für humanoide Roboter und diese stammen hauptsächlich aus echten Sammlungen und Simulationsgenerierung des Pengcheng-Labors. Originalpapier und Projekthomepage. 위 내용은 구현된 지능 데이터는 너무 비싸다는 말이 항상 있습니다. Pengcheng 연구소는 백만 규모의 표준화된 데이터 세트를 오픈 소스로 제공했습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!




















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



