

This time I will show you how to use async in node to control concurrency, and what are the precautions for using async in node to control concurrency. The following is a practical case, let's take a look.
Objective
Create a lesson5 project and write code in it. The entry point of the code is app.js. When node app.js is called, it will output the titles of all topics on the CNode (https://cnodejs.org/) community homepage. Link and first comment in json format.
Note: Unlike the previous lesson, the number of concurrent connections needs to be controlled at 5. Output example:[
{
"title": "【公告】发招聘帖的同学留意一下这里",
"href": "http://cnodejs.org/topic/541ed2d05e28155f24676a12",
"comment1": "呵呵呵呵"
},
{
"title": "发布一款 Sublime Text 下的 JavaScript 语法高亮插件",
"href": "http://cnodejs.org/topic/54207e2efffeb6de3d61f68f",
"comment1": "沙发!"
}
]Knowledge points##Learn async(https://github.com/caolan/async ) usage of. Here is a detailed async demo: https://github.com/alsotang/async_demo
Learn to use async to control the number of concurrent connections.
Course content#lesson4’s code is actually imperfect. The reason why we say this is because in lesson4, we sent 40 concurrent requests at one time. You must know that, except for CNode, other websites may treat you as a malicious request because you send too many concurrent connections. , block your IP.
When we write a crawler, if there are 1,000 links to crawl, it is impossible to send out 1,000 concurrent links at the same time, right? We need to control the number of concurrencies, for example, 10 concurrencies, and then slowly capture these 1,000 links.
Doing this with async is easy.
This time we are going to introduce the
mapLimit(arr, limit, iterator, callback) interface of async. In addition, there is a commonly used interface for controlling the number of concurrent connections: queue(worker, concurrency). You can go to https://github.com/caolan/async#queueworker-concurrency for instructions. This time I won’t take you to crawl the website. Let’s focus on the knowledge point: controlling the number of concurrent connections.
By the way, another question is, when to use eventproxy and when to use async? Aren't they all used for asynchronous
process controlWhen you need to go to multiple sources (usually less than 10)
to summarize data, it is convenient to use eventproxy; when you need to use Use async when you want to queue, need to control the number of concurrency, or if you like functional programming thinking. Most scenarios are the former, so I personally use eventproxy most of the time. The main topic begins.
First, we forge a
fetchUrl(url, callback) function. The function of this function is that when you call it through <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:php;toolbar:false">fetchUrl('http://www.baidu.com', function (err, content) {
// do something with `content`
});</pre><div class="contentsignin">Copy after login</div></div>, it will return http: //The page content of www.baidu.com returns.
Of course, the return content here is false, and the return delay is random. And when it is called, it will tell you how many places it is being called concurrently.
// 并发连接数的计数器
var concurrencyCount = 0;
var fetchUrl = function (url, callback) {
// delay 的值在 2000 以内,是个随机的整数
var delay = parseInt((Math.random() * 10000000) % 2000, 10);
concurrencyCount++;
console.log('现在的并发数是', concurrencyCount, ',正在抓取的是', url, ',耗时' + delay + '毫秒');
setTimeout(function () {
concurrencyCount--;
callback(null, url + ' html content');
}, delay);
};Let’s then forge a set of links
var urls = [];
for(var i = 0; i < 30; i++) {
urls.push('http://datasource_' + i);
}This set of links looks like this:
 Next, we use async.mapLimit to concurrently crawl and obtain results.
Next, we use async.mapLimit to concurrently crawl and obtain results.
async.mapLimit(urls, 5, function (url, callback) {
fetchUrl(url, callback);
}, function (err, result) {
console.log('final:');
console.log(result);
});The running output is like this:
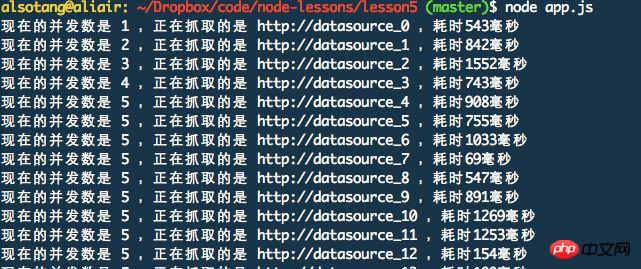 It can be seen that at the beginning, the number of concurrent links starts to grow from 1, and when it grows to 5, It will no longer increase. When one of the tasks is completed, continue fetching. The number of concurrent connections is always limited to 5.
It can be seen that at the beginning, the number of concurrent links starts to grow from 1, and when it grows to 5, It will no longer increase. When one of the tasks is completed, continue fetching. The number of concurrent connections is always limited to 5.
I believe you have mastered the method after reading the case in this article. For more exciting information, please pay attention to other related articles on the php Chinese website!
Recommended reading:
How to replace the callback function with promise in nodeHow to use Vue better-scroll to implement alphabetical index navigationThe above is the detailed content of How to use async in node to control concurrency. For more information, please follow other related articles on the PHP Chinese website!
 What file is resource?
What file is resource?
 How to set a scheduled shutdown in UOS
How to set a scheduled shutdown in UOS
 Springcloud five major components
Springcloud five major components
 The role of math function in C language
The role of math function in C language
 What does wifi deactivated mean?
What does wifi deactivated mean?
 iPhone 4 jailbreak
iPhone 4 jailbreak
 The difference between arrow functions and ordinary functions
The difference between arrow functions and ordinary functions
 How to skip connecting to the Internet after booting up Windows 11
How to skip connecting to the Internet after booting up Windows 11








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



