


I have heard of crawlers for a long time, and I have started to learn nodejs in the past few days. I crawl the article titles, user names, reading numbers, recommendation numbers and user avatars on the homepage of the blog park. Now I will make a short summary.
Use these points:
1. The core module of node--File system
2. Third-party module used for http requests-- superagent
3. Third-party module for parsing DOM--cheerio
Please go to each link for detailed explanations and APIs of several modules. There are only simple usages in the demo.
Preparation
Use npm to manage dependencies, and the dependency information will be stored in package.json
//安装用到的第三方模块 cnpm install --save superagent cheerio
Introduce the required functional modules
//引入第三方模块,superagent用于http请求,cheerio用于解析DOM
const request = require('superagent');
const cheerio = require('cheerio');
const fs = require('fs');Request + parse page
If you want to crawl to the content on the homepage of the blog park, you must first request the homepage address and get the returned html. Here, superagent is used to make http requests. The basic usage method is as follows:
request.get(url)
.end(error,res){
//do something
}Initiate a get request to the specified url. When the request is incorrect, an error will be returned (if there is no error, error is null or undefined), and res is the returned data.
After getting the html content, to get the data we want, we need to use cheerio to parse the DOM. Cheerio needs to load the target html first and then parse it. The API is very similar to the jquery API. , familiar with jquery and getting started very quickly. Directly look at the code example
//目标链接 博客园首页
let targetUrl = 'https://www.cnblogs.com/';
//用来暂时保存解析到的内容和图片地址数据
let content = '';
let imgs = [];
//发起请求
request.get(targetUrl)
.end( (error,res) => {
if(error){ //请求出错,打印错误,返回
console.log(error)
return;
}
// cheerio需要先load html
let $ = cheerio.load(res.text);
//抓取需要的数据,each为cheerio提供的方法用来遍历
$('#post_list .post_item').each( (index,element) => {
//分析所需要的数据的DOM结构
//通过选择器定位到目标元素,再获取到数据
let temp = {
'标题' : $(element).find('h3 a').text(),
'作者' : $(element).find('.post_item_foot > a').text(),
'阅读数' : +$(element).find('.article_view a').text().slice(3,-2),
'推荐数' : +$(element).find('.diggnum').text()
}
//拼接数据
content += JSON.stringify(temp) + '\n';
//同样的方式获取图片地址
if($(element).find('img.pfs').length > 0){
imgs.push($(element).find('img.pfs').attr('src'));
}
});
//存放数据
mkdir('./content',saveContent);
mkdir('./imgs',downloadImg);
})Storing data
After parsing the DOM above, the required information content has been spliced, and the URL of the image has been obtained. Now it is stored and the content is stored in the specified location. txt file in the directory, and download the picture to the specified directory
Create the directory first and use the nodejs core file system
//创建目录
function mkdir(_path,callback){
if(fs.existsSync(_path)){
console.log(`${_path}目录已存在`)
}else{
fs.mkdir(_path,(error)=>{
if(error){
return console.log(`创建${_path}目录失败`);
}
console.log(`创建${_path}目录成功`)
})
}
callback(); //没有生成指定目录不会执行
}After you have the specified directory, you can write data, the txt file The content is already there, just write it directly. Use writeFile()
//将文字内容存入txt文件中
function saveContent() {
fs.writeFile('./content/content.txt',content.toString());
}to get the link to the image, so you need to use superagent to download the image and store it locally. superagent can directly return a response stream, and then cooperate with the nodejs pipeline to directly write the image content to the local
//下载爬到的图片
function downloadImg() {
imgs.forEach((imgUrl,index) => {
//获取图片名
let imgName = imgUrl.split('/').pop();
//下载图片存放到指定目录
let stream = fs.createWriteStream(`./imgs/${imgName}`);
let req = request.get('https:' + imgUrl); //响应流
req.pipe(stream);
console.log(`开始下载图片 https:${imgUrl} --> ./imgs/${imgName}`);
} )
}Effect
Execute the demo and see the effect. The data has climbed down normally
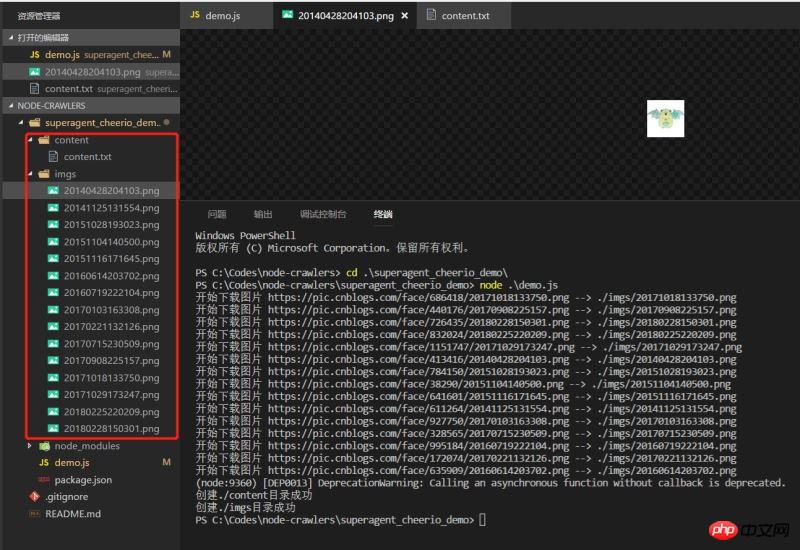
A very simple demo, it may not be that rigorous, but it is always the first small step towards node.
Related recommendations:
node.js [superAgent] request usage example_node.js
NodeJS crawler detailed explanation
Detailed explanation of the web request module of Node.js crawler
The above is the detailed content of nodejs crawler superagent and cheerio experience case. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



