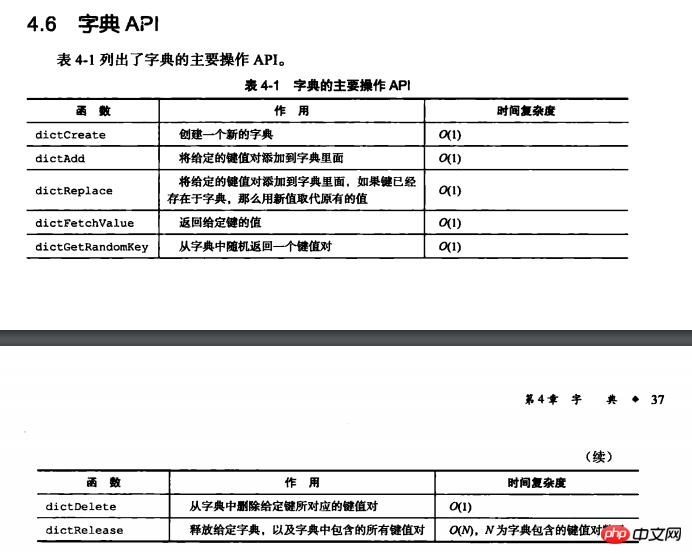
最近在看redis的设计与实现一书,看到字典这一章节时,发现redis字典的增删改查操作的复杂度都是O(1):
对此不太懂,看了它的数据结构,感觉不应该是O(1)的复杂度,给定一个key,去查value的话如果不是定长并且有序的储存结构,怎么可能是O(1)的复杂度?
拥有18年软件开发和IT教学经验。曾任多家上市公司技术总监、架构师、项目经理、高级软件工程师等职务。 网络人气名人讲师,...
下の写真はハッシュテーブルの概略図です:
主に最適化によるもの Hash Function,尽可能的减少冲突。也就是防止不同的key映射到相同的value ですが、競合があっても問題ありません。 。 。
Hash Function
key
value
参考: http://www.tutorialspoint.com/data_ Structures_algorithms/hash_data_structor.htm ファイアウォールを回避する必要があるかどうかはわかりません。
追記: アルゴリズムの概要を読むことができます。 。 。
質問者はハッシュとは何かを知らないようです。最初にデータ構造の基礎を築き、それからデータ構造に基づいてredisの応用を勉強することをお勧めします。
もちろん、ハッシュの複雑さ O(1) は平均複雑さを指し、これは最良のケースでもあり、最悪のケースも O(n) です
よくわかりませんが、リンクされたリストを走査する複雑さはどのようにして 1 になるのでしょうか?
いわゆる辞書はハッシュテーブルであり、ハッシュマップの追加、削除、変更の複雑さはあまり衝突することなく線形です。 ~~

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




下の写真はハッシュテーブルの概略図です:

主に最適化によるもの
Hash Function,尽可能的减少冲突。也就是防止不同的key映射到相同的valueですが、競合があっても問題ありません。 。 。参考:
http://www.tutorialspoint.com/data_ Structures_algorithms/hash_data_structor.htm ファイアウォールを回避する必要があるかどうかはわかりません。
追記: アルゴリズムの概要を読むことができます。 。 。
質問者はハッシュとは何かを知らないようです。最初にデータ構造の基礎を築き、それからデータ構造に基づいてredisの応用を勉強することをお勧めします。
もちろん、ハッシュの複雑さ O(1) は平均複雑さを指し、これは最良のケースでもあり、最悪のケースも O(n) です
よくわかりませんが、リンクされたリストを走査する複雑さはどのようにして 1 になるのでしょうか?
いわゆる辞書はハッシュテーブルであり、ハッシュマップの追加、削除、変更の複雑さはあまり衝突することなく線形です。 ~~