


ビジュアル生成分野の急速な発展の過程で、普及モデルはこの分野の開発トレンドを完全に変えました。テキストガイドによる生成機能の導入は、機能に大きな変化をもたらしました。 。
ただし、テキストのみに依存してこれらのモデルを規制しても、さまざまなアプリケーションやシナリオの多様で複雑なニーズを完全に満たすことはできません。
この欠点を考慮して、多くの研究は、新しい条件をサポートするために事前トレーニングされたテキストから画像への (T2I) モデルを制御することを目的としています。
北京郵電大学の研究者らは、T2I 拡散モデルの制御可能な生成に関する詳細なレビューを実施し、この分野の理論的基礎と実践的な進歩について概説しました。このレビューは最新の研究結果を網羅しており、この分野の発展と応用に重要な参考資料を提供します。

論文: https://arxiv.org/abs/2403.04279 コード: https://github.com/PRIV-Creation/Awesome-Controllable-T2I -拡散モデル
私たちのレビューは、ノイズ除去拡散確率モデル (DDPM) と広く使用されている T2I 拡散モデルの基本の簡単な紹介から始まります。
私たちは拡散モデルの制御メカニズムをさらに調査し、理論分析を通じてノイズ除去プロセスに新しい条件を導入する有効性を判断しました。
さらに、この分野の研究を詳細にまとめ、特定条件生成、複数条件生成、一般的な制御性などの条件の観点からさまざまなカテゴリに分類しました。世代。
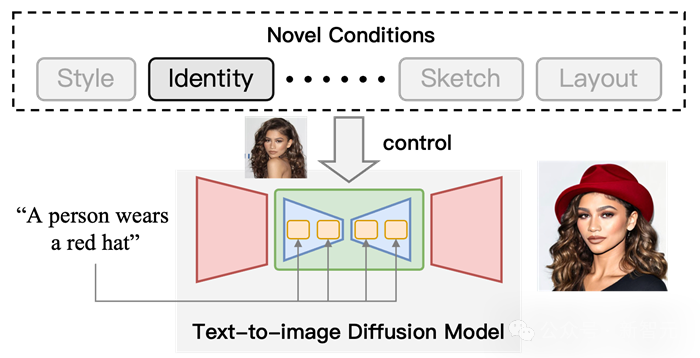
# 図 1 T2I 拡散モデルを使用した制御可能な発電の概略図。テキスト条件に基づいて、出力結果を制御する「同一性」条件を追加します。
分類システムテキスト拡散モデルを使用した条件付き生成のタスクは、多面的で複雑なフィールドを表します。条件の観点から、このタスクを 3 つのサブタスクに分割します (図 2 を参照)。
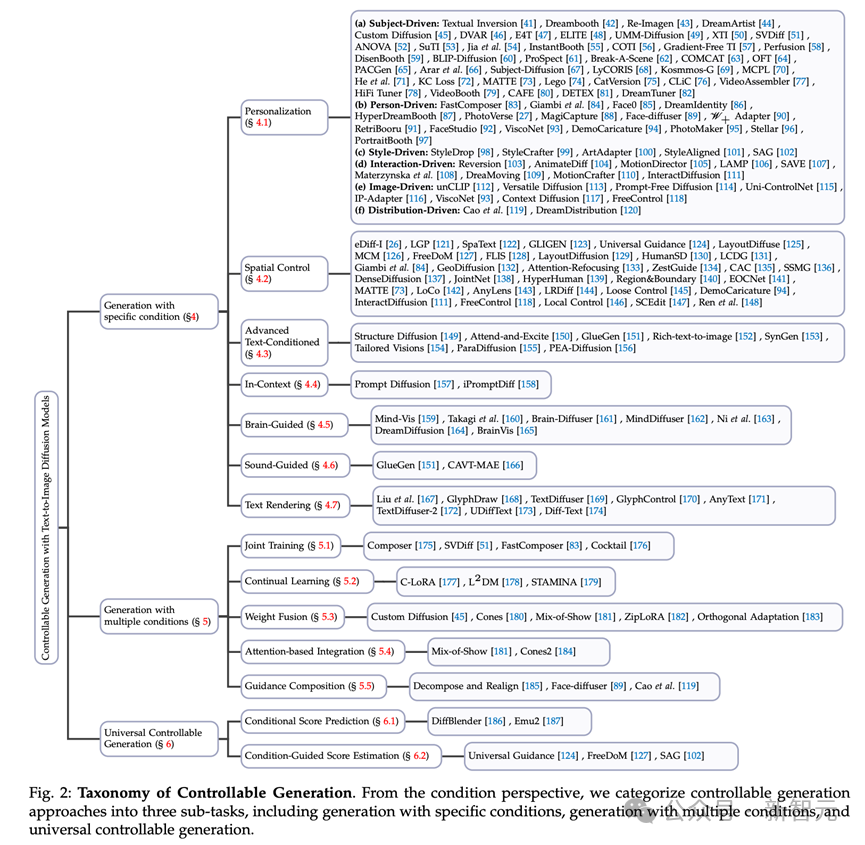
# 図 2 制御可能な発電量の分類。条件の観点から、制御可能な発電方法を、特定の条件による発電、複数の条件による発電、および一般的な制御可能な発電を含む 3 つのサブタスクに分割します。
ほとんどの研究は、画像誘導生成やスケッチから画像の生成など、特定の条件下で画像を生成する方法に重点が置かれています。
これらの方法の理論と特徴を明らかにするために、状態の種類に応じてそれらをさらに分類します。
1. 特定の条件を使用して生成: は、カスタマイズされた条件 (DreamBooth、テキスト反転などのパーソナライゼーション) を含む、特定の種類の条件を導入する方法を示しています。また、ControlNet シリーズ、生理学的信号から画像への変換など、より直接的な条件も含まれています
#2。複数条件の生成: 複数の条件を使用します。条件が生成され、このタスクを技術的な観点から細分化します。
3. 統合制御可能な生成: このタスクは、任意の条件 (任意の数) を使用して生成できるように設計されています。
T2I 拡散モデルに新しい条件を導入する方法
詳細については論文原文を参照してください。これらの手法のメカニズムは以下に簡単に紹介されます。 。
条件付きスコア予測
T2I 普及モデルでは、トレーニング可能なモデルを利用します ( UNet など) を使用してノイズ除去プロセスの確率スコア (つまりノイズ) を予測することは、基本的かつ効果的な方法です。
条件ベースのスコア予測方法では、新しい条件を予測モデルへの入力として使用して、新しいスコアを直接予測します。
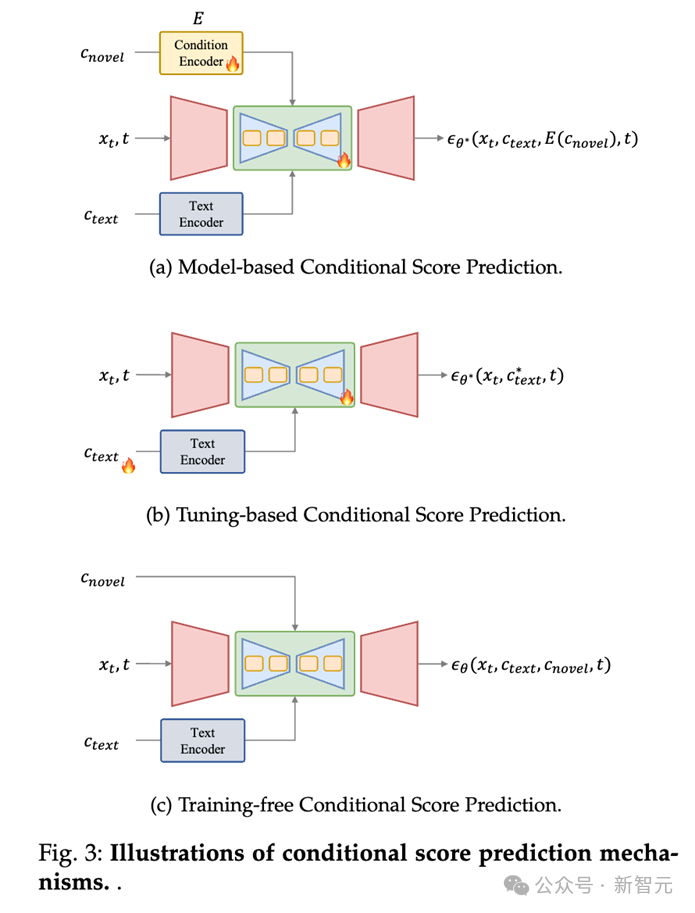
#新しい条件を導入するには、次の 3 つの方法に分けることができます。モデルの条件付きスコア予測に基づく:
このタイプの方法では、新しい条件をエンコードするために使用されるモデルが導入され、UNet の入力としてエンコード機能が使用されます (相互接続に作用するなど)。注意層) 新規性を予測するための条件下でのスコア結果;2. 微調整に基づく条件付きスコア予測:
このタイプの方法は明示的な条件を使用せず、代わりにテキスト埋め込みおよびノイズ除去ネットワークのパラメータを微調整して新しい条件に関する情報を学習し、微調整された重みを使用して制御可能な生成を実現します。たとえば、DreamBooth や Textual Inversion がそのような実践です。3. トレーニングを行わない条件付きスコア予測:
このタイプの方法では、モデルをトレーニングする必要がなく、条件をモデルに直接適用できます。たとえば、Layout-to-Image (レイアウト画像生成) タスクなどの予測プロセスでは、クロスアテンション レイヤーのアテンション マップを直接変更して、オブジェクトのレイアウトを設定できます。#条件付き指導評価のスコア評価
特定の条件を使用して
を生成します

1. パーソナライゼーション: カスタマイズされたタスクは、制御可能な生成条件として概念を捉えて利用するように設計されています。テキストでは簡単に説明できないため、サンプル画像から抽出する必要があります。 DreamBooth、Texutal Inversion、LoRA など。
2. 空間制御: テキストでは構造情報、つまり位置や密なラベルを表現することが難しいため、空間が使用されます。 -制御されたテキストから画像への拡散方法は、レイアウト、人間のポーズ、人体の解析などの分野における重要な研究分野です。 ControlNet などのメソッド。
3. 高度なテキスト条件付き生成: テキストはテキストから画像への拡散モデルで役割を果たしますが、基本的な役割は条件は整っていますが、この分野ではまだいくつかの課題があります。
まず、複数のトピックや豊富な説明を含む複雑なテキストでテキストガイド付き合成を行う場合、テキストの位置がずれているという問題がよく発生します。さらに、これらのモデルは主に英語のデータセットでトレーニングされているため、多言語生成機能が大幅に不足しています。この制限に対処するために、多くの研究で、これらのモデル言語の範囲を拡張することを目的とした革新的なアプローチが提案されています。
4. インコンテキスト生成: タスク固有のサンプル画像とテキストのガイダンスのペアに基づいたコンテキスト生成タスク内、新しいクエリ、画像に対する特定のタスクを理解し、実行します。
5. 脳誘導生成: 脳誘導生成タスクは、脳活動から直接画像を制御することに焦点を当てています。脳波(EEG)記録と機能的磁気共鳴画像法(fMRI)。
6. 音声ガイドによる生成: 音声に基づいて一致する画像を生成します。
7. テキスト レンダリング: 画像内にテキストを生成し、ポスター、データ カバー、表現パッケージなどで広く使用できます。アプリケーションシナリオ。
#複数条件の生成

複数条件の生成タスクが設計されていますユーザー定義のポーズで特定の人物を生成したり、3 つの個人化されたアイデンティティで人物を生成したりするなど、さまざまな条件で画像を生成します。
#このセクションでは、技術的な観点からこれらの方法の包括的な概要を提供し、次のカテゴリに分類します。
# #1. 共同訓練: 訓練段階で共同訓練のための複数の条件を導入します。 2. 継続学習: 複数の条件を順番に学習し、古い条件を忘れることなく新しい条件を学習して、複数の条件生成を実現します。 3. 重みの融合: さまざまな条件下で微調整して得られたパラメータを重みの融合に使用し、モデルに複数の重みが生成されるようにします。条件下で。 4. アテンションベースの統合: 画像内のアテンション マップ (通常はオブジェクト) を通じて複数の条件を設定し、複数条件の生成を実現します。 。 特定の種類の条件に合わせた方法に加えて、画像内の任意の条件に適応するように設計された方法もあります。一般的な生成方法。 これらの方法は、理論的基礎に基づいて、一般的な条件付きスコア予測フレームワークと一般的な条件付きガイド付きスコア推定の 2 つのグループに大別されます。 1. ユニバーサル コンディション スコア予測フレームワーク: ユニバーサル コンディション スコア予測フレームワークは、特定の条件をエンコードできるフレームワークを作成することで機能し、画像合成中の各時間ステップでノイズを予測するためのフレームワーク。 このアプローチは、さまざまな条件に柔軟に適応できる普遍的なソリューションを提供します。このアプローチでは、条件情報を生成モデルに直接統合することで、さまざまな条件に応じて画像生成プロセスを動的に調整できるため、汎用性が高く、さまざまな画像合成シナリオに適用できます。 2. 一般的な条件付きガイド付きスコア推定: 他の方法では、条件付きガイド付きスコア推定を利用して、さまざまな条件をテキストから画像への拡散に組み込みます。モデル真ん中。主な課題は、ノイズ除去中に潜在変数から条件固有のガイダンスを取得することにあります。 新しい条件の導入は、画像編集、画像の完成、画像の結合、テキスト/イラストの 3D 生成など、複数のタスクで役立ちます。 。 たとえば、画像編集では、カスタマイズされた方法を使用して、写真内の猫を特定のアイデンティティを持つ猫に編集できます。その他の情報については、論文を参照してください。 このレビューでは、テキストから画像への拡散モデルの条件付き生成の分野を掘り下げ、テキストへの組み込みを明らかにします。ガイド付き生成プロセス、新しい条件。 まず、著者は読者に基本的な知識を提供し、ノイズ除去拡散確率モデル、有名なテキストから画像への拡散モデル、およびよく構造化された分類法を紹介します。その後、著者らは、T2I 拡散モデルに新しい条件を導入するメカニズムを明らかにしました。 次に、著者はこれまでの条件付き生成手法を要約し、理論的基礎、技術的進歩、解決戦略の側面から分析します。 さらに、著者は、制御可能な生成の実際的な応用を検討し、AI コンテンツ生成の時代におけるその重要な役割と大きな可能性を強調します。 この調査は、制御可能な T2I 生成分野の現状を包括的に理解し、それによってこのダイナミックな研究分野の継続的な進化と拡大を促進することを目的としています。 一般的な条件の生成
アプリケーション
概要
以上が制御可能な画像生成の最新レビュー!北京郵電大学は、テキストから画像への拡散の分野におけるさまざまな「条件」を網羅した249の文書20ページを公開した。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



