


最近、米国のトップ 10 テクノロジー ブログの 1 つとして、Latent Space は、つい最近開催された NeurIPS 2023 カンファレンスの厳選されたレビューと概要を実施しました。
NeurIPS カンファレンスでは、合計 3586 件の論文が採択され、そのうち 6 件が賞を受賞しました。これらの受賞論文は多くの注目を集めていますが、他の論文も同様に優れた品質と可能性を備えています。実際、これらの論文は AI における次の大きな進歩を予告するものになる可能性さえあります。
それでは、一緒に見ていきましょう!

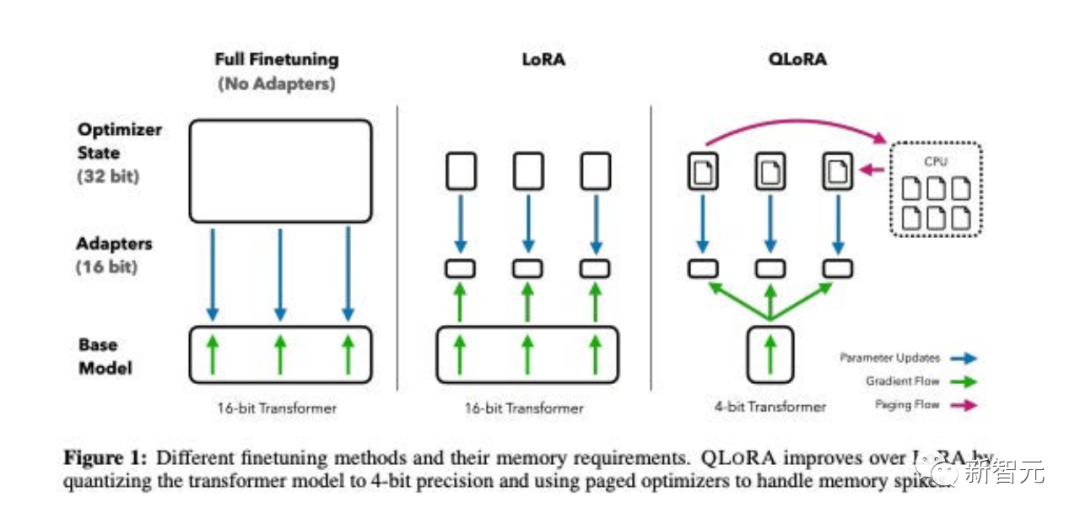
論文のタイトル: QLoRA: 量子化 LLM の効率的な微調整

この論文は、LoRA A メモリのより高度なバージョンである QLoRA を提案します。 - メモリを節約するためにいくつかの最適化トリックを使用する、効率的ですが遅いバージョン。
全体的に、QLoRA を使用すると、大規模な言語モデルを微調整するときに使用する GPU メモリの使用量を減らすことができます。
彼らは、Guanaco という名前の新しいモデルを微調整し、たった 1 つの GPU で 24 時間トレーニングし、Vicuna ベンチマークで以前のモデルを上回りました。
同時に、研究者らは、同様の効果をもたらす 4 ビット LoRA 定量化などの他の方法も開発しました。
論文タイトル: DataComp: 次世代のマルチモーダル データセットを求めて

マルチモーダル データ アンサンブルには、 CLIP、安定拡散、GPT-4 などの最近の進歩において重要な役割を果たしましたが、その設計はモデル アーキテクチャやトレーニング アルゴリズムほど研究の注目を集めてきませんでした。
機械学習エコシステムのこの不足に対処するために、研究者らは、Common Crawl を中心に構築された 128 億の画像とテキストのペアの新しい候補プールである、集団実験用のテスト プラットフォームである DataComp を導入しました。
ユーザーは、DataComp を試して、標準化された CLIP トレーニング コードや 38 の下流テスト セットを実行することで、新しいフィルタリング手法を設計したり、新しいデータ ソースをキュレートしたりすることができます。生成されたモデルをテストして評価することができます。新しいデータセットについて。
結果は、CLIP ViT-L/14 モデルをゼロからトレーニングできる最良のベンチマーク DataComp-1B が、ImageNet 上で 79.2% のゼロショット精度を達成していることを示しています。 OpenAI の CLIP ViT-L/14 モデルを使用した場合のパフォーマンスは 3.7 パーセント ポイント高く、DataComp ワークフローがより優れたトレーニング セットを生成できることが証明されました。
 論文アドレス:
論文アドレス:
//m.sbmmt.com/link/c0db7643410e1a667d5e01868827a9afこの論文では、研究者が言語のみに依存する GPT-4 を使用して、マルチモーダルな言語イメージ命令に従うデータを生成する最初の試みを紹介します。
この生成されたデータに命令を適用することで、LLaVA: Large Language and Vision Assistant を導入します。これは、一般的な視覚のためのビジュアル エンコーダと LLM を接続する、エンドツーエンドでトレーニングされた大規模なマルチモーダル モデルです。そして言語理解。
初期の実験では、LLaVA が印象的なマルチモーダル チャット機能を実証し、目に見えない画像/命令や合成マルチモーダルでマルチモーダル GPT-4 の動作を示す場合があります。静的チャットでは GPT-4 と比較して 85.1% の相対スコアを達成しました。データセットに続く命令。
LLaVA と GPT-4 の相乗効果により、科学的質問応答を微調整する際に 92.53% という新たな最先端の精度が達成されます。

論文のタイトル: 思考の木: 大規模な言語モデルを使用した意図的な問題解決

言語モデルは改善されています幅広いタスクにわたる一般的な問題解決に使用されることが増えていますが、推論中のトークン レベルの左から右への意思決定プロセスにまだ限定されています。これは、探索や戦略的な先見性が必要なタスク、または最初の意思決定が重要な役割を果たすタスクではパフォーマンスが低下する可能性があることを意味します。
これらの課題を克服するために、研究者は新しい言語モデル推論フレームワークである Tree of Thoughts (ToT) を導入しました。これは、言語モデルを促す方法で人気のある思考連鎖を一般化し、一貫した探索を可能にします。問題解決の中間ステップとして機能するテキスト単位 (アイデア)。
ToT を使用すると、言語モデルは、複数の異なる推論パスを考慮し、次のステップを決定するための選択肢を自己評価し、必要に応じて先を読んだり後戻りしたりすることで、意図的な決定を下すことができます。
実験では、ToT が、重要な計画や検索を必要とする 3 つの新しいタスク (24 ポイント ゲーム、クリエイティブ ライティング、ミニクロスワードパズル 。たとえば、24 ポイントのゲームでは、思考連鎖プロンプトを使用した GPT-4 はタスクの 4% しか解決できませんでしたが、ToT は 74% の成功率を達成しました。
 論文アドレス: https://arxiv.org/pdf/2302.04761.pdf
論文アドレス: https://arxiv.org/pdf/2302.04761.pdf
言語モデルは次のことを示しています。特に大規模な状況において、少数の例やテキストによる指示から新しいタスクを解決する実証済みの能力。ただし、逆説的ですが、より単純で小型の特殊なモデルと比較すると、算術演算や事実調査などの基本的な機能で困難が生じます。
この論文では、研究者らは、言語モデルが単純な API を通じて外部ツールの使用を学習し、この 2 つの最適な組み合わせを実現できることを示しています。
彼らは、どの API を呼び出すか、いつ呼び出すか、どのパラメータを渡すか、結果を将来のトークン予測に最適に組み込む方法を決定するためにトレーニングされたモデルである Toolformer を導入しました。
これは自己監視型の方法で行われ、API ごとに少数のデモンストレーションのみが必要になります。電卓、質疑応答システム、検索エンジン、翻訳システム、カレンダーなどのさまざまなツールが統合されています。
Toolformer は、コアの言語モデリング機能を犠牲にすることなく、大規模なモデルと競合しながら、さまざまなダウンストリーム タスクで大幅に向上したゼロショット パフォーマンスを実現します。
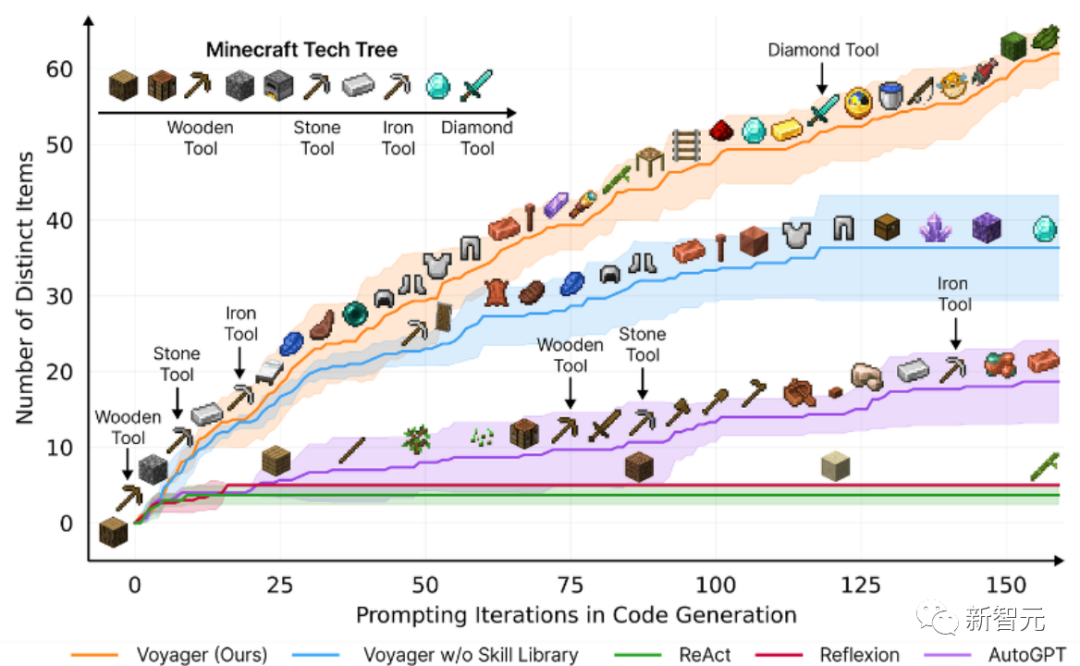
#論文のタイトル: Voyager: 大規模な言語モデルを備えたオープンエンドの組み込みエージェント
#論文アドレス: https://arxiv.org/pdf/2305.16291.pdf
この論文では、最初の A 学習エージェントである Voyager について紹介します。 Minecraft で継続的に世界を探索し、多様なスキルを習得し、独自の発見を行うことができる大規模言語モデル (LLM)。
Voyager は 3 つの主要なコンポーネントで構成されています:
探索を最大限に高めるように設計された自動レッスン、
不斷增長的可執行程式碼技能庫,用於儲存和檢索複雜行為,
新的迭代提示機制,整合了環境回饋、執行錯誤和自我驗證以改進程序。
Voyager透過黑盒查詢與GPT-4進行交互,避免了對模型參數進行微調的需求。
根據實證研究,Voyager展現出強大的環境脈絡中的終身學習能力,並在玩Minecraft方面表現出卓越的熟練度。
它獲得了比先前技術水平高出3.3倍的獨特物品,行進距離更長2.3倍,並且解鎖關鍵技術樹里程碑的速度比先前技術水平快15.3倍。
不過,雖然Voyager能夠在新的Minecraft世界中利用學到的技能庫從零開始解決新穎任務,但其他技術則難以泛化。
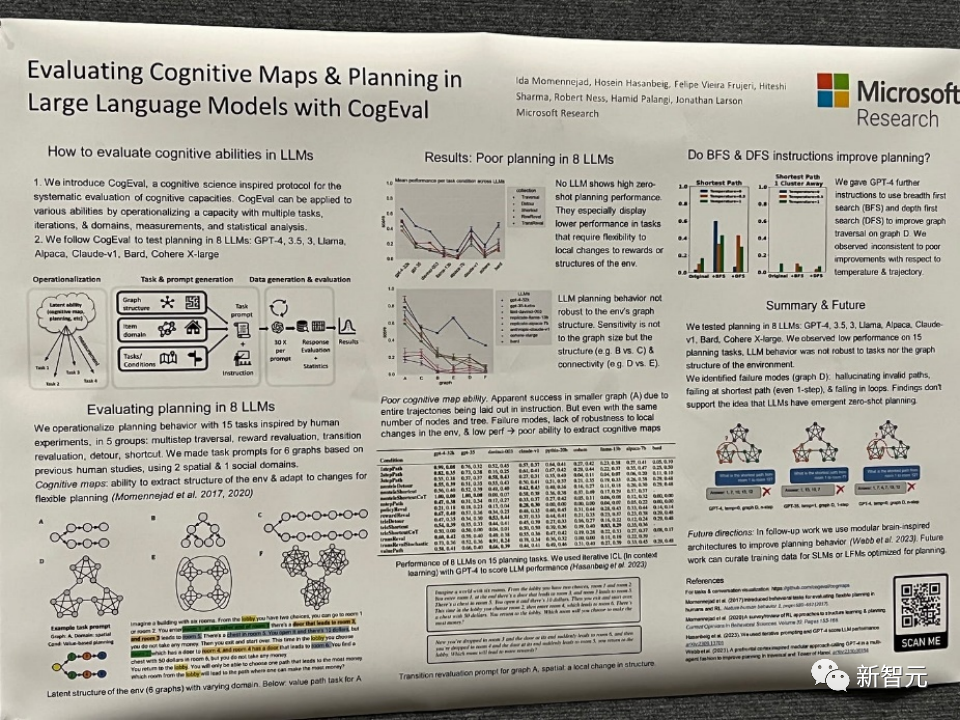
論文主題:Evaluating Cognitive Maps and Planning in Large Language Models with CogEval

##論文網址:https://openreview.net/pdf?id=VtkGvGcGe3
論文首先提出了CogEval,這是一個受認知科學啟發的系統評估大型語言模型認知能力的協議。
其次,論文使用CogEval系統評估了八個LLMs(OpenAI GPT-4、GPT-3.5-turbo-175B、davinci-003-175B、Google Bard、Cohere-xlarge- 52.4B、Anthropic Claude-1-52B、LLaMA-13B和Alpaca-7B)的認知地圖和規劃能力。任務提示是基於人類實驗,且不在LLM訓練集中存在。
研究發現,雖然LLMs在一些結構較簡單的規劃任務中顯示出明顯的能力,但一旦任務變得複雜,LLMs就會陷入盲區,包括對無效軌蹟的幻覺和陷入循環。
這些發現不支持LLMs具有即插即用的規劃能力的觀點。可能是因為LLMs不理解規劃問題背後的潛在關係結構,即認知地圖,並在根據基礎結構展開目標導向軌跡時出現問題。
論文主題:Mamba: Linear-Time Sequence Modeling with Selective State Spaces

論文網址:https://openreview.net/pdf?id=AL1fq05o7H
作者指出了目前許多次線性時間架構,如線性注意力、門控卷積和循環模型,以及結構化狀態空間模型(SSMs),旨在解決Transformer在處理長序列時的計算效率低下問題。然而,這些模型在重要的語言等領域上並沒有像注意力模型那樣表現出色。作者認為這些
型的一個關鍵弱點是它們無法進行基於內容的推理,並且進行了一些改進。
首先,簡單地讓 SSM 參數作為輸入的函數,可以解決其離散模態的弱點,允許模型根據當前標記選擇性地沿序列長度維度傳播或忘記訊息。
其次,儘管這種變化阻止了高效卷積的使用,但作者在循環模式下設計了一種硬體感知的平行演算法。將這些選擇性 SSM 整合到簡化的端對端神經網路架構中,無需注意力機制,甚至不需要 MLP 模組 (Mamba)。
Mamba在推理速度上表現出色(比Transformers高5倍),並且在序列長度上呈線性縮放,在真實數據上的性能提高了,達到了百萬長度序列。
作為一種通用的序列模型骨幹,Mamba在語言、音訊和基因組學等多個領域取得了最先進的性能。在語言建模方面,Mamba-1.4B模型在預訓練和下游評估中均優於相同大小的Transformers模型,與其兩倍大小的Transformers模型相匹敵。

雖然這些論文在2023年沒有獲得獎項,但例如Mamba,作為一種能夠革新語言模型架構的技術模型,評估其影響還為時過早。
明年NeurIPS會如何走向,2024的人工智慧和神經資訊系統領域又會如何發展,雖然目前眾說紛紜,但又有誰能打包票呢?讓我們拭目以待。
以上がNeurIPS 2023 のレビュー: 清華社 ToT は大規模モデルに焦点を当てますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



