昨年、DreamFusion は、3D 静的オブジェクトとシーンの生成という新しいトレンドを主導してきました。テクノロジー分野は広く注目を集めています。昨年を振り返ると、3D 静的生成テクノロジの品質と制御が大幅に進歩しました。技術開発はテキストベースの生成から始まり、徐々に単一ビュー画像に統合され、さらに複数の制御信号を統合するように発展しました。 これに比べ、3D ダイナミック シーンの生成はまだ初期段階にあります。 2023 年の初めに、Meta は MAV3D を立ち上げ、テキストに基づいて 3D ビデオを生成する最初の試みを行いました。ただし、オープンソースのビデオ生成モデルが不足しているため、この分野の進歩は比較的遅いです。 ところが、グラフィックとテキストを組み合わせた3D動画生成技術が登場しました。 テキストベースの 3D ビデオ生成は多様なコンテンツを生成できますが、オブジェクトの詳細やポーズの制御には依然として制限があります。 3D 静的生成の分野では、単一の画像を入力として使用して 3D オブジェクトを効果的に再構築できます。これに触発されて、シンガポール国立大学 (NUS) とファーウェイの研究チームは、Animate124 モデル を提案しました。このモデルは、単一の画像と対応するアクションの説明を組み合わせて、3D ビデオ生成の正確な制御を可能にします。 
- プロジェクトのホームページ: https://animate124.github.io/
- 論文アドレス: https://animate124.github.io/
- ://arxiv.org/abs/2311.14603
コード: https://github.com/HeliosZhao/Animate124
静的最適化と動的最適化、粗い最適化と細かい最適化に従って、この記事では 3D ビデオ生成を 3 つの段階に分割します: 1) 静的生成段階: 鹿肉グラフと 3D グラフ拡散モデルを使用して、単一の画像から 3D オブジェクトを生成します。2)動的ラフ生成ステージ: Vincent ビデオ モデルを使用して、言語記述に基づいてアクションを最適化します; 3) セマンティック最適化ステージ: さらに、パーソナライズされた微調整 ControlNet を使用して、第 2 ステージで言語記述によって引き起こされるオフセットを最適化および改善します。
) を使用した Magic123 メソッドの続きです。静的オブジェクトを生成します。画像に基づく:
条件付き画像に対応するパースペクティブについては、最適化のためにさらに損失関数を使用します:
上記の 2 つの最適化目標を通じて、マルチビュー 3D の一貫した静的オブジェクトが取得されます (この段階はフレーム図では省略されています)。
では、静的 3D を初期フレームとして扱い、言語記述に基づいてアクションを生成します。具体的には、動的 3D モデル (動的 NeRF) は、連続タイムスタンプを持つマルチフレーム ビデオをレンダリングし、このビデオを Vincent ビデオ拡散モデルに入力し、SDS 蒸留損失を使用して動的 3D モデルを最適化します。
Vincent ビデオの蒸留損失のみを使用すると、3D モデルが画像の内容を忘れてしまい、ランダム サンプリングではビデオの初期段階と終了段階でのトレーニングが不十分になります。したがって、この論文の研究者は、開始タイムスタンプと終了タイムスタンプをオーバーサンプリングしました。また、最初のフレームをサンプリングするときに、最適化 (3D グラフの SDS 蒸留損失) のために追加の静的関数が使用されます。したがって、この段階での損失関数は次のとおりです:
# # 初期フレームのオーバーサンプリングと追加の監視を行っても、オブジェクトの外観は、Vincent のビデオ拡散モデルを使用した最適化プロセス中にテキストの影響を受けるため、参照画像がシフトします。したがって、この論文では、パーソナライズされたモデルを通じてセマンティック オフセットを改善するためのセマンティック最適化ステージを提案します。
写真が 1 枚しかないため、Wensheng ビデオ モデルをパーソナライズすることはできません。この記事では、画像とテキストに基づいた拡散モデルを紹介し、この拡散モデルをパーソナライズします。曲。この拡散モデルは、元のビデオの内容や動作を変更するものではなく、外観を調整するだけです。したがって、この記事では ControlNet-Tile グラフィック モデルを採用し、前段階で生成されたビデオ フレームを条件として使用し、言語に応じて最適化します。 ControlNet は安定拡散モデルに基づいており、参照画像内の意味情報を抽出するために安定拡散のパーソナライズされた微調整 (テキスト反転) のみが必要です。個別に微調整した後、ビデオをマルチフレーム画像として扱い、ControlNet を使用して 1 つの画像を監視します。
また、ControlNet はラフな画像を条件として使用するため、分類子なしガイダンス (CFG) では、Vincent 図や Vincent ビデオ モデルのように非常に大きな値 (通常は 100) を使用する代わりに、通常の範囲 (約 10) を使用できます。 CFG が大きすぎると画像の過飽和が発生するため、ControlNet 拡散モデルを使用すると過飽和現象が軽減され、より良い生成結果が得られます。この段階での監視は、動的段階損失と ControlNet 監視によって結合されます。
グラフィックスとテキストに基づく最初の 3D ビデオ生成モデルとして、この記事では 2 つのベースライン モデルおよび MAV3D と比較します。 Animate124 は他の方法と比べて良い結果をもたらします。
図 2. Animate124 vs. 2 つのベースラインの比較
図 3.1. Animate124 と MAV3D Vincent 3D ビデオの比較
図 3.1. Animate124 と MAV3D Tusheng 3D ビデオの比較定量的結果の比較
この記事では、CLIP と手動評価を使用して品質を生成しています。CLIP 指標には、テキストとの類似性、検索精度、画像品質が含まれます。類似性と時間的一貫性。手動評価指標には、テキストとの類似性、写真との類似性、ビデオ品質、動きのリアルさ、動きの振幅が含まれます。手動評価は、対応するメトリックにおける Animate124 の選択に対する単一モデルの比率で表されます。
2 つのベースライン モデルと比較して、Animate124 は CLIP 評価と手動評価の両方でより良い結果を達成しています。
#表 1. Animate124 と 2 つのベースラインの定量的比較
Animate124 は、テキストの説明に基づいてあらゆる画像を 3D ビデオに変換する最初の方法です。監視とガイダンスに複数の拡散モデルを使用し、4D 動的表現ネットワークを最適化して高品質の 3D ビデオを生成します。
以上が写真とアクションコマンドだけで、Animate124 は簡単に 3D ビデオを生成できますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





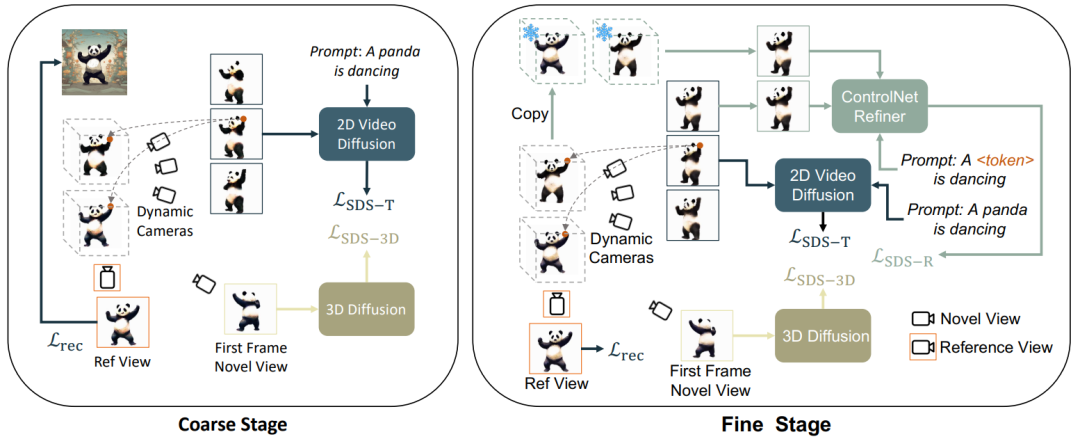 静的最適化と動的最適化、粗い最適化と細かい最適化に従って、この記事では 3D ビデオ生成を 3 つの段階に分割します: 1) 静的生成段階: 鹿肉グラフと 3D グラフ拡散モデルを使用して、単一の画像から 3D オブジェクトを生成します。2)動的ラフ生成ステージ: Vincent ビデオ モデルを使用して、言語記述に基づいてアクションを最適化します; 3) セマンティック最適化ステージ: さらに、パーソナライズされた微調整 ControlNet を使用して、第 2 ステージで言語記述によって引き起こされるオフセットを最適化および改善します。
静的最適化と動的最適化、粗い最適化と細かい最適化に従って、この記事では 3D ビデオ生成を 3 つの段階に分割します: 1) 静的生成段階: 鹿肉グラフと 3D グラフ拡散モデルを使用して、単一の画像から 3D オブジェクトを生成します。2)動的ラフ生成ステージ: Vincent ビデオ モデルを使用して、言語記述に基づいてアクションを最適化します; 3) セマンティック最適化ステージ: さらに、パーソナライズされた微調整 ControlNet を使用して、第 2 ステージで言語記述によって引き起こされるオフセットを最適化および改善します。 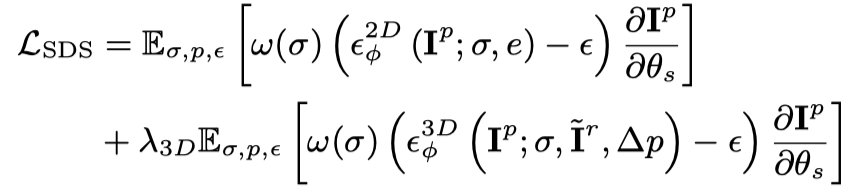
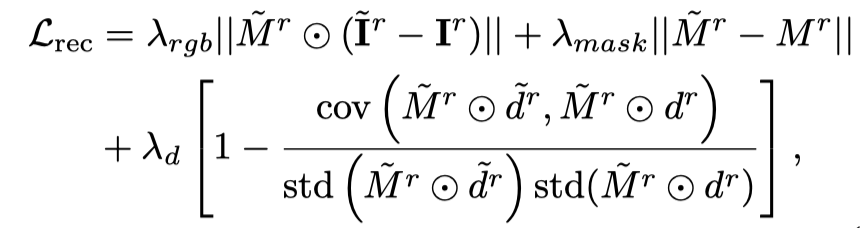
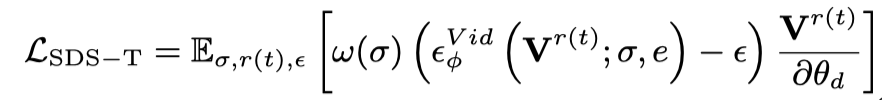 Vincent ビデオの蒸留損失のみを使用すると、3D モデルが画像の内容を忘れてしまい、ランダム サンプリングではビデオの初期段階と終了段階でのトレーニングが不十分になります。したがって、この論文の研究者は、開始タイムスタンプと終了タイムスタンプをオーバーサンプリングしました。また、最初のフレームをサンプリングするときに、最適化 (3D グラフの SDS 蒸留損失) のために追加の静的関数が使用されます。
Vincent ビデオの蒸留損失のみを使用すると、3D モデルが画像の内容を忘れてしまい、ランダム サンプリングではビデオの初期段階と終了段階でのトレーニングが不十分になります。したがって、この論文の研究者は、開始タイムスタンプと終了タイムスタンプをオーバーサンプリングしました。また、最初のフレームをサンプリングするときに、最適化 (3D グラフの SDS 蒸留損失) のために追加の静的関数が使用されます。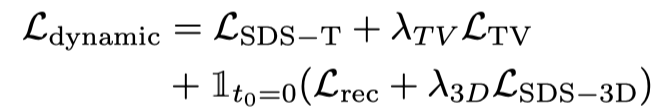
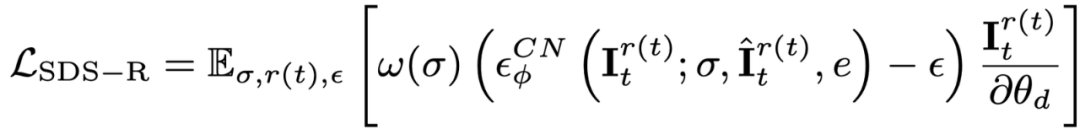
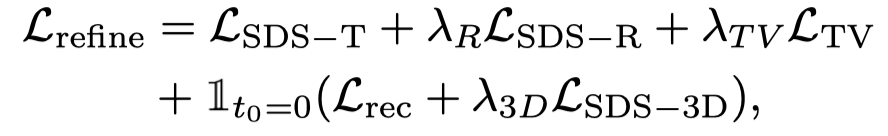




















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



