


大規模なマルチモーダル高解像度ドキュメントも登場しました!
この技術は、画像内の情報を正確に識別するだけでなく、ユーザーのニーズに応じて質問に答えるために独自の知識ベースを呼び出すこともできます
たとえば、写真にマリオのインターフェイスが表示されている場合、直接できます 答えは、これは任天堂の作品であるということです。

このモデルは ByteDance と中国科学技術大学によって共同研究され、2023 年 11 月 24 日に arXiv にアップロードされました
ここで研究してください、著者チームは、統合された 高解像度 マルチモーダル ドキュメント大規模モデル DocPedia である DocPedia を提案しました。

この研究では、著者は高解像度の文書画像を解析できない既存のモデルの欠点を解決する新しい方法を使用しました。
DocPedia の解像度は最大 2560 × 2560 ですが、現在、LLaVA や MiniGPT-4 などの業界の先進的なマルチモーダル大型モデルでは、画像解像度の上限が 336 × 336 であるため、これを使用できません。高解像度のドキュメント画像を解析します。
それでは、このモデルはどのように機能し、どのような最適化手法が使用されているのでしょうか?
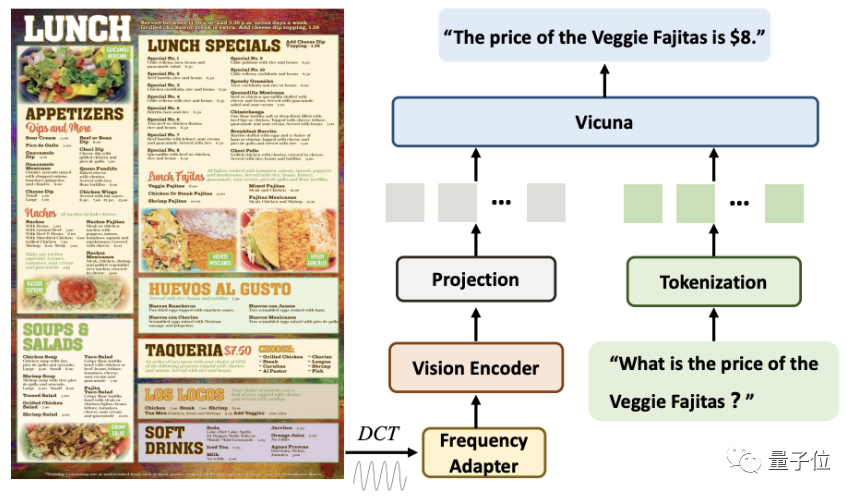
本稿では、DocPedia の高解像度画像とテキスト理解の例を示します。 DocPedia には、指示の内容を理解し、高解像度の文書画像や自然風景の画像から関連するグラフィック情報やテキスト情報を正確に抽出する機能があることがわかります。
たとえば、この一連の写真では、DocPedia が簡単に実行できます。写真から地雷 ナンバープレートの番号やコンピュータの構成などの文字情報により、手書きの文字でも正確に判断できます。

DocPedia は、画像内のテキスト情報と組み合わせて、大規模なモデル推論機能を使用して、コンテキストに基づいて問題を分析することもできます。

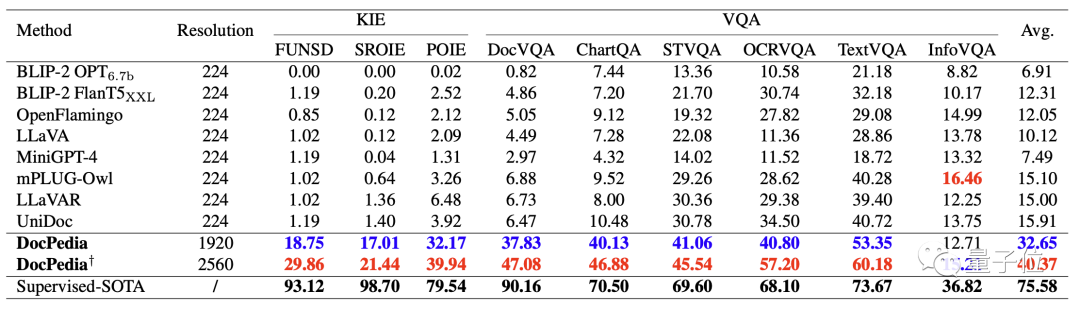
 #次の表は、いくつかの既存のマルチモーダル大規模モデルと DocPedia の重要情報抽出 (KIE) およびビジュアル質問応答 (VQA) 機能を定量的に比較しています。
#次の表は、いくつかの既存のマルチモーダル大規模モデルと DocPedia の重要情報抽出 (KIE) およびビジュアル質問応答 (VQA) 機能を定量的に比較しています。
解像度を高め、効果的なトレーニング方法を採用することにより、DocPedia がさまざまなテスト ベンチマークで大幅な改善を達成したことがわかります。
 それでは、DocPedia はどのようにして成果を上げているのでしょうか。そんな効果?
それでは、DocPedia はどのようにして成果を上げているのでしょうか。そんな効果?
周波数領域からの解像度の問題の解決
問題解決の戦略に関しては、既存の方法とは異なり、DocPedia は
周波数領域の観点から問題を解決します。 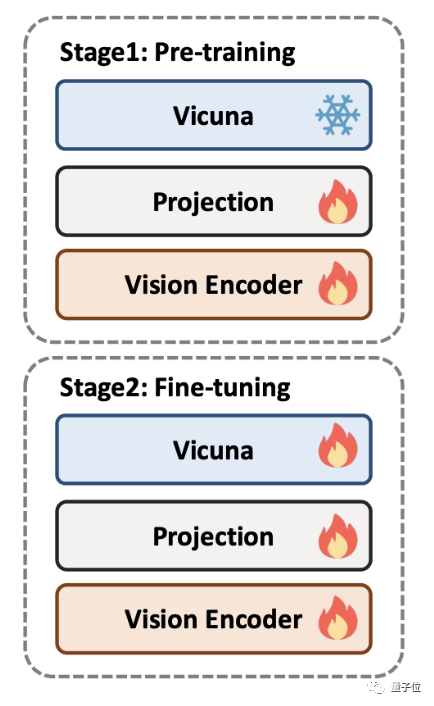
このステップの後、カスケード周波数ドメイン アダプター (周波数アダプター) を使用します。入力信号をビジョン エンコーダーに渡します。より深い解像度圧縮と特徴抽出のための
この方法では、2560×2560 の画像を 1600 個のトークンで表現できます。
元の画像をビジュアル エンコーダ (Swin Transformer など) に直接入力する場合と比較して、この方法ではトークンの数が 4 倍削減されます。
最後に、これらのトークンは、シーケンス次元の命令から変換されたトークンと結合され、応答用の大規模モデルに入力されます。
アブレーション実験の結果は、解像度の向上と共同認識理解の微調整の実行が、DocPedia のパフォーマンスを向上させる 2 つの重要な要素であることを示しています
次の図は、DocPedia の回答を紙の画像と、異なる入力スケールでの同じコマンドと比較したものです。解像度が 2560×2560 に増加した場合にのみ、DocPedia が正しく応答することがわかります。

下の図は、異なる微調整戦略の下で、同じシーンのテキスト画像と同じ命令に対する DocPedia のモデル応答を比較しています。
この例から、知覚と理解によって共同で微調整されたモデルは、テキスト認識と意味論的な質問応答を正確に実行できることがわかります

#論文を表示するには、次のリンクをクリックしてください: https://arxiv.org/abs/2311.11810
以上が解像度の限界を突破: Byte と中国科学技術大学が大規模なマルチモーダル ドキュメント モデルを明らかにの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



