


知識の抽出とは通常、豊富な意味情報を含むタグやフレーズなどの非構造化テキストから構造化情報をマイニングすることを指します。これは、コンテンツ理解や製品理解などのシナリオで業界で広く使用されています。ユーザーが作成したテキスト情報から価値のあるタグを抽出することで、コンテンツや製品に適用されます。
知識の抽出には、通常、分類が伴います。抽出されたタグまたはフレーズの抽出は、通常、固有表現認識タスクとしてモデル化されます。一般的な固有表現認識タスクは、固有表現コンポーネントを識別し、コンポーネントを地名、人名、組織名などに分類することです。ドメイン関連のタグ単語の抽出は、 will タグワードは識別され、シリーズ (Air Force One、Sonic 9)、ブランド (Nike、Li Ning)、タイプ (靴、衣類、デジタル)、スタイル (INS スタイル、レトロスタイル、北欧風))待ってください。
説明の便宜上、以下では情報量の多いタグやフレーズを総称してタグワードと呼びます
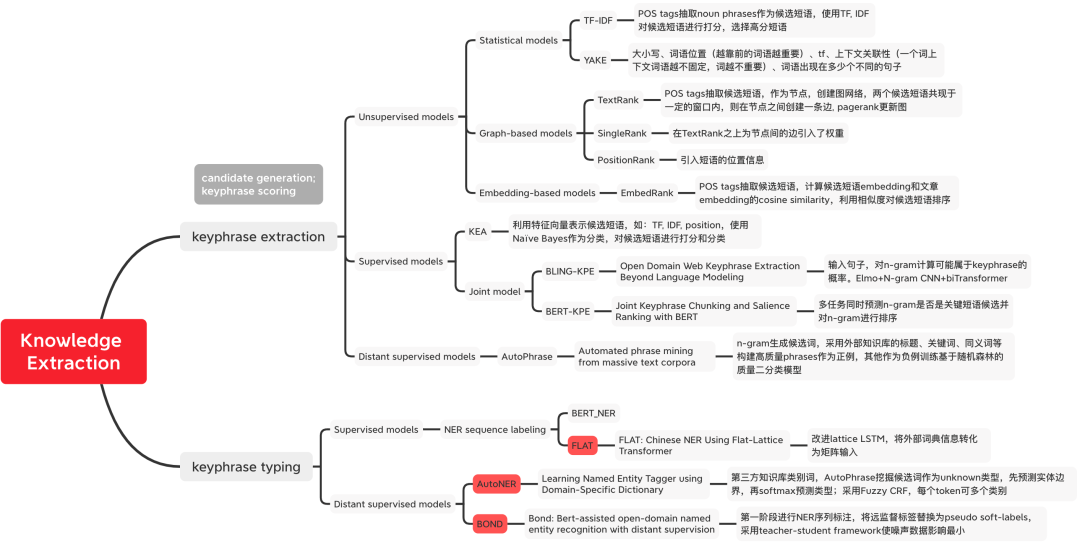 #図 1 知識抽出手法の分類
#図 1 知識抽出手法の分類
#統計ベースの方法
Specificビジネス このシナリオでは、外部ツールを使用して、品詞タグを使用して名詞をスクリーニングするなど、候補単語の最初のスクリーニングを実行できます。
YAKE[1]: キーワードの特徴を捉えるために 5 つの特徴が定義されており、これらの特徴がヒューリスティックに組み合わされて各キーワードにスコアが割り当てられます。スコアが低いほど、キーワードの重要性が高くなります。 1) 大文字: 大文字の用語 (各文の先頭の単語を除く) は、中国語の太字の単語の数に対応して、小文字の用語よりも重要です; 2) 単語の位置: テキストの各段落の一部の単語先頭は後続の単語よりも重要です; 3) 単語の頻度、単語の出現頻度をカウントします; 4) 単語のコンテキスト、固定ウィンドウ サイズの下で表示される異なる単語の数を測定するために使用されます。発生するほど、単語の重要性は低くなります; 5) 単語がさまざまな文に出現する回数が多く、単語がより多くの文に出現するほど、その単語の重要性は高くなります。#表現ベースのメソッド埋め込みベースのモデル
表現ベースのメソッドは、候補単語とドキュメントのランク間のベクトル類似度を計算します。候補の言葉。
EmbedRank[3]: 単語分割と品詞タグ付けを通じて候補単語を選択し、事前トレーニング済みの Doc2Vec と Sent2vec を候補単語とドキュメントのベクトル表現として使用し、コサイン類似度を計算してランク付けします。候補の言葉。同様に、KeyBERT[4] は、EmbedRank のベクトル表現を BERT に置き換えます。
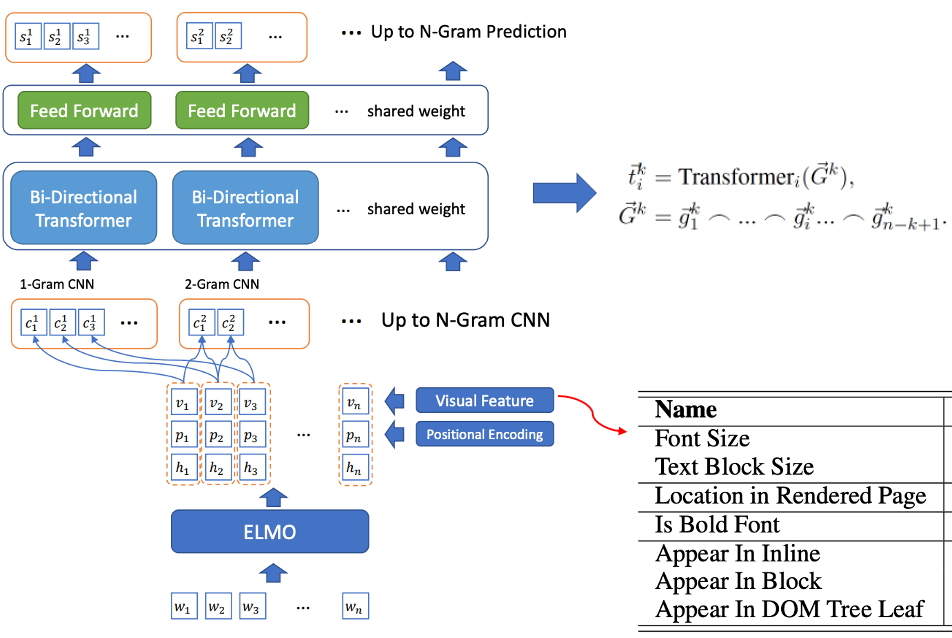 #図 2 BLING-KPE モデル構造
#図 2 BLING-KPE モデル構造
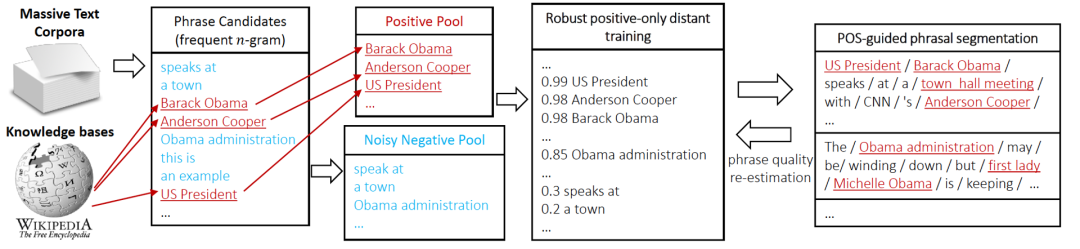 図 3 AutoPhrase タグ マイニング プロセス
図 3 AutoPhrase タグ マイニング プロセス
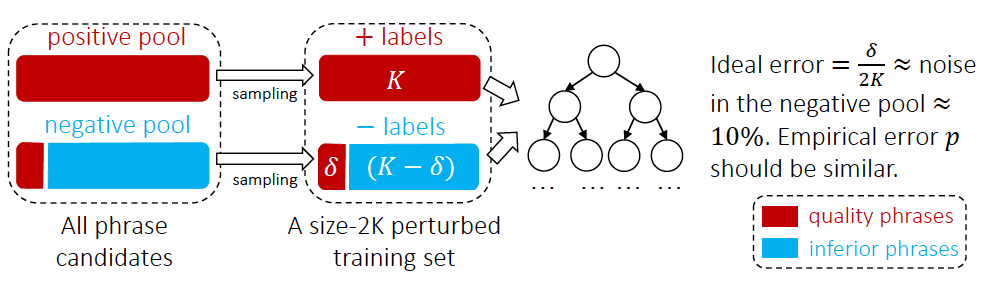 図 4 AutoPhrase のタグ語分類方法
図 4 AutoPhrase のタグ語分類方法
Lattice LSTM[8] は中国語 NER タスクに語彙情報を導入した最初の作品です. Lattice は有向非巡回グラフです. 語彙の開始文字と終了文字がグリッドの位置を決定します. 語彙情報 (辞書) を通じて) 文をマッチングすると、図 5(a) に示すように、格子状の構造が得られます。 Lattice LSTM 構造は、5(b) に示すように、語彙情報をネイティブ LSTM に融合します。現在の文字については、その文字で終わるすべての外部辞書情報が融合されます。たとえば、「store」は「人々とドラッグ ストア」を融合し、 「薬局」の情報です。 Lattice LSTM は、文字ごとにアテンション メカニズムを使用して、可変数の単語単位を融合します。 Lattice-LSTM は NER タスクのパフォーマンスを効果的に向上させますが、RNN 構造は長距離の依存関係をキャプチャできず、語彙情報の導入には損失が伴います。同時に、動的な Lattice 構造は GPU 並列処理を完全には実行できません。Flat[9] モデルこれら 2 つの質問を効果的に改善しました。図 5(c) に示すように、フラット モデルは、Transformer 構造を通じて長距離の依存関係をキャプチャし、Lattice 構造を統合する位置エンコーディングを設計します。文字が一致する単語を文につなぎ合わせた後、各文字と単語は 2 つ構成されます。ヘッド位置エンコーディングとテール位置エンコーディングは、格子構造を有向非巡回グラフからフラットなフラット格子トランスフォーマー構造に平坦化します。
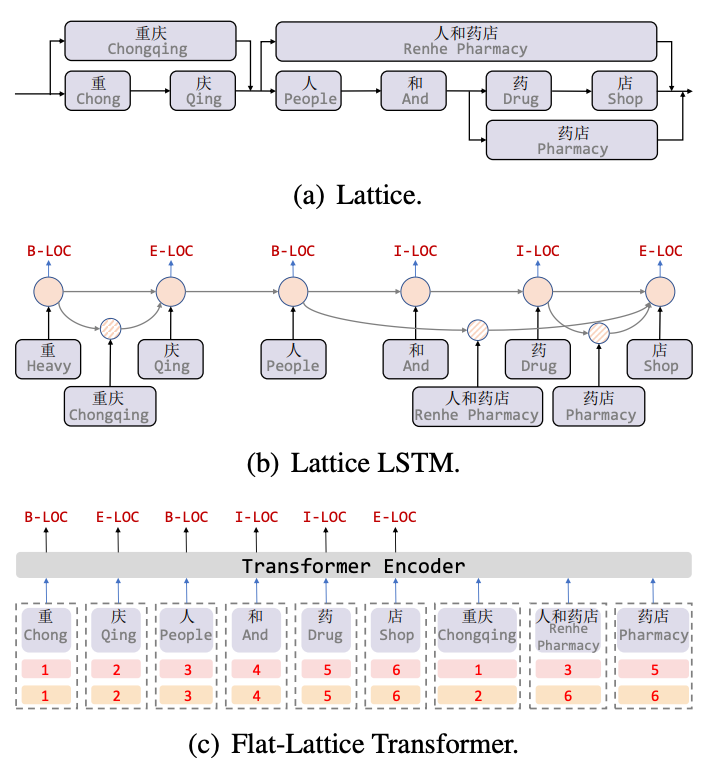 #図 5 語彙情報を導入した NER モデル
#図 5 語彙情報を導入した NER モデル
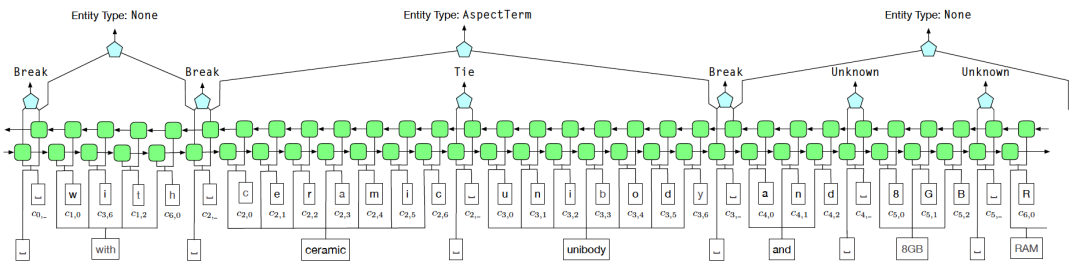
#AutoNER
図 6 AutoNER モデル構造図
BOND
BOND[12] は、遠隔教師あり学習に基づく 2 段階のエンティティ認識モデルです。第 1 段階では、長距離ラベルを使用して、事前トレーニングされた言語モデルを NER タスクに適応させます。第 2 段階では、Student モデルと Teacher モデルが最初にステージ 1 でトレーニングされたモデルで初期化され、次に疑似-教師モデルによって生成されたラベルは、学生モデルをペアにするために使用されます。 遠隔監視によって引き起こされる騒音問題の影響を最小限に抑えるためにトレーニングを実施します。
#図#書き直す必要がある内容は次のとおりです: 図 7 BOND トレーニングのフローチャート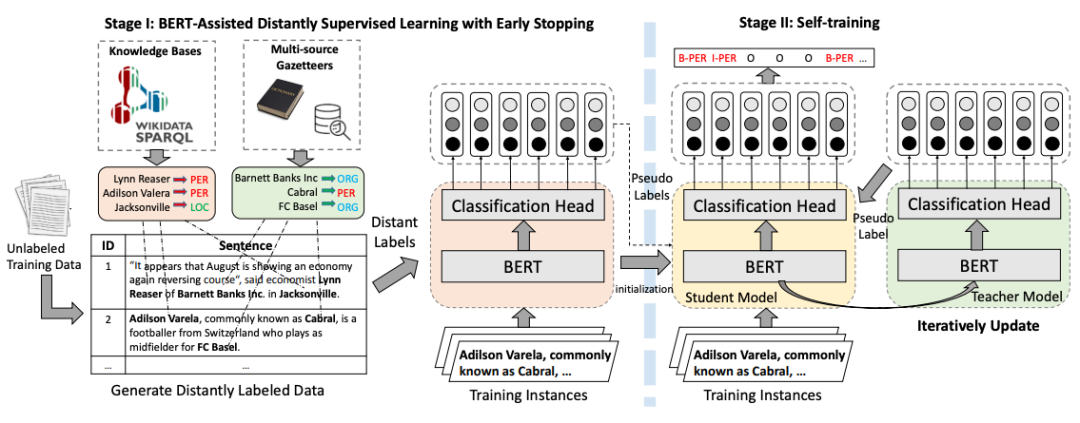 #5. 概要
#5. 概要
【2】Mihalcea R, Tarau P. Textrank: Bringing order into text[C]//自然言語処理における経験的手法に関する 2004 年会議議事録. 2004: 404-411.
【3 】Bennani-Smires K、Musat C、Hossmann A, et al. 文埋め込みを使用した単純な教師なしキーフレーズ抽出[J]. arXiv プレプリント arXiv:1801.04470, 2018.
【4】KeyBERT、https://github .com/MaartenGr/KeyBERT
【5】Witten I H、Paynter G W、Frank E、他 KEA: 実践的な自動キーフレーズ抽出[C]//デジタル ライブラリに関する第 4 回 ACM 会議議事録。1999 年: 254-255.
翻訳内容: [6] Xiong L、Hu C、Xiong C、他。言語モデルを超えたオープンドメイン Web キーワード抽出[J]。 arXiv プレプリント arXiv:1911.02671、2019
[7] Sun, S.、Xiong, C.、Liu, Z.、Liu, Z.、および Bao, J. (2020). 共同キーフレーズのチャンキングと顕著性BERT によるランキング。arXiv プレプリント arXiv:2004.13639.
書き直す必要がある内容は次のとおりです: [8] Zhang Y、Yang J.格子 LSTM[C] を使用した中国語の固有表現認識。 ACL 2018
【9】Li X、Yan H、Qiu X、他 FLAT: フラット格子トランスを使用した中国の NER[C]. ACL 2020.
【10】Shang J 、Liu J、Jiang M、他、大量のテキスト コーパスからの自動フレーズ マイニング[J]. 知識とデータ エンジニアリングに関する IEEE トランザクション、2018、30(10): 1825-1837.
【11】 Shang J, Liu L, Ren X, et al. ドメイン固有辞書を使用した名前付きエンティティ タガーの学習[C]. EMNLP, 2018.
【12】Liang C, Yu Y, Jiang H, et al. Bond : 遠隔監視による Bert 支援オープンドメイン固有表現認識[C]//知識発見とデータ マイニングに関する第 26 回 ACM SIGKDD 国際会議議事録. 2020: 1054-1064.
【13】Meituan Exploration検索における NER テクノロジーの実践、https://zhuanlan.zhihu.com/p/163256192
以上が知識の抽出について話しましょう。学習しましたか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。




























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



