


この記事は自動運転ハート公式アカウントの許可を得て転載しておりますので、転載については転載元にご連絡ください。
エンドツーエンドは今年非常に人気のある方向性であり、今年の CVPR 最優秀論文も受賞しました。ただし、エンドツーエンドには、解釈可能性の低さ、収束トレーニングの難しさなど、多くの問題もあります。エンドツーエンドの解釈可能性を共有します。最新の説明作品は ADAPT です。このメソッドは、Transformer アーキテクチャに基づいており、マルチタスクの共同トレーニングを通じて、車両の動作の説明と各決定の推論をエンドツーエンドで出力します。 ADAPT に関する著者の考えの一部は次のとおりです:
エンドツーエンドの自動運転は運輸業界において大きな可能性を秘めており、現在この分野の研究が盛んに行われています。例えば、CVPR2023の最優秀論文であるUniADは、エンドツーエンドの自動運転を行っています。しかし、自動化された意思決定プロセスの透明性と説明可能性の欠如は、その発展を妨げるでしょう 結局のところ、道路を走行する実際の車両にとって安全性は最優先事項です。モデルの解釈可能性を向上させるためにアテンション マップやコスト ボリュームを使用するという初期の試みがいくつかありましたが、これらの方法を理解するのは困難です。したがって、この研究の出発点は、意思決定を説明するわかりやすい方法を見つけることです。下の図はいくつかの方法を比較したものですが、明らかに言葉で見た方が理解しやすいです。
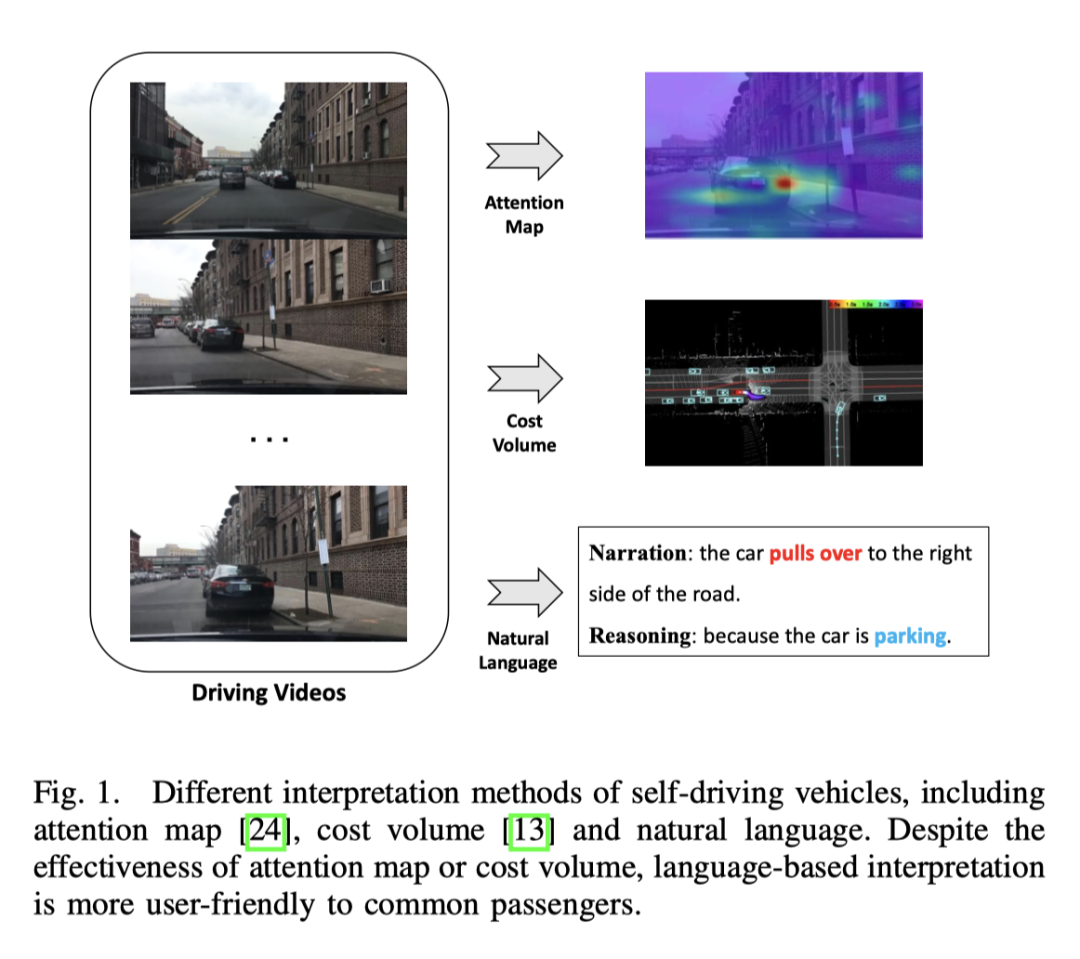
#効果は依然として非常に優れており、特に3番目の暗い夜のシーン、信号機が注目されました。 
この分野の現在の進捗状況
エンドツーエンドの自動運転
自動運転の分野では、ほとんどの解釈可能方法は視覚に基づいており、一部は LiDAR の作業に基づいています。一部の方法では、アテンション マップを利用して重要でない画像領域を除外し、自動運転車の動作が合理的で説明可能に見えるようにします。ただし、アテンション マップには、それほど重要ではない領域が含まれる場合があります。 LIDAR と高精度地図を入力として使用し、他の交通参加者の境界ボックスを予測し、オントロジーを利用して意思決定推論プロセスを説明する方法もあります。さらに、HD マップへの依存を減らすために、セグメンテーションを通じてオンライン マップを構築する方法もあります。ビジョンまたは LIDAR ベースの方法では良好な結果が得られますが、口頭での説明が不足しているため、システム全体が複雑で理解しにくいように見えます。研究では、ビデオの特徴をオフラインで抽出して制御信号を予測し、ビデオ説明のタスクを実行することで、自動運転車のテキスト解釈の可能性を初めて調査しています。
このエンドツーエンドのフレームワークは、マルチタスク学習を使用して、テキスト生成と予測制御信号の 2 つのタスクでモデルを共同トレーニングします。マルチタスク学習は自動運転に広く使用されています。データ活用の向上と機能の共有により、異なるタスクを共同トレーニングすることで各タスクのパフォーマンスが向上するため、本研究では制御信号予測とテキスト生成の 2 つのタスクの共同トレーニングを使用します。
次はネットワーク構造図です。
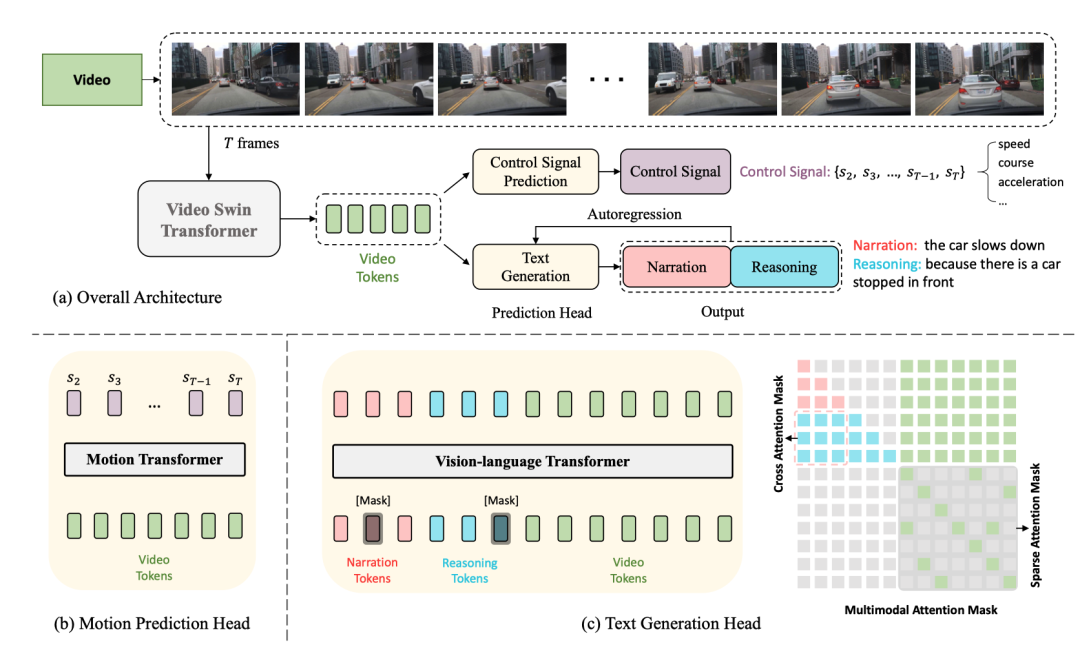
全体構造は 2 つに分かれていますタスク:
そのうち、DCG と CSP の 2 つのタスクはビデオ エンコーダーを共有しますが、異なる予測ヘッドを使用して異なる最終出力を生成します。
DCG タスクでは、ビジョン言語変換エンコーダーを使用して 2 つの自然言語文を生成します。
CSP タスクの場合、モーション変換エンコーダを使用して制御信号のシーケンスを予測します
ビデオ スイング トランスフォーマは、ここで入力に使用されます。ビデオ フレームはビデオ特徴トークンに変換されます。
Input zhenimage、形状は 、フィーチャのサイズは 、ここで はフィーチャの寸法ですチャネル .
上記の機能 はトークン化後に取得されます。 寸法 のビデオ トークンを作成し、MLP を使用してテキスト トークンの埋め込みに合わせて寸法を調整し、テキスト トークンとビデオ トークンを一緒にビジョンにフィードします。アクションを生成するための言語変換エンコーダ 説明と推論。
は、入力 フレーム ビデオに対応します。制御信号 の出力があります。 CSP ヘッド Yes 。各制御信号は必ずしも 1 次元である必要はなく、速度、加速度、方向などを同時に含むなど、多次元にすることもできます。ここでのアプローチは、ビデオ特徴をトークン化し、モーション トランスフォーマーを通じて一連の出力信号を生成することです。損失関数は MSE、
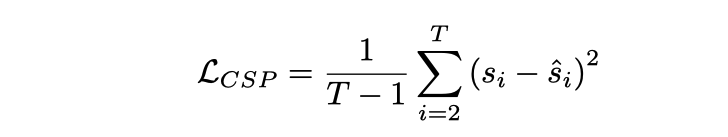
であることに注意してください。いいえ 最初のフレームでは動的情報が少なすぎるため、最初のフレームが含まれます
このフレームでは、共有ビデオ エンコーダのため、実際にはCSP と DCG の 2 つのタスクがビデオ表現のレベルで連携していると仮定しました。出発点は、動作記述と制御信号の両方がきめ細かい車両動作の異なる表現であり、動作推論の説明は主に車両動作に影響を与える運転環境に焦点を当てているということです。
共同トレーニングをトレーニングに使用する
共同トレーニングの場所ですが、推論中に独立して実行できることに注意してください。CSP タスクわかりやすい フローチャートに従って映像を直接入力して制御信号を出力するだけ DCGタスクは映像を直接入力して説明と推論を出力 テキストの生成は自己回帰手法に基づいており、ワードごとに行われる[CLS ] の単語が [SEP] で終わるか、長さのしきい値に達しています。
使用されたデータ セットは BDD-X です。このデータ セットには 7000 セグメントが含まれています。ビデオ信号と制御信号。各ビデオの長さは約 40 秒、画像サイズは 、周波数は FPS です。各ビデオには、加速、右折、合流などの 1 ~ 5 つの車両の動作が含まれています。これらのアクションはすべて、アクションの説明 (例: 「車が停止した」) や推論 (例: 「信号が赤だから」) を含むテキストで注釈が付けられます。合計で約 29,000 の動作アノテーションのペアがあります。
ここでは、共同トレーニングの有効性を示すために比較された 3 つの実験を示します。
CSP タスクを削除し、DCG タスクのみを保持することを指します。これは、キャプション モデルのトレーニングのみに相当します。
CSP タスクはまだ存在しませんが、DCG モジュールに入るときに、ビデオマークに加えて、制御信号マークも入力する必要があります
効果の比較は次のとおりです
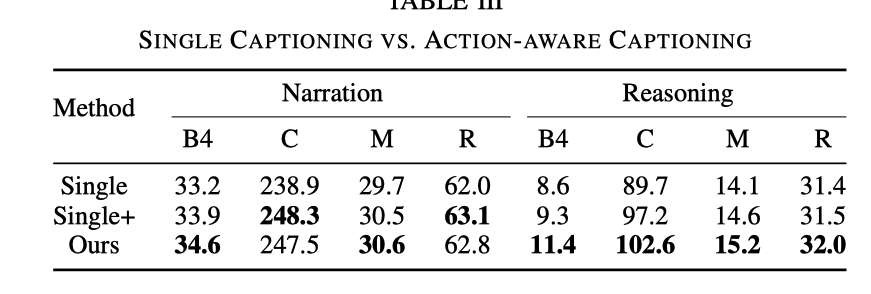
DCGタスクのみとの比較、ADAPT の推論効果は大幅に優れています。制御信号入力があると効果は向上しますが、CSPタスクを追加した場合の効果には及びません。 CSP タスクを追加した後、ビデオを表現し理解する能力が強化されました。
さらに、以下の表は、CSP に対する共同トレーニングの効果も向上していることを示しています。

ここで は精度と理解できます。具体的には、予測された制御信号が切り捨てられます。式は次のとおりです。
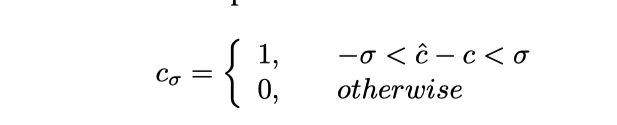
実験では、速度と機首方位が基本的な信号として使用されます。ただし、実験により、信号の 1 つだけを使用した場合、効果は両方の信号を同時に使用した場合ほど良くないことが判明しました。具体的なデータを次の表に示します。
##これは、速度と方向の 2 つの信号が、ネットワークがアクションの説明と推論をよりよく学習するのに役立つことを示しています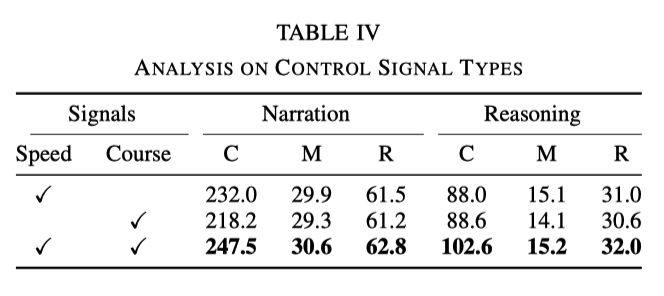
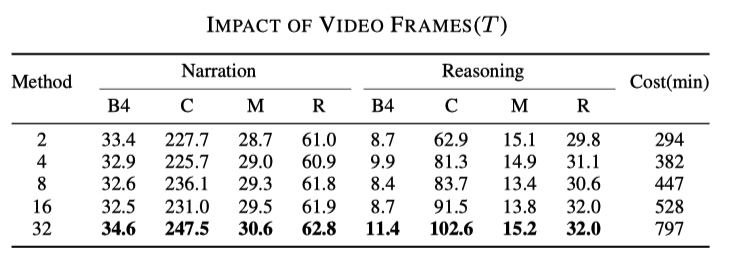
サンプリング レートの影響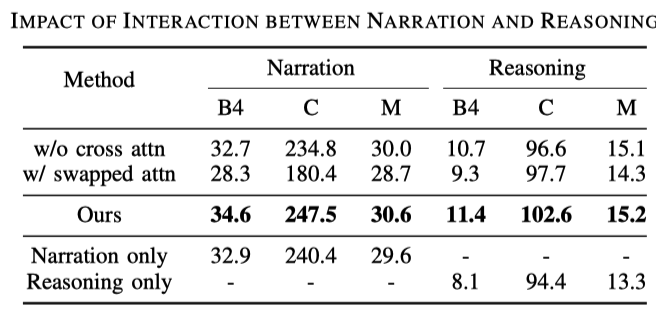
 ##必須 書き換えられた内容は次のとおりです: 元のリンク: https://mp.weixin.qq.com/s/MSTyr4ksh0TOqTdQ2WnSeQ
##必須 書き換えられた内容は次のとおりです: 元のリンク: https://mp.weixin.qq.com/s/MSTyr4ksh0TOqTdQ2WnSeQ
以上が新しいタイトル: ADAPT: エンドツーエンドの自動運転の説明可能性の予備調査の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



