


この問題は<Zhihuホットリスト/Weiboホット検索シーケンスチャート>一連の記事前回の記事の内容 Python を使用してナレッジ Hu ホット リストを定期的にクロールする方法を紹介します/Weibo ホット検索データを取得し、その後の視覚化のために CSV ファイルに保存します。タイミング ダイアグラムの部分は #次の記事 #コンテンツで紹介されたそれがあなたに役立つことを願っています。 read_html — Web フォーム処理 ## 注意:电脑端端直接F12调试页即可看到热榜数据,手机端需要借助抓包工具查看,这里我们使用手机端接口(返回json格式数据,解析比较方便)。 ##コード: 定时间隔设置1S: 效果: 2.3 保存数据 ##3.1 Web ページ分析 ##Weibo ホット検索 URL: https://s.weibo.com/top/summary ##データは、Web ページの ##3.2 データの取得 # 代码: 定时间隔设置1S,效果: 3.3 保存数据 结果: 以上がクローラー + 視覚化 | Python Zhihu ホットリスト/Weibo ホット検索シーケンス チャート (パート 1)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。import json
import time
import requests
import schedule
import pandas as pd
from fake_useragent import UserAgent
ログイン後にコピーhttps://www.zhihu.com/hot
ログイン後にコピーhttps://api.zhihu.com/topstory/hot-list?limit=10&reverse_order=0
ログイン後にコピー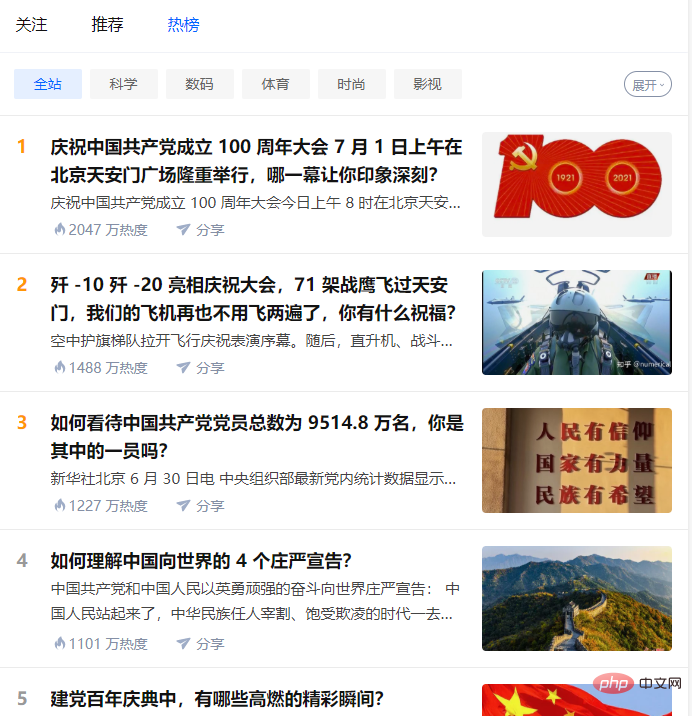
def getzhihudata(url, headers):
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
datas = json.loads(r.text)['data']
allinfo = []
time_mow = time.strftime("%Y-%m-%d %H:%M", time.localtime())
print(time_mow)
for indx,item in enumerate(datas):
title = item['target']['title']
heat = item['detail_text'].split(' ')[0]
answer_count = item['target']['answer_count']
follower_count = item['target']['follower_count']
href = item['target']['url']
info = [time_mow, indx+1, title, heat, answer_count, follower_count, href]
allinfo.append(info)
# 仅首次加表头
global csv_header
df = pd.DataFrame(allinfo,columns=['时间','排名','标题','热度(万)','回答数','关注数','链接'])
print(df.head())ログイン後にコピー# 每1分钟执行一次爬取任务:
schedule.every(1).minutes.do(getzhihudata,zhihu_url,headers)
while True:
schedule.run_pending()
time.sleep(1)ログイン後にコピー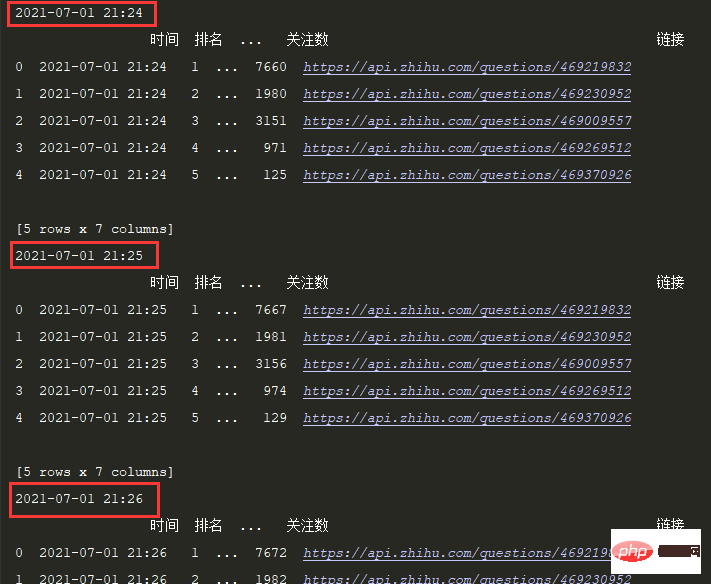
df.to_csv('zhuhu_hot_datas.csv', mode='a+', index=False, header=csv_header)
csv_header = False
ログイン後にコピー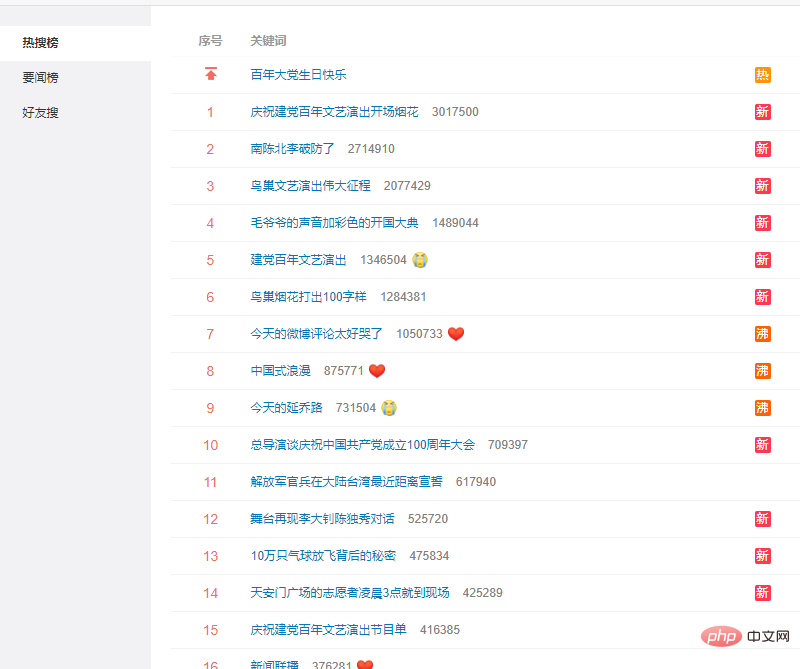
タグ にあります。
def getweibodata():
url = 'https://s.weibo.com/top/summary'
r = requests.get(url, timeout=10)
r.encoding = r.apparent_encoding
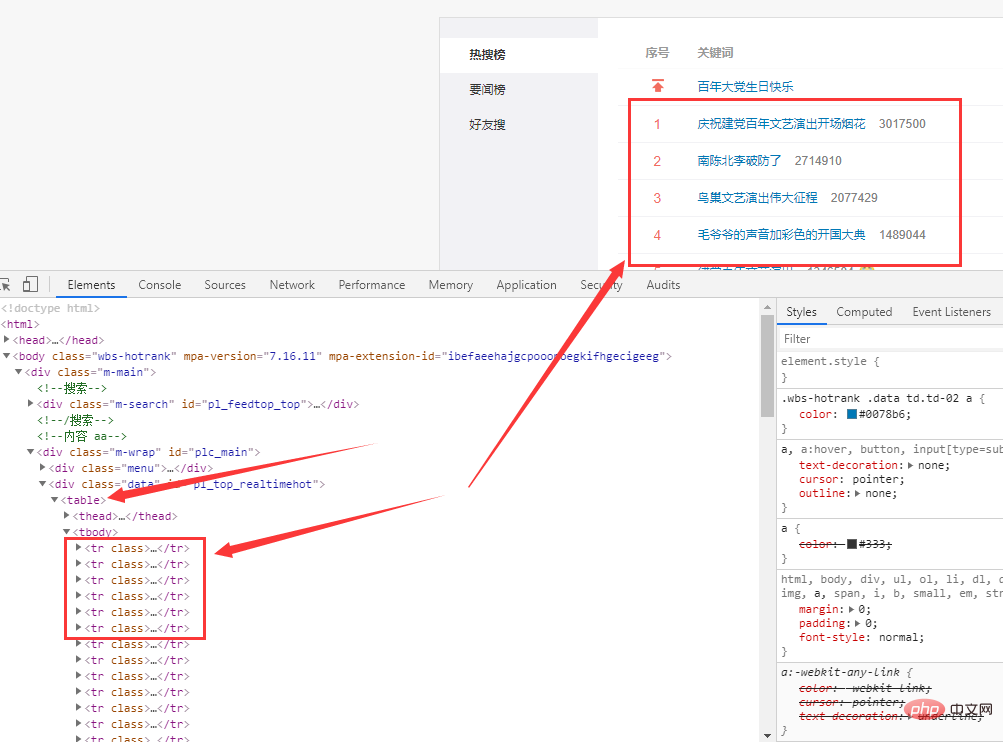
df = pd.read_html(r.text)[0]
df = df.loc[1:,['序号', '关键词']]
df = df[~df['序号'].isin(['•'])]
time_mow = time.strftime("%Y-%m-%d %H:%M", time.localtime())
print(time_mow)
df['时间'] = [time_mow] * df.shape[0]
df['排名'] = df['序号'].apply(int)
df['标题'] = df['关键词'].str.split(' ', expand=True)[0]
df['热度'] = df['关键词'].str.split(' ', expand=True)[1]
df = df[['时间','排名','标题','热度']]
print(df.head())ログイン後にコピー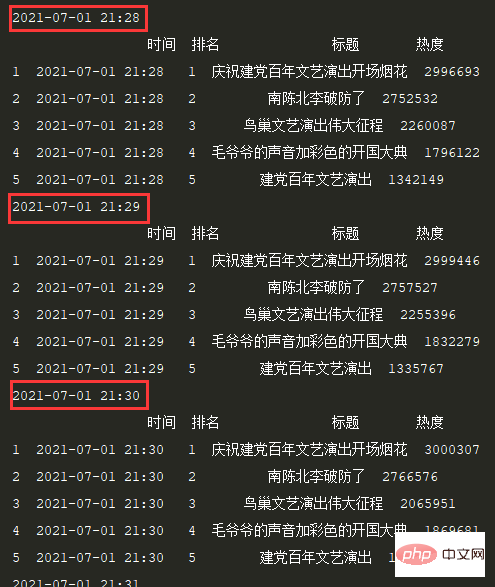
df.to_csv('weibo_hot_datas.csv', mode='a+', index=False, header=csv_header)
ログイン後にコピー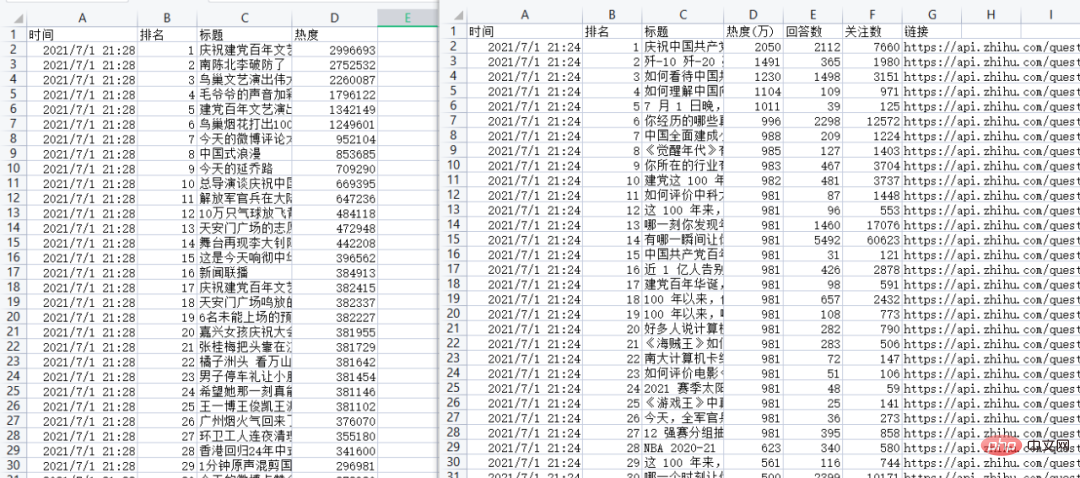 関連ラベル:
ソース:Python当打之年
前の記事:クローラー + 視覚化 | Python Zhihu ホットリスト/Weibo ホット検索シーケンス チャート (パート 2)
次の記事:ヒント | Python は PDF 請求書をバッチで自動的に抽出して整理します
このウェブサイトの声明
この記事の内容はネチズンが自主的に寄稿したものであり、著作権は原著者に帰属します。このサイトは、それに相当する法的責任を負いません。盗作または侵害の疑いのあるコンテンツを見つけた場合は、admin@php.cn までご連絡ください。
著者別の最新記事
関連ラベル:
ソース:Python当打之年
前の記事:クローラー + 視覚化 | Python Zhihu ホットリスト/Weibo ホット検索シーケンス チャート (パート 2)
次の記事:ヒント | Python は PDF 請求書をバッチで自動的に抽出して整理します
このウェブサイトの声明
この記事の内容はネチズンが自主的に寄稿したものであり、著作権は原著者に帰属します。このサイトは、それに相当する法的責任を負いません。盗作または侵害の疑いのあるコンテンツを見つけた場合は、admin@php.cn までご連絡ください。
著者別の最新記事
2023-08-15 15:07:54
2023-08-15 15:03:09
2023-08-15 15:01:56
2023-08-15 14:56:46
2023-08-15 14:55:25
2023-08-15 14:53:11
2023-08-15 14:48:06
2023-08-15 14:42:31
2023-08-15 14:41:13
2023-08-15 14:39:02
最新の問題
Python/MySQL は整数データを正しく保持できません
ここではコードは必要ありません。ゲームを作成していてスコアを保存する必要があるため、非常に長い数値を保存したいと考えています。ただし、テストしてスコアを 25000000000 に...
から 2024-04-04 19:09:44
0
1
367
Seleniumを使用してクラス内でURLをクリックして定義したい
今日はもう一つヒントが必要です。私は Python/Selenium コードを構築しようとしていますが、そのアイデアは www.thewebsiteIwantoclickon をク...
から 2024-04-04 14:14:44
0
1
3492
最初の X 行を保持し、テーブルの行を削除する方法
MySQLincident_archive に数百万のレコードを含む大きなテーブルがあります。作成した列で行をソートし、最初の X 行を保持し、残りを削除したいのですが、最も効率的...
から 2024-04-01 18:32:54
0
1
347
関連トピック
詳細>
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



