

未来の交差点に立って、歴史の失われた道を振り返ると興味深いことがよくあります。なぜなら、何かが事前に起こっていたのに、別のことは起こらなかったかのように、私たちはうっかりクレイジーな考えを抱いてしまうからです。 。 何が起こるか?オーストリア=ハンガリー帝国の王位継承者であるフェルディナンド大公とその妻が、情熱的なセルビア人青年プリンツィプに射殺されなかったらどうなっていたか、そして邱老道がもし射殺していたらどうなっていたかのように。牛家村を通らなかったのか?
2007 年末、タオバオは「カラフル ストーン」と呼ばれる社内再構築プロジェクトを立ち上げました。その後、淘宝網のサービス化、流通の自主研究、インターネットミドルウェアシステムの始まりとなり、同年に淘宝網サービス登録センターConfigServerが誕生しました。
2008 年頃、元インターネット大手の Yahoo は、Google が発表した Chubby と Paxos に関する論文を参照したビッグデータ分散調整製品 ZooKeeper を徐々に公に公開し始めました。
2010 年 11 月、ZooKeeper は Apache Hadoop のサブプロジェクトから Apache のトップレベル プロジェクトに発展し、ZooKeeper が産業グレードの成熟した安定した製品になったことを正式に発表しました。
2011 年、アリババは Dubbo をオープンソース化しました。オープンソースをより良くするために、アリババの内部システムとの関係を切り離す必要がありました。Dubbo は登録センターとしてオープンソースの ZooKeeper をサポートしました。その後、中国でこのような状況下、Dubbo ZooKeeper の典型的なサービス指向ソリューションにより、ZooKeeper は登録センターとして有名になりました。
2015 年のダブル 11、ConfigServer サービスの開始からほぼ 8 年が経過、アリババ社内の「サービス規模」は数百万を超え、「数千マイル離れた」IDC ディザスタ リカバリ テクノロジーの推進もAlibaba は、ConfigServer 2.0 から ConfigServer 3.0 への内部アーキテクチャのアップグレードを開始しました。
時は 2018 年に向かって進んでいます。10 年の節目に立って、刻々と変化する新しいテクノロジーの概念を追いかける際に、少しペースを落としてサービス ディスカバリの分野を詳しく見てみたいと考えている人がどれだけいるでしょうか。人々が考えたことがある質問、または私が考えたことがある質問:
歴史を振り返ると、時々神話もありますが、サービス検出の文脈において、ZooKeeper が HSF 登録センターの ConfigServer よりも早く誕生していたらどうなっていただろうか?
最初に ZooKeeper を使用し、次に Alibaba のサービス指向のシナリオとニーズに適応するために ZooKeeper を必死に変換してパッチを適用するという回り道をするでしょうか?
しかし、今日の人々と先人の肩の上に立つと、サービス ディスカバリの分野において、ZooKeeper は単純に最良の選択ではないということを今日ほどしっかりと認識したことはありません。長年私たちと一緒に活動してきた Eureka と同じように、この記事「Eureka! Why You Shouldn't Use ZooKeeper for Service Discovery」では、サービス ディスカバリに ZooKeeper を使用すべきではない理由をしっかりと説明しています。
私のやり方は一人ではありません。 登録センターの要件分析と主要な設計上の考慮事項 次に、サービス発見のための需要分析に戻り、主要なシナリオにおけるアリババの実践と組み合わせて、1 つずつ分析し、一緒に議論しましょう。 ZooKeeper が登録センター ソリューションとして最適ではない理由。 登録センターは CP システムですか? 読者は CAP 理論と BASE 理論に精通していると思いますが、これらは分散システムと BASE の構築を導く重要な原則の 1 つとなっています。インターネット アプリケーション: ここでは、理論の詳細には触れずに、登録センターのデータ一貫性と可用性要件の分析に直接進みます:service- を使用したクエリ関数Si = F(サービス名)とみなすことができます。 nameをクエリ パラメータとして指定します。service-name対応するサービスの利用可能なendpoints (ip:port)が戻り値です。
注: 以下のテキストでは、サービスを svc と省略します。
最初に重要なデータを見てみましょうエンドポイント (ip:ポート)不整合の影響、つまり、CAP の C を満たさない場合の結果:
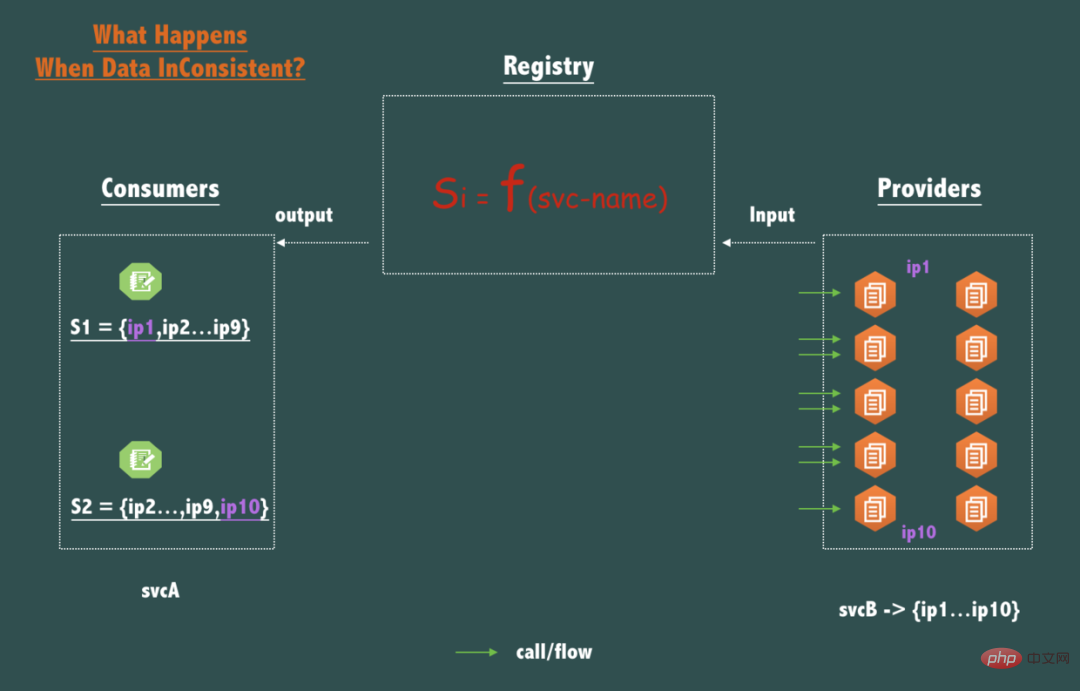
上の図に示すように、svcB が 10 個のノード (レプリカ/レプリカ) をデプロイする場合、同じサービス名 svcB の場合、呼び出し元 svcA の 2 つのノードの 2 つのクエリは一貫性のないデータを返します。例: S1 = {ip1,ip2,ip3...,ip9}、S2 = {ip2,ip3,....ip10} では、この不一致の影響は何でしょうか?
svcB の各ノードのトラフィックが少し不均衡になることに気づいたと思います。
他の 8 ノード {ip2...ip9} と比較すると、ip1 と ip10 のリクエスト トラフィックは少し小さいですが、分散システムでは、ピアツーピアが展開されている場合であっても、トラフィックが少ないことは明らかです。サービス、リクエストが到着する時間、ハードウェア ステータス、オペレーティング システムのスケジュール、仮想マシン GC など、どの時点でも、ピアツーピアで展開されたノードのステータスを完全に一貫させることはできず、一貫性がない場合は、登録センターが SLA で約束された時間内にある限り、データが 1 秒以内 (たとえば、1 秒以内) に一貫した状態 (つまり、結果整合性を満たす) に収束すると、トラフィックはすぐに不安定になる傾向があります。したがって、登録センターは結果的に整合性のあるモデルを使用して設計されており、実稼働環境では完全に許容されます。
次に、ネットワーク パーティションの場合の登録を見てみましょう。センターが利用できない場合のサービス コールへの影響は、CAP の A が満たされていない場合の影響です。
以下に示すような、典型的な ZooKeeper の 3 マシン ルームのディザスタ リカバリ 5 ノード展開構造 (つまり、2-2-1 構造) を考えてみましょう。コンピューター ルームは 3 ネットワーク パーティションが発生すると、コンピューター ルーム 3 はネットワーク上のアイランドになります。ZooKeeper サービス全体は利用可能ですが、リーダーに接続できないため、ノード ZK5 は書き込み可能ではないことがわかります。
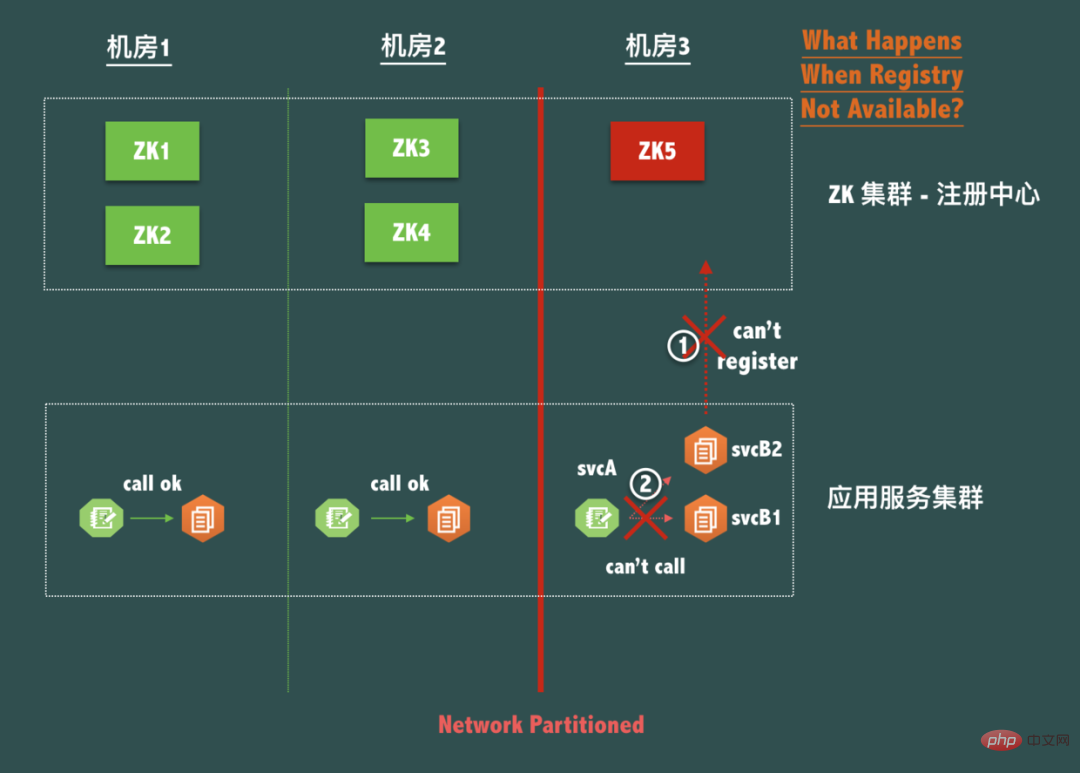
現在、スプリットブレイン(P)下でデータの整合性(C)を確保するために登録センター自体が可用性を放棄しているため、同じコンピュータルーム内のサービスを呼び出すことができません。これは絶対に許されません。実際には、登録センターは、いかなる理由であってもサービス間の接続を破壊することはできないと言えます。これは、登録センターの設計が従うべき鉄則です。登録センター クライアントの災害復旧については、後ほど引き続き説明します。
同時に、この場合のデータの不整合について考えてみましょう。計算機室 1、2、3 が孤立した場合、各計算機室の svcA がこの計算機室の svcB のみを取得するとします。 IP リスト、つまり各コンピュータ室の svcB の IP リスト データが完全に一致していません。影響は何ですか?
実際には大きな影響はありませんが、この場合、すべての電話は同じコンピュータ室から行われます。この登録センター内のデータの不一致 アプリケーションが同じコンピュータ ルームを積極的に呼び出せるようにすることで、サービス コール リンク RT の効果を最適化します。
上記の説明を通じて、CAP のトレードオフでは、データの強い一貫性よりも登録センターの可用性の方が価値があることがわかります。そのため、全体の設計はむしろ AP に偏るべきです。 CP よりもデータの不一致は許容範囲であり、P の下で A を破棄することは、登録センターが独自の理由でサービス自体の接続を破壊できないという原則に完全に違反します。
あなたの会社の「マイクロサービス」の規模はどれくらいですか?何百ものマイクロサービス?何百ものノードを導入しましたか? 3年後はどうでしょうか?インターネットは奇跡が起こる場所です。もしかしたら、あなたの「サービス」が一夜にして有名になり、トラフィックが 2 倍になり、規模が 2 倍になるかもしれません。
データセンターのサービス規模が一定数(サービス規模 = F{サービスパブ番号,サービスサブ番号})を超えると、登録センターであるZooKeeperはすぐに下の写真のロバのように圧倒されてしまいます

実際、ZooKeeper が適切な場所、つまり粗粒度の分散ロックおよび分散調整シナリオで使用される場合、ZooKeeper がサポートできる TPS と接続数は次のようになります。これらのシナリオでは、ZooKeeper のスケーラビリティと容量に対する強い要求がないためです。
しかし、サービスの検出と正常性の監視のシナリオでは、サービスの規模が大きくなるにつれて、アプリケーションが頻繁にリリースされるときのサービス登録によって引き起こされる書き込みリクエストであっても、ミリ秒レベルのサービスの正常性ステータスが更新される書き込みリクエストであっても、書き込みリクエストが発生する可能性があります。データ センター全体のすべてのマシンまたはコンテナは、登録センターへの長い接続を持っています。ZooKeeper は、長い接続によってもたらされる接続圧力にすぐに対処できなくなります。ただし、ZooKeeper の記述はスケーラブルではなく、ノードを追加しても解決できません。水平方向スケーラビリティの問題。
ZooKeeperをベースにサービス規模の拡大という課題を解決したい場合、事業を整理して事業ドメインを縦割りにし、複数のZooKeeperに分割するという現実的な方法が考えられます。しかし、総合サービスを提供するプラットフォーム組織集団として、サービス力不足から技術バトンに応じた事業分割・運営が本当に可能なのか?
そして、これは、登録センター自体 (容量不足) がサービスの接続を破壊するという事実に違反します。簡単な例を挙げると、1 つの検索ビジネス、1 つの地図ビジネス、1 つの大手エンターテイメント ビジネス、1 つのゲーム ビジネスでは、それらのサービスは相互に排他的ですか?おそらく今日はそうだと思いますが、明日はどうなるでしょうか、1 年後、10 年後はどうなるでしょうか?将来、奇妙なビジネス イノベーションを生み出すためにいくつかのビジネス ドメインが開かれることを誰が知っていますか?基本サービスとして、登録センターは将来を予測することができず、将来の固有の接続に対するビジネス サービスの要求を妨げることはできません。
必要なものと不要なもの。
ZooKeeper の ZAB プロトコルは、書き込みリクエストごとに各 ZooKeeper ノードにトランザクション ログを書き込み続け、同時にメモリ データ (スナップショット) をディスクに定期的にミラーリングして、データが確実に保存されることを私たちは知っています。一貫性と耐久性、およびクラッシュ後のデータ回復は非常に優れた機能ですが、サービス検出シナリオでは、コア データ、つまり健全なサービスのリアルタイム アドレス リストが本当に必要であることを確認する必要があります。データは永続的ですか?
このデータの場合、答えは「ノー」です。
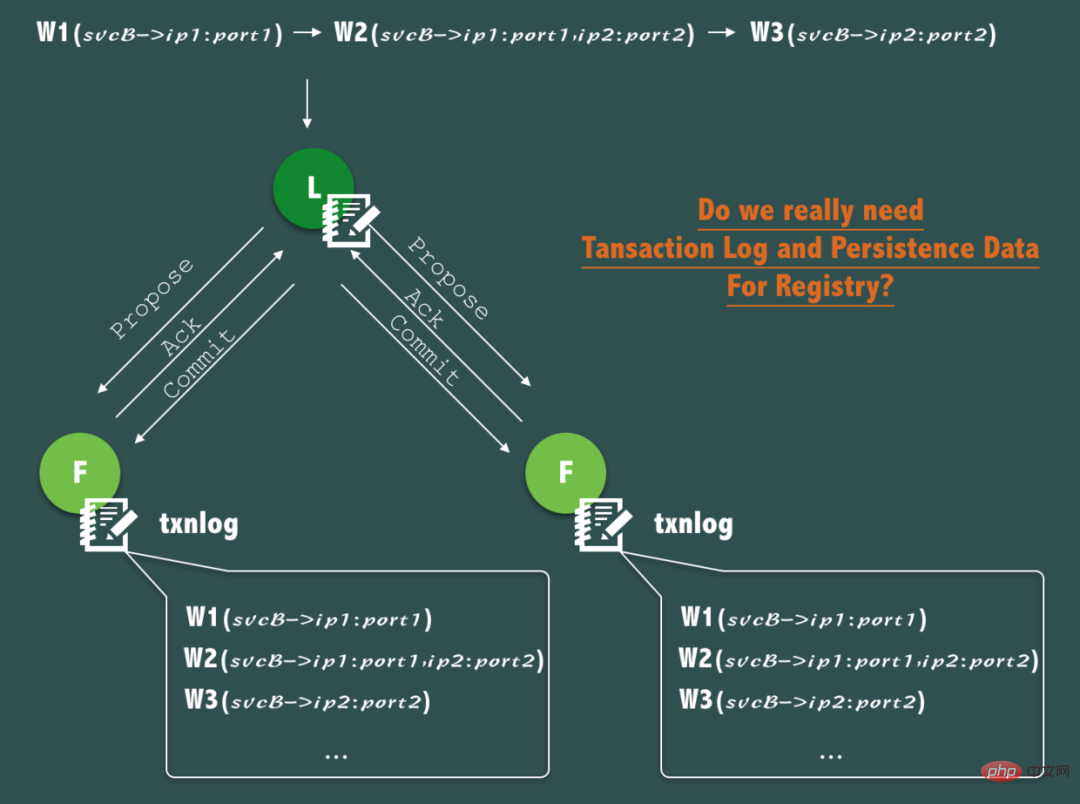
上図に示すように、svcB で登録サービス (ip1)、2 ノードへの拡張 (ip1、ip2)、ダウンタイムによる縮小 (ip1 ダウンタイム) が発生した場合) )、このプロセス中に、ZooKeeper への 3 つの書き込み操作が発生しました。
しかし、注意深く分析すると、トランザクション ログを通じて、この変更プロセスを永続的かつ継続的に記録することは、実際にはほとんど重要ではないことがわかります。これは、サービス検出では、サービス呼び出しの開始者が、サービス呼び出しのリアルタイム アドレス リストをより重視するためです。呼び出すサービスとリアルタイムの健全性ステータス 呼び出しが行われるたびに、呼び出されるサービスの履歴サービス アドレス リストや過去の健全性ステータスは考慮されません。
しかし、なぜそれが必要なのでしょうか? 実稼働環境で利用可能な完全な登録センターには、サービスのリアルタイムのアドレスリストとリアルタイムの正常性状態に加えて、サービスのメタデータ情報も保存されるためです。バージョン、グループ、データセンター、重み、認証ポリシー情報、サービスラベルなどのサービスのメタ情報など。これらのデータは永続的に保存する必要があり、登録センターはこれらのメタ情報を取得する機能を提供する必要があります。
ZooKeeper をサービス登録センターとして使用する場合、サービスのヘルス チェックでは、多くの場合、ZooKeeper のセッション アクティブ トラック メカニズムと、エフェメラル ZNode と組み合わせたメカニズムが使用されます。サービスのヘルス モニタリングを組み合わせるには、ZooKeeper のセッションのヘルス モニタリング、または TCP ロング リンク アクティビティ検出にバインドされます。
これは、多くの場合、致命的な問題を引き起こす可能性もあります。ZK とサービス プロバイダー マシン間の TCP ロング リンク アクティビティ検出が正常であれば、サービスは正常ですか?答えはもちろんノーです!登録センターは、より充実した健全性監視ソリューションを提供する必要があります。また、サービスが健全であるかどうかのロジックは、画一的な TCP アクティビティ テストにするのではなく、サービス プロバイダーが定義できるようにオープンにする必要があります。
健全性検出の基本設計原則の 1 つは、サービス自体の真の健全性状態を可能な限り忠実にフィードバックすることです。そうでない場合、サービス呼び出し元が信じない健全性状態の判定結果は、健全性検出がないことよりも悪いものになります。
前述したように、実際には、登録センターは何らかの理由でサービス間の接続を破壊することはできません。可用性の条件について、重要な質問があります。登録センター (レジストリ) 自体が完全にダウンした場合、svcB を呼び出す svcA のリンクは影響を受けますか?
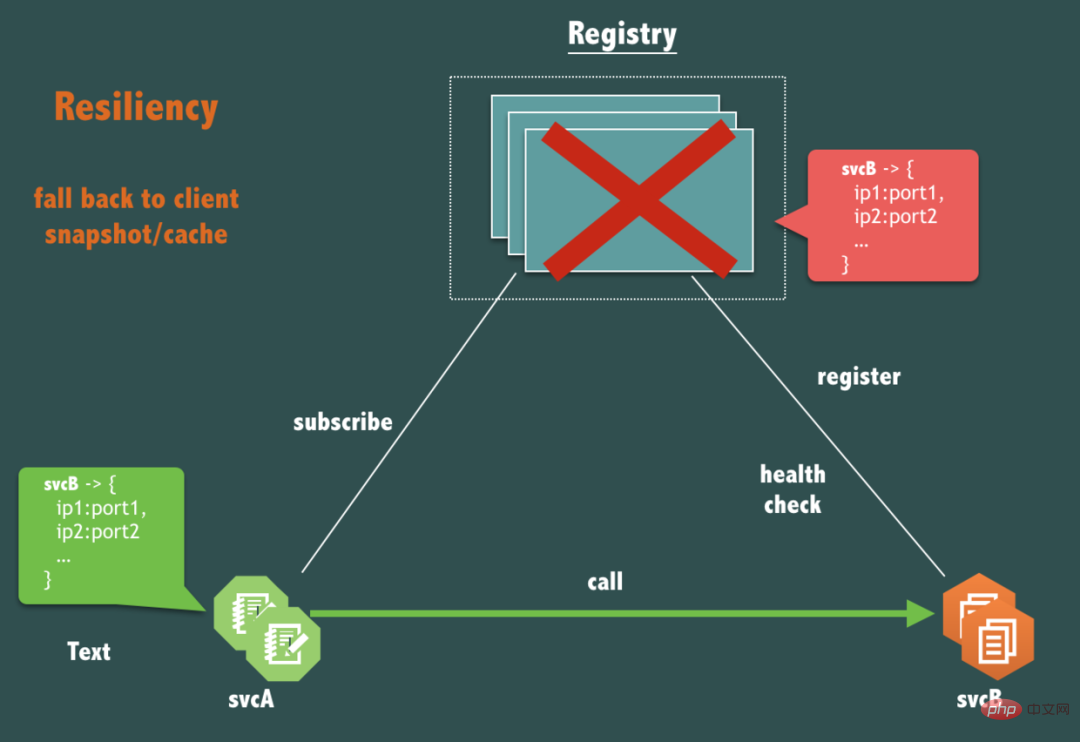
はい、影響はありません。
サービス コール (要求応答フロー) リンクは、登録センターに弱く依存する必要があります。サービスのリリース、マシンのオンラインとオフライン、サービスの拡張と縮小などに必要な場合にのみ登録センターに依存する必要があります。
これには、登録センターが提供するクライアントを慎重に設計する必要があります。クライアントには、クライアント キャッシュ データ メカニズム (クライアント スナップショットと呼びます) の設計など、登録センター サービスが完全に利用できなくなった場合に備えた災害復旧手段が必要です。 )が有効な方法です。さらに、登録センターのヘルスチェックメカニズムは、このような状況で空になるような状況が発生しないように慎重に設計する必要があります。
ZooKeeper のネイティブ クライアントにはこの機能がないため、ZooKeeper を使用して登録センターを実装する場合は、すべての ZooKeeper ノードが強制終了された場合に、プロダクション内のすべてのサービス コール リンクが実行できるかどうかを自問する必要があります。何らかの形で影響を受けていますか?そして、この点に関して定期的に失敗訓練を行う必要があります。
ZooKeeper は非常にシンプルな製品に見えますが、本番環境で大規模に使用したり、使いこなすのは当然のことではありません。 ZooKeeper を運用環境に導入することに決めた場合は、いつでも ZooKeeper の技術専門家に支援を求められるように準備しておいたほうがよいでしょう。最も一般的な症状は 2 つの側面にあります。マスターするのが難しいクライアント/セッション ステート マシン
ZooKeeper を Alibaba の内部アプリケーションに接続する場合、「ZooKeeper アプリケーションを接続する際に知っておくべきこと」WIKI があります。例外処理については次の説明があります:
ZooKeeper を使用する際にアプリケーション開発者が最も明確に知っておく必要があることを選択したい場合は?したがって、これまでのサポートの経験に基づくと、それは例外処理である必要があります。
幸いなことにすべて (ホスト、ディスク、ネットワークなど) が適切に動作している場合、アプリケーションと ZooKeeper も正常に動作する可能性がありますが、残念なことに、私たちは一日中あらゆる種類の事故に直面することになります。これはマーフィーの例に続きます。法則によれば、予期せぬ悪いことは、常に最も心配しているときに起こります。
したがって、一部のシナリオで ZooKeeper で発生する可能性のある例外とエラーを注意深く理解し、これらの例外とエラーを正しく理解し、アプリケーションがこれらの状況を正しく処理する方法を理解してください。
簡単に言えば、これは同じ ZooKeeper セッション内で回復できる例外 (回復可能) ですが、アプリケーション開発 オペレータは、アプリケーションを正しい状態に復元する責任があります。
この例外には、アプリケーション マシンと ZooKeeper ノード間のネットワークの中断、ZooKeeper ノードのダウン、サーバーのフル GC 時間が長すぎる、アプリケーション プロセスがハングしてアプリケーションプロセスがフルになった場合 GC時間が長すぎる場合でも回復可能です。
この例外を理解するには、以下に示すような分散アプリケーションの典型的な問題を理解する必要があります。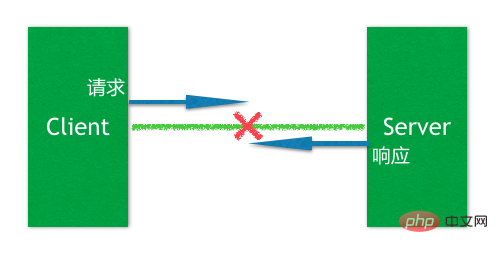
典型的なクライアント要求とサーバー応答では、接続が長いとき、サーバー側は、このリクエストを受け取りましたか?加工されているのでしょうか?これを判断できないため、クライアントがサーバーに再接続するときに、リクエストを再試行するかどうか (Retry) について疑問符が付きます。
したがって、接続切断イベントを処理するとき、アプリケーション開発者は、中断に近いリクエストが何であるか (これは判断が難しい場合が多い)、リクエストが冪等であるかどうか、およびサーバー側のビジネス リクエストのサービス処理を把握する必要があります。 、「1 回だけ処理する」、「最大 1 回処理する」、「少なくとも 1 回処理する」のセマンティクスには選択と期待が必要です。
たとえば、アプリケーションが ConnectionLossException を受け取り、前のリクエストが Create 操作だった場合、アプリケーションがこの例外をキャッチした場合、アプリケーションで考えられる回復ロジックは、前のリクエストによってノードが作成されたかどうかを判断することです。存在します。存在する場合は、再度作成しないでください。存在しない場合は、作成します。
別の例として、アプリケーションが存在監視を使用して存在しないノードの作成イベントを監視する場合、ConnectionLossException が発生している間に、この中断期間中に他のクライアント プロセスがノードに存在する可能性があるという状況が発生する可能性があります。が作成および削除されたため、現在のアプリケーションでは、問題のノードの作成イベントが欠落しています。この欠落がアプリケーションに与える影響は何ですか?それは許容できるものですか、それとも許容できないものですか?アプリケーション開発者は、ビジネス セマンティクスに従ってアプリケーションを評価し、処理する必要があります。
セッション タイムアウトは回復不可能な例外です。これは、アプリケーションがこの例外をキャッチすると、アプリケーションは復元できないことを意味します同じセッション内のアプリケーションの状態を確認するには、新しいセッションを再確立する必要があります。古いセッションに関連付けられた一時ノードの有効期限が切れている可能性もあり、所有しているロックの有効期限が切れている可能性もあります。 ...
ZooKeeper をサービス検出に使用しようとする過程で、アリババの友人たちがイントラネット テクノロジ フォーラムで共有した経験をまとめました

記事で適切に言及されています:
... コーディングのプロセス中に、考えられる多くの落とし穴が発見されました。 , クラスター管理に初めて zk を使用する人の 80% 以上が落とし穴に陥ります。一部の落とし穴はより隠蔽されており、ネットワークの問題または異常なシナリオでのみ現れます。暴露されるまでには長い時間がかかる可能性があります...
アリババは ZooKeeper をまったく使用していないのでしょうか?あまり。
Alibaba の技術システムに精通している人なら、Alibaba が実際に中国最大の ZooKeeper クラスターを維持しており、その全体規模は約 1,000 の ZooKeeper サービス ノードであることを知っています。
同時に、Alibaba ミドルウェアは ZooKeeper のコード ブランチも維持しており、TaoKeeper は大規模な生産を指向しており、可用性が高く、監視と操作が容易です。過去10年間の様々な事業内容や生産実績を踏まえ、ZooKeeperの実績を踏まえてZooKeeperを評価する言葉を一言で言うなら、ZooKeeperは「ビッグデータコーディネートの王様」と言えるでしょう!
これは、高 TPS サポートを必要としない、粗粒度の分散ロック、分散マスター選択、マスター/スレーブの高可用性スイッチングなどのシナリオで、かけがえのない役割を果たします。ビッグデータやオフラインタスクなどの関連ビジネス分野では、ビッグデータの分野ではデータセットをセグメント化することが重要であり、ほとんどの場合、これらのデータセットは複数のプロセスによって並行して処理されます。しかし、これらのタスクとプロセスを統合して調整する必要がある点が常にいくつかあり、ここで ZooKeeper が大きな役割を果たします。
ただし、トランザクション シナリオのトランザクション リンクでは、主要なビジネス データ アクセス、大規模なサービス検出、大規模なヘルス モニタリングなどに当然の欠点があります。ZooKeeper の導入を避けるために最善を尽くす必要があります。 Alibaba の実稼働環境では、アプリケーションは ZooKeeper の使用を申請する際に、シナリオ、容量、および SLA 要件を厳密に評価する必要があります。
つまり、ZooKeeper を使用することはできますが、ビッグ データには左、トランザクションには右、分散調整には左、サービス検出には右に移動してください。
ここまで読んでいただき、ありがとうございました。この時点で、私たちが ZooKeeper を完全に否定するためにこの記事を書いているわけではなく、アリババの見解に基づいているだけであることがご理解いただけたと思います。過去 10 年間の経験を基に、大規模なサービス化の実践において、サービス ディスカバリおよび登録センターの設計と使用に関する経験と教訓を要約し、より効果的な利用方法について業界に洞察を提供したいと考えています。 ZooKeeper と独自のサービス登録センターをより適切に設計する方法。刺激的で役に立ちます。最後に、すべての道はローマに通ず、あなたの登録センターがローマに直接誕生することを心から願っています。
以上がAlibaba はなぜサービス検出に ZooKeeper を使用しないのですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。































![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



