
インタビュアー: Linux を操作したことがありますか?
私: はい
インタビュアー: メモリ使用量を確認するにはどのコマンドを使用すればよいですか?
私: free または top
インタビュアー: では、無料コマンド
を使って確認できる情報を教えてください。 私: すると、下図のように、メモリとキャッシュの使用状況がわかります。
#合計メモリ合計
 ##インタビュアー: それでは、使用済みキャッシュ (buff/cache) をクリアする方法がわかりました。 )
##インタビュアー: それでは、使用済みキャッシュ (buff/cache) をクリアする方法がわかりました。 )
私: em... わかりません
インタビュアー: sync; echo 3 > /proc/sys/vm/ drop_caches バフ/キャッシュをクリアできます。このコマンドをオンラインで実行できるかどうか教えていただけますか?

##私: (ポイントを送信,大喜び) メリットは非常に大きいです。キャッシュをクリアすると、使用可能なメモリ領域が増えます。PC 上の xx Guardian の小さなロケットのように、ワンクリックで大量のメモリが解放されます。
インタビュアー: em….、戻って通知を待ちます
インタビュアー: Change theトピックを決めて話しましょう 参加についてのあなたの理解
私: わかりました (また間違って答えたら終わりです、機会を捉えてください)
が含まれます。
内部結合内部結合
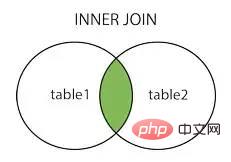
##左結合左結合
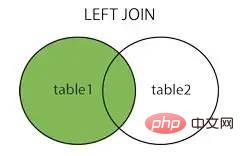
##右結合右結合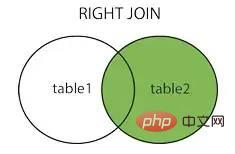
##完全結合完全結合

#画像ソース: https://www.cnblogs.com/reaptomorrow-flydream/p/8145610.html
インタビュアー: プロジェクト開発中に結合ステートメントを使用する必要がある場合、最適化してパフォーマンスを向上させる方法?
私: 意見が分かれましたこの場合、データサイズが小さい場合とデータサイズが大きい場合があります。
インタビュアー: Then?
私: For
1. データ サイズが小さいため、すべてが
#インデックスを追加することで結合ステートメントの実行速度を最適化できます
冗長な情報を使用して結合の数を減らすことができます
##テーブル接続の数も同様に減らしますできる限り、1 つの SQL ステートメントに対するテーブル接続の数は 5 回以内です。
インタビュアー:
join ステートメントは、相対的にパフォーマンスを消費しますよね?私:
はいインタビュアー:
なぜですか?###私: 結合ステートメントの実行時に比較プロセスが必要です
インタビュアー: はい
私: 2 つのテーブルを 1 つずつ比較するステートメントは比較的遅いため、MySQL を使用して InnoDB エンジンを使用して、2 つのテーブルのデータをメモリ ブロックに順番に読み取ることができます。たとえば、次のステートメントを使用すると、関連するメモリ領域を確実に見つけることができます。 show variables like '%buffer%'
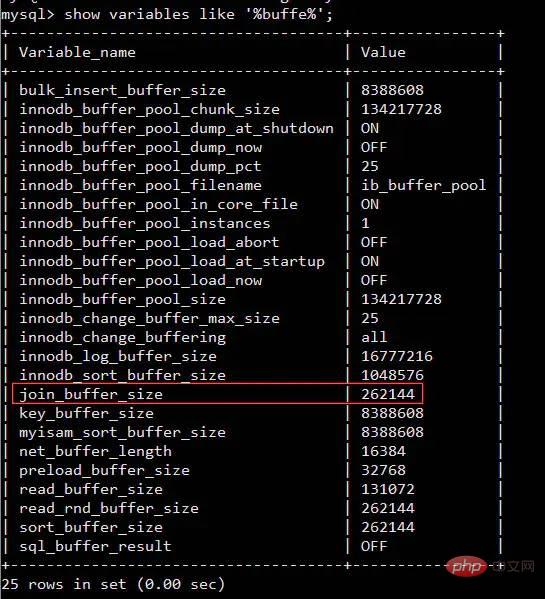
図に示すように、 join_buffer_size のサイズが join ステートメントの実行パフォーマンスに影響することを示します
インタビュアー: 他には何がありますか?
#私: どんなプロジェクトも最終的にはオンラインになります。データの生成は避けられず、データの規模が小さすぎることはできません
インタビュアー: はいこのように
私:データベース内のほとんどのデータは、最終的にはハードディスクに保存され、ファイルの形式で保存されます。
MySQL の InnoDB エンジンを例に挙げます
InnoDB は基本的な IO ユニットとしてページを使用し、各ページのサイズは 16KB
#InnoDB は、データを保存するためにテーブルごとに .ibd ファイルを作成します
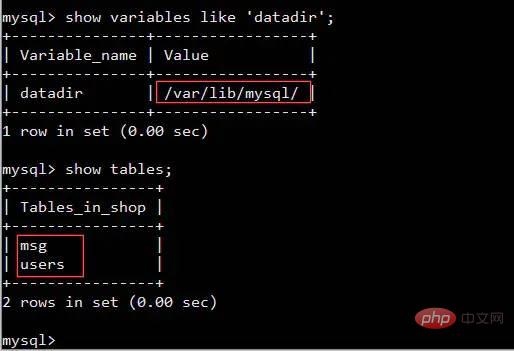
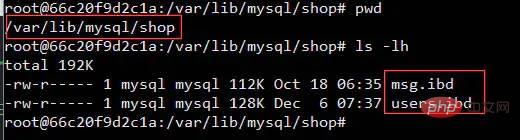
私: これは、インデックスを使用することもできますが、接続するテーブルと同じ数のファイルを読み取る必要があることを意味します。ただし、ハードディスクのヘッドを頻繁に動かすことは避けられません。
インタビュアー:つまり、ヘッドを頻繁に動かすとパフォーマンスに影響が出ますよね。
Me:はい、現在のオープンソース フレームワークは、hbase や kafka などのシーケンシャルな読み取りと書き込みによってパフォーマンスが大幅に向上したと言いたがりませんか
インタビュアー: そうです、それでは Linux がこれを最適化していると思いますか? ヒント、無料のコマンドをもう一度実行して確認してください
私:なぜキャッシュが 1.2G を超えるのか不思議です


画像ソース: https://www.linuxatemyram.com/
インタビュアー:
buff/cache が何に保存されているかについて考えたことはありますか?
バフ/キャッシュがこれほど多くのメモリを占有するのに、使用可能なメモリはあるのにまだ 1.1G あるのはなぜですか?
2 つのコマンドを使用して buff/cache によって占有されているメモリをクリアできるのに、プロセスを終了することによってのみ使用済みメモリを解放できるのはなぜですか?
私: 記憶を解放しますbuff/cache が何気なく占有しているということは、それが重要ではないことを意味しており、それをクリアしてもシステムの動作には影響しません
インタビュアー: 完全に真実ではありません
私: そうですか? 「CSAPP」(コンピュータシステムの詳細な理解)の文を思い出しました。
メモリ階層の本質は、ストレージデバイスの各層が下位層のデバイスのキャッシュであるということです
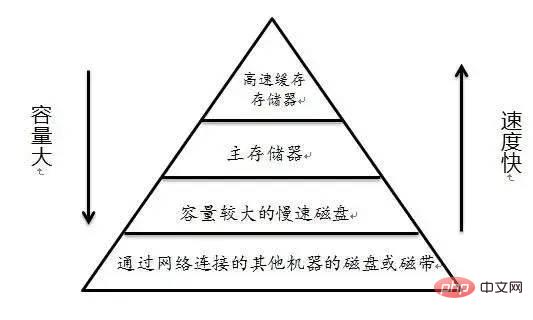
関連情報: http:/ /tldp.org /LDP/sag/html/buffer-cache.html
インタビュアー: これで採点の質問に答える方法がわかりました
#私:私….
 ##参加アルゴリズム
##参加アルゴリズム
私:
インデックスがない場合、ネストされたループは終了します。インデックスがある場合は、index を使用してパフォーマンスを向上させることができます.
インタビュアー: join_buffer に戻りますが、join_buffer には何が保存されていると思いますか?
私: スキャン プロセス中に、データベースはテーブルを選択し、それを追加します。返され、他のテーブルと比較される必要があるデータは、join_buffer に置かれます。
インタビュアー: インデックスがある場合、どのように対処しますか?
私: これは比較的簡単です。2 つのテーブルのインデックス ツリーを直接読み取って比較するだけです。それで終わりです。ここでインデックス以外の処理方法を紹介しましょう
ネストされたループ結合
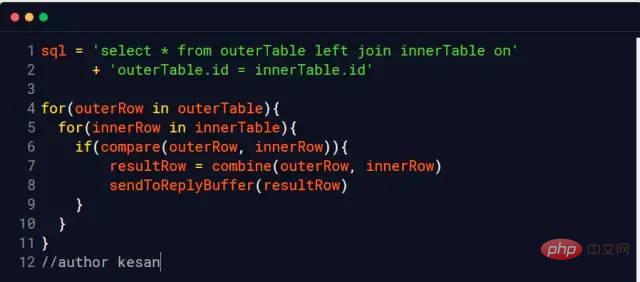
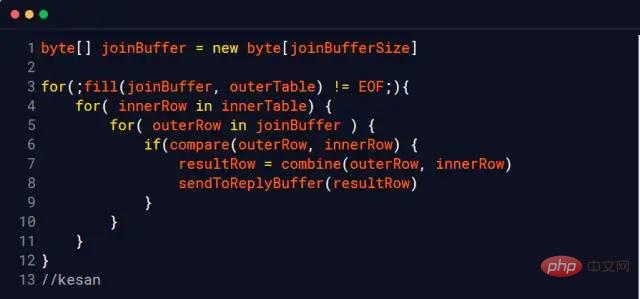 ブロック ブロック、つまり、I/O オーバーヘッドを削減するために毎回データがメモリにフェッチされます
ブロック ブロック、つまり、I/O オーバーヘッドを削減するために毎回データがメモリにフェッチされます
MySQL InnoDB はインデックスを使用できない場合にこのアルゴリズムを使用します
次の 2 つのテーブル t_a と t_b を考慮してください
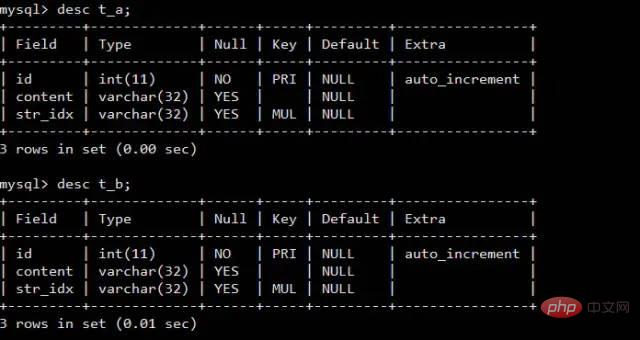
それが不可能な場合インデックスを使用して結合操作を実行すると、InnoDB はブロック ネスト ループ アルゴリズムを自動的に使用します。

学校、データベースの先生 私はデータベース パラダイムを学ぶのが最も好きですが、仕事に就いて初めて、すべてがパフォーマンスに基づいている必要があることを学びました。冗長性が可能であれば、冗長性を使用します。冗長性が不可能な場合は、次の場合に参加してください。結合はパフォーマンスに大きな影響を与えます。 join_buffer_size を増やしてみるか、ソリッド ステート ドライブに変更してください。
「コンピュータ システムを深く理解する」-第 6 章 メモリ階層
「Linux ディスクの実験と楽しみ」の著者キャッシュ" いくつかの例を使用して、ハードディスク キャッシュがプログラムの実行パフォーマンスに及ぼす影響を説明します。
《Linux がラムを食べました》フリー パラメータの説明
Linux でバッファ/ページ キャッシュ (ディスク キャッシュ) をクリアする方法コマンドは記事の冒頭にあります Explain
MySQL の実行方法: MySQL をルートから理解する
ブロック ベスト ループ MariaDB の公式ドキュメントでは、ブロック ネスト ループ アルゴリズムの実装について説明しています
以上がコード仕様では、SQL ステートメントに結合が多すぎないことが要求されるのはなぜですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。











![MySQL クエリ最適化ソリューション [大手メーカーのアーキテクトが教える] [MySQL 入門 | チューニング | インデックス作成] 上級チュートリアル](https://img.php.cn/upload/course/000/000/068/6242a7d5be236814.png)







![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



