

同社は最近、サービスの分離とデータのセグメント化に取り組んでいます。これは、単一のパッケージ テーブル内のデータ量が非常に多すぎるためです。そして今でも1日あたり60Wで成長しています。
私はこれまでにデータベースのサブデータベースとサブテーブルについて学び、いくつかのブログ投稿を読んだことがありますが、漠然とした概念しか知りません。今考えてみると、すべてが漠然としています。
私は午後中ずっとデータベースのサブテーブルを読んだり、たくさんの記事を読んだりして過ごしましたが、ここで要約をします:
パート 1: 実際の Web サイト開発プロセスで直面する問題。
パート 2: セグメンテーションのさまざまな方法、垂直方向と水平方向の違いと適用可能な側面は何ですか。
パート 3: 現在市場に出回っているいくつかのオープンソース製品とテクノロジと、それらの長所と短所。
パート 4: おそらく最も重要なことは、データベースとテーブルを水平方向に分割することが推奨されない理由です。 ?これにより、計画の初期段階で慎重に扱うことができ、セグメンテーションによって引き起こされる問題を回避できます。
用語の説明
ライブラリ: データベース; テーブル: テーブル; サブデータベースおよびサブテーブル: シャーディング
データベース アーキテクチャは進化したばかりです。最初は単一マシンのデータベースを使用するだけで十分でした。その後、より多くのリクエストに直面したとき、複数のスレーブ データベース コピーを使用して、データベースの書き込み操作と読み取り操作を分離しました (スレーバー レプリケーション) は読み取りを担当し、マスター データベース (マスター ) は書き込みを担当し、スレーブ ライブラリはデータの一貫性を保つためにメイン ライブラリから同期してデータを更新します。アーキテクチャ的には、これはデータベースのマスターとスレーブの同期です。スレーブ ライブラリは水平方向に拡張できるため、読み取りリクエストが増えても問題ありません。
しかし、ユーザーの数が増加し、書き込みリクエストがますます増えた場合、どうすればよいでしょうか?マスターを追加しても問題は解決できません。データの一貫性が必要であり、書き込み操作には 2 つのマスター間の同期が必要ですが、これは複製に相当し、より複雑になるからです。
現時点では、シャーディングを使用して書き込み操作を分割する必要があります。
どんな問題も大きすぎたり、小さすぎたりします。ここで直面するデータの量は大きすぎます。 。
単一サーバーの TPS、メモリ、および IO が制限されているためです。
解決策: リクエストを複数のサーバーに分散します。実際、ユーザー リクエストと SQL クエリの実行は本質的に同じであり、どちらもリソースをリクエストしますが、ユーザー リクエストはゲートウェイ、ルーティング、http サーバーなども通過します。 。
単一データベースの処理能力には制限があります;
単一データベースが配置されているサーバー上のディスク容量が不十分です。
単一データベース IO ボトルネックでの操作
解決策: より小さなライブラリに分割します
CRUD が問題です。
インデックス拡張、クエリ タイムアウト
解決策: より小さいデータ セットを含む複数のテーブルに分割します。
一般に、垂直スライスと水平スライスが使用されます。これは、結果セットの説明です。セグメンテーションの方法は物理空間セグメンテーションです。
私たちは直面している問題から出発し、解決していきます。
説明:
まず第一に、ユーザー リクエストの数が多すぎるため、処理するためにマシンを積み上げます (これはこの記事の焦点ではありません)
次に、単一のライブラリは大きすぎます。現時点では、テーブルが多すぎるとデータが多すぎる理由、または 1 つのテーブルにデータが多すぎる理由を確認する必要があります。
多数のテーブルと大量のデータがある場合は、垂直セグメンテーションを使用して、ビジネスに応じて異なるライブラリに分割します。
単一テーブル内のデータ量が大きすぎる場合は、水平セグメンテーションを使用する必要があります。つまり、テーブル内のデータが特定のルールに従って複数のテーブルに分割されるか、複数のデータベース上の複数のテーブルに分割される場合もあります。
データベースとテーブルのパーティショニングの順序は、最初に垂直パーティショニング、次に水平パーティショニングである必要があります。縦割りのほうがシンプルで、現実世界の問題への対処方法とより一貫性があるからです。
つまり、列に基づいて「大きなテーブルを小さなテーブルに分割」します。田畑。一般に、テーブルには多くのフィールドがあり、一般的に使用されないもの、データが大きいもの、長さが長いもの (テキスト タイプのフィールドなど) は「拡張テーブル」に分割されます。これは通常、数百の列を持つ大規模なテーブルを対象としており、クエリ時にデータが多すぎることによって発生する「クロスページ」問題も回避します。
垂直サブライブラリは、ユーザー用のデータベース、製品用のデータベース、注文用のデータベースなど、システム内のさまざまなビジネスを分割することを目的としています。分割後は1つのサーバーではなく複数のサーバーに配置する必要があります。なぜ?ショッピング Web サイトが外部世界にサービスを提供し、ユーザー、商品、注文などの CRUD があると想像してみましょう。分割前はすべてが 1 つのデータベースに集約されていたため、データベースの 単一データベースの処理能力がボトルネック になりました。データベースを縦分割した後も、データベースサーバー上に配置したままでは、ユーザー数が増加するにつれて単一データベースの処理能力がボトルネックとなり、単一サーバーのディスク容量、メモリ、TPSなどが増大します。非常にきつくなります。。したがって、上記の問題を解決し、将来的に単一マシンのリソースの問題に直面しないようにするために、それを複数のサーバーに分割する必要があります。
ガバナンスと 劣化メカニズムに似ており、さまざまなビジネスのデータを管理、保守、監視することもできます。別途、拡張機能などアプリケーション システムのボトルネックとなりやすいのはデータベースであることが多く、データベース自体が ステートフルであるため、Web サーバーやアプリケーション サーバーに比べて 水平拡張##を実現することが困難です。 #。データベース接続リソースは貴重であり、単一マシンの処理能力には制限があるため、同時実行性が高いシナリオでは、垂直サブデータベースは IO、接続数、および単一マシンのハードウェア リソースのボトルネックをある程度まで突破できます。 <h2 data-tool="mdnice编辑器" style="margin-top: 30px;margin-bottom: 15px;font-weight: bold;font-size: 1.3em;border-bottom: 2px solid rgb(239, 112, 96);">
<span style="margin-right: 3px;padding: 3px 10px 1px;display: inline-block;background: rgb(239, 112, 96);color: rgb(255, 255, 255);border-top-right-radius: 3px;border-top-left-radius: 3px;">水平分割</span><span style="display: inline-block;vertical-align: bottom;border-bottom: 36px solid rgb(239, 235, 233);border-right: 20px solid transparent;"></span>
</h2>
<h3 data-tool="mdnice编辑器" style="margin-top: 30px;margin-bottom: 15px;font-weight: bold;font-size: 20px;">水平分割テーブル</h3>
<p data-tool="mdnice编辑器" style="padding-top: 8px;padding-bottom: 8px;line-height: 26px;">大量のデータを含む単一のテーブル (注文テーブルなど) の場合、特定のルール (<code style='margin-right: 2px;margin-left: 2px;padding: 2px 4px;font-size: 14px;border-radius: 4px;background-color: rgba(27, 31, 35, 0.05);font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;color: rgb(239, 112, 96);'>RANGE、ハッシュ係数 など) に従って複数のテーブルに分割されます。ただし、これらのテーブルは依然として同じライブラリ内にあるため、ライブラリ レベルでの データベース操作には依然として IO ボトルネックが存在します 。お勧めしません。
単一テーブルのデータを複数のサーバーに分割します。各サーバーには対応するライブラリとテーブルがありますが、テーブル内のデータ コレクションは異なります。水平サブデータベースとサブテーブルは、単一マシンと単一データベースのパフォーマンスのボトルネックとプレッシャーを効果的に軽減し、IO、接続数、ハードウェア リソースなどのボトルネックを突破します。
RANGE
0 ~ 10000 の 1 つのテーブル、10001 ~ 20000 の 1 つのテーブル;
HASH モデル
ショッピング モール システムは通常、ユーザーと注文をメイン テーブルとして使用し、関連するテーブルを付録として使用します。データベース間のトランザクションなどの問題が発生しません。ユーザー ID を取得し、ハッシュの係数を取得して、それをさまざまなデータベースに配布します。
地理的地域
たとえば、当社のビジネスを中国東部、中国南部、中国北部に分けた場合、Qiniu Cloud は次のようになります。このような。
Time
時間で分割します。つまり、6 か月前または 1 年前のデータを切り取って、別のテーブルに置きます。時間の経過とともに、これらのテーブル内のデータがクエリされる確率は小さくなるため、これらのテーブルを「ホット データ」にまとめる必要がなくなります。これは「ホット データとコールド データの分離」でもあります。
サブデータベースとテーブルその後、分散トランザクションになりました。
データベース自体の分散トランザクション管理機能に依存してトランザクションを実行すると、高いパフォーマンスの代償を支払うことになります; アプリケーションがデータベースの制御を支援し、プログラム ロジック トランザクションを形成すると、プログラミングの問題にも負担がかかります。
group by、order by と同様 このようなグループ化および並べ替えステートメントは使用できません
データベースをテーブルに分割した後は、テーブル間の関連付け操作が制限されるため、異なるデータベースにあるテーブルを結合したり、粒度の異なるテーブルを結合したりすることはできません。結果は、本来は 1 つのクエリで完了できるビジネスでも、完了するには複数のクエリが必要になる場合があります。大まかな解決策: グローバル テーブル: 基本データ、すべてのライブラリにコピーがあります。フィールドの冗長性: この方法では、一部のフィールドを結合によってクエリする必要がありません。システム層のアセンブリ: すべてを個別にクエリしてから組み立てますが、これはより複雑です。
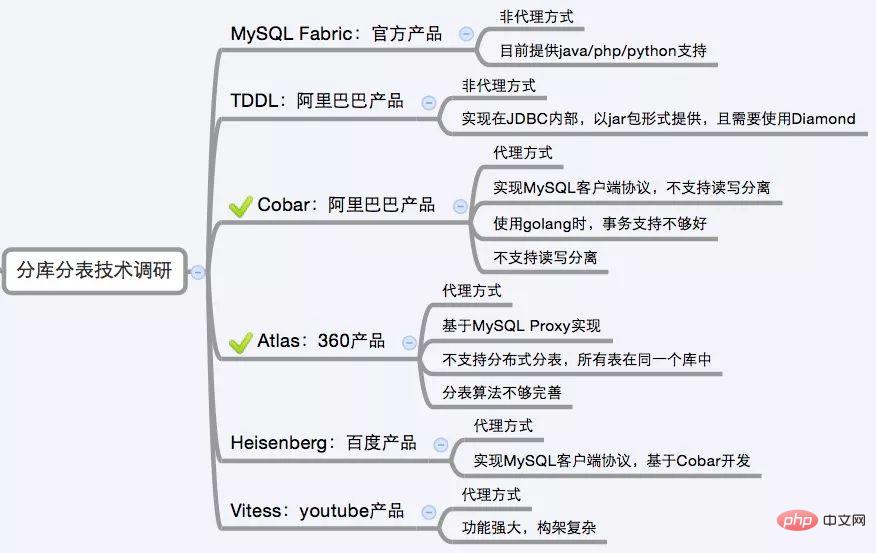
#市場には比較的多くのサブデータベースおよびサブテーブルのミドルウェアがあります。プロキシ メソッド MySQL Proxy および Amoeba に基づいており、Hibernate フレームワークに基づいているのは Hibernate Shards であり、jdbc に基づいているのは Dangdangsharding-jdbc です, mybatis 類似の Maven プラグインをベースに Spring の ibatis テンプレート クラスを書き換えた Mogujie の MogujieTSharding と Cobar Client があります。
いくつかの大企業のオープンソース製品もあります:
私は プログラマー Qingge です。人生と共有するのが大好きな 90 年代以降のプログラマー。
この問題の概要と、Mysql サブデータベースとサブテーブルに関する解決策がここで紹介されています。皆様のお役に立てれば幸いです。パブリック アカウント Java 学習に引き続きご注目ください。今後の Java インタビュー記事。guide。
以上が今日、ついに MySQL のサブデータベースとサブテーブルを理解したので、面接で自慢できます。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。


















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



