

Bilibili に関して言えば、第一印象はビデオです。私と同じように、ウェブ クローラー テクノロジーを使用したいと考えている友人がたくさんいると思います。ステーション B からビデオを取得しますが、ステーション B からのビデオを取得するのは実際にはそれほど簡単ではありません。Guan はステーション B からビデオを取得する方法に関するもので、以前は次の場所で入手できました。 この導入は、you-get ライブラリを通じて実装されています。興味のある友人はこの記事を読むことができます: You-Get はとても強力です! 。
## 自宅の近くでは、Bilibili でよく勉強している友人が、特にこのようなビデオを数十、さらには数百本連載しているブロガーによく遭遇するかもしれません。プログラミング言語に関する継続的なチュートリアル、コース、ツールの使用方法などを選択すると、次の図に示すように一連の選択が表示されます。
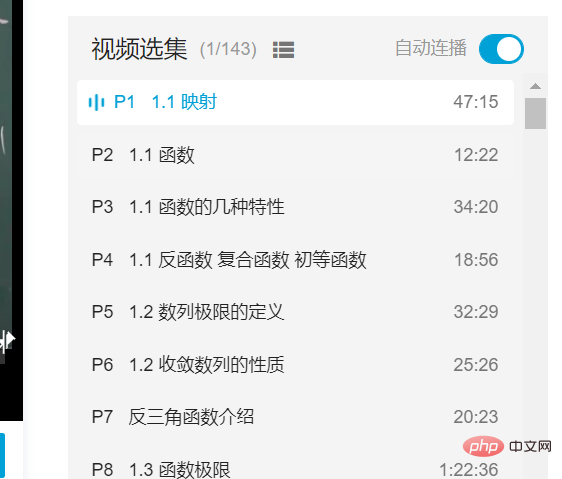
もちろんこれらの選択範囲は肉眼でも見ることができます。 Justプログラムで実装すると、想像ほど単純ではないかもしれません。したがって、この記事の目的は、Python Web クローラー テクノロジを通じて、Selenium ライブラリに基づいてビデオの選択を取得することです。
# coding: utf-8
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
class Item:
page_num = ""
part = ""
duration = ""
def __init__(self, page_num, part, duration):
self.page_num = page_num
self.part = part
self.duration = duration
def get_second(self):
str_list = self.duration.split(":")
sum = 0
for i, item in enumerate(str_list):
sum += pow(60, len(str_list) - i - 1) * int(item)
return sum
def get_bilili_page_items(url):
options = webdriver.ChromeOptions()
options.add_argument('--headless') # 设置无界面
options.add_experimental_option('excludeSwitches', ['enable-automation'])
# options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2,
# "profile.managed_default_content_settings.flash": 0})
browser = webdriver.Chrome(options=options)
# browser = webdriver.PhantomJS()
print("正在打开网页...")
browser.get(url)
print("等待网页响应...")
# 需要等一下,直到页面加载完成
wait = WebDriverWait(browser, 10)
wait.until(EC.visibility_of_element_located((By.XPATH, '//*[@class="list-box"]/li/a')))
print("正在获取网页数据...")
list = browser.find_elements_by_xpath('//*[@class="list-box"]/li')
# print(list)
itemList = []
second_sum = 0
# 2.循环遍历出每一条搜索结果的标题
for t in list:
# print("t text:",t.text)
element = t.find_element_by_tag_name('a')
# print("a text:",element.text)
arr = element.text.split('\n')
print(" ".join(arr))
item = Item(arr[0], arr[1], arr[2])
second_sum += item.get_second()
itemList.append(item)
print("总数量:", len(itemList))
# browser.page_source
print("总时长/分钟:", round(second_sum / 60, 2))
print("总时长/小时:", round(second_sum / 3600.0, 2))
browser.close()
return itemList
get_bilili_page_items("https://www.bilibili.com/video/BV1Eb411u7Fw")ここで使用されるセレクターは xpath です。ビデオの例は、Station の「Advanced Mathematics」の同済版です。 B 完全な教育ビデオ (ソング ハオ先生) のビデオ選択 他のビデオ選択を取得したい場合は、上記のコードの最後の行にある URL リンクを変更するだけです。
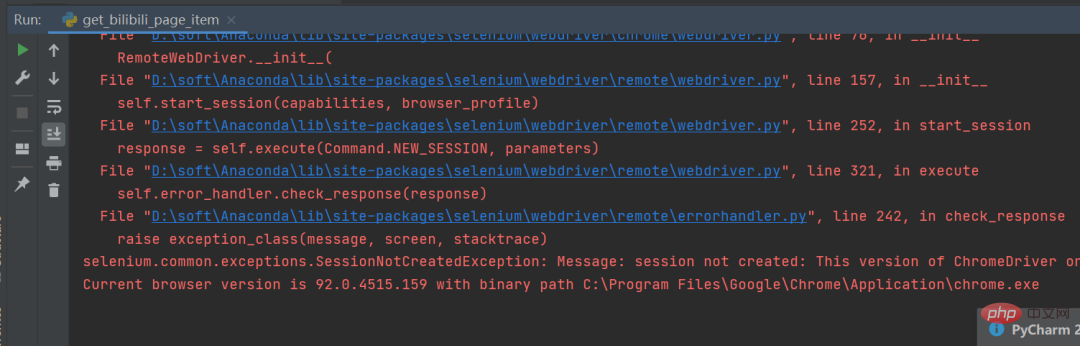
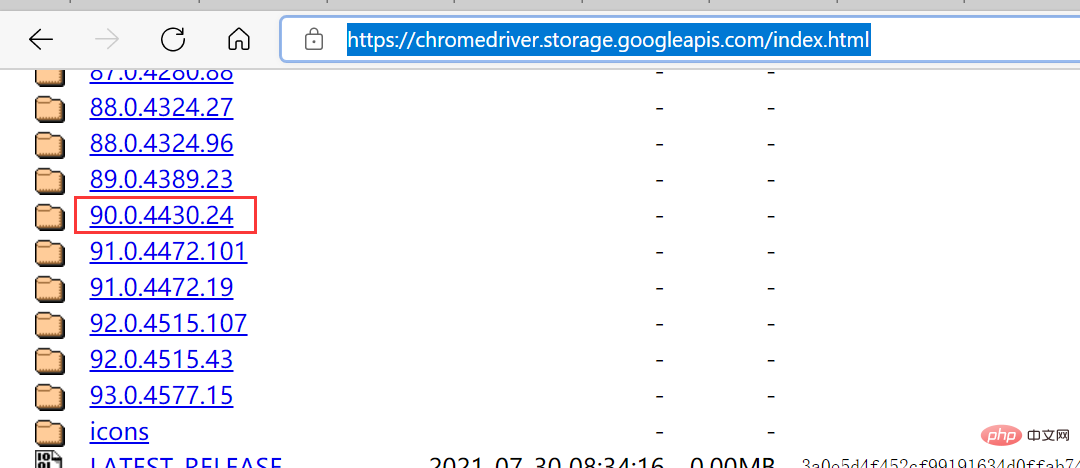
在运行过程中小伙伴们应该会经常遇到这个问题,如下图所示。 这个是因为谷歌驱动版本问题导致的,只需要根据提示,去下载对应的驱动版本即可,驱动下载链接:三、常见问题
https://chromedriver.storage.googleapis.com/index.html
ログイン後にコピー
以上がPython Web クローラーを使用して Bilibili のビデオ選択コンテンツを取得する方法を段階的に説明します (ソース コードが添付されています)。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。


















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



