


ケンブリッジ、NAIST、テンセント AI ラボの研究者らは最近、PandaGPT と呼ばれる研究結果を発表しました。これは、コマンド追従能力のためのクロスモダリティ技術を実現するために、異なるモダリティを持つ大規模な言語モデルを調整およびバインドする方法です。 PandaGPT は、詳細な画像説明の生成、ビデオからのストーリーの作成、音声に関する質問への回答などの複雑なタスクを実行できます。マルチモーダル入力を同時に受信し、それらのセマンティクスを自然に組み合わせることができます。

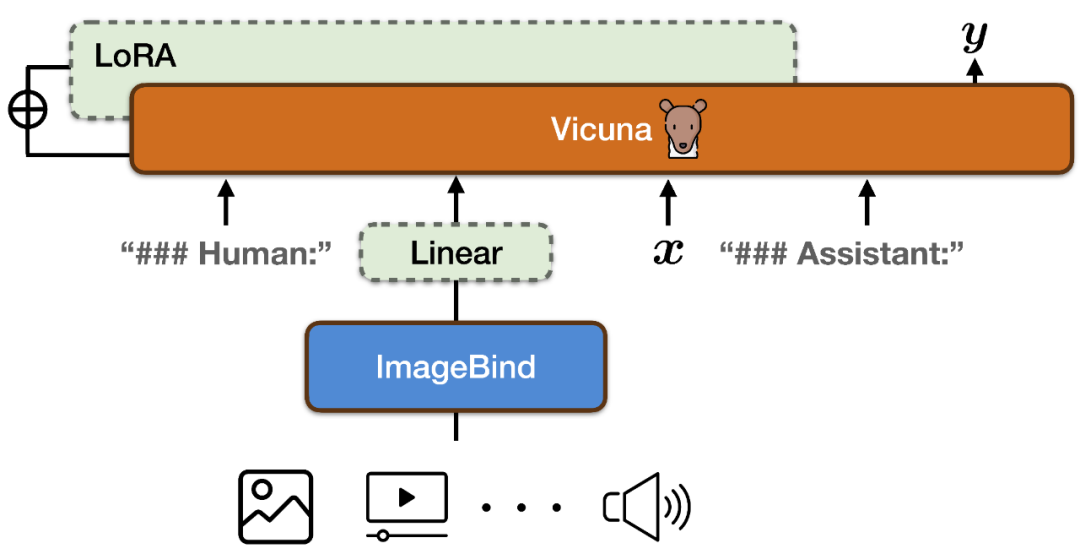
##画像&ビデオ、テキスト、オーディオ、ヒートマップ、デプスマップを実現するには、IMU 読み取り、6 つのモードでのコマンド追従機能、PandaGPT は、ImageBind のマルチモーダル エンコーダーと Vicuna ラージ言語モデルを組み合わせています (上の図を参照)。
ImageBind のマルチモーダル エンコーダと Vicuna の大規模言語モデルの特徴空間を調整するために、PandaGPT は、LLaVa と Mini-GPT4 を組み合わせてリリースされた合計 160k のイメージベースの言語命令を使用します。データをトレーニングデータとして使用します。各トレーニング インスタンスは、画像と対応する一連のダイアログ ラウンドで構成されます。
ImageBind 自体のマルチモーダル位置合わせの性質の破壊を回避し、トレーニング コストを削減するために、PandaGPT は次のモジュールのみを更新しました:
ImageBind のエンコード結果に線形射影行列を追加し、ImageBind によって生成された表現を変換して Vicuna の入力シーケンスに挿入します;
実験では、著者は、画像/ビデオベースの質問と回答、画像/ビデオベースのクリエイティブライティング、視覚および聴覚情報ベースのさまざまなモダリティを理解する PandaGPT の能力を実証しました。推論など、いくつかの例を次に示します:
画像:
#########オーディオビデオ: #### #

# 他のマルチモーダル言語モデルと比較した場合、PandaGPT の最も優れた機能は、さまざまなモダリティからの情報を理解し、自然に組み合わせる能力です。 #ビデオオーディオ: 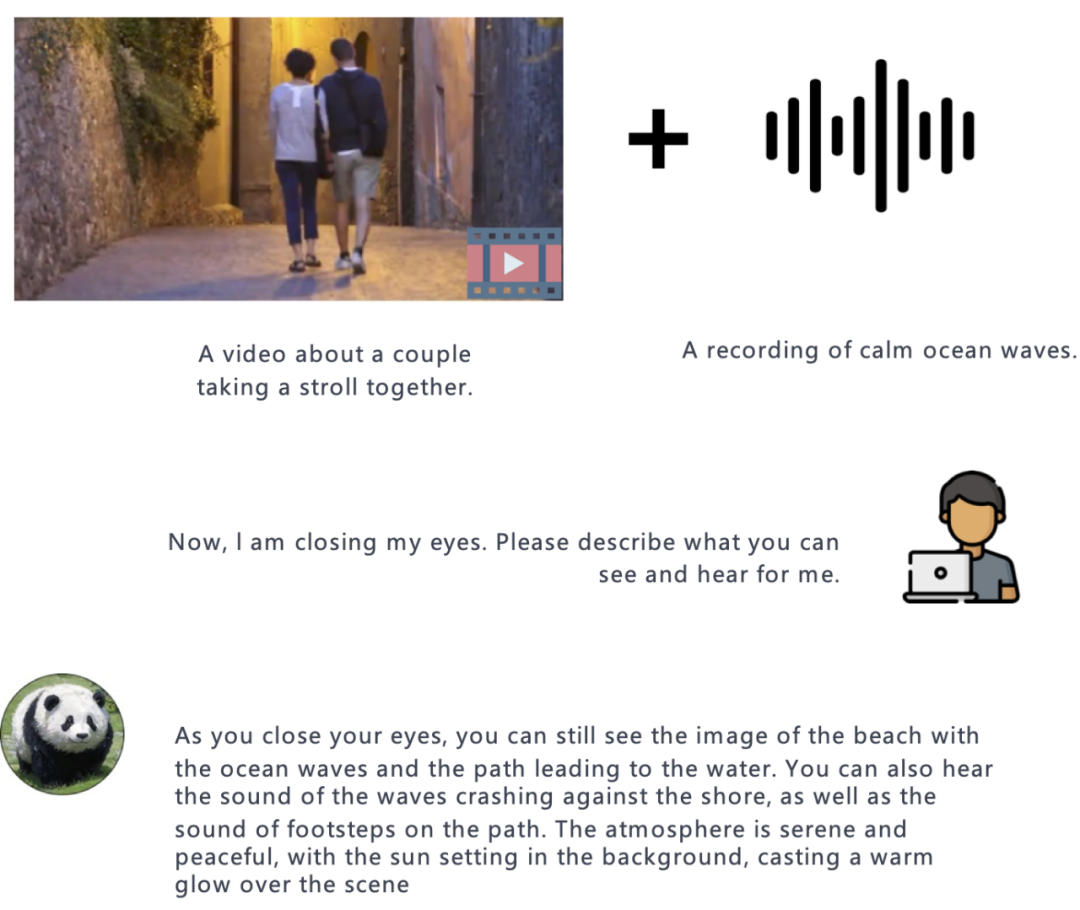
##画像音声:
 ##概要
##概要
PandaGPT は、音声テキスト モダリティに ASR や TTS データを使用するなど、他のモーダル アライメント データを使用することで、画像以外のモダリティの理解をさらに向上させることができます。技術的な理解と指示に従う能力。
以上がCambridge、Tencent AI Lab などが大規模言語モデル PandaGPT を提案しました: 1 つのモデルが 6 つのモダリティを統合しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



