


自動運転アプリケーションの場合、最終的には 3D シーンを認識することが必要になります。理由は簡単で、車両は画像から得られる知覚結果に基づいて運転することはできませんし、人間のドライバーであっても画像に基づいて運転することはできません。物体までの距離やシーンの奥行き情報は2D認識結果に反映できないため、自動運転システムが周囲の環境を正しく判断するための鍵となります。
一般に、自動運転車の視覚センサー (カメラなど) は、車体上部または車内のバックミラーに設置されます。どこにいても、カメラが取得するのは、透視図 (世界座標系から画像座標系) での現実世界の投影です。このビューは人間の視覚システムに似ているため、人間のドライバーは容易に理解できます。しかし、パース ビューの致命的な問題は、距離に応じてオブジェクトのスケールが変化することです。したがって、知覚システムが画像から前方の障害物を検出する場合、車両から障害物までの距離も、障害物の実際の 3 次元形状やサイズも知りません。
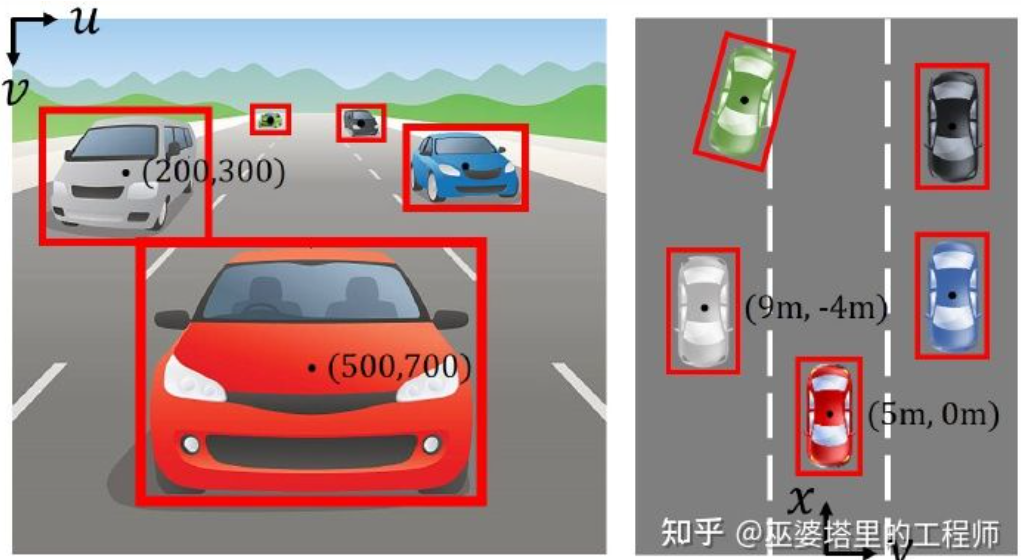
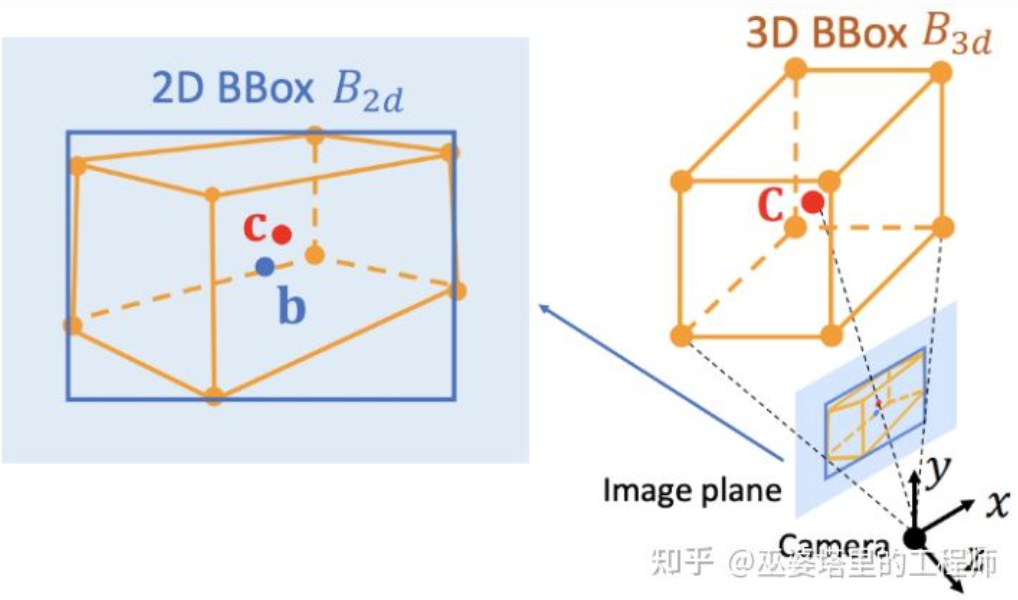
画像座標系(透視図)と世界座標系(鳥瞰図) [IPM- BEV ]
3D 空間に関する情報を取得する最も直接的な方法の 1 つは、LiDAR を使用することです。一方で、LiDAR によって出力された 3D 点群を直接使用して、障害物の距離とサイズ (3D オブジェクト検出)、およびシーンの深度 (3D セマンティック セグメンテーション) を取得できます。一方、3D 点群を 2D 画像と融合して、この 2 つによって提供されるさまざまな情報を最大限に活用することもできます。点群の利点は正確な距離と奥行きの認識であり、画像の利点はより豊富な意味情報です。
ただし、LiDAR にはコストが高い、車載グレードの製品の量産が難しい、天候の影響が大きいなどの欠点もあります。したがって、カメラのみに基づく 3D 認識は、依然として非常に有意義で価値のある研究の方向性です。この記事の次のセクションでは、シングル カメラとデュアル カメラに基づく 3D 認識アルゴリズムを詳しく紹介します。
単一のカメラ画像に基づいて 3D 環境を認識することは厄介な問題です。このタスクの完了を支援するためにいくつかの幾何学的制約と事前知識を使用すると、ディープ ニューラル ネットワークを使用して、画像の特徴から 3D 情報を予測する方法をエンドツーエンドで学習することもできます。

##単一カメラ 3D 物体検出 ( 画像M3D-RPN より) ##逆画像変換
BEV-IPM [1] は、画像を透視図から鳥瞰図 (BEV) に変換することを提案しています。ここでは 2 つの仮定があります。1 つは路面が世界座標系に平行で高さが 0 であるということ、もう 1 つは車両自身の座標系が世界座標系に平行であるということです。前者は路面が平坦でない場合には満たされませんが、後者は車両姿勢パラメータ(ピッチとロール)、つまり車両座標系と世界座標系のキャリブレーションによって補正できます。現実世界では画像内のすべてのピクセルの高さがゼロであると仮定すると、ホモグラフィー変換を使用して画像を BEV ビューに変換できます。 BEV ビューでは、YOLO ネットワークに基づく手法を使用して、路面に接する長方形であるターゲットの下部ボックスを検出します。ボトム ボックスの高さはゼロであるため、ニューラル ネットワークをトレーニングするための GroudTruth として BEV ビューに正確に投影でき、同時にニューラル ネットワークによって予測されたボックスの距離も正確に推定できます。ここでの前提は、ターゲットが路面に接触している必要があるということですが、車両や歩行者のターゲットには通常これで十分です。
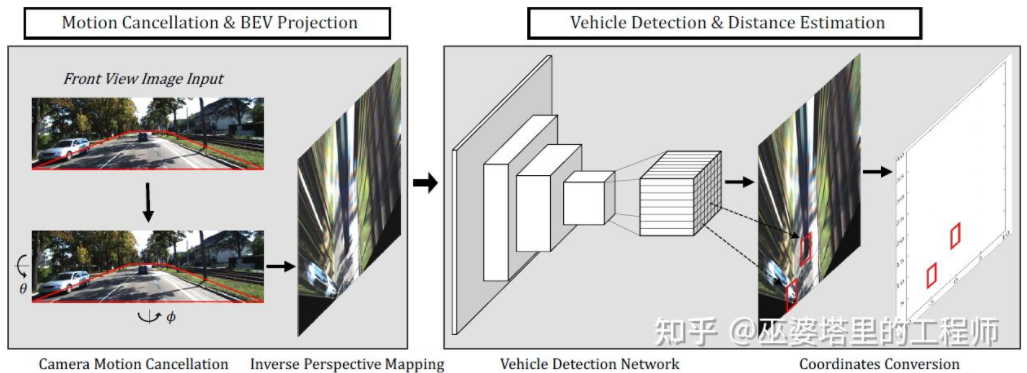
#BEV-IPM
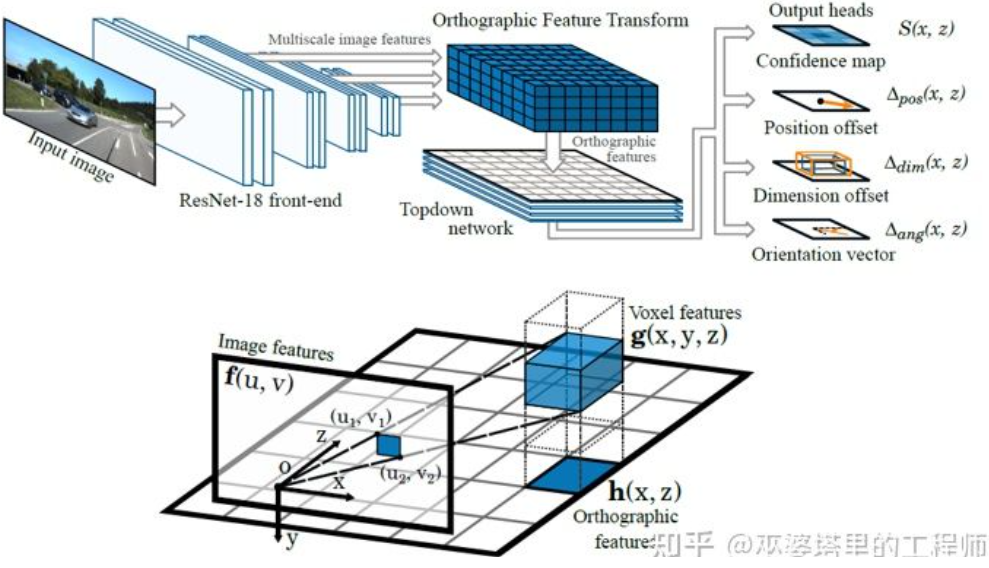
##もう 1 つの逆変換方法は、直交特徴変換 (OFT) [2] を使用します。そのアイデアは、CNN を使用してマルチスケールの画像特徴を抽出し、次にこれらの画像特徴を BEV ビューに変換し、最後に BEV 特徴に対して 3D オブジェクト検出を実行することです。まず、BEV の観点から 3D グリッドを構築する必要があります (この記事の実験のグリッド範囲は 80 メートル x 80 メートル x 4 メートル、グリッド サイズは 0.5 メートルです)。各グリッドは透視変換により画像上の領域(便宜上長方形領域と定義)に対応し、この領域内の画像特徴量の平均値をグリッドの特徴量として使用することで、3Dグリッド特性が得られます。計算量を削減するために、3D グリッド フィーチャを高さ次元で圧縮 (加重平均) して 2D グリッド フィーチャを取得します。最終的なオブジェクト検出は 2D メッシュ フィーチャに対して実行されます。 3D グリッドの 2D 画像ピクセルへの投影は 1 対 1 に対応せず、複数のグリッドが隣接する画像領域に対応するため、グリッドの特徴が曖昧になります。したがって、検出対象物はすべて道路上にあり、高さの範囲が非常に狭いことも想定する必要があります。したがって、実験で使用された 3D グリッドの高さはわずか 4 メートルで、地上の車両と歩行者を十分にカバーできます。しかし、交通標識を検出したい場合、物体が地面に近いと仮定するこの方法は適用できません。
上記どちらの方法も、オブジェクトが地上にあるという前提に基づいています。また、深度推定の結果を利用して擬似点群データを生成するアイデアもあり、代表的なものとしてPseudo-LiDAR[3]が挙げられる。奥行き推定の結果は通常、追加の画像チャネル (RGB-D データと同様) として扱われ、画像ベースのオブジェクト検出ネットワークを直接使用して 3D オブジェクト境界ボックスが生成されます。著者は記事の中で、奥行き推定に基づく3Dオブジェクト検出の精度がLiDARベースの方法よりもはるかに悪い主な理由は、奥行き推定の精度が不十分であるためではなく、データの表現方法。まず、画像データ上では、遠方の物体の領域が非常に小さいため、遠方の物体の検出が非常に不正確になります。次に、隣接するピクセル間の奥行きの差が非常に大きい場合があります (オブジェクトのエッジなど) この場合、特徴を抽出するために畳み込み演算を使用する場合に問題が発生します。この 2 つの点を考慮して、著者は、入力画像を深度マップに基づいて LiDAR が生成するものと同様の点群データに変換し、点群と画像融合アルゴリズム (AVOD や F-PointNet など) を使用して、 3D オブジェクトを検出します。 Pseudo-LiDAR 方法は、特定の深度推定アルゴリズムに依存せず、単眼または双眼からの任意の深度推定を直接使用できます。この特別なデータ表現方法により、Pseudo-LiDAR は 30 メートルの範囲内で物体検出の精度を 22% から 74% に向上させることができます。
 #擬似 LiDAR
#擬似 LiDAR
本物の LiDAR 点群と比較すると、擬似 LiDAR 方式は、3D オブジェクトの検出精度に依然として一定のギャップがありますが、これは主に奥行き推定の精度が不十分 (単眼よりも両眼の方が優れている) ためであり、特に物体周囲の奥行き推定誤差が大きな影響を与えます。検出時。したがって、Pseudo-LiDAR もそれ以来、多くの拡張を経てきました。擬似 LiDAR [4] は、低配線 LiDAR を使用して仮想点群を強化します。 Pseudo-Lidar End2End[5] は、インスタンス セグメンテーションを使用して、F-PointNet のオブジェクト フレームを置き換えます。 RefinedMPL [6] は、前景点にのみ仮想点群を生成し、点群の数を元の 10% に削減します。これにより、誤検出の数とアルゴリズムの計算量を効果的に削減できます。
キーポイントと 3D モデル
DeepMANTA[7] は、この方向における先駆的な作品の 1 つです。まず、Faster RNN などの従来の画像オブジェクト検出アルゴリズムを使用して 2D オブジェクト フレームを取得し、車両上のキー ポイントも検出します。次に、これらの 2D オブジェクトのフレームとキー ポイントがデータベース内のさまざまな 3D 車両 CAD モデルと照合され、最も類似性の高いモデルが 3D オブジェクト検出の出力として選択されます。
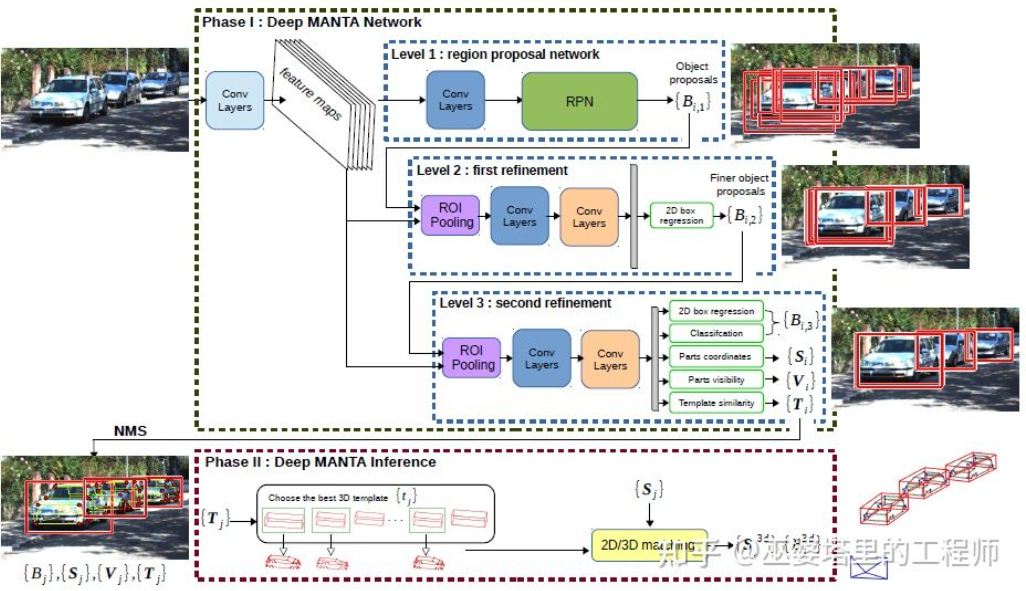
#Deep MANTA
3D-RCNN[8] の使用が提案されましたインバース - 画像に基づいて、シーン内の各ターゲットの 3D 形状とポーズを復元するグラフィックス手法。基本的な考え方は、ターゲットの 3D モデルから開始し、パラメータ検索を通じて画像内のターゲットに最もよく一致するモデルを見つけることです。これらの 3D モデルには通常、多くの制御パラメータと広い探索空間が含まれるため、従来の方法では高次元のパラメータ空間で最適な結果を探索するのに良い結果が得られません。 3D-RCNN は、PCA を使用してパラメーター空間 (10-D) の次元を削減し、ディープ ニューラル ネットワーク (R-CNN) を使用して各ターゲットの低次元モデル パラメーターを予測します。予測されたモデル パラメーターは、各ターゲットの 2 次元画像または深度マップを生成するために使用でき、GroudTruth データと比較することで得られる Loss は、ニューラル ネットワークの学習をガイドするために使用できます。この損失は Render-and-Compare Loss と呼ばれ、OpenGL に基づいて実装されています。 3D-RCNN 手法は大量の入力データを必要とし、損失の設計が比較的複雑であるため、エンジニアリングでの実装が困難です。
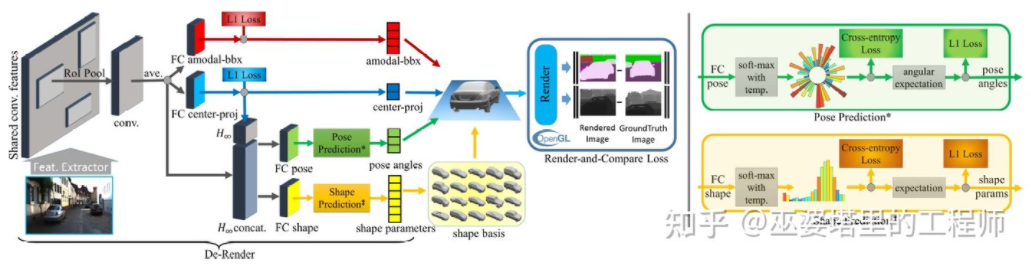
3D-RCNN
MonoGRNet[ 9 ] は、単眼 3D オブジェクト検出を 4 つのステップに分割することを提案しました。これらのステップは、2D オブジェクトのフレーム、オブジェクトの 3D 中心の深さ、オブジェクトの 3D 中心の 2D 投影位置、および 8 つのコーナー点の 3D 位置を予測するために使用されます。まず、画像内の予測された 2D オブジェクト フレームが ROIAlign によって操作され、オブジェクトの視覚的特徴が取得されます。これらの特徴は、オブジェクトの 3D 中心の深さと 3D 中心の 2D 投影位置を予測するために使用されます。この 2 つの情報により、物体の 3D 中心点の位置が得られます。最後に、3D 中心の位置に基づいて、8 つのコーナー ポイントの相対位置が予測されます。 MonoGRNet はオブジェクトの中心のみをキーポイントとして使用し、2D と 3D のマッチングは点の距離の計算であると考えることができます。 MonoGRNetV2 [10] は中心点を複数のキーポイントに拡張し、深度推定に 3D CAD オブジェクト モデルを使用します。これは、以前に導入された DeepMANTA および 3D-RCNN に非常によく似ています。
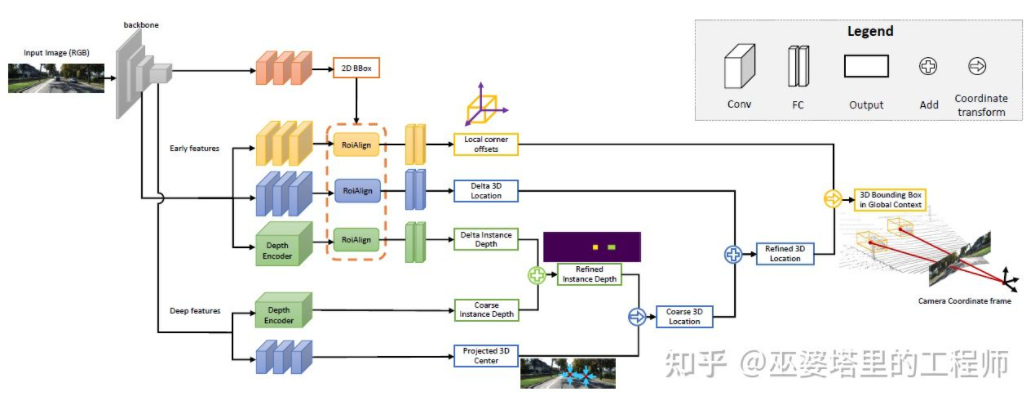
MonoGRNet
Monoloco[11] は主に、次の 3D 検出を解決します。歩行者の質問。歩行者は姿勢や変形が多様な非剛体であるため、車両の検出よりも困難になります。 Monoloco もキー ポイント検出に基づいており、事前にキー ポイントの相対 3D 位置を深度推定に使用できます。例えば、歩行者の距離は、歩行者の肩から腰までの長さ50センチメートルに基づいて推定される。この長さをベンチマークとして使用する理由は、人体のこの部分が最も変形が少なく、最も高い精度で深度推定に使用できるためです。もちろん、他の重要なポイントも、詳細な見積もりのタスクを完了するための補助として使用できます。 Monoloco は、多層完全接続ネットワークを使用して、主要なポイントの位置から歩行者までの距離を予測すると同時に、予測の不確実性も提供します。
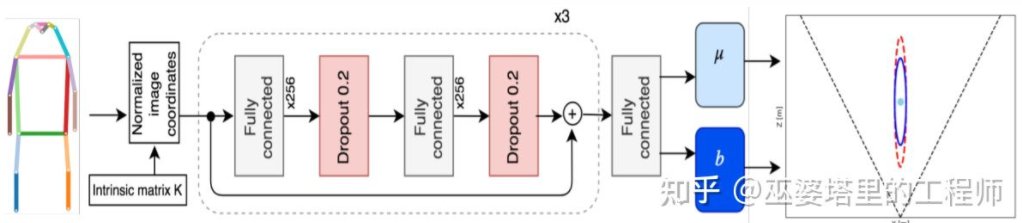
要約すると、上記の方法はすべて 2D から始まります。画像 キーポイントを抽出し、3Dモデルと照合し、対象物の3D情報を取得します。このタイプの方法は、ターゲットが比較的固定された形状モデルを持っていることを前提としています。これは車両にとっては一般に満足ですが、歩行者にとっては比較的困難です。さらに、このタイプの方法では 2D 画像上に複数のキー ポイントをマークする必要があり、これも非常に時間がかかります。
Deep3DBox[12]は、この方向における初期の代表的な作品です。 3D オブジェクトのフレームを表すには、中心、サイズ、向きという 9 次元の変数が必要です (3D の向きはヨーに簡略化できるため、7 次元の変数になります)。画像 2D オブジェクト検出では、4 つの既知の変数 (2D 中心と 2D サイズ) を含む 2D オブジェクト フレームを提供できますが、これは 7 または 9 自由度の変数を解決するには十分ではありません。これら 3 つの変数セットのうち、サイズと方向は視覚的特徴と比較的密接に関連しています。たとえば、オブジェクトの 3D サイズはそのカテゴリ (歩行者、自転車、自動車、バス、トラックなど) と密接に関連しており、オブジェクトのカテゴリは視覚的な特徴を通じて予測できます。中心点の 3D 位置については、透視投影によって生じる曖昧さのため、純粋に視覚的な特徴を通じて予測することは困難です。したがって、Deep3DBox は、まず 2D オブジェクト ボックス内の画像特徴を使用して、オブジェクトのサイズと方向を推定することを提案します。次に、2D/3D 幾何拘束を使用して中心点の 3D 位置を解決します。この制約は、画像上の 3D オブジェクト フレームの投影が 2D オブジェクト フレームに密接に囲まれている、つまり 3D オブジェクト フレームの少なくとも 1 つのコーナー ポイントが 2D オブジェクト フレームの両側に存在するということです。事前に予測されたサイズと方向をカメラのキャリブレーション パラメーターと組み合わせることで、中心点の 3D 位置を解決できます。
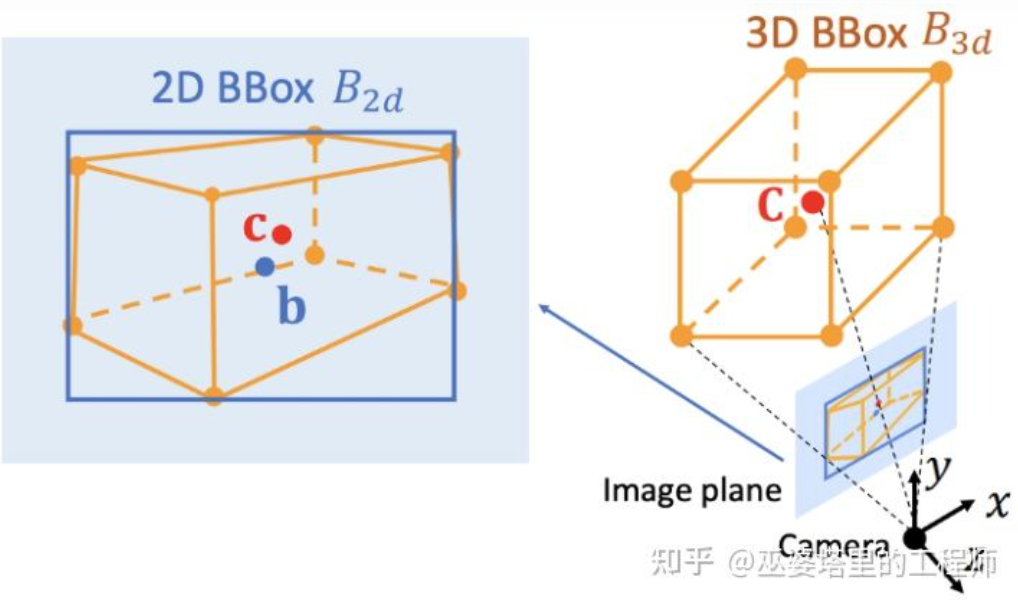
#2D オブジェクト フレームと 3D オブジェクト フレーム間の幾何学的制約 (図は参考文献 [9] から)
2D/3D 制約を利用するこの方法では、非常に正確な 2D オブジェクト フレーム検出が必要です。 Deep3DBox のフレームワークでは、2D オブジェクトのフレーム上の小さな誤差が 3D オブジェクトのフレーム予測の失敗を引き起こす可能性があります。 Shift R-CNN [13] の最初の 2 つのステージは Deep3DBox に非常に似ており、2D オブジェクト ボックスと視覚的特徴を通じて 3D サイズと方向を予測し、幾何学的制約を通じて 3D 位置を解決します。ただし、Shift R-CNN は 3 番目のステージを追加します。このステージでは、最初の 2 つのステージで取得された 2D オブジェクト フレーム、3D オブジェクト フレーム、およびカメラ パラメーターが入力として結合され、完全に接続されたネットワークを使用して、より正確な 3D 位置を予測します。
Shift R-CNN
2D/3D 幾何拘束を使用する上記のメソッドはすべて、一連の超制約された方程式を解くことによってオブジェクトの 3D 位置を取得します。このプロセスは後処理ステップとして使用され、ニューラル ネットワーク内にはありません。 Shift R-CNN の第 1 段階と第 3 段階も個別にトレーニングされます。 MVRA [14] は、この超制約された方程式の解法プロセスをネットワークに構築し、画像座標の IoU 損失と BEV 座標の L2 損失を設計して、それぞれオブジェクト フレームの誤差と距離推定を測定し、エンドツーエンドの完了を支援します。トレーニング終了です。このように、オブジェクトの 3D 位置予測の品質は、以前の 3D サイズと方向の予測にもフィードバック効果をもたらします。3D オブジェクト フレームを直接生成する
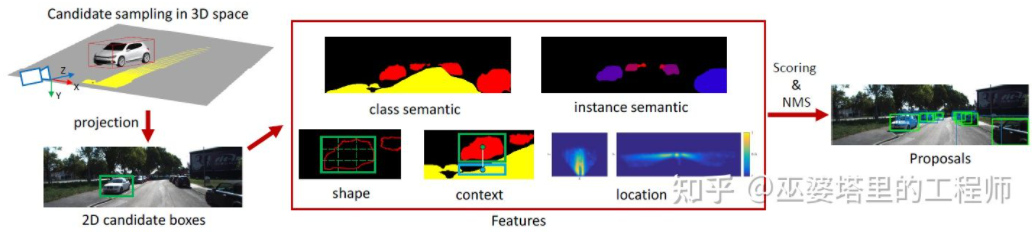
Mono3D[15]はこの種の手法の代表的なものです。まず、ターゲットの以前の位置 (Z 座標は地上) とサイズに基づいて、密な 3D 候補ボックスが生成されます。 KITTI データセットでは、フレームごとに約 40,000 (車両) または 70,000 (歩行者と自転車) の候補ボックスが生成されます。これらの 3D 候補ボックスが画像座標に投影された後、2D 画像上の特徴によってスコアが付けられます。これらの特徴は、セマンティック セグメンテーション、インスタンス セグメンテーション、コンテキスト、形状、位置の事前情報から得られます。これらすべての特徴を組み合わせて候補ボックスにスコアを付け、より高いスコアを持つものが最終候補として選択されます。これらの候補は、次のスコアリング ラウンドで CNN に渡され、最終的な 3D オブジェクト フレームが取得されます。
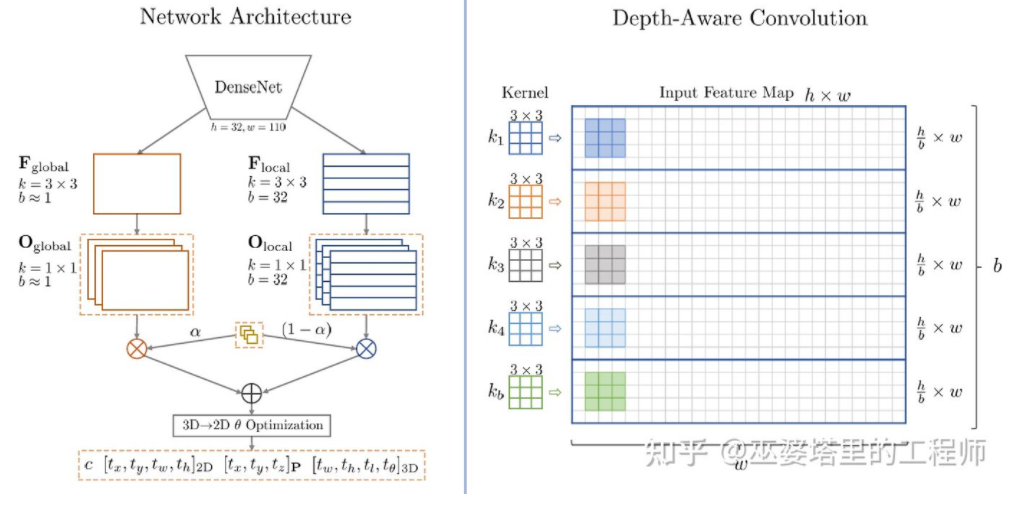
Mono3D M3D-RPN[16] はアンカーベースの方法です。このメソッドは、それぞれ 2D および 3D オブジェクト フレームを表す 2D および 3D アンカーを定義します。 2D アンカーは画像上の高密度サンプリングによって取得されますが、3D アンカーのパラメータはトレーニング セット データから取得された事前知識に基づいて決定されます。具体的には、各 2D アンカーは、IoU に従って画像内でマークされた 2D オブジェクト フレームと照合され、対応する 3D オブジェクト フレームの平均値を使用して 3D アンカーのパラメータが定義されます。 M3D-RPN では、標準の畳み込み演算 (空間不変性を伴う) と深度認識畳み込みの両方が使用されることに言及する価値があります。後者は、画像の行 (Y 座標) を複数のグループに分割し、各グループは異なるシーン深度に対応し、異なるコンボリューション カーネルによって処理されます。 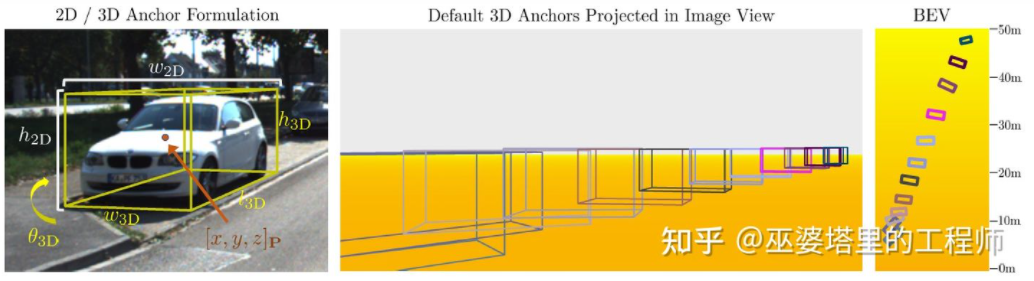
## M3D-RPN アンカー設計
#いくつかの事前知識が使用されますが、Mono3D と M3D-RPN は、オブジェクト候補またはアンカーを生成するときに依然として高密度サンプリングに基づいているため、計算量が大幅に増加します。必要な量は非常に多く、実用性に大きく影響します。その後、探索空間をさらに縮小するために、2 次元画像の検出結果を使用するいくつかの方法が提案されました。TLNet[17] は、アンカーを 2 次元平面上に密に配置します。アンカー間隔は 0.25 メートル、方向は 0 度と 90 度、サイズはターゲットの平均です。画像上の 2 次元検出結果は 3 次元空間に複数のビューイング コーンを形成し、これらのビューイング コーンを通じて背景の多数のアンカーを除去することができ、アルゴリズムの効率が向上します。フィルタリングされたアンカーが画像上に投影され、ROI プーリング後に取得された特徴を使用して 3D オブジェクト フレームのパラメータがさらに調整されます。
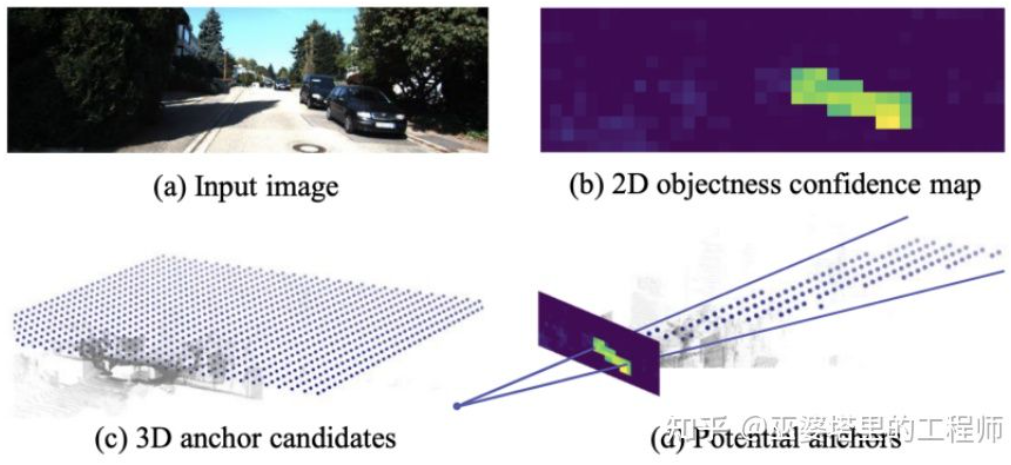
SS3D[18] Aより効率的な一段階検出が使用され、CenterNet 構造と同様のネットワークが、オブジェクト カテゴリ、2D オブジェクト フレーム、3D オブジェクト フレームなどのさまざまな 2D および 3D 情報を画像から直接出力するために使用されます。ここでの 3D オブジェクト フレームは、一般的な 9D または 7D 表現 (この表現は画像から直接予測することが困難です) ではなく、画像から予測しやすく、距離などのより多くの冗長性を含む 2D 表現であることに注意してください。 . (1-d)、向き (2-d、sin および cos)、サイズ (3-d)、8 つのコーナー点の画像座標 (16-d)。 2D オブジェクト ボックスの 4D 表現と組み合わせると、合計 26D フィーチャになります。これらすべての特徴は 3D オブジェクト フレームを予測するために使用され、実際の予測プロセスでは 26D 特徴に最もよく一致する 3D オブジェクト フレームを見つけます。特別な点は、この解法プロセスがニューラル ネットワーク内で実行されるため、微分可能でなければならないという点であり、これもこの記事の大きなハイライトです。シンプルな構造と実装の利点を活かし、SS3D は 20FPS の速度で実行できます。
 #SS3D
#SS3D
##FCOS3D[19] も 1 段階検出ですメソッドですが、SS3D よりも簡潔です。 3D オブジェクト フレームの中心を 2D 画像に投影して 2.5D 中心 (X、Y、深さ) を取得します。これは回帰の目標の 1 つとして使用されます。さらに、回帰ターゲットには 3D サイズと方向も含まれます。ここでの方向は、角度 (0-pi) と方位の組み合わせで表されます。
FCOS3D
##SMOKE[20] 類似品CenterNet のような構造を通じて画像から 2D および 3D 情報を直接予測するというアイデアも提案されました。 2D 情報には、オブジェクトのキーポイント (中心点とコーナー点) の画像上の投影位置が含まれ、3D 情報には中心点の奥行き、サイズ、向きが含まれます。画像の位置と中心点の深さによって、オブジェクトの 3D 位置を復元できます。各コーナーポイントの 3D 位置は、3D サイズと方向を通じて復元できます。 上で紹介した単一ステージ ネットワークのアイデアは、複雑な前処理 (画像の逆変換など) や後処理 (画像の逆変換など) を必要とせずに、画像から 3D 情報を直接返すことです。 3D モデルのマッチングなど)、正確な幾何学的制約 (たとえば、3D オブジェクト フレームの少なくとも 1 つのコーナー ポイントが 2D オブジェクト フレームの各エッジ上に存在する)。これらの方法では、さまざまな種類のオブジェクトの実際の平均サイズや、その結果得られる 2D オブジェクトのサイズと深さの対応関係など、少量の事前知識のみが使用されます。これらの事前知識はオブジェクトの 3D パラメーターの初期値を定義し、ニューラル ネットワークは実際の値からの偏差を回帰するだけで済みます。これにより、探索スペースが大幅に削減され、ネットワーク学習の困難さが軽減されます。 前のセクションでは、単眼 3D オブジェクト検出の代表的な方法を紹介しましたが、そのアイデアは初期の画像変換、3D に基づいています。モデルマッチングと 2D/3D 幾何学的制約から、画像から直接 3D 情報を予測する最近の機能まで。この考え方の変化は主に、深さ推定における畳み込みニューラル ネットワークの進歩に起因しています。以前に紹介した単一ステージ 3D オブジェクト検出ネットワークのほとんどには、深度推定ブランチが含まれています。ここでの深さの推定は、密なピクセル レベルではなく、まばらなターゲット レベルでのみ行われますが、オブジェクトの検出には十分です。 自動運転の認識には、物体の検出に加えて、セマンティック セグメンテーションという別の重要なタスクもあります。セマンティック セグメンテーションを 2D から 3D に拡張する最も直接的な方法は、各ピクセルのセマンティック情報と深度情報が利用できるように、高密度深度マップを使用することです。 上記 2 点に基づいて、単眼奥行き推定は 3D 認識タスクにおいて非常に重要な役割を果たします。前のセクションでの 3D オブジェクト検出方法の紹介からの類推により、完全畳み込みニューラル ネットワークは高密度深度推定にも使用できます。以下に、この方向性の現在の開発状況を紹介します。 単眼奥行き推定の入力は画像であり、出力も画像 (通常は入力と同じサイズ) であり、その上の各ピクセル値はシーンの奥行きに対応します。入力画像の。このタスクは、セマンティック セグメンテーションが各ピクセルのセマンティック分類を出力することを除いて、画像のセマンティック セグメンテーションにある程度似ています。もちろん、入力をビデオ シーケンスにすることもでき、カメラまたはオブジェクトの動きによってもたらされる追加情報を使用して、奥行き推定 (ビデオ セマンティック セグメンテーションに対応) の精度を向上させます。 前述したように、2D 画像から 3D 情報を予測するのは不適切な問題であるため、従来の方法では、幾何学的情報、動き情報、その他の手がかりを使用して、手動で設計された特徴の深さを通じてピクセルを予測します。 。セマンティック セグメンテーションと同様に、スーパーピクセル (SuperPixel) と条件付きランダム フィールド (CRF) の 2 つの方法が、推定の精度を向上させるためによく使用されます。近年、ディープ ニューラル ネットワークはさまざまな画像認識タスクにおいて画期的な進歩を遂げており、深度推定も例外ではありません。大量の研究により、ディープ ニューラル ネットワークは、手作業で設計された特徴よりも優れた特徴をトレーニング データを通じて学習できることが示されています。ここでは主に教師あり学習に基づく手法を紹介します。両眼視差情報、単眼デュアルピクセル (Dual Pixel) 差分情報、ビデオ動き情報などの使用など、他のいくつかの教師なし学習のアイデアは、後で紹介します。 この方向における初期の代表的な研究は、Eigen らによって提案されたグローバル手がかりとローカル手がかり融合に基づく方法です[21]。単眼の奥行き推定のあいまいさは主に地球規模に起因します。たとえば、記事では、実際の部屋とおもちゃの部屋は画像上では大きく異なって見えるかもしれないが、実際の被写界深度は大きく異なると述べました。これは極端な例ですが、実際のデータセットには部屋や家具の寸法のばらつきが依然として存在します。したがって、この方法では、画像に対して多層畳み込みとダウンサンプリングを実行してシーン全体の記述的特徴を取得し、これを使用してグローバル深度を予測することを提案します。次に、別のローカル ブランチ (比較的高い解像度) を使用して、ローカル画像の深度を予測します。ここでは、グローバル深度がローカル ブランチへの入力として使用され、ローカル深度の予測を支援します。 奥行き推定
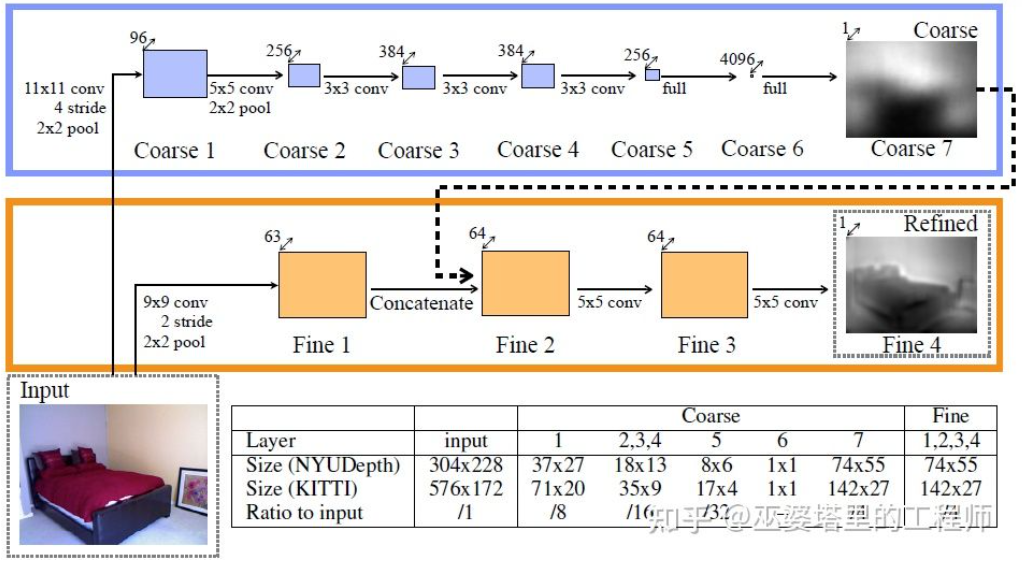
グローバル情報とローカル情報の融合 [21]
Literature [22] はさらに、畳み込みニューラル ネットワークによって出力されたマルチスケールの特徴マップを使用して、さまざまな解像度の深度マップを予測することを提案しています ([21] には解像度が 2 つだけあります)。異なる解像度のこれらの特徴マップは、連続 MRF を通じて融合され、入力画像に対応する深度マップが取得されます。
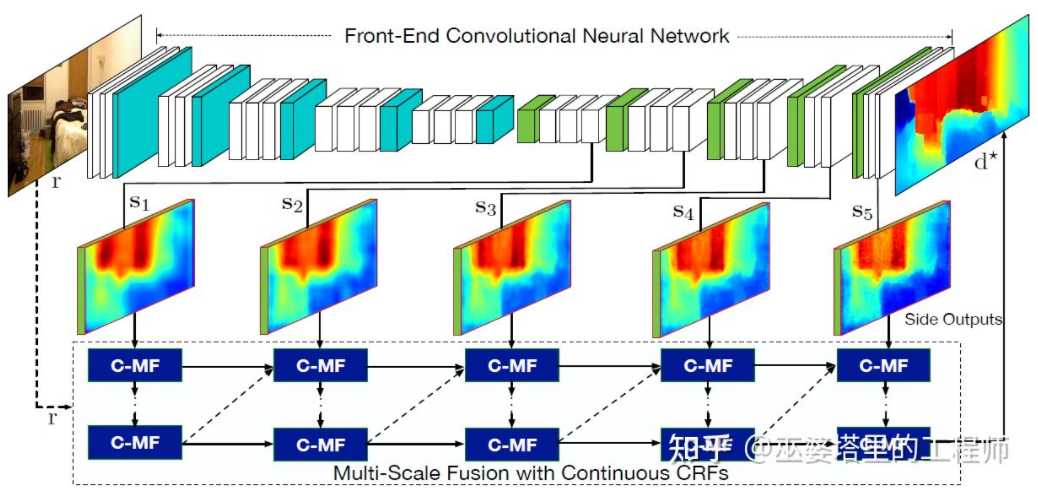
#マルチスケール情報融合[22]
上記 2 つこれらはすべて畳み込みニューラル ネットワークを使用して深度マップを返します。別のアイデアは、回帰問題を分類問題に変換すること、つまり、連続的な深度値を離散的な区間に分割し、各区間をカテゴリと見なすことです。この方向の代表的な作品は DORN [23] である。 DORN フレームワークのニューラル ネットワークもコーディングとデコーディングの構造ですが、全結合層デコーディングの使用、特徴抽出のための拡張畳み込みなど、細部ではいくつかの違いがあります。
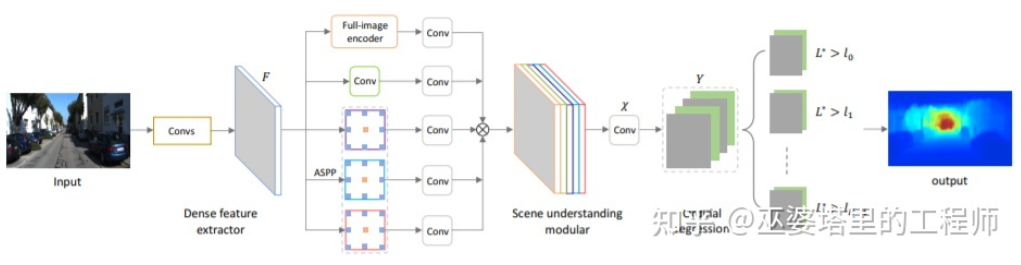
DORN の深層分類
前述深度推定にはセマンティック セグメンテーション タスクとの類似点があるため、受容野のサイズも深度推定には非常に重要であることに注意してください。前述のピラミッド ノットと拡張畳み込みに加えて、最近人気のトランスフォーマー構造はグローバルな受容フィールドを備えているため、このようなタスクに非常に適しています。文献 [24] では、Transformer とマルチスケール構造を使用して、予測のローカルな精度とグローバルな一貫性を同時に確保することが提案されています。
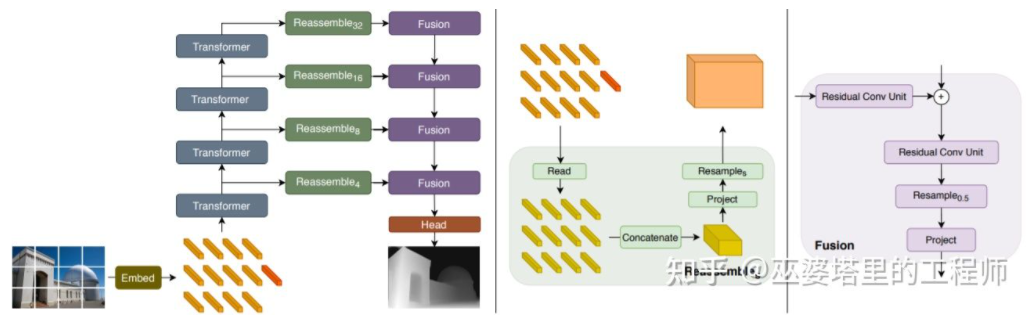
高密度予測用トランスフォーマー02
両眼 3D 知覚両眼視機能は、視点変換によって生じる曖昧さを解決できるため、理論的には 3D 認識の精度を向上させることができます。ただし、双眼システムにはハードウェアとソフトウェアの点で比較的高い要件があります。ハードウェア的には、正確に登録された 2 台のカメラが必要であり、車両の運行中に登録の精度を確保する必要があります。ソフトウェア面では、アルゴリズムは 2 台のカメラからのデータを同時に処理する必要があり、計算の複雑さは高く、アルゴリズムのリアルタイム性を確保することはさらに困難です。
一般に、単眼視覚に比べて両眼視覚に関する論文は比較的少ないため、以下に代表的な論文をいくつか取り上げて紹介します。さらに、AI Day で Tesla が実証した 360° 知覚システムのように、多目的に基づいているがシステム アプリケーション レベルに偏った作品もいくつかあります。
物体検出
一般に、これは 2 段階の検出方法です。第 1 段階では深度情報 (点群) を使用してオブジェクト候補を生成し、第 2 段階では画像情報 (または深度) を使用してさらに絞り込みます。理論的には、点群生成の最初の段階も LiDAR で置き換えることができるため、著者は実験的な比較を行いました。 LiDAR の利点は、距離測定が正確であるため、小さな物体、部分的に隠れた物体、遠くにある物体に対して効果的に機能することです。両眼視の利点は、点群密度が高いため、近距離に障害物が少なく、オブジェクトが比較的大きい場合に効果的です。もちろん、コストと計算の複雑さを考慮せずに、この 2 つを統合することで最良の結果が得られます。
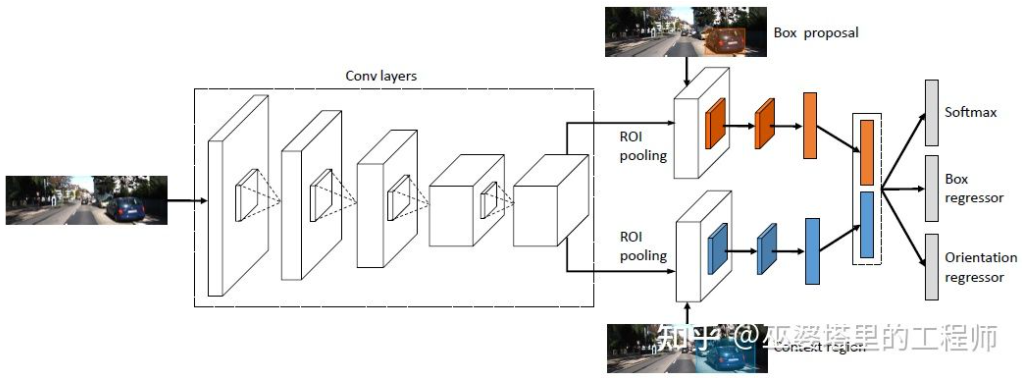
3DOP
##3DOP は、前に紹介した Pseudo- と同じです。セクション LiDAR [3] にも同様のアイデアがあり、(単眼、両眼、または低ライン数の LiDAR からの) 高密度深度マップを点群に変換し、点群オブジェクト検出の分野にアルゴリズムを適用します。画像から深度マップを推定し、深度マップから点群を生成し、最後に点群オブジェクト検出アルゴリズムを適用します。このプロセスの各ステップは個別に実行されるため、実行できません。エンドツーエンドで実行される列車。 DSGN [26] は、左右の画像から開始し、平面スイープ ボリュームなどの中間表現を使用して BEV ビューで 3D 表現を生成し、奥行き推定とオブジェクト検出を同時に実行する単一段階アルゴリズムを提案しました。このプロセスのすべてのステップは微分可能であるため、エンドツーエンドでトレーニングできます。
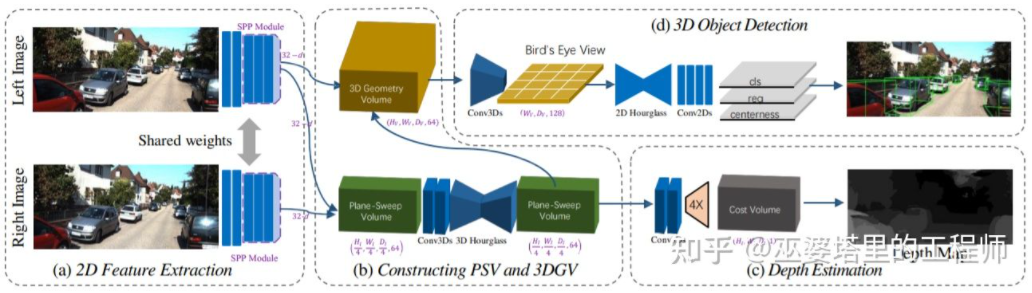
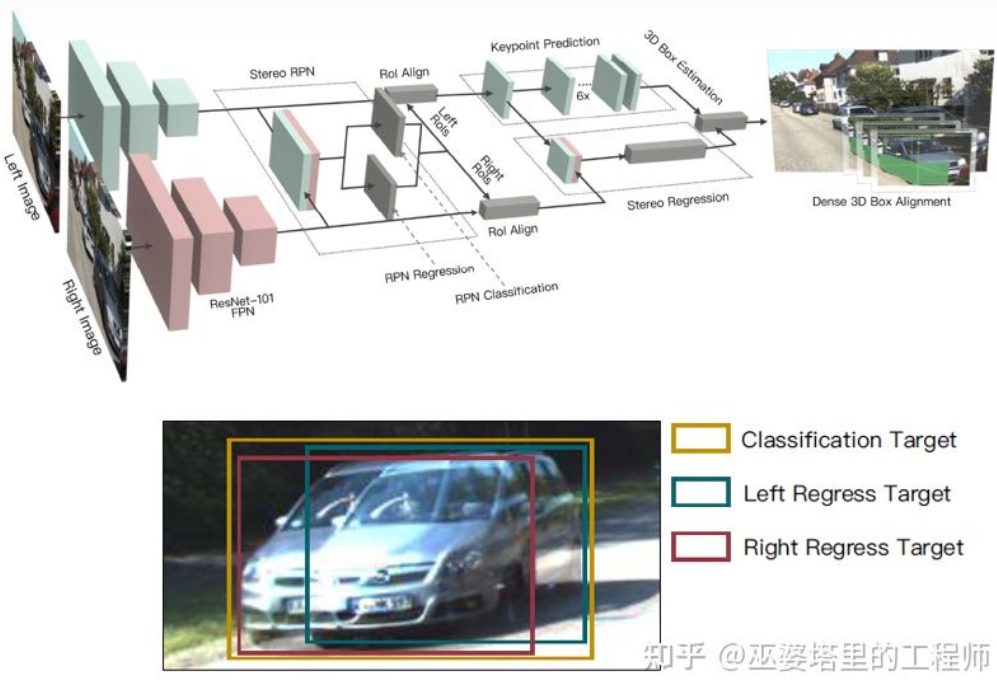
深度マップは実際、オブジェクト学習の場合、密な表現では、シーンのすべての位置で奥行き情報を取得する必要はなく、対象のオブジェクトの位置を推定するだけで済みます。同様のアイデアは、単眼アルゴリズムを導入したときに以前に言及されました。ステレオ R-CNN [27] は深度マップを推定しませんが、RPN のフレームワークの下で 2 台のカメラからの特徴マップをスタックしてオブジェクト候補を生成します。ここで、左右のカメラからの情報を関連付ける鍵となるのは、アノテーション データの変更です。下図のように、左右のラベルボックスに加えて、左右のラベルボックスの和集合も追加されます。左または右ボックスのいずれかで IoU が 0.7 を超えるアンカーはポジティブ サンプルとして使用され、ユニオン ボックスで IoU が 0.3 未満のアンカーはネガティブ サンプルとして使用されます。 Positive の Anchor は、左右のラベル ボックスの位置とサイズを同時に返します。この方法では、オブジェクト フレームに加えて、コーナー ポイントも補助として使用します。これらすべての情報を使用して、3D オブジェクトのフレームを復元できます。
はい 高密度シーン全体の深度推定は、物体の検出に悪影響を及ぼす可能性さえあります。たとえば、オブジェクトのエッジが背景と重なっているため、奥行き推定の偏差が大きく、シーン全体の奥行き範囲が広いこともアルゴリズムの速度に影響します。したがって、ステレオ RCNN と同様に、関心のあるオブジェクトのみで深度を推定し、オブジェクト上に点群のみを生成することも [28] で提案されています。これらのオブジェクト中心の点群は、最終的にオブジェクトの 3D 情報を予測するために使用されます。
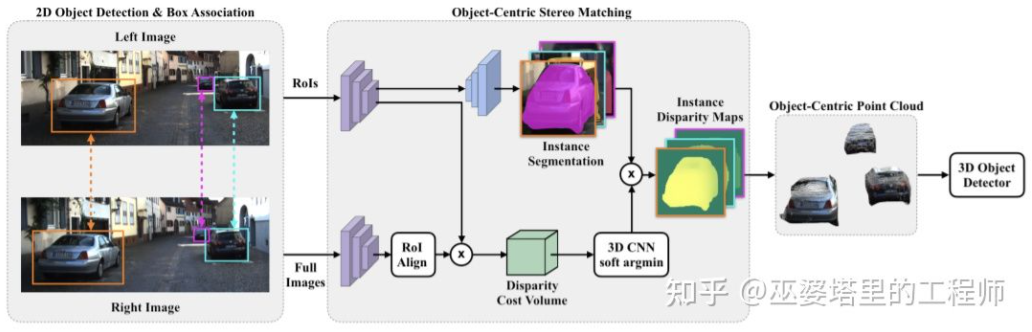 オブジェクト中心のステレオ マッチング
オブジェクト中心のステレオ マッチング
## 深度推定
単眼知覚アルゴリズムと同様に、奥行き推定も両眼知覚における重要なステップです。前のセクションの両眼オブジェクト検出の概要から判断すると、シーンレベルの奥行き推定やオブジェクトレベルの奥行き推定など、多くのアルゴリズムで奥行き推定が使用されています。以下は、両眼深度推定の基本原理といくつかの代表的な研究の簡単なレビューです。
双眼システムでは、f と B は固定されているため、視差である距離 d のみを推定する必要があります。ピクセルごとに、他の画像内で一致する点を見つけるだけで済みます。距離 d の範囲は限られているため、一致する検索範囲も限られます。考えられる d ごとに、各ピクセルでのマッチング誤差を計算できるため、コスト ボリュームと呼ばれる 3 次元誤差データが取得されます。マッチング誤差を計算するとき、通常、ピクセル付近の局所領域が考慮されます。最も簡単な方法の 1 つは、局所領域内のすべての対応するピクセル値の差を合計することです:
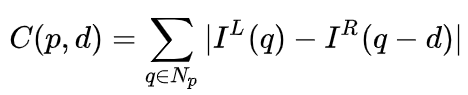

MC-CNN [29] は、マッチング プロセスを 2 つの画像パッチの類似性を計算するものとして形式化しています。画像パッチの特徴はニューラル ネットワークを通じて学習されます。データにラベルを付けることにより、トレーニング セットを構築できます。各ピクセルで、ポジティブ サンプルとネガティブ サンプルが生成され、各サンプルは画像パッチのペアになります。ポジティブ サンプルは、同じ 3D ポイント (同じ深さ) からの 2 つの画像ブロックであり、ネガティブ サンプルは、異なる 3D ポイント (異なる深さ) からの画像ブロックです。陰性サンプルには多くの選択肢がありますが、陽性サンプルと陰性サンプルのバランスを維持するために、1 つだけがランダムに抽出されます。正のサンプルと負のサンプルを使用して、類似性を予測するようにニューラル ネットワークをトレーニングできます。ここでの中心となるアイデアは、監視信号を使用してニューラル ネットワークをガイドし、タスクの照合に適した画像の特徴を学習することです。
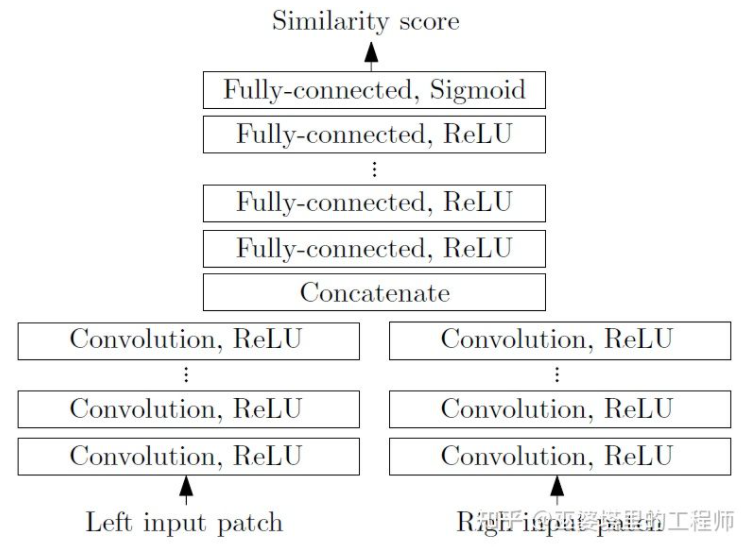
MC-CNN
MC- ネット1) コスト ボリュームの計算はローカル画像ブロックに依存しているため、テクスチャが少ない領域や繰り返しパターンのある一部の領域では大きなエラーが発生します、2) 後処理ステップは手動設計に依存しています。時間がかかるため、最適性を保証するのは困難です。 GC-Net[30] では、これら 2 つの点が改善されています。まず、意味論的な特徴をより適切に抽出するために、多層畳み込みおよびダウンサンプリング操作が左右の画像に対して実行されます。各視差レベル (ピクセル単位) に対して、左右の特徴マップが位置合わせ (ピクセル オフセット) され、結合されてその視差レベルの特徴マップが取得されます。すべての視差レベルの特徴マップは、4D コスト ボリューム (高さ、幅、視差、特徴) を取得するためにマージされます。コスト ボリュームには 1 つの画像からの情報のみが含まれており、画像間の相互作用はありません。したがって、次のステップでは、3D 畳み込みを使用してコスト ボリュームを処理し、左右の画像間の関連情報と異なる視差レベル間の情報を同時に抽出できるようにします。このステップの出力は 3D コスト ボリューム (高さ、幅、視差) です。最後に、最適な視差値を取得するには視差次元で Argmin を見つける必要がありますが、標準の Argmin を導出することはできません。 Soft Argmin は GC-Net で導出問題を解決するために使用され、ネットワーク全体をエンドツーエンドでトレーニングできるようになります。
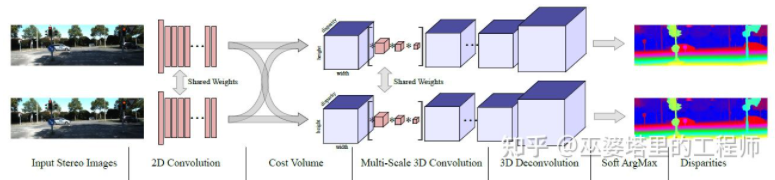
GC-Net
PSMNet[ 31 ] は GC-Net の構造と非常によく似ていますが、次の 2 つの点で改良されています。1) ピラミッド構造とアトラス コンボリューションを使用して多重解像度情報を抽出し、受容野を拡張します。グローバル機能とローカル機能の融合により、コスト量の推定もより正確になります。 2) 複数の砂時計構造を重ね合わせて 3D 畳み込みを強化します。グローバル情報の活用がさらに強化されます。一般に、PSMNet はグローバル情報の利用を改善し、視差推定がピクセル レベルのローカル情報ではなく、さまざまなスケールのコンテキスト情報に依存するようになりました。
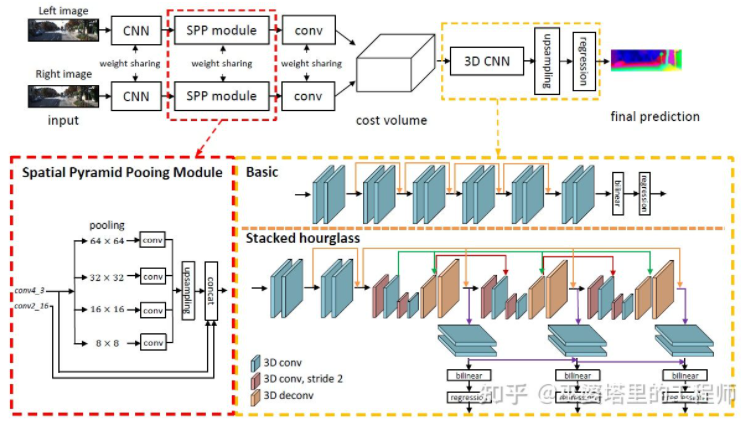
コスト ボリュームでは、視差レベルは離散 (ピクセル単位) です。ニューラル ネットワークが学習するのは、これらの離散点でのコスト分布であり、分布の極点が現在の位置に対応します。視差値。ただし、視差 (奥行き) 値は実際には連続的である必要があり、離散点を使用して推定すると誤差が生じます。連続推定の概念は CDN [32] で提案されており、離散点の分布に加えて、各点のオフセットも推定されます。離散点とオフセットが一緒になって連続的な視差推定を形成します。 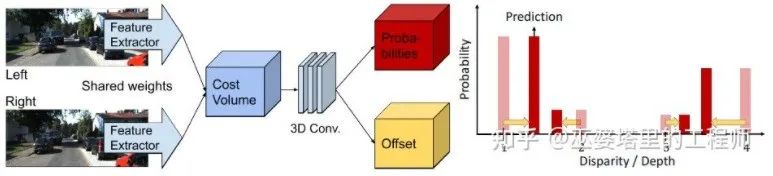
CDN
以上が自動運転のための 3D 視覚認識アルゴリズムの詳細な解釈の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



