

クライアント: このキーは存在しますか?
サーバー: 存在しません/わかりません
ブルーム フィルターは比較的賢い確率的データ構造であり、その本質はデータ構造です。効率的な挿入とクエリが特徴です。しかし、特定の構造にキーが存在するかどうかを確認したい場合、ブルームフィルターを使用すると、「このキーは存在してはいけない、または存在する可能性がある」ことがすぐにわかります。 List、Set、Map などの従来のデータ構造と比較すると、より効率的で使用するスペースが少なくなりますが、返される結果は確率的で不正確です。
ブルーム フィルターは、コレクション内のメンバーシップをテストするためにのみ使用されます。古典的なブルーム フィルターの例は、存在しないキーに対する高価なディスク (またはネットワーク) の検索を削減することで効率を向上させることです。ご覧のとおり、ブルーム フィルターは O(k) 定数時間 (k はハッシュ関数の数) でキーを検索でき、キーが存在しないことのテストは非常に高速になります。
アクセス効率を向上させるために、一部のデータを Redis キャッシュに置きます。データクエリを実行する場合、データベースを読み取ることなく、まずキャッシュからデータを取得できます。これにより、パフォーマンスを効果的に向上させることができます。
データをクエリする場合は、まずキャッシュにデータがあるかどうかを判断し、データがある場合はキャッシュから直接データを取得します。
ただし、データがない場合は、データベースからデータを取得してキャッシュに入れる必要があります。多数のアクセスがキャッシュにヒットしない場合、データベースに多大な負荷がかかり、データベースがクラッシュする原因になります。ブルーム フィルターを使用すると、存在しないキャッシュにアクセスするときに、すぐに戻ってキャッシュや DB のクラッシュを回避できます。
HBase には非常に大量のデータが格納されます。特定の ROWKEYS または特定の列が存在するかどうかを確認するには、ブルーム フィルターを使用します。特定のデータが存在するかどうかをすばやく取得します。しかし、一定の誤判断率は存在します。ただし、キーが存在しない場合は、正確である必要があります。
要素が存在するかどうかを判断するには、HashMap を使用すると効率が非常に高くなります。 HashMap は、値を HashMap キーにマッピングすることで、O(1) の定数時間計算量を実現できます。
ただし、保存されているデータの量が非常に多い場合 (例: 数億のデータ)、HashMap は非常に大量のメモリを消費します。そして、大量のデータを一度にメモリに読み込むことはまったく不可能です。
:
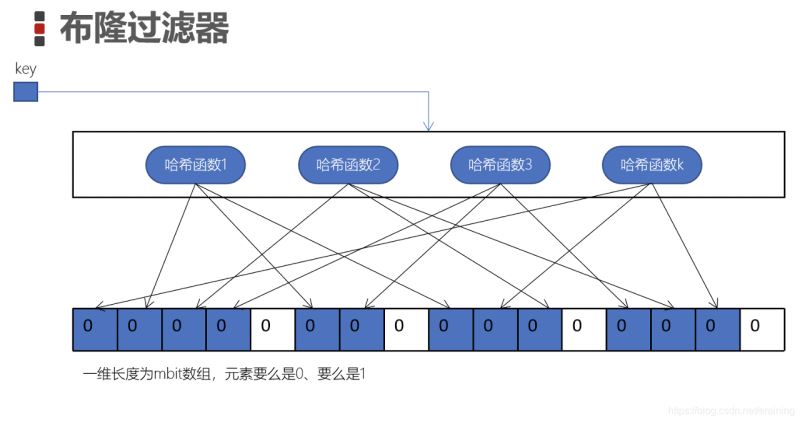
ブルーム フィルターはビット配列またはビット バイナリ ベクトルです
この配列の要素は 0 または 1 です。
k 個のハッシュ関数は互いに独立しており、各ハッシュ関数の計算結果は配列の長さ m を法として、対応するビットを 1 に設定します (青いセル)
このようにセルに各キーを設定します。これが「ブルームフィルター」です
キーがが入力されたら、前の k 個のハッシュ関数を使用してハッシュを見つけ、k 個の値を取得します。
k 個の値がすべて青であるかどうかを判断します。1 つが青でない場合、キーは存在してはなりません
両方とも青色の場合、キーが存在する可能性があります (ブルームフィルターにより誤判定が発生します)
入力オブジェクトが多く、セットが比較的小さい場合は、結果として、コレクション内のほとんどの位置が青色で塗りつぶされます。すると、あるキーが青にチェックされると、たまたまある位置が青に設定されてしまい、このときそのキーがコレクション内にあると誤解されてしまいます。
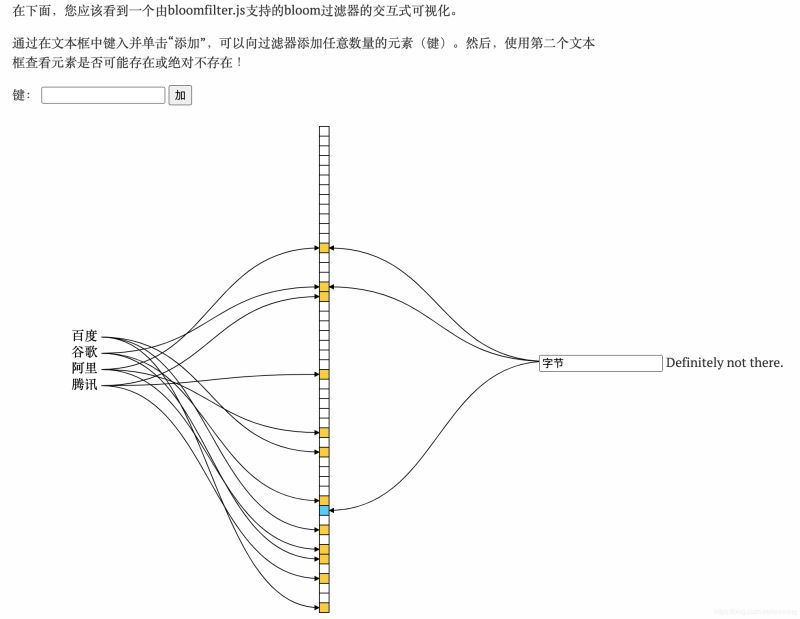
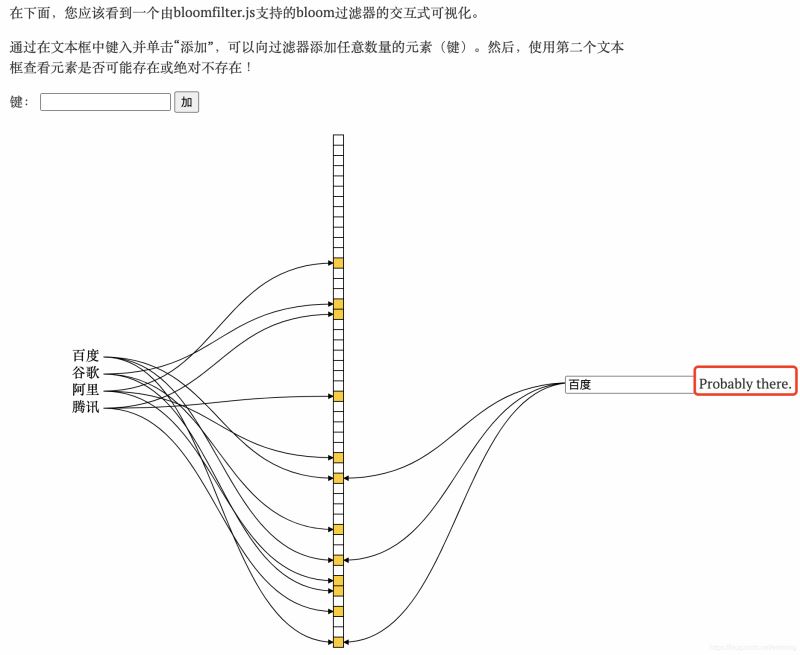 従来のブルーム フィルターは削除操作をサポートしていません。ただし、Counting Bloom フィルターと呼ばれるバリアントを使用すると、要素カウント数が特定のしきい値より絶対に小さいかどうかをテストでき、要素の削除がサポートされます。 Counting Bloom Filter の記事の原理と実装については非常に詳しく書かれており、詳しく読むことができます。
従来のブルーム フィルターは削除操作をサポートしていません。ただし、Counting Bloom フィルターと呼ばれるバリアントを使用すると、要素カウント数が特定のしきい値より絶対に小さいかどうかをテストでき、要素の削除がサポートされます。 Counting Bloom Filter の記事の原理と実装については非常に詳しく書かれており、詳しく読むことができます。
明らかに、ブルーム フィルターが小さすぎると、すぐにすべてのビットが 1 になり、その後は任意の値が可能になります。クエリを実行すると、すべてが「存在する可能性があります」を返します。これでは、フィルタリングの目的が無効になります。ブルーム フィルターの長さが増加するにつれて、その誤検出率は減少します。
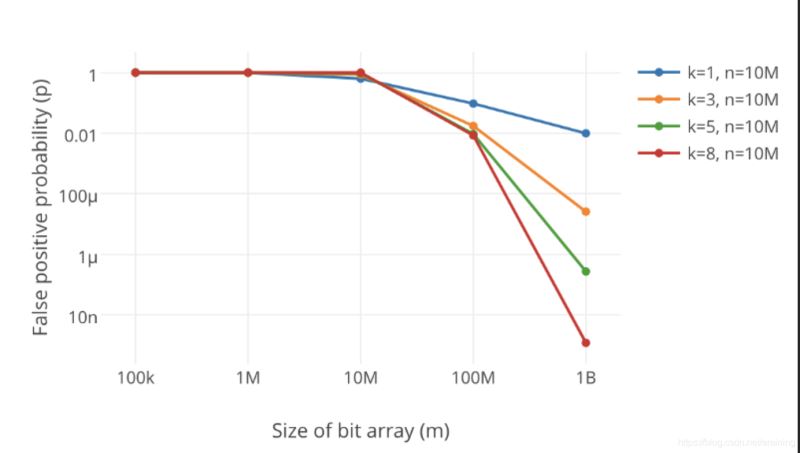
心配しないでください。実際には、m と k の値を確認する必要があります。次に、フォールト トレランス p と要素の数 n を指定すると、これらのパラメーターは次の式を使用して計算できます。
これらのパラメーターは、フィルターのサイズ m、ハッシュの数に基づいて計算できます。関数 k と挿入された要素の数 n 誤警報率 p を計算するための式は次のとおりです。 上記に基づいて、ビジネスに適した k と m の値をどのように選択するか?
式:
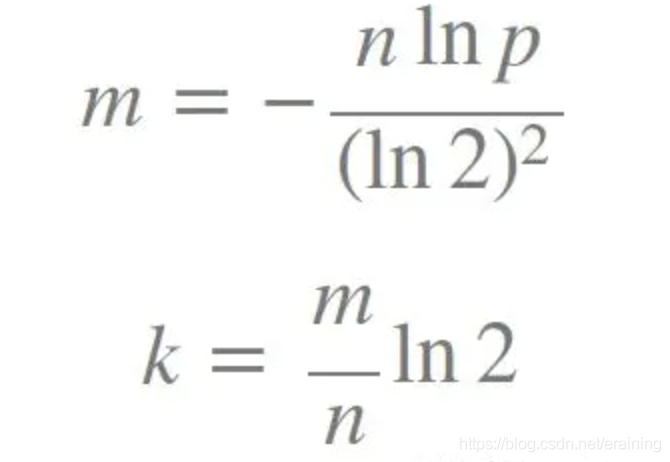
k はハッシュ関数の数、m はブルーム フィルターの長さ、n は挿入された要素の数、p は誤検知率です。
この公式の導出方法については、Zhihuに記事を掲載しましたので、興味のある方は読んでいただければと思いますが、興味のない方は上の公式を覚えておいてください。
ここでもう一つ重要な点についても触れておきたいと思います。ブルームフィルターを使用する唯一の目的は検索を高速化することなので、遅いハッシュ関数を使用することはできません。暗号化ハッシュ関数 (Sha-1、MD5 など) は少し遅いため、ブルーム フィルターには適していません。したがって、より高速なハッシュ関数実装のより良い選択肢は、murmur、fnv ファミリ ハッシュ、Jenkins ハッシュ、および HashMix です。
指定された例では、これを使用してユーザーに脆弱なパスワードを入力することを警告できることがわかりました。
ブルーム フィルターを使用すると、ユーザーが悪意のある Web サイトにアクセスするのを防ぐことができます。
SQL データベースにクエリを実行して、特定の電子メールを持つユーザーが存在するかどうかを確認する代わりに、まず Bloom ブルーム フィルターを使用して簡単な検索チェックを行うことができます。メールが存在しない場合でも問題ありません。存在する場合は、データベースに対して追加のクエリを実行する必要がある場合があります。同様の操作を行って、「ユーザー名はすでに使用されています」を検索することもできます。
Web サイト訪問者の IP アドレスに基づいてブルーム フィルターを保持し、Web サイトのユーザーが「リピーター」であるか「新規ユーザー」であるかを確認できます。 「リピーター」による誤検知がいくつかあったとしても、害を及ぼすことはありません。
ブルーム フィルターを使用して辞書の単語を追跡することで、スペル チェックを行うこともできます。
以上がRedis ブルーム フィルター サイズのアルゴリズム式は何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



