


ChatGPT などの会話型 AI の出現により、人々はテキスト、コード、または画像を入力すると、会話型ロボットがあなたの望む答えを返してくれるということに慣れてきました。しかし、この単純な対話方法の背後では、AI モデルは非常に複雑なデータ処理と計算を実行する必要があり、トークン化が一般的です。
自然言語処理の分野では、トークン化とは、テキスト入力を「トークン」と呼ばれる小さな単位に分割することを指します。これらのトークンは、特定の単語分割戦略とタスク要件に応じて、単語、サブワード、または文字になります。たとえば、「私はリンゴを食べるのが好きです」という文に対してトークン化を実行すると、[「私」、「好き」、「食べる」、「リンゴ」] という一連のトークンが得られます。トークン化を「単語の分割」と訳す人もいますが、この翻訳は誤解を招くと考える人もいますし、結局のところ、分割されたトークンは私たちが日常的に理解している「単語」ではない可能性があります。
出典: https://towardsdatascience.com/dynamic-word-tokenization-with-regex - tokenizer-801ae839d1cd
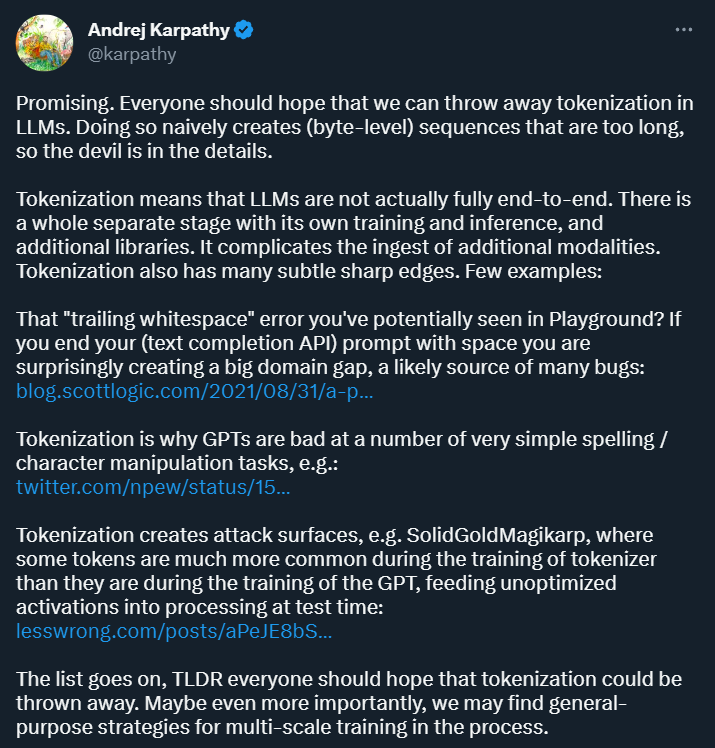
トークン化の目的は、入力データをコンピューターで処理できる形式に変換し、後続のモデルのトレーニングと分析のための構造化表現を提供することです。 。この方法はディープラーニング研究に利便性をもたらしますが、多くの問題ももたらします。少し前に OpenAI に加わったばかりの Andrej Karpathy 氏は、それらのいくつかを指摘しました。
まず第一に、Karpathy は、トークン化によって複雑さが生じると考えています。トークン化を使用すると、言語モデルは完全なエンドツーエンド モデルではなくなります。トークン化には別の段階が必要で、これには独自のトレーニングと推論プロセスがあり、追加のライブラリが必要です。これにより、他のモダリティからのデータを導入する際の複雑さが増大します。
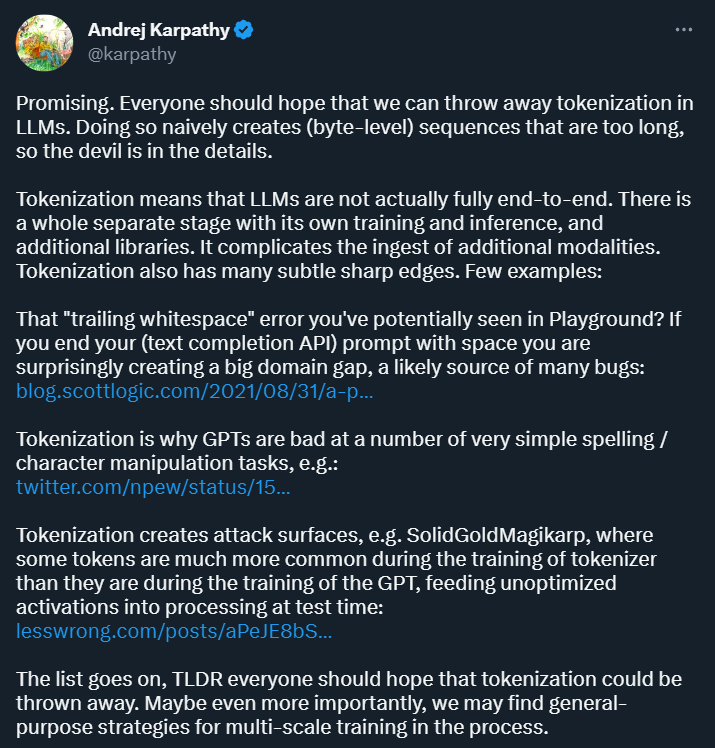
さらに、トークン化により、テキスト補完を使用する場合など、特定のシナリオでモデルにエラーが発生しやすくなります。完全な API では、プロンプトがスペースで終わっている場合、得られる結果は大きく異なる可能性があります。

画像ソース: https://blog.scottlogic.com/2021/08/31/a - primer-on-the-openai-api-1.html
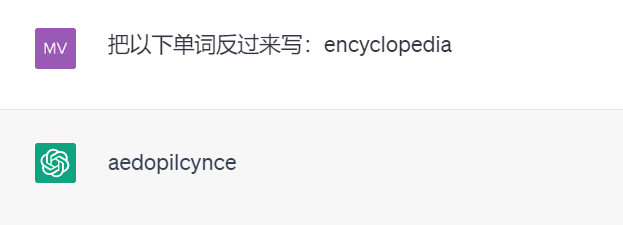
別の例として、トークン化が存在するため、強力な ChatGPT は実際には単語を逆に書きません (以下のテスト結果は GPT 3.5 によるものです)。
Meta AI によって発表された新しい論文では、この疑問について考察しています。具体的には、100万バイトを超えるシーケンスのエンドツーエンド微分可能モデリングを実行できる「MEGABYTE」と呼ばれるマルチスケールデコーダアーキテクチャを提案した。

重要なのは、この論文はトークン化を放棄する実現可能性を示しており、Karpathy によって「有望」と評価されたことです。
論文の詳細は次のとおりです。
論文の概要
NLP も同じ考えです。テキストはすべて「非構造化データ」です。まずこれらのデータを「構造化データ」に変換する必要があります。データ」では、構造化データを数学的問題に変換できます。単語の分割は変換の最初のステップです。
セルフアテンション メカニズムと大規模なフィードフォワード ネットワークのコストが高いため、大規模なトランス デコーダ (LLM) は通常、数千のコンテキスト トークンしか使用しません。これにより、LLM を適用できるタスクのセットが大幅に制限されます。
これに基づいて、Meta AI の研究者は、長いバイト シーケンスをモデル化するための新しい方法である MEGABYTE を提案しました。この方法では、トークンと同様に、バイト シーケンスを固定サイズのパッチに分割します。
MEGABYTE モデルは 3 つの部分で構成されています:
重要なことに、この研究では、多くのタスク (最初の数文字が与えられた単語を完成させるなど) では、ほとんどのバイトが比較的簡単に予測できることがわかりました。すべてのバイトに大規模なニューラル ネットワークを使用する必要がありますが、代わりにはるかに小さいモデルをパッチ内モデリングに使用できます。
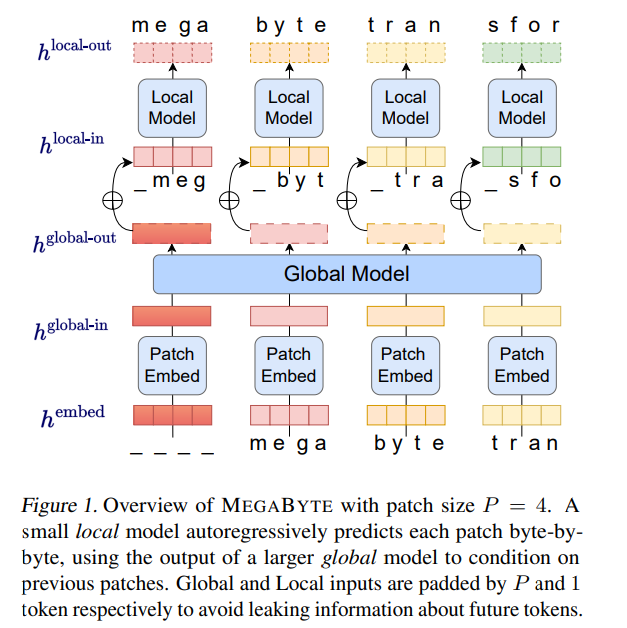
#MEGABYTE アーキテクチャでは、長いシーケンス モデリングのために Transformer に 3 つの大きな改善が加えられました。
二次二次自己注意。長いシーケンス モデルに関する研究のほとんどは、自己注意の二次コストを削減することに焦点を当てています。 MEGABYTE は、長いシーケンスを 2 つの短いシーケンスと最適なパッチ サイズに分解することにより、セルフ アテンション メカニズムのコストを 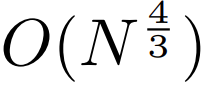 に削減し、長いシーケンスでも処理しやすくします。
に削減し、長いシーケンスでも処理しやすくします。
パッチごとのフィードフォワード レイヤー。 GPT-3 などの非常に大規模なモデルでは、FLOPS の 98% 以上が位置に関するフィードフォワード層の計算に使用されます。 MEGABYTE は、(位置ごとではなく) パッチごとに大規模なフィードフォワード レイヤーを使用することで、同じコストでより大規模で表現力豊かなモデルを実現します。パッチ サイズ P の場合、ベースライン トランスフォーマーは m パラメーターを持つ同じフィードフォワード レイヤーを P 回使用しますが、MEGABYTE は同じコストで mP パラメーターを持つレイヤーを 1 回使用するだけで済みます。
3. 並列デコード。各タイム ステップの入力は前のタイム ステップの出力であるため、変換器は生成中にすべての計算をシリアルに実行する必要があります。パッチ表現を並行して生成することにより、MEGABYTE は生成プロセスの並列性を向上させます。たとえば、1.5B パラメータを持つ MEGABYTE モデルは、標準の 350M パラメータ変換器よりも 40% 高速にシーケンスを生成すると同時に、同じ計算を使用してトレーニングした場合のパープレキシティも向上します。
全体として、MEGABYTE を使用すると、同じコンピューティング予算でより大規模でパフォーマンスの高いモデルをトレーニングでき、非常に長いシーケンスを処理できるようになり、デプロイ時の生成速度が向上します。
MEGABYTE は、通常、バイトのシーケンスがより大きな離散トークンにマッピングされる何らかの形式のトークン化を使用する既存の自己回帰モデルとも対照的です (Sennrich et al., 2015; Ramesh et al., 2021; Hsu et al., 2015)。 、2021)。トークン化により、前処理、マルチモーダル モデリング、新しいドメインへの転送が複雑になる一方で、モデル内の有用な構造が隠蔽されます。これは、ほとんどの SOTA モデルが真のエンドツーエンド モデルではないことを意味します。最も広く使用されているトークン化方法では、言語固有のヒューリスティックの使用 (Radford et al., 2019) または情報の損失 (Ramesh et al., 2021) が必要です。したがって、トークン化を効率的でパフォーマンスの高いバイト モデルに置き換えることには、多くの利点があります。
調査では、MEGABYTE といくつかの強力なベースライン モデルで実験が行われました。実験結果は、MEGABYTE がロングコンテキスト言語モデリングでサブワード モデルと同等の性能を発揮し、ImageNet で最先端の密度推定パープレキシティを実現し、生のオーディオ ファイルからのオーディオ モデリングを可能にすることを示しています。これらの実験結果は、大規模なトークン化のない自己回帰シーケンス モデリングの実現可能性を示しています。
##MEGABYTE の主要コンポーネント
パッチ エンベッダー
##サイズ P のパッチ エンベッダーは、バイト シーケンス
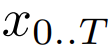 を長さ # にマッピングできます。
を長さ # にマッピングできます。
## およびディメンション 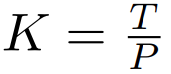
##。
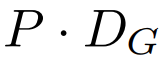
#まず、各バイトがルックアップ テーブルに埋め込まれます
,サイズ D_G の埋め込みを形成し、位置的な埋め込みを追加します。
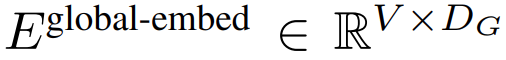
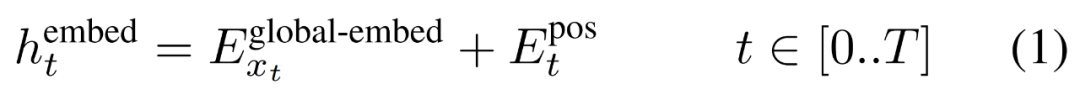 次に、バイト埋め込みは
次に、バイト埋め込みは
に埋め込まれた K 個のパッチのシーケンス。自己回帰モデリングを可能にするために、パッチ シーケンスはトレーニング可能なパッチ サイズからのパディング埋め込み (
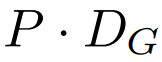
) でパディングされ、入力から最後のパッチ。このシーケンスはグローバル モデルへの入力であり、
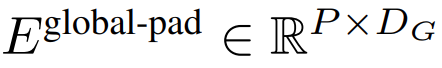
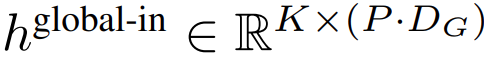
## として表されます。
グローバルモジュール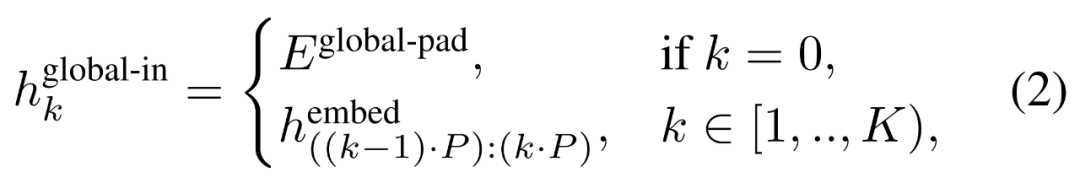
グローバル モジュールはデコーダ専用アーキテクチャの P・D_G 次元トランスフォーマー モデルであり、k 個のパッチ シーケンスで動作します。グローバル モジュールは、セルフ アテンション メカニズムと因果マスクを組み合わせて、パッチ間の依存関係をキャプチャします。グローバル モジュールは、k 個のパッチ シーケンス
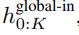
## を出力します。
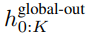
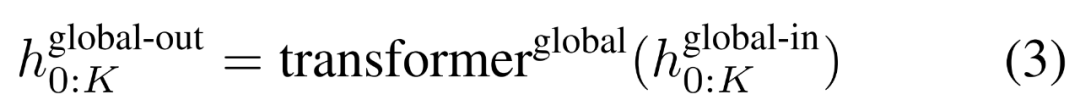
P・D_G 寸法の K 個のパッチ表現が含まれています。これらのそれぞれについて、長さ P と次元 D_G のシーケンスに再形成します。ここで、位置 p は次元 p・D_G から (p 1)・D_G を使用します。次に、各場所は行列 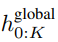
を使用してローカル モジュールの次元にマップされます。ここで、D_L はローカル モジュールの次元です。これらは、次の 
トークンのサイズ D_L のバイト埋め込みと結合されます。 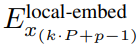
ローカル バイト エンベディングは、トレーニング可能なローカル パッド エンベディング (E^local-pad ∈ R^DL) によって 1 オフセットされ、パス内自己回帰が可能になります。モデリング。最後にテンソルを取得します
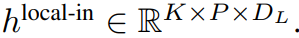
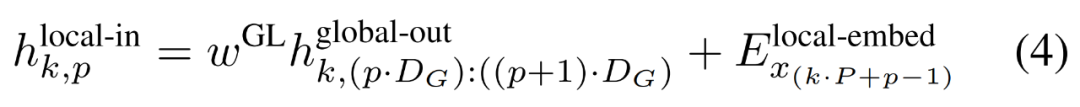 ローカル モジュール
ローカル モジュール
ローカル モジュールは、P 要素を含む、より小型のデコーダ専用アーキテクチャ D_L 次元トランスフォーマー モデルです。単一のパッチで実行されます。 k、各要素は、グローバル モジュール出力とシーケンス内の前のバイトの埋め込みの合計です。ローカル モジュールの K 個のコピーが各パッチで独立して、トレーニング中に並行して実行されるため、表現
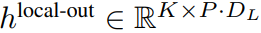 # が計算されます。
# が計算されます。
#最後に、研究者は各位置の語彙確率分布を計算できます。 k 番目のパッチの p 番目の要素は、完全なシーケンスの要素 t に対応します。ここで、t = k・P p です。

#効率分析
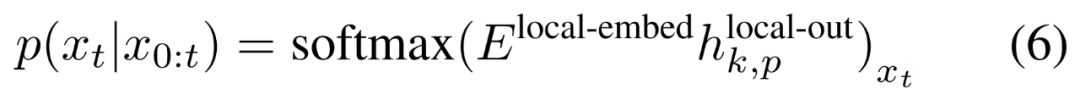 トレーニング効率
トレーニング効率
研究者らは、シーケンスの長さとモデルのサイズをスケーリングする際のさまざまなアーキテクチャのコストを分析しました。以下の図 3 に示すように、MEGABYTE アーキテクチャは、さまざまなモデル サイズとシーケンス長にわたって、同等のサイズのトランスや線形トランスよりも FLOPS が少ないため、同じ計算コストでより大きなモデルを使用できます。
#発電効率
次のようなことを検討してください。グローバル モデルに L_global 層、ローカル モジュールに L_local 層があり、パッチ サイズが P の MEGABYTE モデルを、L_local L_global 層を備えたトランスフォーマ アーキテクチャと比較します。 MEGABYTE で各パッチを生成するには、O (L_global P・L_local) シーケンスのシリアル操作が必要です。 L_global ≥ L_local (グローバル モジュールにはローカル モジュールより多くのレイヤーがある) の場合、MEGABYTE は推論コストをほぼ P 倍削減できます。
実験結果言語モデリング
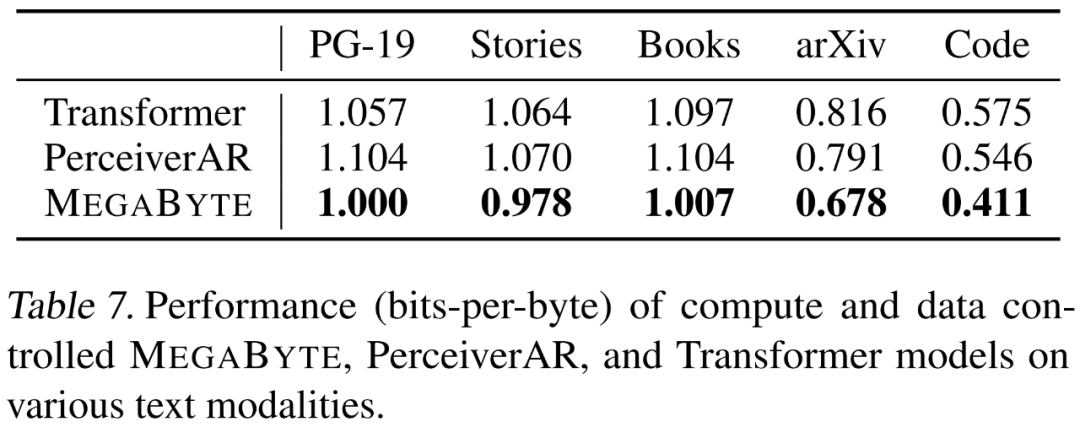
研究者らは、長期依存の 5 つの側面を強調しています。 MEGABYTE の言語モデリング機能は、Project Gutenberg (PG-19)、Books、Stories、arXiv、Code などのさまざまなデータ セットで評価されました。結果は以下の表 7 に示されており、MEGABYTE はすべてのデータセットでベースライン トランスフォーマーと PerceiverAR を一貫して上回っています。
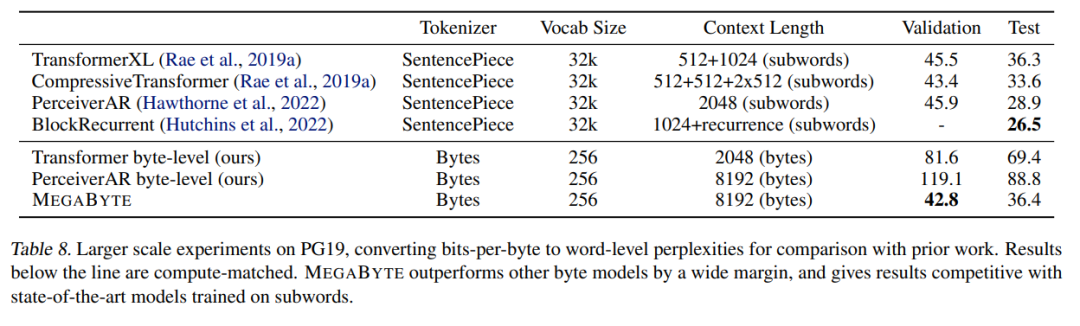
研究者らは、PG-19 のトレーニング データも拡張しました。結果を以下の表 8 に示します。他のバイト モデルよりも優れたパフォーマンスを示し、サブワードでトレーニングされた SOTA モデルに匹敵します。
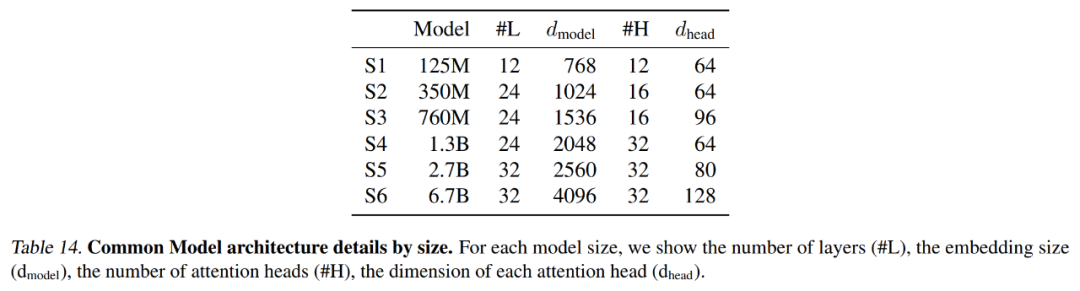
#画像モデリング
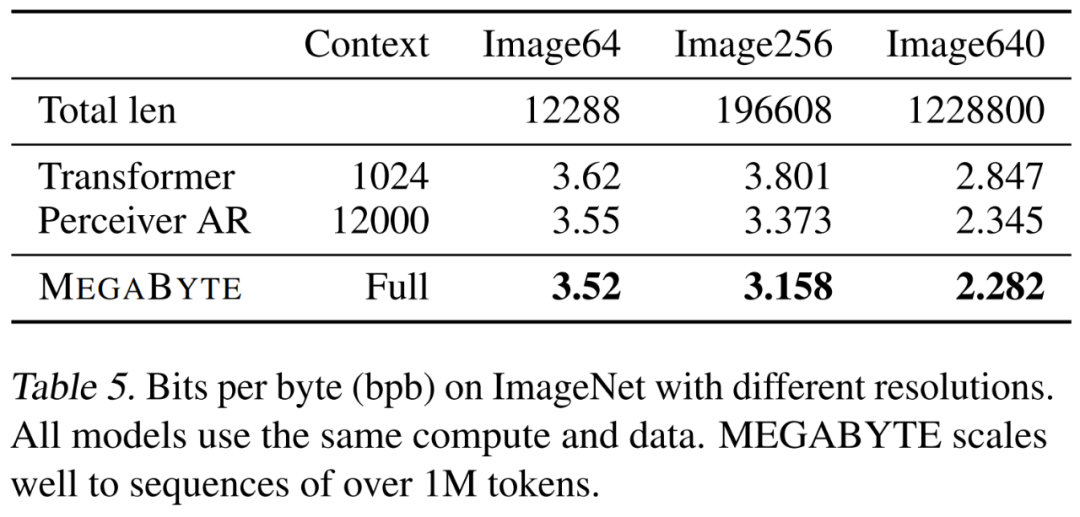
研究者 A 大MEGABYTE モデルは ImageNet 64x64 データ セットでトレーニングされました。グローバル モジュールとローカル モジュールのパラメーターはそれぞれ 2.7B と 350M で、1.4T のトークンがあります。彼らは、モデルのトレーニングにかかる時間は、Hawthorne et al., 2022 の論文で最良の PerceiverAR モデルを再現するのに必要な GPU 時間の半分未満であると推定しています。上記の表 8 に示すように、MEGABYTE は PerceiverAR の SOTA と同等のパフォーマンスを備えていますが、後者の計算の半分しか使用していません。私たちは、3 つのトランスフォーマー バリアント、つまり vanilla、PerceiverAR、および MEGABYTE を比較して、ますます大きな画像解像度での長いシーケンスのスケーラビリティをテストしました。結果は以下の表 5 に示されており、この計算制御設定の下では、MEGABYTE はすべての解像度でベースライン モデルを上回っています。
オーディオ兼テキストのシーケンス構造と画像の連続的な性質を考慮した、これは MEGABYTE にとって興味深いアプリケーションです。この記事のモデルでは 3.477 の bpb が得られましたが、これは PerperrAR (3.543) やバニラ トランスフォーマー モデル (3.567) よりも大幅に低くなります。さらなるアブレーション結果を以下の表10に詳述する。
#技術的な詳細と実験結果については、元の論文を参照してください。 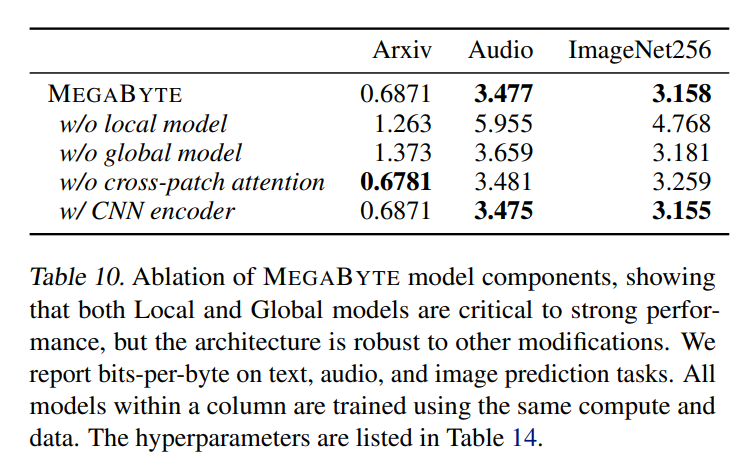
以上が「分詞」は必要ですか?アンドレイ・カルパシー: この歴史的な荷物を捨てる時が来たの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



