


大規模な言語モデルには素晴らしい機能がありますが、規模が大きいため、その展開に必要なコストが膨大になることがよくあります。ワシントン大学は、Google Cloud Computing Artificial Intelligence Research Institute および Google Research と協力して、この問題をさらに解決し、モデルのトレーニングを支援するステップバイステップ蒸留パラダイムを提案しました。 LLM と比較して、この方法は小さなモデルをトレーニングして特定のタスクに適用する場合に効果的であり、従来の微調整や蒸留よりも必要なトレーニング データが少なくなります。ベンチマーク タスクでは、770M T5 モデルが 540B PaLM モデルよりも優れたパフォーマンスを示しました。印象的なことに、彼らのモデルは利用可能なデータの 80% しか使用していませんでした。

大規模言語モデル (LLM) は優れた少数ショット学習を実証していますが、しかし、このような大規模なモデルを実際のアプリケーションに展開することは困難です。 1,750 億パラメータ規模の LLM に対応する専用インフラストラクチャには、少なくとも 350 GB の GPU メモリが必要です。さらに、今日の最先端の LLM は 5,000 億を超えるパラメータで構成されており、より多くのメモリとコンピューティング リソースが必要になります。このようなコンピューティング要件は、低遅延を必要とするアプリケーションはもちろんのこと、ほとんどのメーカーにとっては手の届かないものです。
大規模モデルの問題を解決するために、デプロイ担当者は多くの場合、代わりに小規模な特定のモデルを使用します。これらの小さなモデルは、微調整や蒸留などの一般的なパラダイムを使用してトレーニングされます。微調整では、人間が注釈を付けた下流のデータを使用して、事前トレーニングされた小規模なモデルをアップグレードします。蒸留では、より大きな LLM によって生成されたラベルを使用して、同様に小さなモデルをトレーニングします。残念ながら、これらのパラダイムにはモデル サイズを縮小する一方でコストがかかります。LLM と同等のパフォーマンスを達成するには、微調整には高価な人間によるラベルが必要であり、蒸留には入手が困難な大量のラベルなしデータが必要です。
「Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes」というタイトルの論文で、ワシントン大学と Google の研究者が新しいシンプルなメカニズムを発表しました。 , ステップバイステップの蒸留は、より少ないトレーニング データを使用して小規模なモデルをトレーニングするために導入されています。このメカニズムにより、LLM の微調整と抽出に必要なトレーニング データの量が削減され、その結果、モデル サイズが小さくなります。

#紙のリンク: https://arxiv.org/pdf/2305.02301 v1.pdf
#このメカニズムの核心は、視点を変えて、LLM をノイズ ラベルのソースとしてではなく、推論できるエージェントとしてみなすことです。 LLM は、モデルによって予測されたラベルを説明およびサポートするために使用できる自然言語の理論的根拠を生成できます。たとえば、「紳士はゴルフ用品を持ち歩いていますが、何を持っていると思いますか? (a) クラブ、(b) 講堂、(c) 瞑想センター、(d) 会議、(e) 教会」と質問された場合、LLM は「(a)」と答えることができます。 ) クラブ」を思考連鎖 (CoT) 推論によって解釈し、「答えはゴルフをプレイするために使用されるものに違いない」と説明することでこのラベルを合理化します。上記の選択肢のうち、ゴルフに使用するクラブのみです。これらの位置合わせを、マルチタスク トレーニング設定で小規模なモデルをトレーニングし、ラベル予測と位置合わせ予測を実行するための追加の豊富な情報として使用します。
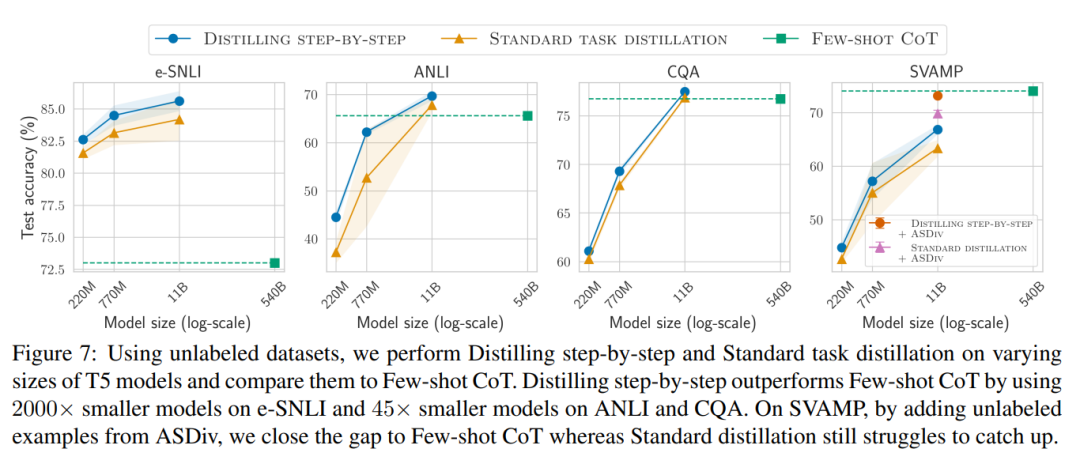
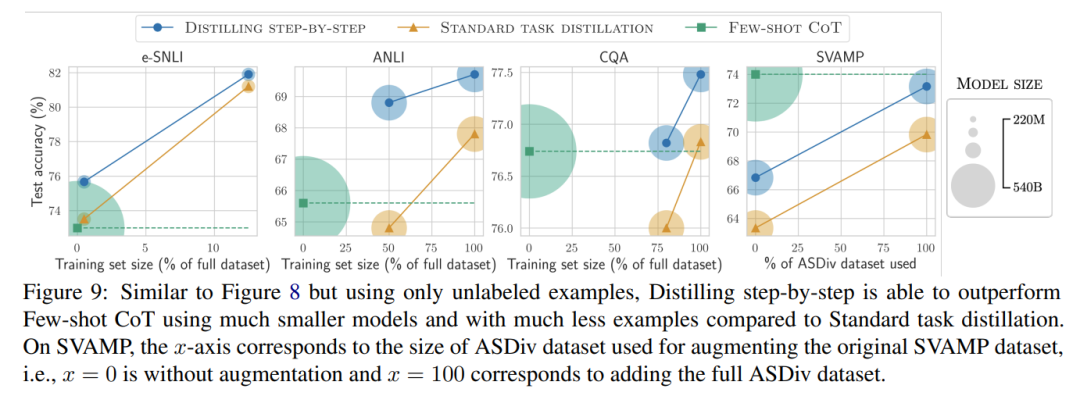
図 1 に示すように、段階的蒸留では、LLM の 1/500 未満のパラメーター数でタスク固有の小さなモデルを学習できます。また、段階的蒸留では、従来の微調整や蒸留よりもはるかに少ないトレーニング サンプルを使用します。

ラベルのないデータのみがある場合、小規模モデルのパフォーマンスは LLM のパフォーマンスより優れています。11B T5 モデルを使用した場合のみ、540B の PaLM のパフォーマンスを超えます。改善されました。
研究ではさらに、小規模なモデルのパフォーマンスが LLM よりも悪い場合、段階的蒸留の方が標準的な蒸留方法よりも追加のラベルなしデータを効果的に利用できることが示されています。LLM のパフォーマンスと同等の小規模なモデルを作成します。
研究者らは、LLM の推論能力を使用して予測を予測し、データ効率の高い方法で小規模なモデルをトレーニングする、段階的蒸留の新しいパラダイムを提案しました。マナー、モデル。全体的なフレームワークを図 2 に示します。
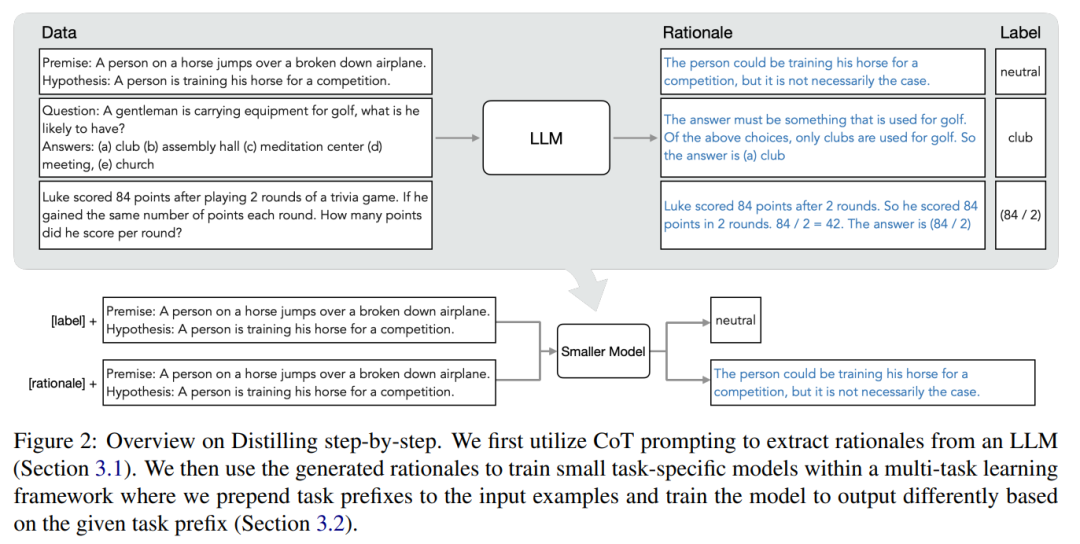
パラダイムには 2 つの簡単なステップがあります。まず、LLM とラベルのないデータを与えます。 set は、LLM に出力ラベルとラベルの位置揃えを生成するように指示します。理論的根拠は自然言語で説明され、モデルによって予測されたラベルのサポートを提供します (図 2 を参照)。正当化は、現在の自己教師あり LLM の新たな動作特性です。
次に、タスク ラベルに加えて、これらの理由を使用して、より小さな下流モデルをトレーニングします。率直に言って、理由は、入力が特定の出力ラベルにマップされる理由を説明するための、より豊富で詳細な情報を提供します。
研究者らは、実験で段階的蒸留の有効性を検証しました。まず、標準的な微調整およびタスク蒸留手法と比較して、段階的蒸留ははるかに少ない数のトレーニング サンプルでより優れたパフォーマンスを達成するのに役立ち、小さなタスク固有のモデルを学習する際のデータ効率が大幅に向上します。
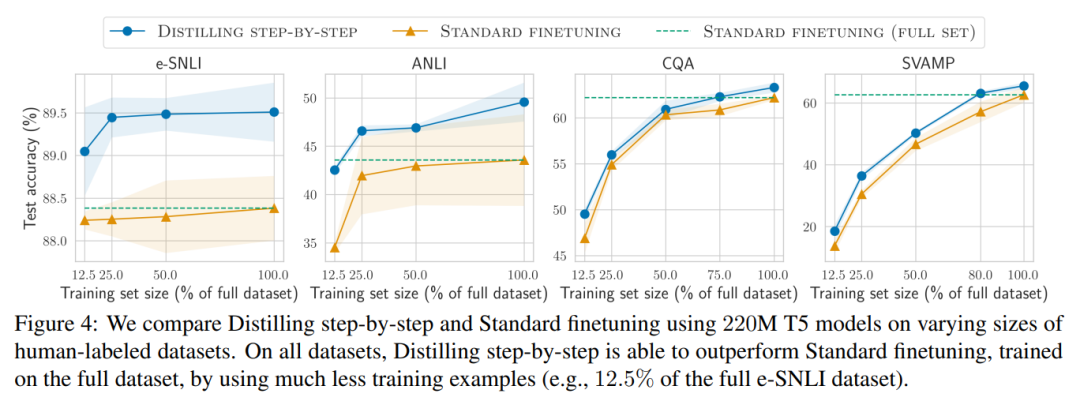
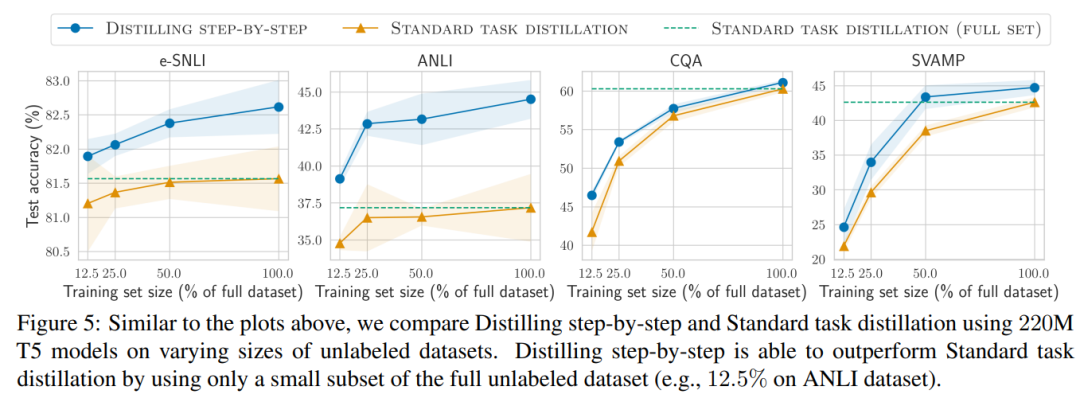
#第二に、研究は次のことを示しています。段階的蒸留方法は、より小さいモデル サイズで LLM のパフォーマンスを上回り、LLM と比較して導入コストが大幅に削減されることがわかりました。
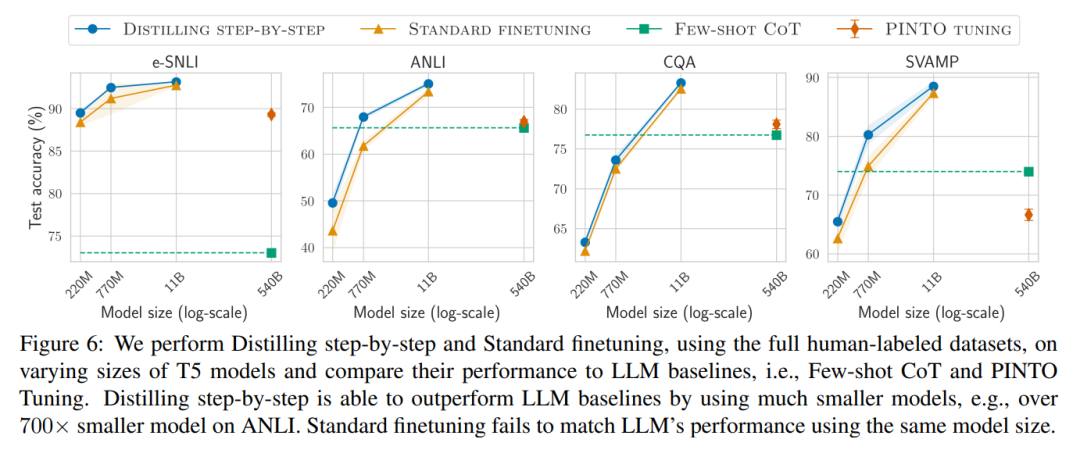
#
以上が蒸留は段階的に行うこともできます。新しい方法により、小型モデルを 2000 倍のサイズの大型モデルと同等にできるようになります。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



