Python組み込み型strソースコード解析

1 Unicode
コンピュータ ストレージの基本単位は 8 ビットで構成されるバイトです。英語は 26 文字といくつかの記号のみで構成されているため、英語の文字はバイト単位で直接格納できます。ただし、他の言語 (中国語、日本語、韓国語など) では、文字数が多いため、エンコードに複数のバイトを使用する必要があります。
コンピューター技術の普及に伴い、非ラテン文字エンコーディング技術は発展を続けていますが、依然として 2 つの大きな制限があります。
複数の言語をサポートしていません。ある言語のエンコード スキームを別の言語に使用することはできません
統一された標準はありません。たとえば、中国語には GBK、GB2312、GB18030
などの複数のエンコード標準があります。
エンコード方式が統一されていないため、開発者は異なるエンコード間で変換を行ったり来たりする必要があり、必然的に多くのエラーが発生します。このような不一致の問題を解決するために、Unicode 標準が提案されました。 Unicode は、世界中のほとんどの書記体系を整理してエンコードし、コンピュータが統一された方法でテキストを処理できるようにします。 Unicode には現在 140,000 文字以上が含まれており、当然ながら複数の言語をサポートしています。 (Unicode の uni は「unification」の語源です)
2 Python における Unicode
2.1 Unicode オブジェクトの利点
Python 3 以降、Unicode は str オブジェクトの内部で使用されます。を表すため、ソース コードでは Unicode オブジェクトになります。 Unicode 表現を使用する利点は、プログラムのコア ロジックが Unicode を均一に使用し、入力層と出力層でのみデコードおよびエンコードする必要があるため、さまざまなエンコードの問題を最大限に回避できることです。
図は次のとおりです:

>>> sys.getsizeof('ab') - sys.getsizeof('a') 1 >>> sys.getsizeof('一二') - sys.getsizeof('一') 2 >>> sys.getsizeof('????????') - sys.getsizeof('????') 4テキストの内容に従って、Python が内部的に Unicode オブジェクトを最適化していることがわかります。 、基礎となるストレージユニットが選択されます。 Unicode オブジェクトの基礎となるストレージは、テキスト文字の Unicode コード ポイント範囲に従って 3 つのカテゴリに分類されます:
- PyUnicode_1BYTE_KIND: すべての文字コード ポイントは U 0000 の間にあります。および U 00FF
- PyUnicode_2BYTE_KIND: すべての文字コード ポイントが U 0000 から U FFFF の間にあり、少なくとも 1 つの文字のコード ポイントが U 00FF## より大きい #PyUnicode_1BYTE_KIND: すべての文字コード ポイントは U 0000 ~ U 10FFFF であり、少なくとも 1 つの文字のコード ポイントが U FFFF
- ##対応する列挙は次のとおりです。 ##
enum PyUnicode_Kind { /* String contains only wstr byte characters. This is only possible when the string was created with a legacy API and _PyUnicode_Ready() has not been called yet. */ PyUnicode_WCHAR_KIND = 0, /* Return values of the PyUnicode_KIND() macro: */ PyUnicode_1BYTE_KIND = 1, PyUnicode_2BYTE_KIND = 2, PyUnicode_4BYTE_KIND = 4 };さまざまな分類に従って、さまざまなストレージ ユニットを選択します:
/* Py_UCS4 and Py_UCS2 are typedefs for the respective unicode representations. */ typedef uint32_t Py_UCS4; typedef uint16_t Py_UCS2; typedef uint8_t Py_UCS1;
対応する関係は次のとおりです:
テキスト タイプ| 文字ストレージ ユニット サイズ (バイト) | PyUnicode_1BYTE_KIND | |
|---|---|---|
| 1 | ##PyUnicode_2BYTE_KIND | |
| 2 | PyUnicode_4BYTE_KIND | |
| 4 | Unicode の内部ストレージ構造はテキスト タイプによって異なるため、タイプの種類は Unicode オブジェクトのパブリック フィールドとして保存する必要があります。 Python は内部的にいくつかのフラグ ビットを Unicode パブリック フィールドとして定義します: (作成者のレベルが限られているため、ここにあるすべてのフィールドは後続のコンテンツでは紹介されません。これについては後ほど自分で学ぶことができます。頑張ってください~) |
interned: interned メカニズムを維持するかどうか
kind: type、基礎となる文字の記憶単位のサイズを区別するために使用されます
compact: メモリ割り当て方法、オブジェクトとテキスト バッファーが分離されているかどうか
asscii: テキストがすべて純粋な ASCII かどうか
-
PyUnicode_New 関数を通じて、テキスト文字数のサイズと最大文字数に従って、maxchar が Unicode オブジェクトを初期化します。この関数は主に、maxchar に基づいて最もコンパクトな文字格納ユニットと Unicode オブジェクトの基礎となる構造を選択します。 (ソース コードは比較的長いため、ここには記載しません。ご自身で理解してください。以下の表形式で示します) )
| 128 <= maxchar < 256 | 256 <= maxchar < 65536 | 65536 <= maxchar < MAX_UNICODE | ||
|---|---|---|---|---|
| PyUnicode_1BYTE_KIND | PyUnicode_2BYTE_KIND | PyUnicode_4BYTE_KIND | ascii | |
| 0 | 0 | 0 | 文字格納単位サイズ (バイト) | |
| 1 | 2 | 4 | 基礎構造 | |
| PyCompactUnicodeObject | PyCompactUnicodeObject | PyCompactUnicodeObject | 3 Unicode对象的底层结构体3.1 PyASCIIObjectC源码: typedef struct {
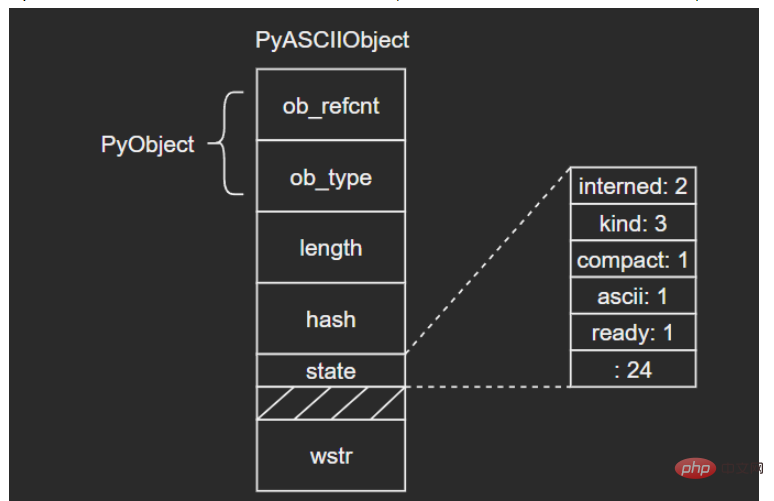
PyObject_HEAD
Py_ssize_t length; /* Number of code points in the string */
Py_hash_t hash; /* Hash value; -1 if not set */
struct {
unsigned int interned:2;
unsigned int kind:3;
unsigned int compact:1;
unsigned int ascii:1;
unsigned int ready:1;
unsigned int :24;
} state;
wchar_t *wstr; /* wchar_t representation (null-terminated) */
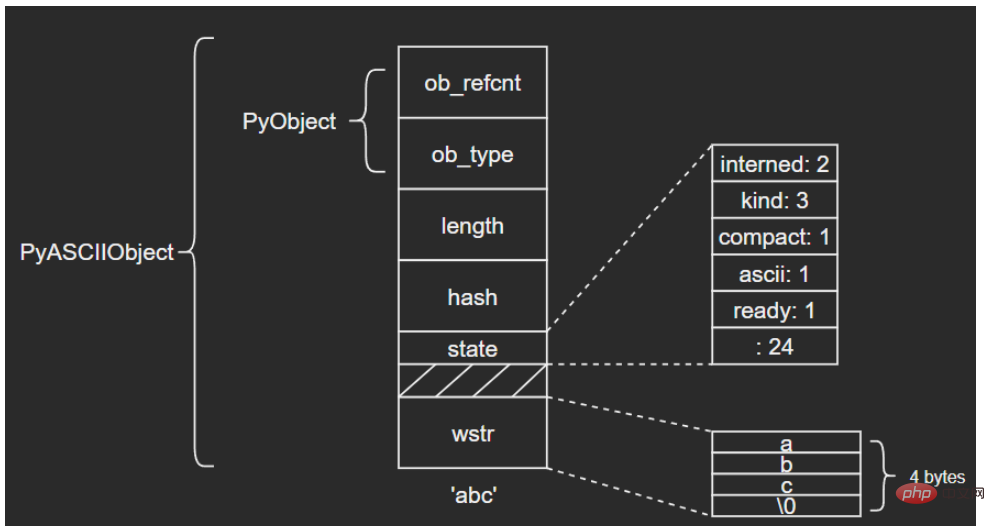
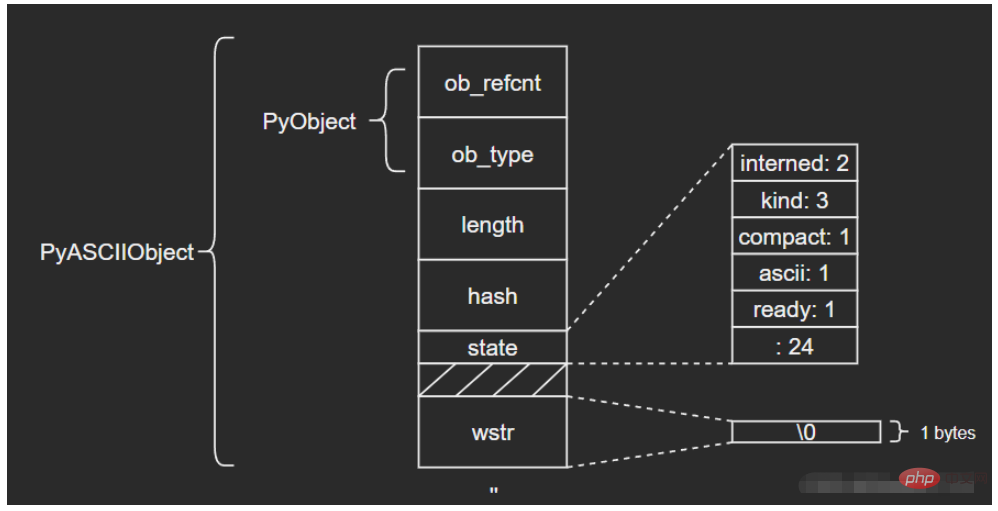
} PyASCIIObject;源码分析: length:文本长度 hash:文本哈希值 state:Unicode对象标志位 wstr:缓存C字符串的一个wchar_t指针,以“\0”结束(这里和我看的另一篇文章讲得不太一样,另一个描述是:ASCII文本紧接着位于PyASCIIObject结构体后面,我个人觉得现在的这种说法比较准确,毕竟源码结构体后面没有别的字段了) 图示如下: (注意这里state字段后面有一个4字节大小的空洞,这是结构体字段内存对齐造成的现象,主要是为了优化内存访问效率)
ASCII文本由wstr指向,以’abc’和空字符串对象’'为例:
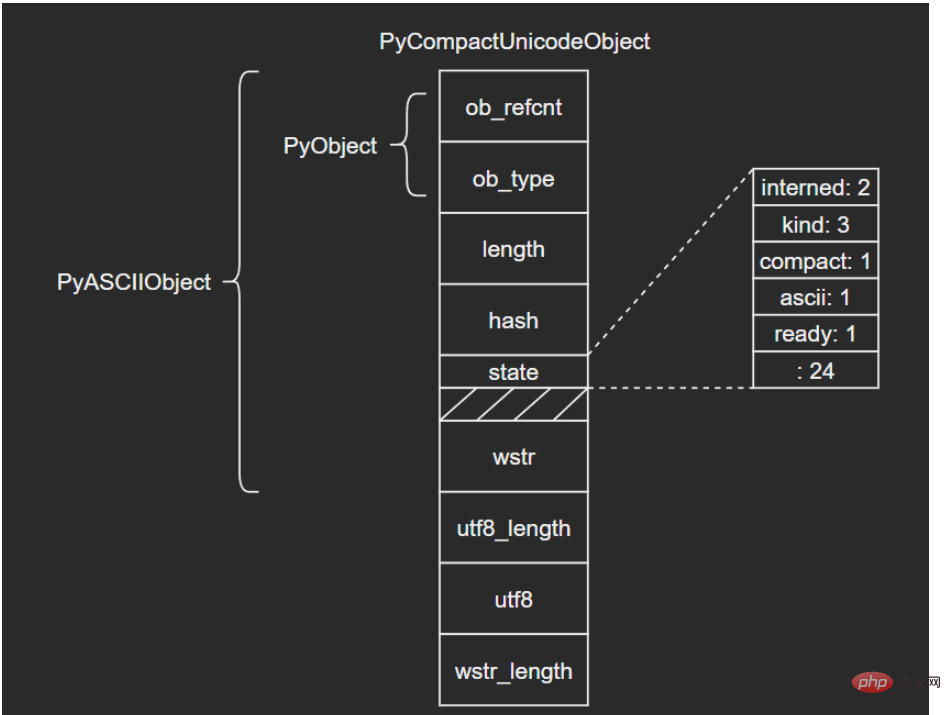
3.2 PyCompactUnicodeObject如果文本不全是ASCII,Unicode对象底层便由PyCompactUnicodeObject结构体保存。C源码如下: /* Non-ASCII strings allocated through PyUnicode_New use the
PyCompactUnicodeObject structure. state.compact is set, and the data
immediately follow the structure. */
typedef struct {
PyASCIIObject _base;
Py_ssize_t utf8_length; /* Number of bytes in utf8, excluding the
* terminating \0. */
char *utf8; /* UTF-8 representation (null-terminated) */
Py_ssize_t wstr_length; /* Number of code points in wstr, possible
* surrogates count as two code points. */
} PyCompactUnicodeObject;PyCompactUnicodeObject在PyASCIIObject的基础上增加了3个字段: utf8_length:文本UTF8编码长度 utf8:文本UTF8编码形式,缓存以避免重复编码运算 wstr_length:wstr的“长度”(这里所谓的长度没有找到很准确的说法,笔者也不太清楚怎么能打印出来,大家可以自行研究下) 注意到,PyASCIIObject中并没有保存UTF8编码形式,这是因为ASCII本身就是合法的UTF8,这也是ASCII文本底层由PyASCIIObject保存的原因。 结构图示:
3.3 PyUnicodeObjectPyUnicodeObject则是Python中str对象的具体实现。C源码如下: /* Strings allocated through PyUnicode_FromUnicode(NULL, len) use the
PyUnicodeObject structure. The actual string data is initially in the wstr
block, and copied into the data block using _PyUnicode_Ready. */
typedef struct {
PyCompactUnicodeObject _base;
union {
void *any;
Py_UCS1 *latin1;
Py_UCS2 *ucs2;
Py_UCS4 *ucs4;
} data; /* Canonical, smallest-form Unicode buffer */
} PyUnicodeObject;3.4 示例在日常开发时,要结合实际情况注意字符串拼接前后的内存大小差别: >>> import sys >>> text = 'a' * 1000 >>> sys.getsizeof(text) 1049 >>> text += '????' >>> sys.getsizeof(text) 4080 4 interned机制如果str对象的interned标志位为1,Python虚拟机将为其开启interned机制, 源码如下:(相关信息在网上可以看到很多说法和解释,这里笔者能力有限,暂时没有找到最确切的答案,之后补充。抱拳~但是我们通过分析源码应该是能看出一些门道的) /* This dictionary holds all interned unicode strings. Note that references
to strings in this dictionary are *not* counted in the string's ob_refcnt.
When the interned string reaches a refcnt of 0 the string deallocation
function will delete the reference from this dictionary.
Another way to look at this is that to say that the actual reference
count of a string is: s->ob_refcnt + (s->state ? 2 : 0)
*/
static PyObject *interned = NULL;
void
PyUnicode_InternInPlace(PyObject **p)
{
PyObject *s = *p;
PyObject *t;
#ifdef Py_DEBUG
assert(s != NULL);
assert(_PyUnicode_CHECK(s));
#else
if (s == NULL || !PyUnicode_Check(s))
return;
#endif
/* If it's a subclass, we don't really know what putting
it in the interned dict might do. */
if (!PyUnicode_CheckExact(s))
return;
if (PyUnicode_CHECK_INTERNED(s))
return;
if (interned == NULL) {
interned = PyDict_New();
if (interned == NULL) {
PyErr_Clear(); /* Don't leave an exception */
return;
}
}
Py_ALLOW_RECURSION
t = PyDict_SetDefault(interned, s, s);
Py_END_ALLOW_RECURSION
if (t == NULL) {
PyErr_Clear();
return;
}
if (t != s) {
Py_INCREF(t);
Py_SETREF(*p, t);
return;
}
/* The two references in interned are not counted by refcnt.
The deallocator will take care of this */
Py_REFCNT(s) -= 2;
_PyUnicode_STATE(s).interned = SSTATE_INTERNED_MORTAL;
}可以看到,源码前面还是做一些基本的检查。我们可以看一下37行和50行:将s添加到interned字典中时,其实s同时是key和value(这里我不太清楚为什么会这样做),所以s对应的引用计数是+2了的(具体可以看PyDict_SetDefault()的源码),所以在50行时会将计数-2,保证引用计数的正确。 考虑下面的场景: >>> class User:
def __init__(self, name, age):
self.name = name
self.age = age
>>> user = User('Tom', 21)
>>> user.__dict__
{'name': 'Tom', 'age': 21}由于对象的属性由dict保存,这意味着每个User对象都要保存一个str对象‘name’,这会浪费大量的内存。而str是不可变对象,因此Python内部将有潜在重复可能的字符串都做成单例模式,这就是interned机制。Python具体做法就是在内部维护一个全局dict对象,所有开启interned机制的str对象均保存在这里,后续需要使用的时候,先创建,如果判断已经维护了相同的字符串,就会将新创建的这个对象回收掉。 示例: 由不同运算生成’abc’,最后都是同一个对象: >>> a = 'abc' >>> b = 'ab' + 'c' >>> id(a), id(b), a is b (2752416949872, 2752416949872, True) 以上がPython組み込み型strソースコード解析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。 このウェブサイトの声明
この記事の内容はネチズンが自主的に寄稿したものであり、著作権は原著者に帰属します。このサイトは、それに相当する法的責任を負いません。盗作または侵害の疑いのあるコンテンツを見つけた場合は、admin@php.cn までご連絡ください。

ホットAIツール
Undress AI Tool脱衣画像を無料で 
Undresser.AI Undressリアルなヌード写真を作成する AI 搭載アプリ 
AI Clothes Remover写真から衣服を削除するオンライン AI ツール。 
Clothoff.ioAI衣類リムーバー 
Video Face Swap完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。 
人気の記事
船と墓のためのRimworld Odyssey温度ガイド
1 か月前
By Jack chen
Rimworld Odyssey釣り方
1 か月前
By Jack chen
2つのAlipayアカウントを頂けますか?
1 か月前
By 下次还敢
Rimworldへの初心者のガイド:Odyssey
1 か月前
By Jack chen
PHP変数スコープは説明されています
3週間前
By 百草
ホットツール
メモ帳++7.3.1使いやすく無料のコードエディター 
SublimeText3 中国語版中国語版、とても使いやすい 
ゼンドスタジオ 13.0.1強力な PHP 統合開発環境 
ドリームウィーバー CS6ビジュアル Web 開発ツール 
SublimeText3 Mac版神レベルのコード編集ソフト(SublimeText3)  暗号通貨の統計的裁定とは何ですか?統計的な裁定はどのように機能しますか?
Jul 30, 2025 pm 09:12 PM
暗号通貨の統計的裁定とは何ですか?統計的な裁定はどのように機能しますか?
Jul 30, 2025 pm 09:12 PM
統計アービトラージの紹介統計的arbitrageは、数学モデルに基づいて金融市場で価格の不一致を捉える取引方法です。その核となる哲学は、平均回帰に由来する、つまり、資産価格は短期的には長期的な傾向から逸脱する可能性がありますが、最終的には歴史的平均に戻ります。トレーダーは統計的方法を使用して、資産間の相関を分析し、通常は同期して変更されるポートフォリオを探す。これらの資産の価格関係が異常に逸脱すると、裁定取引の機会が生じます。暗号通貨市場では、主に市場自体の非効率性と劇的な変動のために、統計的な裁定が特に一般的です。従来の金融市場とは異なり、暗号通貨は24時間体制で動作し、その価格はニュース速報、ソーシャルメディアの感情、テクノロジーのアップグレードに非常に敏感です。この一定の価格の変動は、頻繁に価格設定バイアスを作成し、仲裁人を提供します  python shotil rmtreeの例
Aug 01, 2025 am 05:47 AM
python shotil rmtreeの例
Aug 01, 2025 am 05:47 AM
shutil.rmtree()は、ディレクトリツリー全体を再帰的に削除するPythonの関数です。指定されたフォルダーとすべてのコンテンツを削除できます。 1.基本的な使用法:shutil.rmtree(PATH)を使用してディレクトリを削除すると、FilenotFounderror、PermissionError、その他の例外を処理する必要があります。 2。実用的なアプリケーション:一時的なデータやキャッシュディレクトリなど、サブディレクトリとファイルを1回クリックして含むフォルダーをクリアできます。 3。注:削除操作は復元されません。 FilenotFounderrorは、パスが存在しない場合に投げられます。許可またはファイル職業のために失敗する可能性があります。 4.オプションのパラメーター:INGRORE_ERRORS = trueでエラーを無視できます  PythonでSQLクエリを実行する方法は?
Aug 02, 2025 am 01:56 AM
PythonでSQLクエリを実行する方法は?
Aug 02, 2025 am 01:56 AM
対応するデータベースドライバーをインストールします。 2。CONNECT()を使用してデータベースに接続します。 3.カーソルオブジェクトを作成します。 4。Execute()またはexecuteMany()を使用してSQLを実行し、パラメーター化されたクエリを使用して噴射を防ぎます。 5。Fetchall()などを使用して結果を得る。 6。COMMING()は、変更後に必要です。 7.最後に、接続を閉じるか、コンテキストマネージャーを使用して自動的に処理します。完全なプロセスにより、SQL操作が安全で効率的であることが保証されます。  Pythonで仮想環境を作成する方法
Aug 05, 2025 pm 01:05 PM
Pythonで仮想環境を作成する方法
Aug 05, 2025 pm 01:05 PM
Python仮想環境を作成するには、VENVモジュールを使用できます。手順は次のとおりです。1。プロジェクトディレクトリを入力して、python-mvenvenv環境を実行して環境を作成します。 2。SourceENV/bin/Activate to Mac/LinuxおよびEnv \ Scripts \ Windowsにアクティブ化します。 3. PIPINSTALLインストールパッケージ、PIPFREEZE> RECUMESSION.TXTを使用して、依存関係をエクスポートします。 4.仮想環境をGITに提出しないように注意し、設置中に正しい環境にあることを確認してください。仮想環境は、特にマルチプロジェクト開発に適した競合を防ぐためにプロジェクト依存関係を分離でき、PycharmやVSCodeなどの編集者も  VSCODEで引数を使用してPythonスクリプトを実行する方法
Jul 30, 2025 am 04:11 AM
VSCODEで引数を使用してPythonスクリプトを実行する方法
Jul 30, 2025 am 04:11 AM
torunapythonscriptwithargumentsvscode、configurelaunch.jsonbyopeningtherunanddebugpanel、作成済みのthelaunch.jsonfile、andaddinddindingedesirededesiredconguments in "arraywithintheconfiguration.2.inyourpythonscript、useargparseorsys.gparseorsys.gparseorsysces  Pythonの複数のプロセス間でデータを共有する方法は?
Aug 02, 2025 pm 01:15 PM
Pythonの複数のプロセス間でデータを共有する方法は?
Aug 02, 2025 pm 01:15 PM
MultiProcessing.Queueを使用して、複数のプロセスと消費者のシナリオに適した複数のプロセス間でデータを安全に渡す。 2。MultiProcessing.Pipeを使用して、2つのプロセス間の双方向の高速通信を実現しますが、2点接続のみ。 3.値と配列を使用して、シンプルなデータ型を共有メモリに保存し、競争条件を回避するためにロックで使用する必要があります。 4.マネージャーを使用して、リストや辞書などの複雑なデータ構造を共有します。これらは非常に柔軟ですが、パフォーマンスが低く、複雑な共有状態を持つシナリオに適しています。データサイズ、パフォーマンス要件、複雑さに基づいて適切な方法を選択する必要があります。キューとマネージャーは、初心者に最適です。  Python boto3 S3アップロード例
Aug 02, 2025 pm 01:08 PM
Python boto3 S3アップロード例
Aug 02, 2025 pm 01:08 PM
BOTO3を使用してファイルをS3にアップロードしてBOTO3を最初にインストールし、AWS資格情報を構成します。 2。boto3.client( 's3')を介してクライアントを作成し、upload_file()メソッドを呼び出してローカルファイルをアップロードします。 3. S3_Keyをターゲットパスとして指定し、指定されていない場合はローカルファイル名を使用できます。 4. filenotfounderror、nocredentialserror、clienterrorなどの例外を処理する必要があります。 5。ACL、ContentType、StorageClass、Metadataは、exrceargsパラメーターを介して設定できます。 6。メモリデータについては、bytesioを使用して単語を作成できます  Pythonのリストを使用してスタックデータ構造を実装する方法は?
Aug 03, 2025 am 06:45 AM
Pythonのリストを使用してスタックデータ構造を実装する方法は?
Aug 03, 2025 am 06:45 AM
pythonlistscani実装Append()penouspop()popoperations.1.useappend()2つのBelief stotetopthestack.2.usep op()toremoveandreturnthetop要素、保証済みのtocheckeckeckestackisnotemptoavoidindexerror.3.pekattehatopelementwithstack [-1] 
|