


AI モデルの開発がモデル中心からデータ中心に移行する現在の傾向において、データの品質が特に重要になっています。
以前の AI 開発プロセスでは、データセットは通常固定されており、開発作業はベースライン パフォーマンスを向上させるためにモデル アーキテクチャまたはトレーニング プロセスを反復することに重点が置かれていました。現在、データの反復が中心的な役割を果たしており、AI モデルのトレーニングとテストに使用されるデータを評価、フィルター、クリーニング、注釈付けするためのより体系的な方法が必要です。
最近、スタンフォード大学コンピュータ サイエンス学部の Weixin Liang 氏、Li Feifei 氏らは共同で、「信頼できる AI のためのデータ作成における進歩、課題、機会」というタイトルの記事を「Nature-Machine Intelligence」に発表しました。 AI データ プロセス全体のあらゆる側面でデータ品質を確保するための重要な要素と方法について説明しました。

論文アドレス: https://www.nature.com/articles/s42256-022-00516-1.epdf?sharing_token=VPzI-KWAm8tLG_BiXJnV9tRgN0jAjWel9jnR3ZoTv0MRS1pu9dXg73FQ0NTrwhu7Hi_VBEr6peszIAFc 6XO1td lvV1lLJQtOvUFnSXpvW6_nu0Knc_dRekx6lyZNc6PcM1nslocIcut_qNW9OUg1IsbCfuL058R4MsYFqyzlb2E=
AI データ プロセスの主なステップには、データ設計 (データの収集と記録)、データの改善 (データのフィルタリング、クリーニング、注釈、強化)、AI モデルの評価と監視のためのデータ戦略が含まれます。これらすべてが最終的な AI モデルの信頼性に影響します。
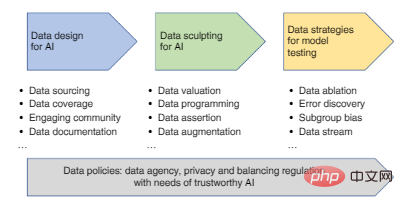
図 1: データ設計から評価までのデータ中心アプローチの開発ロードマップ。
人工知能アプリケーションを特定した後、AI モデル開発の最初のステップはデータを設計することです (つまり、データのソースを特定して記録します)。 。
設計は反復的なプロセスである必要があります。実験データを使用して初期 AI モデルを開発し、その後追加データを収集してモデルの制限にパッチを当てます。設計の主な基準は、データがタスクに適しており、モデルが遭遇する可能性のあるさまざまなユーザーやシナリオを表すのに十分な範囲をカバーしていることを確認することです。
そして、AI の開発に現在使用されているデータセットは、対象範囲が限られているか、偏っていることがよくあります。たとえば医療 AI では、アルゴリズムの開発に使用される患者データの収集が地理的に不均衡に分散しているため、AI モデルのさまざまな集団への適用が制限される可能性があります。
データ カバレッジを向上させる 1 つの方法は、データの作成に広範なコミュニティを参加させることです。これは、現在利用可能な最大の公開データセットである Common Voice プロジェクトによって実証されており、これには 166,000 人を超える参加者による 76 言語での 11,192 時間の音声文字起こしが含まれています。
また、代表的なデータを入手するのが難しい場合は、合成データを使用してカバレッジのギャップを埋めることができます。たとえば、実際の顔の収集にはプライバシーの問題やサンプリングのバイアスが伴うことがよくありますが、現在では、データの不均衡とバイアスを軽減するために、ディープ生成モデルによって作成された合成顔が使用されています。ヘルスケアでは、実際の患者情報を開示することなく、合成医療記録を共有して知識の発見を促進できます。ロボット工学では、現実世界の課題は究極のテストベッドであり、忠実度の高いシミュレーション環境を使用して、エージェントが複雑で長期的なタスクをより迅速かつ安全に学習できるようにすることができます。
しかし、合成データにはいくつかの問題もあります。合成データと現実世界のデータの間には常にギャップがあるため、合成データでトレーニングされた AI モデルが現実世界に転送されると、パフォーマンスの低下が発生することがよくあります。シミュレーターが少数派グループを念頭に置いて設計されていない場合、合成データはデータの格差を悪化させる可能性もあります AI モデルのパフォーマンスは、トレーニング データと評価データのコンテキストに大きく依存するため、データ設計のコンテキストを標準化された形式で文書化することが重要です透明性のあるレポートです。
現在、研究者たちは、データ設計と注釈のプロセスに関するメタデータを取得するために、さまざまな「データ栄養ラベル」を作成しています。有用なメタデータには、データセット内の参加者の性別、性別、人種、地理的位置に関する統計が含まれており、カバーされていない過小評価されているサブグループがあるかどうかを発見するのに役立ちます。データの出所は、データのソースと時刻、データを作成したプロセスと方法を追跡するメタデータの一種でもあります。
メタデータは、専用のデータ設計ドキュメントに保存できます。これは、データのライフサイクルと社会技術的コンテキストを観察するために重要です。ドキュメントは、Zenodo などの安定した一元化されたデータ リポジトリにアップロードできます。
初期データセットが収集された後、AI の開発により効果的なデータを提供するためにデータをさらに改善する必要があります。これは、図 2a に示すように、AI に対するモデル中心のアプローチとデータ中心のアプローチの主な違いです。モデル中心の研究は通常、特定のデータに基づいており、モデル アーキテクチャの改善またはこのデータの最適化に焦点を当てています。一方、データ中心の研究は、データ クリーニング、フィルタリング、アノテーション、強化などのプロセスを通じてデータを体系的に改善するスケーラブルな方法に焦点を当てており、ワンストップのモデル開発プラットフォームを使用できます。

図 2a: AI に対するモデル中心のアプローチとデータ中心のアプローチの比較。 MNIST、COCO、ImageNet は、AI 研究で一般的に使用されるデータセットです。
データセットに非常にノイズが多い場合は、トレーニング前にデータを慎重にスクリーニングする必要があります。これにより、モデルの信頼性と一般化が大幅に向上します。図 2a の飛行機の画像は、鳥のデータ セットから削除する必要があるノイズの多いデータ ポイントです。
図 2b では、以前に使用された大規模な皮膚科データでトレーニングされた 4 つの最先端のモデルはすべて、トレーニング データ、特に肌の色が濃い画像の偏りにより、パフォーマンスが低下しています。良好ではなく、モデル 1 はトレーニング済みです。小さい高品質のデータでは、肌の色が暗い場合でも明るい場合でも比較的信頼性が高くなります。
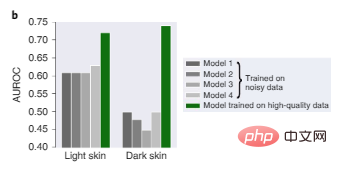
図 2b: 明るい肌と暗い肌の画像に対する皮膚科診断テストのパフォーマンス。
図 2c は、画像分類用の 3 つの一般的なディープ ラーニング アーキテクチャである ResNet、DenseNet、および VGG がすべて、ノイズの多い画像データセットでトレーニングされた場合にはパフォーマンスが低下することを示しています。データ Shapley 値フィルタリングの後、低品質のデータは削除され、よりクリーンなデータ サブセットでトレーニングされた ResNet モデルのパフォーマンスが大幅に向上します。
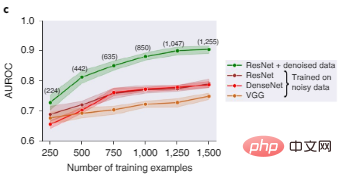
#図 2c: データ フィルタリング前後のさまざまなモデルの物体認識テストのパフォーマンスの比較。括弧内の数字は、ノイズの多いデータをフィルターで除外した後に残っているトレーニング データ ポイントの数を表し、結果は 5 つのランダム シードにわたって集計され、影付きの領域は 95% 信頼区間を表します。
これがデータ評価の本質であり、さまざまなデータの重要性を定量化し、低品質や偏りによってモデルのパフォーマンスに悪影響を与える可能性のあるデータを除外することを目的としています。
この記事では、著者はデータのクリーニングに役立つ 2 つのデータ評価方法を紹介します。
1 つの方法は、トレーニング中にさまざまなデータがいつ削除されたかを測定することです。プロセス AI モデルのパフォーマンスの変化は、以下の図 3a に示すように、Shapley 値またはデータの影響近似を使用して取得できます。このアプローチにより、大規模な AI モデルの効率的な計算評価が可能になります。
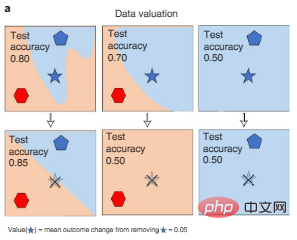
図 3a: データ評価。データの Shapley 値は、特定のポイントがトレーニングから削除されたとき (図の色褪せた五芒星に取り消し線が引かれている) ときの、データのさまざまなサブセットでトレーニングされたモデルのパフォーマンスの変化を測定し、それによって各データ ポイントを定量化します (五芒星の記号) の値。色はカテゴリのラベルを表します。
もう 1 つのアプローチは、不確実性を予測して低品質のデータ ポイントを検出することです。人間によるデータ ポイントのアノテーションは、AI モデルの予測から体系的に逸脱する可能性があり、信頼度学習アルゴリズムはこれらの逸脱を検出できます。ImageNet などの一般的なベンチマークでは、テスト データの 3% 以上が誤ってラベル付けされていることが判明しています。これらのエラーを除外すると、モデルのパフォーマンスが大幅に向上します。
データ アノテーションもデータ バイアスの主な原因です。 AI モデルは一定レベルのランダムなラベル ノイズを許容できますが、偏ったエラーによって偏ったモデルが生成されます。現在、私たちは主に手動のアノテーションに依存していますが、これは非常に高価です。たとえば、単一の LIDAR スキャンにアノテーションを付けるコストは 30 ドルを超える場合があります。データは 3 次元データであるため、アノテーターは 3 次元の境界ボックスを描画する必要があります。一般的な注釈タスクよりも要求が厳しいです。
したがって、著者は、一貫したアノテーション ルールを提供するために、MTurk などのクラウドソーシング プラットフォーム上のアノテーション ツールを慎重に調整する必要があると考えています。医療環境では、アノテーターが専門知識を必要とする場合や、クラウドソーシングできない機密データを保有している場合があることを考慮することも重要です。
アノテーションのコストを削減する 1 つの方法は、データ プログラミングです。データ プログラミングにおいて、AI 開発者はデータ ポイントに手動でラベルを付ける必要がなくなり、代わりにプログラムによるラベル付け関数を作成して、トレーニング セットに自動的にラベルを付けることができます。図 3b に示すように、ユーザー定義のラベル関数を使用して各入力に対してノイズの可能性がある複数のラベルを自動的に生成した後、複数のラベル特徴を集約してノイズを低減する追加のアルゴリズムを設計できます。
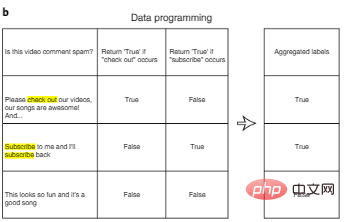
図 3b: データ プログラミング。
ラベル付けコストを削減するためのもう 1 つの「人間参加型」アプローチは、アクティブ ラーニングを通じてラベル付けできるように、最も価値のあるデータに優先順位を付けることです。アクティブ ラーニングは、最適な実験計画からアイデアを引き出します。アクティブ ラーニングでは、アルゴリズムは、ラベルのないデータ ポイントのセットから、情報利得が高いポイントやモデルに不確実性があるポイントなど、最も有益なポイントを選択します。クリックして、手動で実行します。注釈。このアプローチの利点は、必要なデータ量が標準の教師あり学習に必要なデータ量よりもはるかに少ないことです。
最後に、既存のデータがまだ非常に限られている場合、データ拡張はデータセットを拡張し、モデルの信頼性を向上させる効果的な方法です。
コンピュータ ビジョン データは、画像の回転、反転、その他のデジタル変換によって強化でき、テキスト データは自動記述スタイルへの変換によって強化できます。また、図 3c に示すように、トレーニング サンプルのペアを補間して新しいトレーニング データを作成する、より複雑な拡張手法である最近の Mixup もあります。
手動のデータ強化に加えて、現在の AI 自動データ強化プロセスも一般的なソリューションです。さらに、ラベルのないデータが利用可能な場合は、初期モデルを使用して予測を行い (これらの予測は擬似ラベルと呼ばれます)、次に実際のデータと信頼性の高い擬似ラベルを組み合わせたデータで大規模なモデルをトレーニングすることによって、ラベルの拡張を実現することもできます。ラベル、モデル。
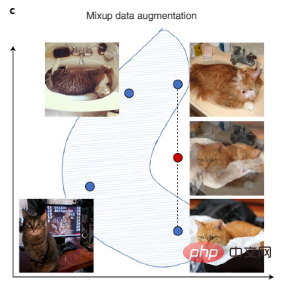
図 3c: ミックスアップは、既存のデータを補間する合成データを作成することでデータセットを強化します。青い点はトレーニング セット内の既存のデータ ポイントを表し、赤い点は 2 つの既存のデータ ポイントを内挿することによって作成された合成データ ポイントを表します。
モデルがトレーニングされた後の AI 評価の目標は、モデルの一般化可能性と信頼性です。
この目標を達成するには、モデルの実際の設定を見つけるために評価データを慎重に設計する必要があります。また、評価データはモデルのトレーニング データと十分に異なる必要があります。
たとえば、医学研究では、AI モデルは通常、少数の病院からのデータに基づいてトレーニングされます。このようなモデルを新しい病院に導入すると、データの収集と処理の違いにより精度が低下します。モデルの一般化を評価するには、さまざまな病院やさまざまなデータ処理パイプラインから評価データを収集する必要があります。他のアプリケーションでは、評価データはさまざまなソースから収集され、できればさまざまなアノテーターによってトレーニング データとしてラベル付けされる必要があります。同時に、高品質の人間によるラベルが最も重要な評価であることに変わりはありません。
AI 評価の重要な役割は、AI モデルが、十分に概念化できないトレーニング データの「ショートカット」として偽の相関を使用しているかどうかを判断することです。たとえば、医療画像処理では、データの処理方法 (トリミングや画像圧縮など) により、モデルによって検出される偽の相関関係 (つまり、ショートカット) が作成される可能性があります。これらのショートカットは表面的には便利かもしれませんが、モデルが少し異なる環境にデプロイされると致命的に失敗する可能性があります。
系統的なデータアブレーションは、潜在的なモデルの「近道」を調べる良い方法です。データ アブレーションでは、擬似相関表面信号のアブレーション入力に対して AI モデルがトレーニングされ、テストされます。
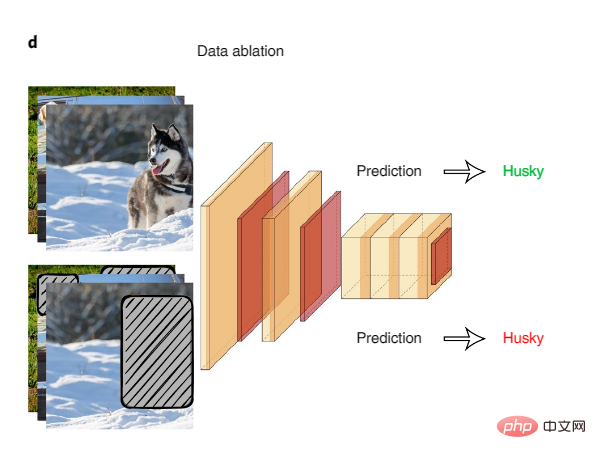
図 4: データ アブレーション
データ アブレーションを使用してモデルのショートカットを検出する例は、一般的な自然言語推論データセットに関する研究です。AI モデルテキスト入力の前半のみでトレーニングされた人々は、同じ入力に対する人間の推論やランダムな推測のレベルと比較して、テキストの前半と後半の間の論理関係を推論する際に高い精度を達成しました。これは、AI モデルがこのタスクを達成するための近道として偽の相関を利用していることを示唆しています。研究チームは、テキスト内の否定がタグと高度に相関しているなど、特定の言語現象が AI モデルによって悪用されていることを発見しました。
データアブレーションはさまざまな分野で広く使用されています。たとえば、医療分野では、AI が偽の背景から学習しているのか、画質のアーティファクトから学習しているのかを評価する方法として、画像の生物学的に関連する部分をマスクアウトすることができます。
AI 評価は、多くの場合、テスト データ セット全体にわたる全体的なパフォーマンス メトリクスの比較に限定されます。しかし、AI モデルが全体的なデータ レベルでうまく機能する場合でも、データの特定のサブグループで系統的なエラーが表示される可能性があり、これらのエラーのクラスターを特徴付けることで、モデルの限界をより深く理解できるようになります。
メタデータが利用可能な場合、きめ細かい評価方法では、可能な限り、データセット内の参加者の性別、性別、人種、地理的位置によって評価データをスライスする必要があります。たとえば、「アジア系の高齢者」などです。男性」または「アメリカ先住民の女性」を抽出し、各データ サブグループに対するモデルのパフォーマンスを定量化します。多重精度監査は、AI モデルのパフォーマンスが低いデータのサブグループを自動的に検索するアルゴリズムです。ここでは、メタデータを使用して元のモデルのエラーを予測およびクラスタリングし、AI モデルがどのような間違いを犯したのか、その理由などの質問に対して説明可能な答えを提供するように監査アルゴリズムがトレーニングされています。
メタデータが利用できない場合、Domino などのメソッドは、評価モデルがエラーを起こしやすいデータ クラスターを自動的に特定し、テキスト生成を使用してこれらのモデル エラーの自然言語説明を作成します。
現在、ほとんどの AI 研究プロジェクトはデータセットを 1 回だけ開発しますが、実際の AI ユーザーは多くの場合、データセットとモデルを継続的に更新する必要があります。継続的なデータ開発には、次のような課題が伴います。
まず、データと AI タスクの両方が時間の経過とともに変化する可能性があります。たとえば、新しい車両モデルが路上に登場する (つまり、ドメイン シフト) か、あるいは AI が変化する可能性があります。開発者は、ラベルの分類を変更する新しいオブジェクト カテゴリ (たとえば、通常のバスとは異なるスクール バスのタイプ) を認識したいと考えています。何百万時間もの古いタグ データを廃棄するのは無駄であるため、更新は不可欠です。さらに、トレーニングと評価の指標は、新しいデータを比較検討し、各サブタスクに適切なデータを使用するように慎重に設計する必要があります。
第二に、継続的にデータを取得して使用するために、ユーザーはデータ中心の AI プロセスのほとんどを自動化する必要があります。この自動化には、アルゴリズムを使用して、どのデータをアノテーターに送信するか、およびそれを使用してモデルを再トレーニングするかを選択し、プロセスで何か問題が発生した場合 (たとえば、精度メトリクスが低下した場合) にのみモデル開発者に警告することが含まれます。 「MLOps (Machine Learning Operations)」トレンドの一環として、業界企業は機械学習のライフサイクルを自動化するツールを使用し始めています。
以上がスタンフォード大学リー・フェイフェイのチームによる新しい研究で、データの設計、改善、評価が信頼できる人工知能を実現する鍵であることが判明の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



