


この記事では、機械学習タスクにおける表形式データに対するさまざまな次元削減手法の有効性を比較します。次元削減手法をデータセットに適用し、回帰分析と分類分析を通じてその有効性を評価します。さまざまなドメインに関連する UCI から取得したさまざまなデータセットに次元削減手法を適用します。合計 15 のデータセットが選択され、そのうち 7 つは回帰に使用され、8 つは分類に使用されます。
この記事を読みやすく理解しやすくするために、1 つのデータセットの前処理と分析のみを示します。実験はデータセットをロードすることから始まります。データ セットはトレーニング セットとテスト セットに分割され、平均が 0、標準偏差が 1 になるように正規化されます。
次元削減手法がトレーニング データに適用され、同じパラメーターを使用してテスト セットが次元削減のために変換されます。回帰では主成分分析 (PCA) と特異値分解 (SVD) を使用して次元削減を行い、分類では線形判別分析 (LDA) を使用します。機械学習モデルがトレーニングされる テストが実施され、さまざまな次元削減方法を通じて取得されたさまざまなデータセットでさまざまなモデルのパフォーマンスが比較されました。
データ処理
import pandas as pd ## for data manipulation df = pd.read_excel(r'RegressionAirQualityUCI.xlsx') print(df.shape) df.head()
 データセットには 15 列が含まれており、そのうちの 1 つが含まれています。ラベルを予測する必要があるということです。次元削減を続行する前に、日付と時刻の列も削除されます。
データセットには 15 列が含まれており、そのうちの 1 つが含まれています。ラベルを予測する必要があるということです。次元削減を続行する前に、日付と時刻の列も削除されます。
X = df.drop(['CO(GT)', 'Date', 'Time'], axis=1) y = df['CO(GT)'] X.shape, y.shape #Output: ((9357, 12), (9357,))
トレーニングでは、次元削減手法と次元削減特徴空間でトレーニングされた機械学習モデルの有効性を評価できるように、データセットをトレーニング セットとテスト セットに分割する必要があります。 。モデルはトレーニング セットを使用してトレーニングされ、パフォーマンスはテスト セットを使用して評価されます。
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) X_train.shape, X_test.shape, y_train.shape, y_test.shape #Output: ((7485, 12), (1872, 12), (7485,), (1872,))
データ セットに対して次元削減手法を使用する前に、入力データをスケーリングして、すべてのフィーチャが同じスケールになるようにすることができます。一部の次元削減手法では、データが正規化されているかどうかに応じて出力が変更され、フィーチャのサイズに影響される可能性があるため、これは線形モデルにとって重要です。
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X_train = scaler.fit_transform(X_train) X_test = scaler.transform(X_test) X_train.shape, X_test.shape
主成分分析 (PCA)
ここでは、Python sklearn.decomposition モジュールの PCA メソッドを使用します。保持するコンポーネントの数はこのパラメータで指定され、この数はより小さい特徴空間に含まれる次元の数に影響します。別の方法として、保持する目標分散を設定することもできます。これにより、キャプチャされたデータの分散量に基づいて成分の数が決まります。ここでは 0.95
from sklearn.decomposition import PCA pca = PCA(n_compnotallow=0.95) X_train_pca = pca.fit_transform(X_train) X_test_pca = pca.transform(X_test) X_train_pca
# に設定します。 # #上記の特徴は何を表していますか? 主成分分析 (PCA) は、データを低次元空間に投影し、データ内の差異をできるだけ多く保持しようとします。これは特定の操作に役立つ場合がありますが、データの理解がさらに難しくなる可能性もあります。 , PCA は、初期特徴の線形融合であるデータ内の新しい軸を識別できます。
from sklearn.decomposition import TruncatedSVD svd = TruncatedSVD(n_compnotallow=int(X_train.shape[1]*0.33)) X_train_svd = svd.fit_transform(X_train) X_test_svd = svd.transform(X_test) X_train_svd
回帰モデルのトレーニング
import numpy as np from sklearn.linear_model import LinearRegression from sklearn.neighbors import KNeighborsRegressor from sklearn.svm import SVR from sklearn.tree import DecisionTreeRegressor from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor from sklearn.metrics import r2_score, mean_squared_error import time
def train_test_ML(dataset, dataform, X_train, y_train, X_test, y_test): temp_df = pd.DataFrame(columns=['Data Set', 'Data Form', 'Dimensions', 'Model', 'R2 Score', 'RMSE', 'Time Taken']) for i in [LinearRegression, KNeighborsRegressor, SVR, DecisionTreeRegressor, RandomForestRegressor, GradientBoostingRegressor]: start_time = time.time() reg = i().fit(X_train, y_train) y_pred = reg.predict(X_test) r2 = np.round(r2_score(y_test, y_pred), 2) rmse = np.round(np.sqrt(mean_squared_error(y_test, y_pred)), 2) end_time = time.time() time_taken = np.round((end_time - start_time), 2) temp_df.loc[len(temp_df)] = [dataset, dataform, X_train.shape[1], str(i).split('.')[-1][:-2], r2, rmse, time_taken] return temp_df
original_df = train_test_ML('AirQualityUCI', 'Original', X_train, y_train, X_test, y_test) original_df
元のデータを入力すると、KNN リグレッサーとランダム フォレストが比較的良好にパフォーマンスし、ランダムのトレーニング時間が短縮されることがわかります。森が一番長い。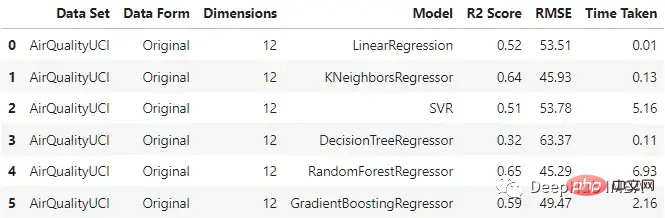
pca_df = train_test_ML('AirQualityUCI', 'PCA Reduced', X_train_pca, y_train, X_test_pca, y_test) pca_df
与原始数据集相比,不同模型的性能有不同程度的下降。梯度增强回归和支持向量回归在两种情况下保持了一致性。这里一个主要的差异也是预期的是模型训练所花费的时间。与其他模型不同的是,SVR在这两种情况下花费的时间差不多。
SVD
svd_df = train_test_ML('AirQualityUCI', 'SVD Reduced', X_train_svd, y_train, X_test_svd, y_test) svd_df

与PCA相比,SVD以更大的比例降低了维度,随机森林和梯度增强回归器的表现相对优于其他模型。
对于这个数据集,使用主成分分析时,数据维数从12维降至5维,使用奇异值分析时,数据降至3维。
将类似的过程应用于其他六个数据集进行测试,得到以下结果:
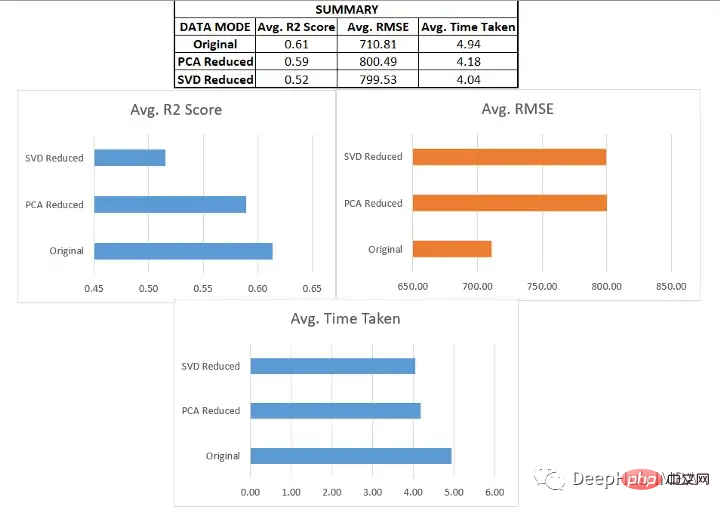
我们在各种数据集上使用了SVD和PCA,并对比了在原始高维特征空间上训练的回归模型与在约简特征空间上训练的模型的有效性
对于分类我们将使用另一种降维方法:LDA。机器学习和模式识别任务经常使用被称为线性判别分析(LDA)的降维方法。这种监督学习技术旨在最大化几个类或类别之间的距离,同时将数据投影到低维空间。由于它的作用是最大化类之间的差异,因此只能用于分类任务。
from sklearn.linear_model import LogisticRegression from sklearn.neighbors import KNeighborsClassifier from sklearn.svm import SVC from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier from sklearn.metrics import accuracy_score, f1_score, recall_score, precision_score
继续我们的训练方法
def train_test_ML2(dataset, dataform, X_train, y_train, X_test, y_test): temp_df = pd.DataFrame(columns=['Data Set', 'Data Form', 'Dimensions', 'Model', 'Accuracy', 'F1 Score', 'Recall', 'Precision', 'Time Taken']) for i in [LogisticRegression, KNeighborsClassifier, SVC, DecisionTreeClassifier, RandomForestClassifier, GradientBoostingClassifier]: start_time = time.time() reg = i().fit(X_train, y_train) y_pred = reg.predict(X_test) accuracy = np.round(accuracy_score(y_test, y_pred), 2) f1 = np.round(f1_score(y_test, y_pred, average='weighted'), 2) recall = np.round(recall_score(y_test, y_pred, average='weighted'), 2) precision = np.round(precision_score(y_test, y_pred, average='weighted'), 2) end_time = time.time() time_taken = np.round((end_time - start_time), 2) temp_df.loc[len(temp_df)] = [dataset, dataform, X_train.shape[1], str(i).split('.')[-1][:-2], accuracy, f1, recall, precision, time_taken] return temp_df
开始训练
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis lda = LinearDiscriminantAnalysis() X_train_lda = lda.fit_transform(X_train, y_train) X_test_lda = lda.transform(X_test)
预处理、分割和数据集的缩放,都与回归部分相同。在对8个不同的数据集进行新联后我们得到了下面结果:
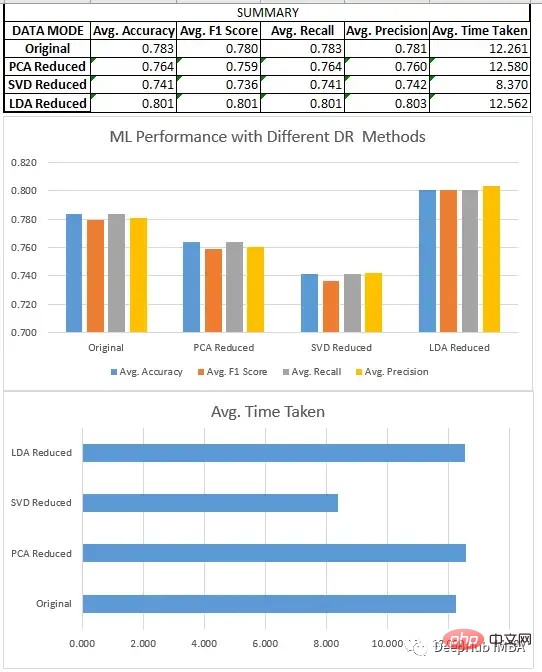
我们比较了上面所有的三种方法SVD、LDA和PCA。
我们比较了一些降维技术的性能,如奇异值分解(SVD)、主成分分析(PCA)和线性判别分析(LDA)。我们的研究结果表明,方法的选择取决于特定的数据集和手头的任务。
回帰タスクの場合、一般に PCA の方が SVD よりも優れたパフォーマンスを発揮することがわかります。分類の場合、LDA は SVD や PCA、さらには元のデータセットよりも優れています。線形判別分析 (LDA) が分類タスクにおいて主成分分析 (PCA) を常に上回ることが重要ですが、これは一般に LDA の方が優れた技術であることを意味するものではありません。これは、LDA がラベル付きデータに依存してデータ内の最も識別的な特徴を特定する教師あり学習アルゴリズムであるのに対し、PCA はラベル付きデータを必要とせず、可能な限り多くの分散を維持しようとする教師なし手法であるためです。したがって、PCA は教師なしタスクや解釈可能性が重要な状況に適している可能性があり、LDA はラベル付きデータを含むタスクに適している可能性があります。
次元削減手法はデータセット内の特徴の数を減らし、機械学習モデルの効率を向上させるのに役立ちますが、モデルのパフォーマンスと結果の解釈可能性への潜在的な影響を考慮することが重要です。
この記事の完全なコード:
https://github.com/salmankhi/DimensionalityReduction/blob/main/Notebook_25373.ipynb
以上が一般的な次元削減テクノロジーの比較: 情報の整合性を維持しながらデータ次元を削減する実現可能性分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



