



ドキュメントの解析には、ドキュメント内のデータを調べて有用な情報を抽出することが含まれます。自動化により多くの手作業を削減できます。一般的な解析戦略は、文書を画像に変換し、認識にコンピューター ビジョンを使用することです。文書画像分析とは、文書の画像のピクセル データから情報を取得するテクノロジーを指しますが、場合によっては、期待される結果 (テキスト、画像、グラフ、数値、表、数式) について明確な答えがない場合があります。 ..)。

OCR (光学式文字認識) は、コンピューター ビジョンを通じて画像内のテキストを検出および抽出するプロセスです。第一次世界大戦中にイスラエルの科学者エマニュエル・ゴールドバーグが文字を読み取って電信コードに変換できる機械を開発したときに発明されました。現在この分野は、画像処理、テキストローカリゼーション、文字セグメンテーション、文字認識を組み合わせた非常に洗練されたレベルに達しています。基本的にはテキストのオブジェクト検出技術です。
この記事では、OCR を使用してドキュメントを解析する方法を説明します。他の同様の状況で簡単に使用できる (コピー、貼り付け、実行するだけ) 便利な Python コードをいくつか紹介し、完全なソース コードのダウンロードも提供します。
ここでは、上場企業のPDF形式の財務諸表を例に挙げます(下記リンク)。

# with pip pip install python-poppler # with conda conda install -c conda-forge poppler
# READ AS IMAGE
import pdf2imagedoc = pdf2image.convert_from_path("doc_apple.pdf")
len(doc) #<-- check num pages
doc[0] #<-- visualize a page
# Save imgs import osfolder = "doc" if folder not in os.listdir(): os.makedirs(folder)p = 1 for page in doc: image_name = "page_"+str(p)+".jpg" page.save(os.path.join(folder, image_name), "JPEG") p = p+1
pip install layoutparser torchvision && pip install "git+https://github.com/facebookresearch/detectron2.git@v0.5#egg=detectron2"
pip install "layoutparser[ocr]"
import layoutparser as lp import cv2 import numpy as np import io import pandas as pd import matplotlib.pyplot as plt
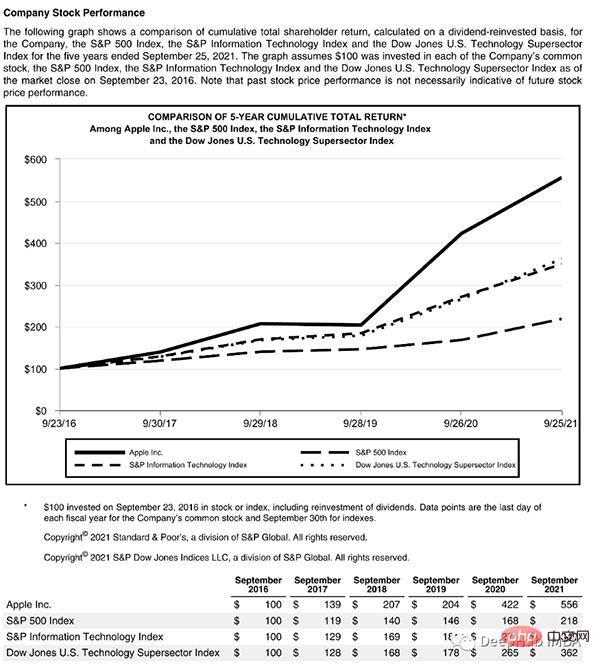 #このページはタイトルで始まり、テキスト ブロック、次に図と表があるため、これらのオブジェクトを認識するにはトレーニングされたモデルが必要です。幸いなことに、Detectron はこれを行うことができます。ここからモデルを選択し、コードでそのパスを指定するだけです。
#このページはタイトルで始まり、テキスト ブロック、次に図と表があるため、これらのオブジェクトを認識するにはトレーニングされたモデルが必要です。幸いなことに、Detectron はこれを行うことができます。ここからモデルを選択し、コードでそのパスを指定するだけです。
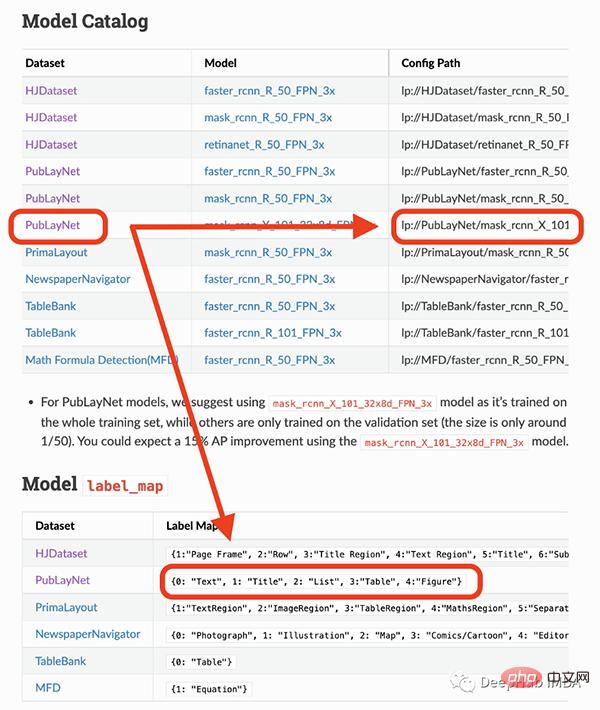 #私が使用しようとしているモデルは、4 つのオブジェクト (テキスト、タイトル、リスト、表、グラフ) のみを検出できます。したがって、他のもの (方程式など) を識別する必要がある場合は、他のモデルを使用する必要があります。
#私が使用しようとしているモデルは、4 つのオブジェクト (テキスト、タイトル、リスト、表、グラフ) のみを検出できます。したがって、他のもの (方程式など) を識別する必要がある場合は、他のモデルを使用する必要があります。
## load pre-trained model
model = lp.Detectron2LayoutModel(
"lp://PubLayNet/mask_rcnn_X_101_32x8d_FPN_3x/config",
extra_config=["MODEL.ROI_HEADS.SCORE_THRESH_TEST", 0.8],
label_map={0:"Text", 1:"Title", 2:"List", 3:"Table", 4:"Figure"})
## turn img into array
i = 21
img = np.asarray(doc[i])
## predict
detected = model.detect(img)
## plot
lp.draw_box(img, detected, box_width=5, box_alpha=0.2,
show_element_type=True)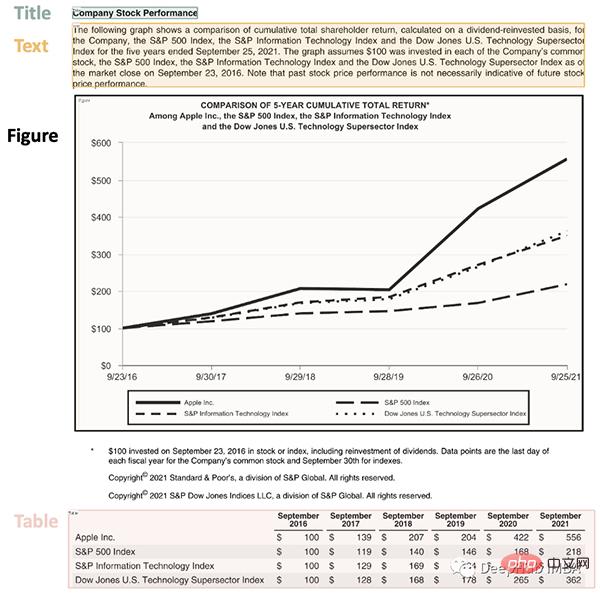
结果包含每个检测到的布局的细节,例如边界框的坐标。根据页面上显示的顺序对输出进行排序是很有用的:
## sort
new_detected = detected.sort(key=lambda x: x.coordinates[1])
## assign ids
detected = lp.Layout([block.set(id=idx) for idx,block in
enumerate(new_detected)])## check
for block in detected:
print("---", str(block.id)+":", block.type, "---")
print(block, end='nn')
完成OCR的下一步是正确提取检测到内容中的有用信息。
我们已经对图像完成了分割,然后就需要使用另外一个模型处理分段的图像,并将提取的输出保存到字典中。
由于有不同类型的输出(文本,标题,图形,表格),所以这里准备了一个函数用来显示结果。
'''
{'0-Title': '...',
'1-Text': '...',
'2-Figure': array([[ [0,0,0], ...]]),
'3-Table': pd.DataFrame,
}
'''
def parse_doc(dic):
for k,v in dic.items():
if "Title" in k:
print('x1b[1;31m'+ v +'x1b[0m')
elif "Figure" in k:
plt.figure(figsize=(10,5))
plt.imshow(v)
plt.show()
else:
print(v)
print(" ")首先看看文字:
# load model
model = lp.TesseractAgent(languages='eng')
dic_predicted = {}
for block in [block for block in detected if block.type in ["Title","Text"]]:
## segmentation
segmented = block.pad(left=15, right=15, top=5,
bottom=5).crop_image(img)
## extraction
extracted = model.detect(segmented)
## save
dic_predicted[str(block.id)+"-"+block.type] =
extracted.replace('n',' ').strip()
# check
parse_doc(dic_predicted)
再看看图形报表
for block in [block for block in detected if block.type == "Figure"]: ## segmentation segmented = block.pad(left=15, right=15, top=5, bottom=5).crop_image(img) ## save dic_predicted[str(block.id)+"-"+block.type] = segmented # check parse_doc(dic_predicted)
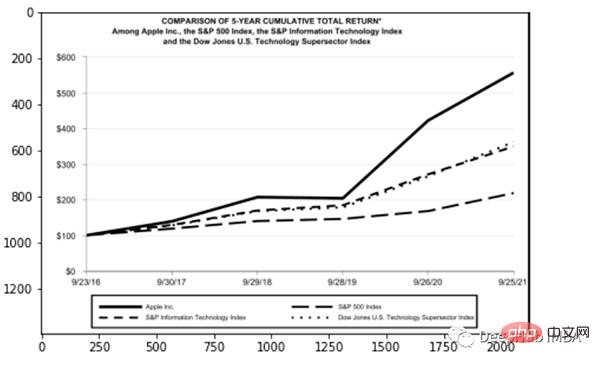
上面两个看着很不错,那是因为这两种类型相对简单,但是表格就要复杂得多。尤其是我们上看看到的的这个,因为它的行和列都是进行了合并后产生的。
for block in [block for block in detected if block.type == "Table"]: ## segmentation segmented = block.pad(left=15, right=15, top=5, bottom=5).crop_image(img) ## extraction extracted = model.detect(segmented) ## save dic_predicted[str(block.id)+"-"+block.type] = pd.read_csv( io.StringIO(extracted) ) # check parse_doc(dic_predicted)

正如我们的预料提取的表格不是很好。好在Python有专门处理表格的包,我们可以直接处理而不将其转换为图像。这里使用TabulaPy 包:
import tabula
tables = tabula.read_pdf("doc_apple.pdf", pages=i+1)
tables[0]
结果要好一些,但是名称仍然错了,但是效果要比直接OCR好的多。
本文是一个简单教程,演示了如何使用OCR进行文档解析。使用Layoutpars软件包进行了整个检测和提取过程。并展示了如何处理PDF文档中的文本,数字和表格。
以上がPython と OCR を使用したドキュメント解析の完全なコード デモ (コードは添付)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



