


この記事では、python に関する関連知識を提供し、Word ファイルを読み取るための ReadDoc クラスの定義や search_word 関数の定義など、主に履歴書審査に関連する問題を紹介します。皆様の参考になれば幸いです。

推奨される学習: Python ビデオ チュートリアル
関連する履歴書情報は次のとおりです:

#実際のケース スクリプトは次のとおりです:既知の条件:
ファイルを検索したい指定されたキーワード履歴書を含む (Python、Java など)
実装アイデア:
各単語ファイルをバッチで読み取り (glob を通じて単語情報を取得)、読み取り可能な内容をすべて結合します。キーワードを取得してフィルタリングして、ターゲットの履歴書アドレスを取得します。
ここで注意すべき点は、すべての「履歴書」が段落形式で表示されているわけではないということです。たとえば、「Liepin」の Web サイトからダウンロードした履歴書は「表形式」です。 、「boss」からダウンロードした履歴書は「段落形式」です。ここで読むときは注意が必要です。私たちが行ったデモスクリプト演習は「表形式」です。
ここでは、「段落」と「表」をそれぞれ読み取るための 2 つの関数を定義する「ReadDoc」クラスを具体的に定義できます。
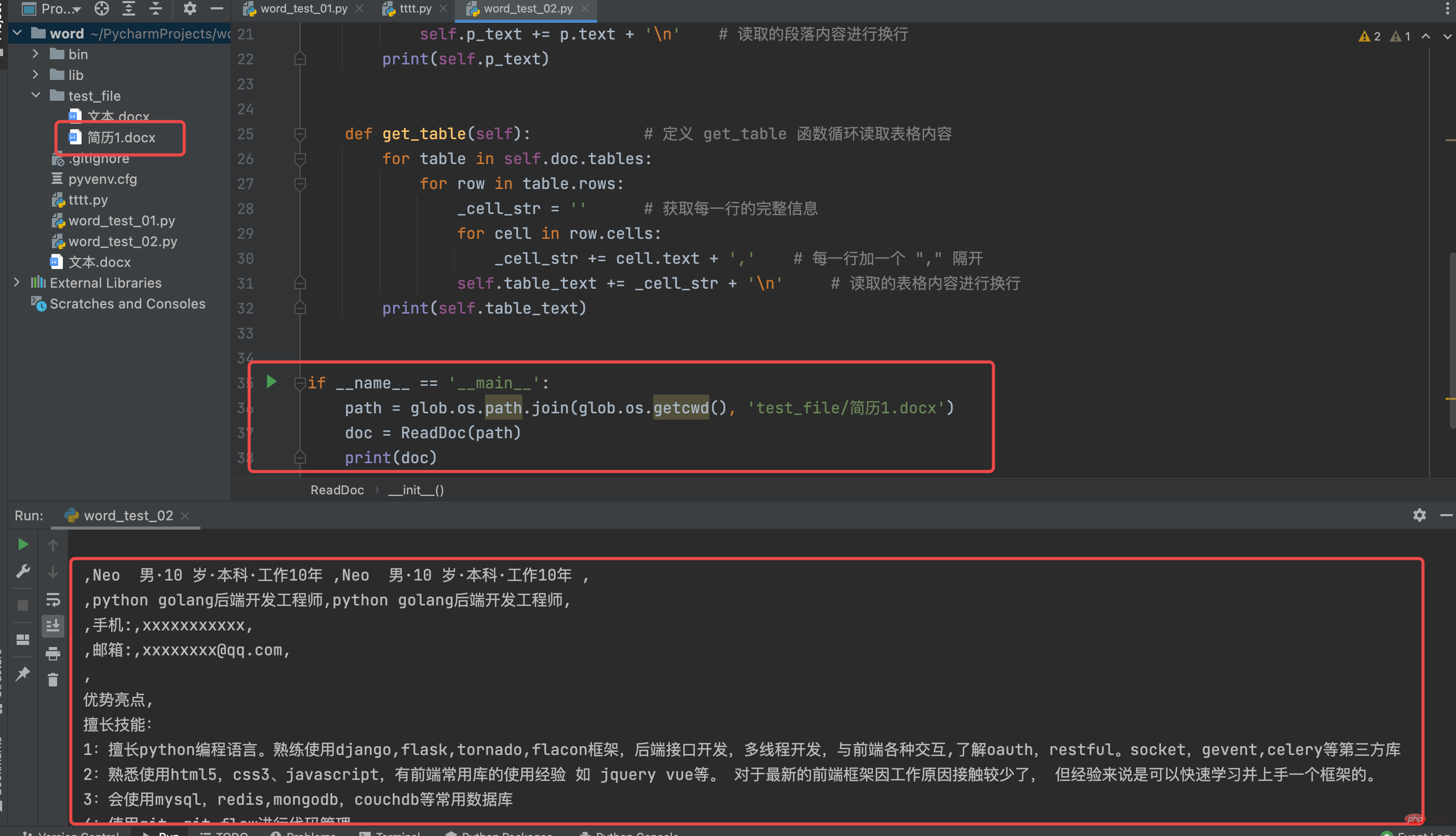
# coding:utf-8from docx import Documentclass ReadDoc(object): # 定义一个 ReadDoc ,用以读取 word 文件 def __init__(self, path): # 构造函数默认传入读取 word 文件的路径 self.doc = Document(path) self.p_text = '' self.table_text = '' self.get_para() self.get_table() def get_para(self): # 定义 get_para 函数用以读取 word 文件的段落 for p in self.doc.paragraphs: self.p_text += p.text + '\n' # 读取的段落内容进行换行 print(self.p_text) def get_table(self): # 定义 get_table 函数循环读取表格内容 for table in self.doc.tables: for row in table.rows: _cell_str = '' # 获取每一行的完整信息 for cell in row.cells: _cell_str += cell.text + ',' # 每一行加一个 "," 隔开 self.table_text += _cell_str + '\n' # 读取的表格内容进行换行 print(self.table_text)if __name__ == '__main__': path = glob.os.path.join(glob.os.getcwd(), 'test_file/简历1.docx') doc = ReadDoc(path) print(doc)
ReadDoc クラスの実行結果を見てください
# coding:utf-8import globfrom docx import Documentclass ReadDoc(object): # 定义一个 ReadDoc ,用以读取 word 文件
def __init__(self, path): # 构造函数默认传入读取 word 文件的路径
self.doc = Document(path)
self.p_text = ''
self.table_text = ''
self.get_para()
self.get_table()
def get_para(self): # 定义 get_para 函数用以读取 word 文件的段落
for p in self.doc.paragraphs:
self.p_text += p.text + '\n' # 读取的段落内容进行换行
# print(self.p_text) # 调试打印输出 word 文件的段落内容
def get_table(self): # 定义 get_table 函数循环读取表格内容
for table in self.doc.tables:
for row in table.rows:
_cell_str = '' # 获取每一行的完整信息
for cell in row.cells:
_cell_str += cell.text + ',' # 每一行加一个 "," 隔开
self.table_text += _cell_str + '\n' # 读取的表格内容进行换行
# print(self.table_text) # 调试打印输出 word 文件的表格内容def search_word(path, targets): # 定义 search_word 用以筛选符合内容的简历;传入 path 与 targets(targets 为列表)
result = glob.glob(path)
final_result = [] # 定义一个空列表,用以后续存储文件的信息
for i in result: # for 循环获取 result 内容
isuse = True # 是否可用
if glob.os.path.isfile(i): # 判断是否是文件
if i.endswith('.docx'): # 判断文件后缀是否是 "docx" ,若是,则利用 ReadDoc类 实例化该文件对象
doc = ReadDoc(i)
p_text = doc.p_text # 获取 word 文件内容
table_text = doc.table_text
all_text = p_text + table_text for target in targets: # for 循环判断关键字信息内容是否存在
if target not in all_text:
isuse = False
break
if not isuse:
continue
final_result.append(i)
return final_resultif __name__ == '__main__':
path = glob.os.path.join(glob.os.getcwd(), '*')
result = search_word(path, ['python', 'golang', 'react', '埋点']) # 埋点是为了演示效果,故意在 "简历1.docx" 加上的
print(result)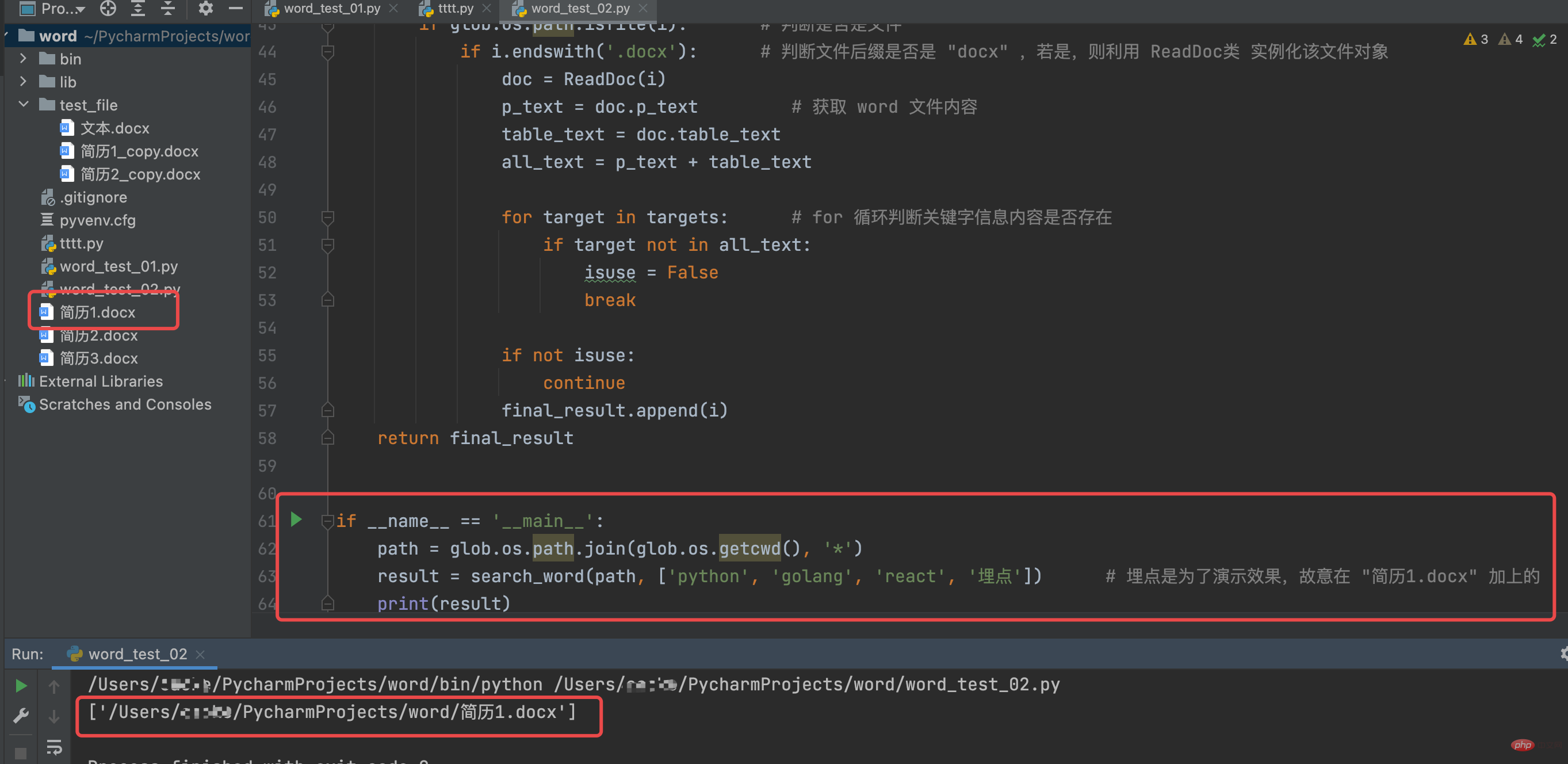
以上が履歴書審査のための Python 自動化の実践の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。


















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



