


この記事では、javascript に関する関連知識をお届けします。主に、解析エンジンやその他のコンテンツを含む、JavaScript の動作メカニズムと原理に関する関連事項を紹介します。一緒に見ていきましょう。助けるために。

[関連する推奨事項: JavaScript ビデオ チュートリアル 、Web フロントエンド ]
私はこれまで書いてきましたjs を 2 年以上使用していますが、その動作メカニズムや原理がよく理解できませんでした。今日は特別に達人の理論と私自身の要約を以下に記録しました:
簡単に言えば、JavaScript 解析エンジンは、JavaScript コードを「読み取り」、コードの実行結果を正確に提供できるプログラムです。
たとえば、var a = 1 1; のようなコードを作成すると、JavaScript エンジンはコードを理解 (解析) し、a の値を 2 に変更します。
コンパイルの原理を勉強したことがある方は、静的言語 (Java、C、C など) の場合、上記のことを処理するものがコンパイラー (Compiler) と呼ばれることを知っています。 JavaScript などの動的言語の場合、コンパイラ、インタプリタと呼ばれます。 2 つの違いは 1 つの文に要約できます。コンパイラーはソース コードを別のタイプのコード (マシン コード、バイトコードなど) にコンパイルしますが、インタープリターはコードの実行結果を直接解析して出力します。たとえば、Firebug のコンソールは JavaScript インタープリターです。
ただし、たとえば V8 (Chrome の JS エンジン) は実際に JS の実行パフォーマンスを向上させるために JavaScript エンジンを使用しているため、JavaScript エンジンがインタプリタであるかコンパイラであるかを定義することは現在では困難です。 JS はネイティブ マシン コード (ネイティブ マシン コード) にコンパイルされ、その後マシン コードが実行されます (これははるかに高速になります)。
JavaScript エンジンもプログラムであり、私たちが記述する JavaScript コードもプログラムです。プログラムを理解させるにはどうすればよいでしょうか?これにはルールを定義する必要があります。たとえば、前述の var a = 1 1; の意味は次のとおりです:
左側の var は変数 a を宣言する宣言を表します
右側の var は 1 と 1 の違いを表しますand 1 Do add
真ん中の等号は、これが代入ステートメントであることを示します
最後のセミコロンはステートメントの終わりを示します
これらがルールです。 JavaScript エンジンは、この標準に従って JavaScript コードを解析できます。次に、ここの ECMAScript でこれらのルールを定義します。その中で、文書 ECMAScript 262 は、JavaScript 言語の完全な標準セットを定義しています。これらには以下が含まれます:
var、if、else、break、 continue などは JavaScript のキーワードです
abstract、int、long などは JavaScript の予約語です
それを数値として数える方法と文字列としてカウントする方法など
演算子 ( 、 - 、>、 JavaScript 構文を定義します
式、ステートメントなどの標準処理アルゴリズムを定義します。 == に遭遇した場合の対処方法
⋯⋯
標準の JavaScript エンジンは、この一連のドキュメントに従って実装されます。標準に従わない実装もあるため、ここでは標準が強調されていることに注意してください。 IEのJSエンジンなど。これが、JavaScript に互換性の問題がある理由です。 IE の JS エンジンが標準に従って実装されていない理由については、ブラウザ戦争に関係します。ここでは詳しく説明しませんので、自分でググってください。
つまり、簡単に言うと、ECMAScript が言語の標準を定義し、JavaScript エンジンがそれに従って実装する、これが 2 つの関係です。
簡単に言えば、JavaScript エンジンはブラウザのコンポーネントの 1 つです。ブラウザは、ページの解析、ページのレンダリング、Cookie 管理、履歴記録など、他にも多くのことを実行する必要があるためです。そうですね、JavaScript エンジンはコンポーネントであるため、通常はブラウザー開発者自身によって開発されます。例: IE9 の Chakra、Firefox の TraceMonkey、Chrome の V8 など。
また、ブラウザごとに異なる JavaScript エンジンが使用されていることがわかります。したがって、私たちが言えることは、どの JavaScript エンジンをより深く理解するかということだけです。
JavaScript 言語の主な特徴の 1 つは、JavaScript 言語がシングルスレッドであること、つまり、同時に 1 つのことしか実行できないことです。 。では、なぜ JavaScript は複数のスレッドを持てないのでしょうか?これにより効率が向上します。
JavaScript の単一スレッドは、その目的に関連しています。ブラウザーのスクリプト言語としての JavaScript の主な目的は、ユーザーと対話して DOM を操作することです。これにより、シングルスレッドのみが可能であることが決まります。そうでない場合は、非常に複雑な同期の問題が発生します。たとえば、JavaScript に同時に 2 つのスレッドがあるとします。1 つのスレッドは特定の DOM ノードにコンテンツを追加し、もう 1 つのスレッドはノードを削除します。この場合、ブラウザはどちらのスレッドを使用する必要がありますか?
つまり、複雑さを避けるために、JavaScript は誕生以来シングルスレッドであり、これがこの言語の中核機能となっており、今後も変わることはありません。
マルチコア CPU のコンピューティング能力を活用するために、HTML5 は Web Worker 標準を提案しています。これにより、JavaScript スクリプトは複数のスレッドを作成できますが、子スレッドはメインスレッドによって完全に制御されるため、 DOM を操作しないでください。したがって、この新しい標準は JavaScript のシングルスレッドの性質を変更しません。
プロセスは CPU リソース割り当ての最小単位であり、プロセスには複数のスレッドを含めることができます。ブラウザはマルチプロセスであり、開いているブラウザ ウィンドウはそれぞれ 1 つのプロセスです。
スレッドは CPU スケジューリングの最小単位であり、プログラムのメモリ空間は同じプロセス内のスレッド間で共有されます。
プロセスは倉庫と見なすことができ、スレッドは輸送可能なトラックです。各倉庫には、倉庫にサービスを提供する (商品を運ぶ) ための複数のトラックがあります。各倉庫は複数の車両で牽引できます。貨物ですが、各車両が一度にできることは 1 つだけで、それはこの貨物を輸送することです。
コアポイント:
プロセスは、CPU リソース割り当ての最小単位 (リソースを所有し、独立して実行できる最小単位)です。スレッドは CPU スケジューリングの最小単位です (スレッドはプロセスに基づくプログラム実行単位であり、プロセス内に複数のスレッドが存在する可能性があります)
異なるプロセスも通信できますが、コストが高くなります。
ブラウザはマルチプロセスです プロセスとスレッドの違いを理解した後、ブラウザをある程度理解しましょう: (最初に簡略化した理解を見てみましょう)
ブラウザはマルチプロセスですプロセスの
簡単に理解すると、タブ ページを開くたびに、次の処理と同等になります。別のブラウザプロセスを作成します。
Chrome を例に挙げると、複数のタブ ページがあり、Chrome のタスク マネージャーで複数のプロセスを確認できます (各タブ ページには独立したプロセスとメイン プロセスがあります)。 Windows タスク マネージャーで。
注: ここでは、ブラウザにも独自の最適化メカニズムが必要です。複数のタブ ページを開いた後、Chrome タスク マネージャーで、いくつかのプロセスがマージされているのが確認できる場合があります (各タブ ラベルは、プロセスが存在しません)必然的に絶対的です)
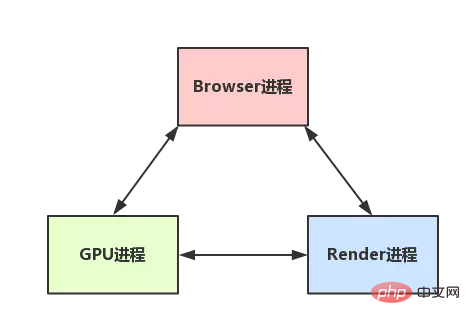
ブラウザにはどのようなプロセスが含まれていますか?
(1) ブラウザ プロセス: ブラウザのメイン プロセスは 1 つだけです (調整と制御を担当します)。役割:
ブラウザ インターフェイスの表示とユーザー インタラクションを担当します。前方、後方など。 (4) ブラウザー レンダリング プロセス (ブラウザー カーネル、レンダラ プロセス、内部マルチスレッド): デフォルトでは、各タブ ページには 1 つのプロセスがあり、相互に影響しません。主な機能は次のとおりです: ページのレンダリング、スクリプトの実行、イベント処理など。
メモリの強化: ブラウザーで Web ページを開くことは、新しいプロセスを開始することと同じです (プロセスには独自のマルチスレッドがあります)
もちろん、ブラウザーは複数のプロセスをマージすることがあります (たとえば、複数の空白のタブを開いた後、複数の空白のタブが 1 つのプロセスにマージされていることがわかります)
複数のブラウザー プロセスの利点
ブラウザが単一プロセスの場合、特定のタブ ページがクラッシュするとブラウザ全体に影響があり、エクスペリエンスが低下します。同様に、単一プロセスの場合は、プラグインのクラッシュはブラウザ全体にも影響します。
もちろん、メモリやその他のリソースの消費も大きくなります。これは、空間が時間と交換されることを意味します。 Chrome ではメモリがいくら多くても足りません。メモリ リーク問題は少し改善されましたが、これは単なる改善であり、消費電力の増加にもつながります。
ブラウザ カーネル (レンダリング プロセス)
ページの描画、JSの実行、イベントループがすべてこのプロセス内で行われていることが分かります。次に、このプロセスの分析に焦点を当てます。
ブラウザのレンダリング プロセスはマルチスレッドであることに注意してください (JS エンジンはシングルスレッドです)次に、次のことを考えてみましょう。どのスレッドが含まれているかを確認してください (主な常駐スレッドをいくつかリストします):
これを見ると、まず、ブラウザプロセスとブラウザカーネルのプロセスとスレッドについてある程度理解できるはずです。次に、ブラウザのブラウザ プロセス (制御プロセス) がカーネルとどのように通信するかについて説明します。これを理解した後、この部分の知識を結び付けて、最初から最後まで完全な概念を得ることができます。
タスク マネージャーを開いてからブラウザーを開くと、タスク マネージャーに 2 つのプロセスが表示されます (1 つはメイン コントロール プロセスで、もう 1 つはタブ ページを開くレンダリング プロセスです)。次に、この前提の下で、プロセス全体を見てみましょう: (大幅に簡略化されています)
JavaScript は DOM を操作できるため、これらの要素のプロパティを変更し、同時にインターフェイス (つまり、JSスレッドと UI スレッドが同時に実行される場合)、前後のレンダリング スレッドで取得された要素データが不整合になる可能性があります。
そこで、ブラウザでは、予期しない描画結果を防ぐために、GUI 描画スレッドと JS エンジンが排他的な関係になるように設定し、JS エンジンが実行されると GUI スレッドが一時停止され、 GUI の更新はキューの待機に保存され、JS エンジン スレッドがアイドル状態のときにすぐに実行されます。
上記の相互排他関係から、実行時間が長すぎる場合、JS はページをブロックすると推測できます。
たとえば、JS エンジンが膨大な量の計算を実行しているとします。この時点で GUI が更新されたとしても、それはキューに保存され、JS エンジンがアイドル状態になって実行されるのを待ちます。 。すると、膨大な計算量が発生するため、JS エンジンは長時間アイドル状態になる可能性が高く、当然のことながら非常に大きく感じられます。
したがって、JS の実行に時間がかかりすぎるとページのレンダリングに一貫性がなくなり、ページのレンダリングと読み込みがブロックされているように感じることを避けるようにしてください。
この問題を解決するには、計算をバックエンドに配置することに加えて、それが避けられず、膨大な計算が UI に関連している場合、私のアイデアは setTimeout を使用してタスクを分割し、途中で少し空き時間があります。ページが直接フリーズしないように、JS エンジンに UI を処理させる時間です。
必要な HTML5 の最小バージョンを直接決定する場合は、以下の WebWorker を参照してください。
前の記事で述べたように、JS エンジンはシングルスレッドであり、JS の実行時間が長すぎる場合、ページをブロックしてしまうため、JS は実際に CPU を大量に使用する計算には無力なのでしょうか?
つまり、Web Worker は後に HTML5 でサポートされるようになりました。
MDN の公式説明は次のとおりです:
Web Worker は、Web コンテンツのバックグラウンド スレッドでスクリプトを実行する簡単な方法を提供します。
スレッドは、ユーザー インターフェイスに干渉することなくタスクを実行できます。ワーカーは、名前付きの JavaScript ファイルを実行するコンストラクター (Worker()) を使用して作成されたオブジェクトです (このファイルには、ワーカーで実行されるコードが含まれています)糸 )。
ワーカーは、現在のウィンドウとは異なる別のグローバル コンテキストで実行されます。
したがって、ウィンドウ ショートカットを使用して (self ではなく) 現在のグローバル スコープを取得すると、ワーカー内でエラーが返されます。
次のように理解してください。ワーカー、JS エンジンはブラウザに適用されてサブスレッドを開きます (サブスレッドはブラウザによって開かれ、メインスレッドによって完全に制御され、DOM を操作できません)
JS エンジン スレッドとワーカースレッドは特定のメソッド(postMessage API を渡す必要があります。特定のデータのスレッドと対話するためにオブジェクトをシリアル化する必要があります)を通じて通信します。 したがって、非常に時間のかかる作業がある場合は、別のワーカー スレッドを開いてください。それはどれほど驚くべきことでしょう。JS エンジンのメインスレッドには影響しません。結果が計算されるのを待つだけです。最後に、結果をメインスレッドに伝えるだけです。完璧です!
そして、JS エンジンのメインスレッドには影響しないことに注意してください。エンジンはシングルスレッドです。この本質は変わっていません。ワーカーは、ブラウザによって開かれる JS エンジン用のプラグインとして理解できます。特に、これらの大きなコンピューティングの問題を解決するために設計されています。
その他、Worker の詳細な説明はこの記事の範囲を超えているため、詳細は説明しません。
WebWorker と SharedWorkerWebWorker のみに属します特定のページは、他のページのレンダリング プロセス (ブラウザ カーネル プロセス) と共有されません。
したがって、Chrome は、ワーカー プログラムで JavaScript を実行するために、レンダリング プロセス (各タブ ページはレンダリング プロセス) に新しいスレッドを作成します。 。 SharedWorker はブラウザのすべてのページで共有され、レンダリング プロセスに関連付けられておらず、複数のレンダリング プロセスで共有できるため、ワーカーと同じ方法で実装することはできません。
したがって、Chrome ブラウザは別のSharedWorker プロセスは JavaScript プログラムの実行に使用されます。何度作成されても、ブラウザ内の同じ JavaScript ごとに SharedWorker プロセスは 1 つだけ存在します。
これを見るとわかりやすいと思いますが、本質的にはプロセスとスレッドの違いです。 SharedWorker は独立したプロセスによって管理され、WebWorker は Render プロセスの下の単なるスレッドです。
ブラウザ レンダリング プロセス
理解を容易にするために、事前作業は直接省略されています。ブラウザが URL を入力すると、ブラウザのメイン プロセスが引き継ぎ、ダウンロード スレッドを開き、次に http リクエストを作成し (DNS クエリや IP アドレス指定などを省略します)、応答を待ってコンテンツを取得し、コンテンツを転送します。
ブラウザのレンダリング プロセスが開始されますブラウザ カーネルがコンテンツを取得した後、レンダリングは次の手順に大まかに分けられます。
HTML を解析して dom ツリーを構築する
css を解析してレンダー ツリーを構築する (CSS コードをツリー状のデータ構造に解析し、それを DOM と結合してレンダー ツリーにマージします)
要素のサイズと位置の計算を担当するレンダー ツリーのレイアウト (レイアウト/リフロー)
レンダー ツリー (ペイント) の描画とページのピクセル情報の描画
ブラウザーは各レイヤーの情報を GPU に送信し、 GPU は各レイヤーを合成して画面に表示します。
詳細な手順は省略していますが、レンダリング完了後はloadイベントとなり、その後は独自のJSロジック処理となります。
一部の詳細な手順が省略されているため、注意が必要な点についていくつか説明します。 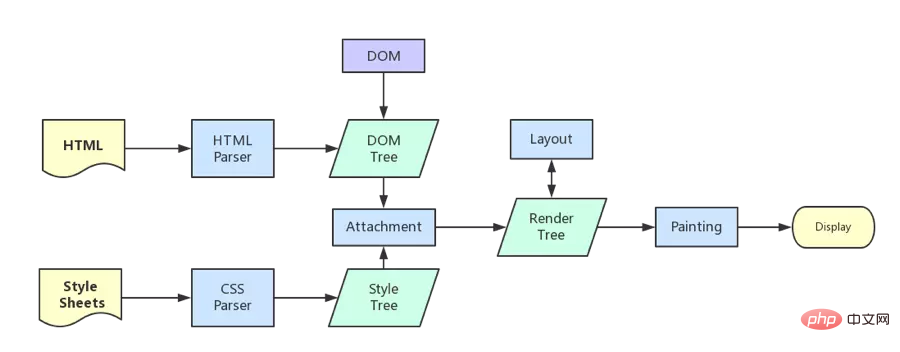
前述したように、load イベントはレンダリング完了後にトリガーされますが、load イベントのシーケンスを区別できますか?とDOMContentLoadedイベント??
これは非常に簡単です。定義を知っておくだけです。
DOMContentLoaded イベントがトリガーされるときは、DOM が読み込まれるときのみであり、スタイル シート、画像、非同期スクリプトなどは除きます。
onload イベントがトリガーされると、ページ上のすべての DOM、スタイル シート、スクリプト、画像が読み込まれ、つまりレンダリングされます。 # #css の読み込みが dom ツリーのレンダリングをブロックするかどうか
css の読み込みによって DOM ツリーの解析がブロックされることはありません (DOM は非同期読み込み中に通常どおり構築されます)
opacity 属性/トランジション アニメーション (アニメーションの実行中にコンポジション レイヤーが作成され、アニメーションが開始または終了しなかった後、要素は以前の状態に戻ります)
will-chang 属性 (これは比較的リモートです)一般に不透明度や翻訳と組み合わせて使用されます。その機能は、ブラウザーが何らかの最適化作業を開始できるように、変更が加えられることを事前にブラウザーに伝えることです (使用後にこれを解放するのが最善です) video、iframe、canvas、webgl などの要素
その他、以前のフラッシュ プラグインなど
絶対アクセラレーションとハードウェア アクセラレーションの違い
絶対は分離できますが、通常のドキュメント フローからは、デフォルトの複合レイヤーから分離できません。そのため、通常のドキュメントフローでは絶対値の情報が変わってもレンダーツリーは変わりませんが、最終的にブラウザが描画する際には合成レイヤー全体が描画されるため、絶対値の情報の変更は描画に影響を及ぼします。複合層全体の。 (ブラウザが再描画します。複合レイヤーのコンテンツが多い場合、absolute によってもたらされる描画情報が変化しすぎて、リソースの消費が非常に大きくなります)
一般に、要素はハードウェア アクセラレーションが有効になった後、通常のドキュメント フローから独立した複合レイヤーになります。変更後、全体の再描画を回避できます。ページを作成してパフォーマンスを向上させますが、多数の複合レイヤーを使用しないようにしてください。そうしないと、過度のリソース消費によりページがスタックしてしまいます。
ハードウェア アクセラレーションを使用する場合は、可能な限りインデックスを使用して、これを防ぐ必要があります。デフォルトでは、ブラウザは後続の要素に対して複合レイヤー レンダリングを作成します。具体的な原則は次のとおりです: Webkit CSS3 では、この要素にハードウェア アクセラレーションが追加されており、インデックス レベルが比較的低い場合、この要素の背後にある他の要素は (レベルがこの要素より高いか同じで、相対属性または絶対属性が同じである場合)、デフォルトで複合レイヤーのレンダリングになります。これが適切に処理されない場合、これはパフォーマンスに大きな影響を与えます。
簡単に理解すると、実際にそれが可能です。これは暗黙的な合成概念であると考えられます。つまり、a が複合レイヤーで、b が a の上にある場合、b もまた複合レイヤーになります。これには特別な注意が必要です。
EventLoop からの JS の実行メカニズムについて話します実行可能コンテキスト、VO、scop チェーンなどの概念については説明しないことに注意してください (これらは別の記事にまとめることができます) ここでは主に、JS コードがイベント ループと組み合わせてどのように実行されるかについて説明します。
このパートを読むための前提条件は、JS エンジンがシングルスレッドであることをすでに知っていることです。ここでは、上で説明したいくつかの概念が使用されます:
JS エンジン スレッド# #同期タスクはメイン スレッドで実行され、実行スタックを形成します。
これを見ると、setTimeout によってプッシュされたイベントが時間通りに実行されないことがあるのはなぜですか?メインスレッドがまだアイドル状態ではなく、イベントリストにプッシュされるときに他のコードを実行している可能性があるため、当然エラーが発生します。 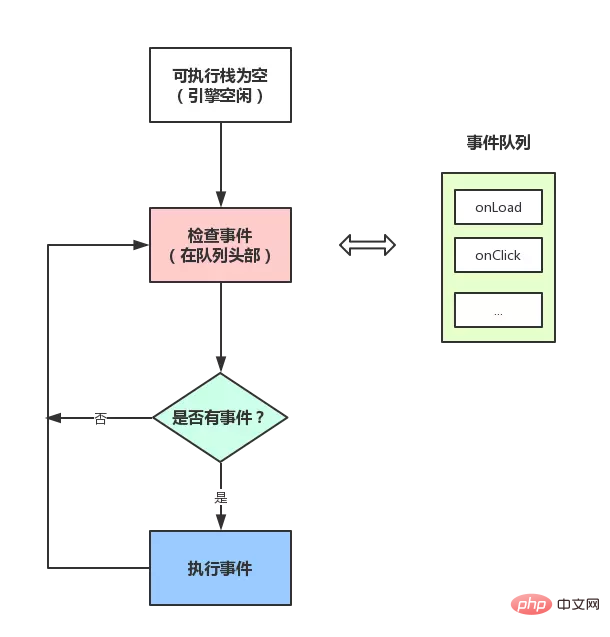
上の図の大まかな説明は次のとおりです。 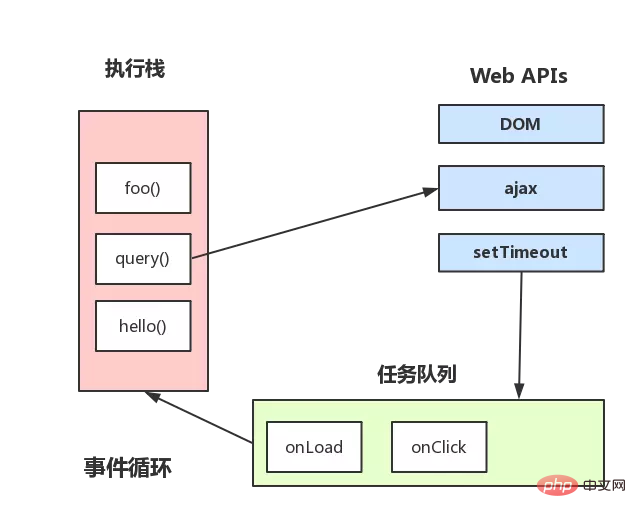
メイン スレッドは次のようになります。実行中に実行スタックを生成します。スタック内のコードが特定の API を呼び出すと、イベント キューにさまざまなイベントが追加されます (ajax リクエストの完了など、トリガー条件が満たされたとき)
##上記のイベント ループ メカニズムの核心は次のとおりです: JS エンジン スレッドとイベント トリガー スレッド
##しかし、イベント内に隠された詳細がいくつかあります。たとえば、setTimeout を呼び出した後、イベント キューに追加する前に特定の時間待機する方法はありますか? JS エンジンによって検出されますか?もちろん違います。これはタイマー スレッドによって制御されます (JS エンジン自体が多忙で時間がないため) なぜ別のタイマー スレッドが必要なのでしょうか? JavaScript エンジンはシングルスレッドであるため、スレッドがブロックされた状態になるとタイミングの精度に影響するため、タイミングのために別のスレッドを開く必要があります。 タイマー スレッドはいつ使用されますか? setTimeout または setInterval を使用する場合、タイマー スレッドで時間を計測する必要があり、時間が完了すると、特定のイベントがイベント キューにプッシュされます。 setInterval の代わりに setTimeoutsetTimeout を使用して通常のタイミングをシミュレートすることと、setInterval を直接使用することには違いがあります。 setTimeout が実行されるたびに実行され、一定期間実行した後に setTimeout が続行されるため、途中でエラーが発生します (エラーはコードの実行時間に関連します)累積的な影響として、setInterval コードが再度キューに追加される前に実行が完了していない場合、タイマー コードが間隔なしで連続して数回実行されます。通常の間隔で実行したとしても、複数の setInterval コードの実行時間が予想より短くなる場合があります (コードの実行にある程度の時間がかかるため)
たとえば、iOS の Webview や Safari などのブラウザには、スクロール時 JSを実行しない場合、setIntervalを使用すると、スクロール後に複数回実行されることがわかります スクロールではJSが実行されないため、コールバックが蓄積されコンテナがフリーズし、不明なエラーが発生しますコールバックの実行時間が長すぎる場合 (このセクションは後で補足します。SetInterval の組み込みの最適化によりコールバックが繰り返し追加されることはありません)
そして、ブラウザーが最小化されて表示されている場合、setInterval はプログラムを実行せず、キュー内の setInterval のコールバック関数。ブラウザ ウィンドウが再度開かれると、すべてが瞬時に実行されます
したがって、非常に多くの問題を考慮して、現在一般的に考えられている最善の解決策は、 setTimeout を使用してシミュレートすることです。 setInterval、または特別な場合には requestAnimationFrame
を直接使用します。: JS 昇格で説明したように、JS エンジンは setInterval を最適化します。現在のイベント キューに setInterval コールバックがある場合、それは繰り返し追加されません。
上記は JS イベント ループ メカニズムを整理したもので、ES5 の場合はこれで十分です。しかし、ES6 が普及した今でも、次のような問題が発生するでしょう:
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0);
Promise.resolve().then(function() {
console.log('promise1');
}).then(function() {
console.log('promise2');
});
console.log('script end');うーん、正しい実行順序は次のとおりです:
script start script end promise1 promise2 setTimeout
Why? ? Promise には microtask
という新しい概念があるため、さらに JS はマクロタスクとマイクロタスクの 2 つのタスクタイプに分けられますが、ECMAScript ではマイクロタスクをジョブと呼び、マクロタスクをタスクと呼ぶこともあります。
それらの定義は何ですか?違い?簡単に言うと、次のように理解できます:
実行スタックによって毎回実行されるコードがマクロであることが理解できますタスク (イベントからの毎回の時間を含む) イベント コールバックをキューから取得し、実行のために実行スタックに入れる)
理解できます現在のタスクの実行終了直後に実行されるタスクであること
追加: ノード環境では、process.nextTick の優先順位が Promise よりも高くなります。これは単純に次のように理解されます: マクロ タスクが終了した後、マイクロタスク キューの nextTickQueue 部分が最初に実行され、次にマイクロタスクの Promise 部分が実行されます。
スレッドに基づいて理解してみましょう:
(1) マクロタスク内のイベントはイベント キューに配置され、このキューはイベント トリガー スレッドによって維持されます
(2) ) マイクロタスク内のすべてのマイクロタスクはマイクロタスク キュー (ジョブ キュー) に追加され、現在のマクロタスクが完了した後の実行を待機します。このキューは JS エンジン スレッドによって維持されます (これは私自身の理解から推測したものです。メインスレッド下でシームレスに実行されます)
動作メカニズムを要約すると、
図に示すように: 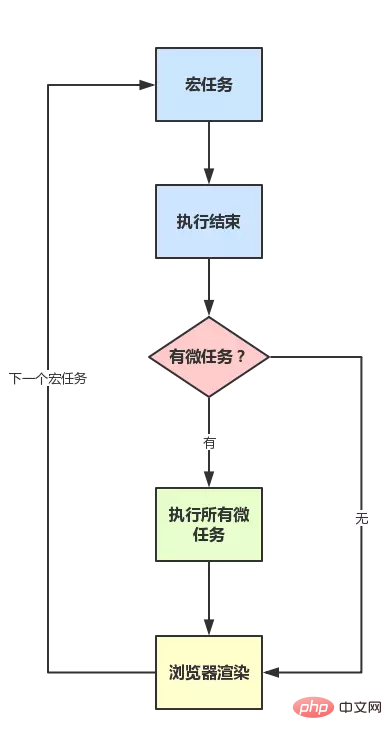
さらに、Promise ポリフィルとの違いに注意してください。および正式バージョン:
正式バージョンでは、これは標準のマイクロタスク形式です
Polyfill は一般に setTimeout を通じてシミュレートされるため、マクロタスクの形式になります
一部のブラウザでは実行が異なることに注意してください標準ブラウザでのシナリオ (ただし、一部のブラウザは標準ではない可能性があることに注意してください)
补充:使用MutationObserver实现microtask
MutationObserver可以用来实现microtask (它属于microtask,优先级小于Promise, 一般是Promise不支持时才会这样做)
它是HTML5中的新特性,作用是:监听一个DOM变动, 当DOM对象树发生任何变动时,Mutation Observer会得到通知
像以前的Vue源码中就是利用它来模拟nextTick的, 具体原理是,创建一个TextNode并监听内容变化, 然后要nextTick的时候去改一下这个节点的文本内容, 如下:
var counter = 1
var observer = new MutationObserver(nextTickHandler)
var textNode = document.createTextNode(String(counter))
observer.observe(textNode, {
characterData: true
})
timerFunc = () => {
counter = (counter + 1) % 2
textNode.data = String(counter)
}不过,现在的Vue(2.5+)的nextTick实现移除了MutationObserver的方式(据说是兼容性原因), 取而代之的是使用MessageChannel (当然,默认情况仍然是Promise,不支持才兼容的)。
MessageChannel属于宏任务,优先级是:MessageChannel->setTimeout, 所以Vue(2.5+)内部的nextTick与2.4及之前的实现是不一样的,需要注意下。
【相关推荐:javascript视频教程、web前端】
以上がJavaScriptの動作仕組みと原理を完全マスターの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



