


この記事では、内部結合、外部結合、複数テーブル結合、サブクエリに関する問題など、MySQL の接続クエリに関する関連知識を提供します。皆様のお役に立てれば幸いです。

これまで、2 つのテーブル student_info と student_score を使用して、実際、生徒の基本情報と生徒の成績情報を 1 つのテーブルにマージすることは不可能ではありません。2 つのテーブルをマージした後の新しいテーブルの名前が student_merge であると仮定すると、
student_merge table
| number | name | sex# のようになります。 | ##id_number部署 | 専攻 | 登録時刻 | 件名 | スコア | |
|---|---|---|---|---|---|---|---|---|
| Du Ziteng | 男性 | 158177199901044792 | コンピュータ サイエンス学部 | コンピュータ サイエンスおよびエンジニアリング | 2018-09-01 | 雌豚の産後ケア | 78 | |
| Du Ziteng | 男性 | 158177199901044792 | コンピュータサイエンス学部 | コンピュータサイエンスアンドエンジニアリング | 2018-09-01 | サダムの戦争準備について | 88 | |
| ドゥ・キヤン | #女151008199801178529 | コンピュータサイエンス学部 | コンピュータサイエンスアンドエンジニアリング | 2018-09-01 | 雌豚の産後ケア | 100 | 20180102 | |
| 女 | 151008199801178529 | コンピュータ サイエンス学部 | コンピュータ サイエンス アンド エンジニアリング | 2018-09-01 | サダムの戦争準備について | 98 | ##20180103 | |
| 男性 | 17156319980116959X | コンピュータサイエンス学部 | ソフトウェアエンジニアリング | 2018-09-01 | 雌豚の産後ケア | 59 | 20180103 | |
| 男性 | 17156319980116959X | 学校コンピュータサイエンス | ソフトウェアエンジニアリング | 2018-09-01 | サダムの戦争準備について | 61 | #20180104 | Shi Zhenxiang |
| 141992199701078600 | コンピュータ サイエンス学部 | ソフトウェア エンジニアリング | 2018-09- 01 | 雌豚の産後ケア | 55 | 20180104 | Shi Zhenxiang | |
| 141992199701078600 | コンピュータ大学 | ソフトウェア工学 | 2018-09-01 | サダムの戦争準備について | 46 | 20180105 | Fan Jian | |
| ##181048200008156368 | 宇宙アカデミー | 航空機設計 | 2018-09-01 | NULL | NULL | 20180106 | Zhu Yiqun | |
| 197995199801078445 | スペースアカデミー | 電子情報 | 2018-09-01 | NULL | NULL |
この結合されたテーブルを使用すると、学生の基本情報だけでなく、次のクエリ ステートメントのような 1 つのクエリ ステートメントで学生の成績情報もクエリできます。 SELECT number, name, major, subject, score FROM student_merge; ログイン後にコピー クエリ リスト
そのため、冗長な情報をできるだけ少なく保存するために、いわゆる 、 時代は、複数のテーブルの情報を 1 つのクエリ ステートメントの結果セットに表示する方法を求めています。Connection Query は、この困難な歴史的使命を引き受けました。もちろん、ストーリーをスムーズに進めるために、最初に 2 つの単純なテーブルを作成し、それらにデータを入力します。 と mysql> SELECT * FROM t1; +------+------+ | m1 | n1 | +------+------+ | 1 | a | | 2 | b | | 3 | c | +------+------+ 3 rows in set (0.00 sec) mysql> SELECT * FROM t2; +------+------+ | m2 | n2 | +------+------+ | 2 | b | | 3 | c | | 4 | d | +------+------+ 3 rows in set (0.00 sec) mysql> ログイン後にコピー #このプロセスは、t1 テーブルのレコードと t1 テーブルのレコードを接続することで構成されているようです。 t2 テーブル 新しい大きなレコードのため、このクエリ プロセスは結合クエリと呼ばれます。結合クエリの結果セットには、別のテーブルの各レコードと一致する、1 つのテーブルの各レコードの組み合わせが含まれます。このような結果セットは、 t1 mysql> SELECT * FROM t1, t2; +------+------+------+------+ | m1 | n1 | m2 | n2 | +------+------+------+------+ | 1 | a | 2 | b | | 2 | b | 2 | b | | 3 | c | 2 | b | | 1 | a | 3 | c | | 2 | b | 3 | c | | 3 | c | 3 | c | | 1 | a | 4 | d | | 2 | b | 4 | d | | 3 | c | 4 | d | +------+------+------+------+ 9 rows in set (0.00 sec) ログイン後にコピー クエリ リストの # は、FROM ステートメントの後にリストされているテーブルから各列を選択することを表します。上記のクエリ ステートメントは、実際には次の記述メソッドと同等です: SELECT t1.m1, t1.n1, t2.m2, t2.n2 FROM t1, t2; ログイン後にコピー t1 , ## に適用されます。 #t2テーブル内の列名は明示的に書き込まれます。つまり、列の完全修飾名が使用されます。 SELECT m1, n1, m2, n2 FROM t1, t2; ログイン後にコピー テーブルと t2 テーブルの列名は重複していないため、曖昧さによってサーバーを混乱させるために、クエリ リストで列名を直接使用することもできます。 SELECT t1.*, t2.* FROM t1, t2; ログイン後にコピー テーブルのすべての列と t2# テーブルのすべての列をクエリすることを意味します。 ## テーブル すべての列。
デカルト積は、100×100×100=1000000 这种只涉及单表的过滤条件我们之前都提到过一万遍了,我们之前也一直称为 涉及两表的条件 这种过滤条件我们之前没见过,比如 下边我们就要看一下携带过滤条件的连接查询的大致执行过程了,比方说下边这个查询语句: SELECT * FROM t1, t2 WHERE t1.m1 > 1 AND t1.m1 = t2.m2 AND t2.n2 <p>在这个查询中我们指明了这三个过滤条件:</p> ログイン後にコピー
那么这个连接查询的大致执行过程如下:
从上边两个步骤可以看出来,我们上边唠叨的这个两表连接查询共需要查询1次 内连接和外连接了解了连接查询的执行过程之后,视角再回到我们的 mysql> SELECT student_info.number, name, major, subject, score FROM student_info, student_score WHERE student_info.number = student_score.number; +----------+-----------+--------------------------+-----------------------------+-------+ | number | name | major | subject | score | +----------+-----------+--------------------------+-----------------------------+-------+ | 20180101 | 杜子腾 | 计算机科学与工程 | 母猪的产后护理 | 78 | | 20180101 | 杜子腾 | 计算机科学与工程 | 论萨达姆的战争准备 | 88 | | 20180102 | 杜琦燕 | 计算机科学与工程 | 母猪的产后护理 | 100 | | 20180102 | 杜琦燕 | 计算机科学与工程 | 论萨达姆的战争准备 | 98 | | 20180103 | 范统 | 软件工程 | 母猪的产后护理 | 59 | | 20180103 | 范统 | 软件工程 | 论萨达姆的战争准备 | 61 | | 20180104 | 史珍香 | 软件工程 | 母猪的产后护理 | 55 | | 20180104 | 史珍香 | 软件工程 | 论萨达姆的战争准备 | 46 | +----------+-----------+--------------------------+-----------------------------+-------+ 8 rows in set (0.00 sec) mysql> ログイン後にコピー
从上述查询结果中我们可以看到,各个同学对应的各科成绩就都被查出来了,可是有个问题,
可是这样仍然存在问题,即使对于外连接来说,有时候我们也并不想把驱动表的全部记录都加入到最后的结果集。这就犯难了,有时候匹配失败要加入结果集,有时候又不要加入结果集,这咋办,有点儿愁啊。。。噫,把过滤条件分为两种不就解决了这个问题了么,所以放在不同地方的过滤条件是有不同语义的:
一般情况下,我们都把只涉及单表的过滤条件放到
左(外)连接的语法 左(外)连接的语法还是挺简单的,比如我们要把 SELECT * FROM t1 LEFT [OUTER] JOIN t2 ON 连接条件 [WHERE 普通过滤条件]; ログイン後にコピー 其中中括号里的 mysql> SELECT student_info.number, name, major, subject, score FROM student_info LEFT JOIN student_score ON student_info.number = student_score.number; +----------+-----------+--------------------------+-----------------------------+-------+ | number | name | major | subject | score | +----------+-----------+--------------------------+-----------------------------+-------+ | 20180101 | 杜子腾 | 计算机科学与工程 | 母猪的产后护理 | 78 | | 20180101 | 杜子腾 | 计算机科学与工程 | 论萨达姆的战争准备 | 88 | | 20180102 | 杜琦燕 | 计算机科学与工程 | 母猪的产后护理 | 100 | | 20180102 | 杜琦燕 | 计算机科学与工程 | 论萨达姆的战争准备 | 98 | | 20180103 | 范统 | 软件工程 | 母猪的产后护理 | 59 | | 20180103 | 范统 | 软件工程 | 论萨达姆的战争准备 | 61 | | 20180104 | 史珍香 | 软件工程 | 母猪的产后护理 | 55 | | 20180104 | 史珍香 | 软件工程 | 论萨达姆的战争准备 | 46 | | 20180105 | 范剑 | 飞行器设计 | NULL | NULL | | 20180106 | 朱逸群 | 电子信息 | NULL | NULL | +----------+-----------+--------------------------+-----------------------------+-------+ 10 rows in set (0.00 sec) mysql> ログイン後にコピー 从结果集中可以看出来,虽然 右(外)连接的语法 右(外)连接和左(外)连接的原理是一样一样的,语法也只是把 SELECT * FROM t1 RIGHT [OUTER] JOIN t2 ON 连接条件 [WHERE 普通过滤条件]; ログイン後にコピー 只不过驱动表是右边的表,被驱动表是左边的表,具体就不唠叨了。 内连接的语法 内连接和外连接的根本区别就是在驱动表中的记录不符合 SELECT * FROM t1 [INNER | CROSS] JOIN t2 [ON 连接条件] [WHERE 普通过滤条件]; ログイン後にコピー 也就是说在
上边的这些写法和直接把需要连接的表名放到 SELECT * FROM t1, t2; ログイン後にコピー 现在我们虽然介绍了很多种内连接的书写方式,不过熟悉一种就好了,这里我们推荐INNER JOIN的形式书写内连接(因为INNER JOIN语义很明确嘛,可以和LEFT JOIN和RIGHT JOIN很轻松的区分开)。这里需要注意的是,由于在内连接中ON子句和WHERE子句是等价的,所以内连接中不要求强制写明ON子句。 我们前边说过,连接的本质就是把各个连接表中的记录都取出来依次匹配的组合加入结果集并返回给用户。不论哪个表作为驱动表,两表连接产生的笛卡尔积肯定是一样的。而对于内连接来说,由于凡是不符合ON子句或WHERE子句中的条件的记录都会被过滤掉,其实也就相当于从两表连接的笛卡尔积中把不符合过滤条件的记录给踢出去,所以对于内连接来说,驱动表和被驱动表是可以互换的,并不会影响最后的查询结果。但是对于外连接来说,由于驱动表中的记录即使在被驱动表中找不到符合ON子句连接条件的记录也会被加入结果集,所以此时驱动表和被驱动表的关系就很重要了,也就是说左外连接和右外连接的驱动表和被驱动表不能轻易互换。 小结 上边说了很多,给大家的感觉不是很直观,我们直接把表t1和t2的三种连接方式写在一起,这样大家理解起来就很easy了: mysql> SELECT * FROM t1 INNER JOIN t2 ON t1.m1 = t2.m2; +------+------+------+------+ | m1 | n1 | m2 | n2 | +------+------+------+------+ | 2 | b | 2 | b | | 3 | c | 3 | c | +------+------+------+------+ 2 rows in set (0.00 sec) mysql> SELECT * FROM t1 LEFT JOIN t2 ON t1.m1 = t2.m2; +------+------+------+------+ | m1 | n1 | m2 | n2 | +------+------+------+------+ | 2 | b | 2 | b | | 3 | c | 3 | c | | 1 | a | NULL | NULL | +------+------+------+------+ 3 rows in set (0.00 sec) mysql> SELECT * FROM t1 RIGHT JOIN t2 ON t1.m1 = t2.m2; +------+------+------+------+ | m1 | n1 | m2 | n2 | +------+------+------+------+ | 2 | b | 2 | b | | 3 | c | 3 | c | | NULL | NULL | 4 | d | +------+------+------+------+ 3 rows in set (0.00 sec) ログイン後にコピー 连接查询产生的结果集就好像把散布到两个表中的信息被重新粘贴到了一个表,这个粘贴后的结果集可以方便我们分析数据,就不用老是两个表对照的看了。 多表连接上边说过,如果我们乐意的话可以连接任意数量的表,我们再来创建一个简单的 mysql> CREATE TABLE t3 (m3 int, n3 char(1)); ERROR 1050 (42S01): Table 't3' already exists mysql> INSERT INTO t3 VALUES(3, 'c'), (4, 'd'), (5, 'e'); Query OK, 3 rows affected (0.01 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql> ログイン後にコピー 与 mysql> SELECT * FROM t1 INNER JOIN t2 INNER JOIN t3 WHERE t1.m1 = t2.m2 AND t1.m1 = t3.m3; +------+------+------+------+------+------+ | m1 | n1 | m2 | n2 | m3 | n3 | +------+------+------+------+------+------+ | 3 | c | 3 | c | 3 | c | +------+------+------+------+------+------+ 1 row in set (0.00 sec) mysql> ログイン後にコピー 其实上边的查询语句也可以写成这样,用哪个取决于你的心情: SELECT * FROM t1 INNER JOIN t2 ON t1.m1 = t2.m2 INNER JOIN t3 ON t1.m1 = t3.m3; ログイン後にコピー 这个查询的执行过程用伪代码表示一下就是这样: for each row in t1 {
for each row in t2 which satisfies t1.m1 = t2.m2 {
for each row in t3 which satisfies t1.m1 = t3.m3 {
send to client;
}
}
}ログイン後にコピー 其实不管是多少个表的 表的别名我们前边曾经为列命名过别名,比如说这样: mysql> SELECT number AS xuehao FROM student_info; +----------+ | xuehao | +----------+ | 20180104 | | 20180102 | | 20180101 | | 20180103 | | 20180105 | | 20180106 | +----------+ 6 rows in set (0.00 sec) mysql> ログイン後にコピー 我们可以把列的别名用在 mysql> SELECT number AS xuehao FROM student_info ORDER BY xuehao DESC; +----------+ | xuehao | +----------+ | 20180106 | | 20180105 | | 20180104 | | 20180103 | | 20180102 | | 20180101 | +----------+ 6 rows in set (0.00 sec) mysql> ログイン後にコピー 与列的别名类似,我们也可以为表来定义别名,格式与定义列的别名一致,都是用空白字符或者 mysql> SELECT s1.number, s1.name, s1.major, s2.subject, s2.score FROM student_info AS s1 INNER JOIN student_score AS s2 WHERE s1.number = s2.number; +----------+-----------+--------------------------+-----------------------------+-------+ | number | name | major | subject | score | +----------+-----------+--------------------------+-----------------------------+-------+ | 20180101 | 杜子腾 | 计算机科学与工程 | 母猪的产后护理 | 78 | | 20180101 | 杜子腾 | 计算机科学与工程 | 论萨达姆的战争准备 | 88 | | 20180102 | 杜琦燕 | 计算机科学与工程 | 母猪的产后护理 | 100 | | 20180102 | 杜琦燕 | 计算机科学与工程 | 论萨达姆的战争准备 | 98 | | 20180103 | 范统 | 软件工程 | 母猪的产后护理 | 59 | | 20180103 | 范统 | 软件工程 | 论萨达姆的战争准备 | 61 | | 20180104 | 史珍香 | 软件工程 | 母猪的产后护理 | 55 | | 20180104 | 史珍香 | 软件工程 | 论萨达姆的战争准备 | 46 | +----------+-----------+--------------------------+-----------------------------+-------+ 8 rows in set (0.00 sec) mysql> ログイン後にコピー 这个例子中,我们在 自连接我们上边说的都是多个不同的表之间的连接,其实同一个表也可以进行连接。比方说我们可以对两个 mysql> SELECT * FROM t1, t1; ERROR 1066 (42000): Not unique table/alias: 't1' mysql> ログイン後にコピー 咦,报了个错,这是因为设计MySQL的大叔不允许 mysql> SELECT * FROM t1 AS table1, t1 AS table2; +------+------+------+------+ | m1 | n1 | m1 | n1 | +------+------+------+------+ | 1 | a | 1 | a | | 2 | b | 1 | a | | 3 | c | 1 | a | | 1 | a | 2 | b | | 2 | b | 2 | b | | 3 | c | 2 | b | | 1 | a | 3 | c | | 2 | b | 3 | c | | 3 | c | 3 | c | +------+------+------+------+ 9 rows in set (0.00 sec) mysql> ログイン後にコピー 这里相当于我们为 mysql> SELECT s2.number, s2.name, s2.major FROM student_info AS s1 INNER JOIN student_info AS s2 WHERE s1.major = s2.major AND s1.name = '史珍香' ; +----------+-----------+--------------+ | number | name | major | +----------+-----------+--------------+ | 20180103 | 范统 | 软件工程 | | 20180104 | 史珍香 | 软件工程 | +----------+-----------+--------------+ 2 rows in set (0.01 sec) mysql> ログイン後にコピー
连接查询与子查询的转换有的查询需求既可以使用连接查询解决,也可以使用子查询解决,比如 SELECT * FROM student_score WHERE number IN (SELECT number FROM student_info WHERE major = '计算机科学与工程'); ログイン後にコピー 这个子查询就可以被替换: SELECT s2.* FROM student_info AS s1 INNER JOIN student_score AS s2 WHERE s1.number = s2.number AND s1.major = '计算机科学与工程'; ログイン後にコピー 大家在实际使用时可以按照自己的习惯来书写查询语句。
推荐学习:mysql视频教程 |
以上がMySQL 接続クエリの基本について話しましょうの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

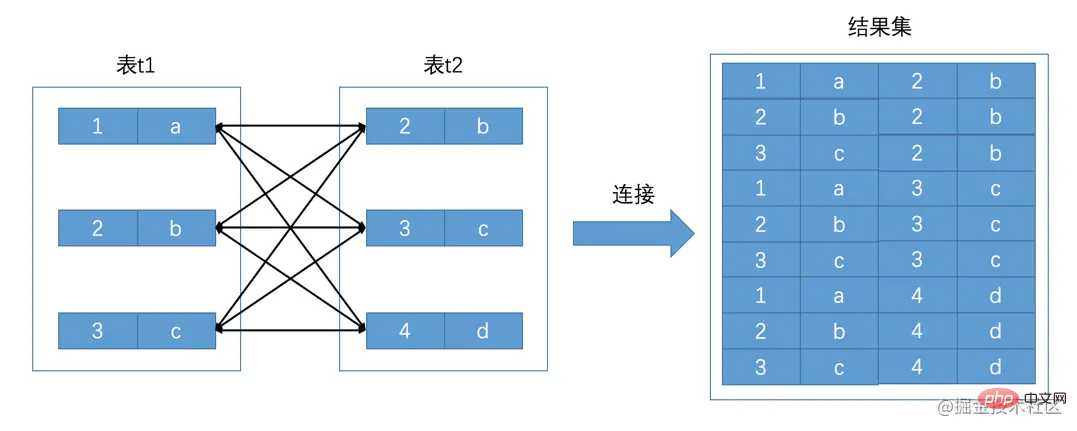 デカルト積
デカルト積
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



