


MySQL データベース コマンドの爆発的なコレクション (概要の共有)

この記事では、mysql データベース コマンドに関する関連知識を提供します。一般的に使用されるコマンドが多数リストされています。皆様のお役に立てれば幸いです。

#mysql -u ユーザー名 -p パスワード
2. 既存のデータベースを表示します
show Databases;
3. データベースを作成します
create database sqlname;
4. データベースを選択します
use database sqlname;
5. データベース内のテーブルを表示します (最初にデータベースを選択します)
show tables;
6. 現在のデータベースのバージョン情報を表示します。データベースと接続ユーザーの名前
select version(),user();
7. データベースを削除します (削除時にプロンプトなしで削除)
drop database sqlname;
2. データベース内のテーブルのコマンド
1. テーブルの作成
(1) 構文:
create table tablename(
フィールド 1 データ型フィールド 属性 …
フィールド n
);
(2) 注:
1. テーブル作成時に予約語との競合を防ぐため、テーブルを '' # で囲みます。 ## 2. 単一行のコメント : #…
複数行のコメント : /
…
/
3. テーブルを作成するときは、複数のフィールドを英語のカンマで区切ります。カンマは使用しないでください。最後の行で。 (3) フィールドの制約と属性 1. 非 null 制約
not null (フィールドを空にすることはできません)
2. デフォルト制約default(デフォルトを設定) value)
3. 一意の制約unique key(uk)(設定されたフィールドの値は一意で空にすることもできますが、空の値は 1 つだけです)
4 . 主キー制約主キー(pk)(テーブルレコードの一意の識別子として)
5. 外部キー制約外部キー(fk)(テーブルレコード間の関係を確立するために使用されます) 2 つのテーブルの場合、メイン テーブルのどのフィールドを指定する必要があります。InnoDB はデータベース ストレージ エンジンの外部キーをサポートしていますが、MyISAM は外部キーをサポートしていません。
外部キーとして使用されるフィールドは、メイン テーブルの主キーである必要があります。メイン テーブル (単一フィールドの主キー))外部キー制約の追加:
CONSTRAINT FK_外部キー名 FOREIGN KEY (ワード テーブル内の外部キー フィールド) REFERENCES 関連するテーブル名 (関連フィールド)。
MySQL データベース コマンドの爆発的なコレクション (概要の共有) はワードテーブルの外部キーとして使用されます 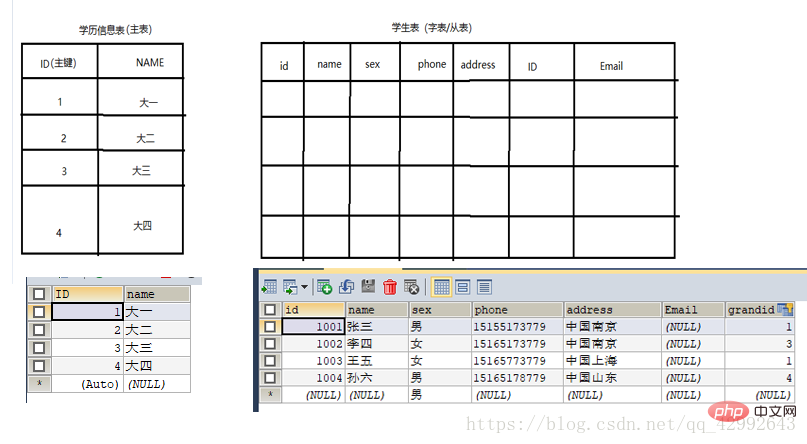 1.
1.
n から始まる auto_increment=n を設定します。 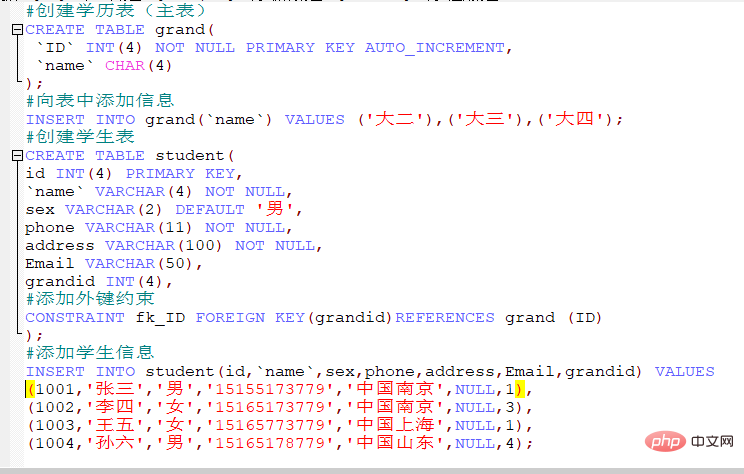
2.自動インクリメント セット @@ auto_increment_increment=m を設定します。ステップ サイズは m です。
3. 複数フィールド設定の主キー:
主キー (フィールド 1、フィールド 2...フィールド n) 
4. コメント/説明文表内 :)comment="説明";
5. 文字セットを設定します:)charset="文字セット";
6. の構造を表示します。テーブル:describe'table name'/desc table name
7. データベース定義を表示します: show create database sqlname;
8. データ テーブル定義を表示します: show create table tablename ;
9. デフォルトのストレージ エンジンを表示します: show variables like'storage_engine%';
11. テーブルのストレージ エンジンを指定します:) engine=storage Engine;
10. テーブルの削除: drop table 'tablename';
11. 現在の日付の取得: now();
12. テーブルの変更: (1) テーブル名の変更: alter table old table name rename new table name;
(2) フィールドの追加: alter table table name add field name data type...;(新しいフィールドの追加)
(3) フィールドの変更: alter table テーブル名の変更 元のフィールド名 新しいフィールド名のデータ型...;
(4) フィールドの削除: alter table テーブル名ドロップ フィールド名;
(5) テーブルの作成後に主キー制約を追加: alter table table name addconstraintprimaryキー名 主キー テーブル名 (主キー フィールド);
(6) テーブルの作成後、外部キー制約を追加します (外部キーとして使用されるフィールドは、メイン テーブル (単一の) の主キーである必要があります)フィールド主キー)): alter table テーブル名 add constraint 外部キー名 外部キー (外部キー フィールド) 参照関連テーブル名 (関連フィールド);
Insert data
2. 複数行のデータを挿入します。 insert into table name (field name list) names (value List 1), … ,(value list n);
3.クエリ結果を新しいテーブルに追加します: create table new table (元のテーブルからフィールド 1, … を選択します) ;
查询student表中的id,name,sex,phone数据插入到newstudent表中: CREATE TABLE newstudent(SELECT id,`name`,sex,phone FROM student);3. データを更新します (データを変更します): 更新テーブル名セット列名 = 更新条件の更新値;
修改newstudent表中id=1001的数据名字为tom: UPDATE newstudent SET `name`='tom' WHERE id=1001;4 .データの削除 (1)削除条件のテーブル名から削除;
delete は、単一の列だけではなく、データ全体を削除します。 删除newstudent表中名字为tom的数据:
DELETE FROM newstudent WHERE `name`='tom';
(2) Truncate table はデータを削除します:
truncate table はテーブル内のすべての行を削除しますが、テーブルの構造、列、制約、インデックスなどは変更されません。外部キー制約のあるテーブルには使用できません。削除されたデータは復元できません。
削除条件のテーブルテーブル名を切り詰めます;
数据查询
1.使用select查询
select 列名/表达式/函数/常量 from 表名 where 查询条件 order by 排序的列名asc/desc;
(1)查询所有的数据行和列:
select * from 表名;
(2)查询部分行和列:
select 列名… from 表名 where 查询条件;
(3)在查询中使用列的别名:
select 列名 AS 新列名 form 表名 where 查询条件;
计算,合并得到新的列名:
select 列名1+’.’+列名2 AS 新列名 from 表名;
(4)查询空值:
通过is null 或者 is not null 判断列值是否为空
查询student表中Email为空的学生姓名: SELECT `name` FROM student WHERE Email IS NULL;
2.分组查询
#查询不同课程的平均分,最低分,最高分,并查询出平均分大于80分的课程 SELECT r.subjectno,sub.`SubjectName` 课程名称,AVG(StudentResult) 平均分, MAX(StudentResult) 最高分,MIN(StudentResult) 最低分 FROM result r INNER JOIN `subject` sub ON r.`SubjectNo`=sub.`SubjectNo` GROUP BY r.subjectno #where AVG(StudentResult)>=80出现错误, #分组查询group by 在where语句后, #group by 约束条件使用having语句 HAVING AVG(StudentResult)>=80;
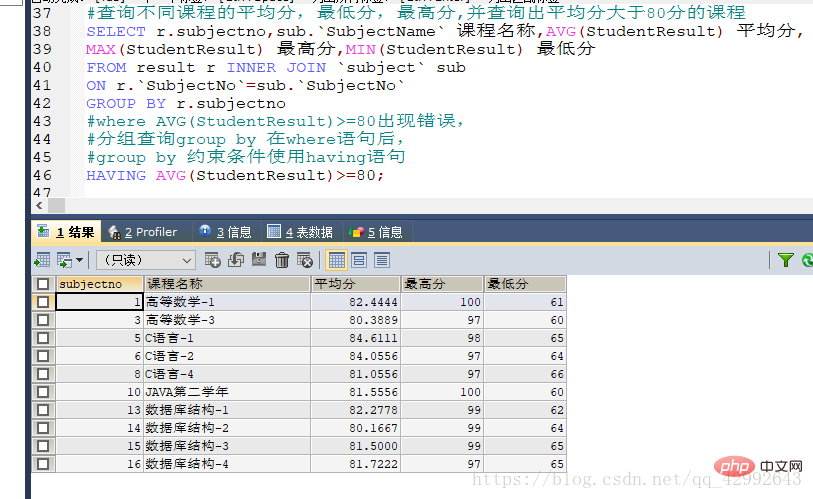
常用函数
1.聚合函数:
(1)AVG (平均值):select avg(列名)from 表名
假设列名为成绩 则查询到的是表中所有成绩的平均值。
(2)count 返回某字段的行数
(3)max 返回某字段的最大数
(4)min 返回某字段的最小值
(5)sum 返回某字段的和。
2.字符串函数:
(1)concat() 连接字符串s1,s2…sn为一个完整的字符串。
(2)insert(s1,p1,n,news)将字符串s1从p1位置开始,n个字符长的字串替换为字符串news。
(3)lower(s)将字符串s中的所有字符改为小写。
(4)upper(s)将字符串s中的所有字符改为大写。
(5)substring(s,num,len)返回字符串s的第num个位置开始长度为len的子字符串。
3.时间日期函数:
(1)获取当前日期:curdate();
(2)获取当前时间:curtime();
(3)获取当前日期和时间:now();
(4)返回日期date为一年中的第几周:week(date);
(5)返回日期date的年份:year(date);
(6)返回时间time的小时值:hour(time);
(7)返回时间time的分钟值:minute(time);
(8)返回日期参数(date1和date2之间相隔的天数):datediff(date1,date2);
(9)计算日期参数date加上n天后的日期:adddate(date,n);
4.数学函数
(1)返回大于或等于数值x的最小整数:ceil(x);
(2)返回小于或等于数值x的最大整数:floor(x);
(3)返回0~1之间的随机数:rand();
order by 子句
order by子句按照一定的顺序排列查询结果,asc升序排列,desc降序排列。
limit子句
显示指定位置指定行数的记录。
select 字段名列表 form 表名 where 约束条件 group by分组的字段名 order by 排序列名 limit 位置偏移量,行数;
#查询学生信息里gid=1按学号升序排列前四条记录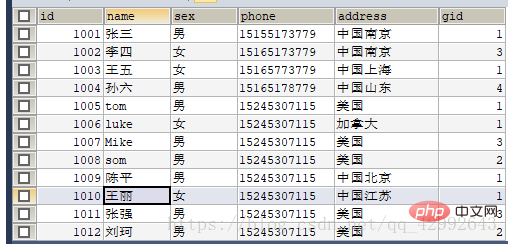
#查询学生信息里gid=1按学号升序排列前四条记录(步长) SELECT id,`name` FROM `student1` WHERE gid=1 ORDER BY id LIMIT 4; (查询表里全部信息中gid=1的前四个学生)
查询结果: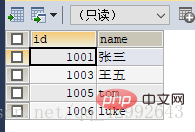
#查询学生信息里gid=1按学号升序排列前四条记录(位置偏移量,步长) SELECT id,`name` FROM `student1` WHERE gid=1 ORDER BY id LIMIT 4,4; (查询表中全部信息gid=1前四条以后的全部信息中的前四条学生信息)
查询结果: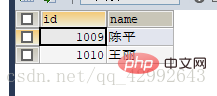
模糊查询
in子查询******not in 子查询
使用in关键字可以使父查询匹配子查询返回的多个单字段值。
解决使用比较运算符(=,>等),子查询返回值不唯一错误信息。
like模糊查询
LIKE语句语法格式:select * from 表名 where 字段名 like 对应值(子串)。
它主要是针对字符型字段的,它的作用是在一个字符型字段列中检索包含对应子串的。
A:% 包含零个或多个字符的任意字符串: 1、LIKE’Mc%’ 将搜索以字母 Mc 开头的所有字符串(如 McBadden)。
2、LIKE’%inger’ 将搜索以字母 inger 结尾的所有字符串(如 Ringer、Stringer)。
3、LIKE’%en%’ 将搜索在任何位置包含字母 en 的所有字符串(如 Bennet、Green、McBadden)。
B:_(下划线) 任何单个字符:LIKE’_heryl’ 将搜索以字母 heryl 结尾的所有六个字母的名称(如 Cheryl、Sheryl)。
C:[ ] 指定范围 ([a-f]) 或集合 ([abcdef]) 中的任何单个字符:、
1,LIKE’[CK]ars[eo]n’ 将搜索下列字符串:Carsen、Karsen、Carson 和 Karson(如 Carson)。
2、LIKE’[M-Z]inger’ 将搜索以字符串 inger 结尾、以从 M 到 Z 的任何单个字母开头的所有名称(如 Ringer)
***D:[^] 不属于指定范围 ([a-f]) 或集合 ([abcdef]) 的任何单个字符:LIKE’M[^c]%’ 将搜索以字母 M 开头,并且第二个字母不是 c 的所有名称(如MacFeather)。
E: 它同于DOS命令中的通配符,代表多个字符:cc代表cc,cBc,cbc,cabdfec等多个字符。
F:?同于DOS命令中的?通配符,代表单个字符 :b?b代表brb,bFb等
G:# 大致同上,不同的是代只能代表单个数字。k#k代表k1k,k8k,k0k 。
F:[!] 排除 它只代表单个字符
下面我们来举例说明一下:
例1,查询name字段中包含有“明”字的。
select * from table1 where name like ‘%明%’
例2,查询name字段中以“李”字开头。
select * from table1 where name like '李’
例3,查询name字段中含有数字的。
select * from table1 where name like ‘%[0-9]%’
例4,查询name字段中含有小写字母的。
select * from table1 where name like ‘%[a-z]%’
例5,查询name字段中不含有数字的。
select * from table1 where name like ‘%[!0-9]%’
可以自定义转移符----》escape’自定义转移符’
distinct------》去除重复项
between*and模糊查询
操作符 BETWEEN … AND 会选取介于两个值之间的数据范围。这些值可以是数值、文本或者日期。
null ,not null查询
-- 查询手机号不为null的用户数据 SELECT * from user where phone is not null; -- 查询手机号为null的用户数据 SELECT * from user where phone is null;
exists 子查询 not exists子查询
exists子查询用来确认后边的查询是否继续进行
drop table if exists test—>判断是否存在表test,如果存在就删除。
not exists实现取反操作。对不存在对应查询条件的记录。
多表连接查询
多表连接查询是通过各个表之间共同列的关联性来查询数据。
1.内连接查询
内连接查询根据表中共同的列进行匹配。取两个的表的交集。两个表存在主外键关系是通常使用内连接查询。
内连接使用inner join…on 关键字或者where子句来进行表之间的关联。
inner 可省略 on 用来设置条件。
(1)在where子句中指定连接条件
(2)在from中使用inner join…on关键字
#查询学生姓名和成绩 SELECT studentname,studentresult FROM student s,result r WHERE s.`StudentNo`=r.`StudentNo`
#在from中使用inner join....on关键字 SELECT s.`StudentName`,r.`StudentResult` ,r.`SubjectNo`FROM student s INNER JOIN result r ON s.`StudentNo`=r.`StudentNo`
两种方法查询结果相同。
2.外连接查询
外连接查询中参与连接的表有主从之分,已主表的每行数据匹配从表的数据列,将符合连接条件的数据直接返回到结果集中,对不符合连接条件的列,将被填上null值再返回到结果集中。
(1)左外连接查询
left join…on 或者left outer join…on关键字进行表之间的关联。
SELECT s.`StudentName`,r.`StudentResult` ,r.`SubjectNo`FROM student s LEFT JOIN result r ON s.`StudentNo`=r.`StudentNo`
将没有成绩的学生成绩查出。
(2)右外连接查询
右外连接包含右表中所有的匹配行,右表中有的项在左表中没有对应的项将以null值填充。
right join…on 或right outer join…on关键字进行表之间的关联。
(3)自连接
把一个表作为两个表使用。
#创建一个表 CREATE TABLE book( id INT(10), sort INT(10), books VARCHAR(10) NOT NULL ); #插入数据 INSERT INTO book VALUES (2,1,'古文书'), (3,1,'现代书'), (4,2,'《三字经》'), (5,2,'《唐诗三百首》'), (6,3,'《我与地坛》'), (7,2,'《游大林寺》'), (8,2,'《王右军年减十岁时》'), (9,3,'《致橡树》'); #查询结果为: #书籍类型 书籍名 #古文书 三字经.... #现代书 我与地坛.... SELECT a.books 书籍类型, b.books 书籍名 FROM book a,book b WHERE a.id=b.sort;
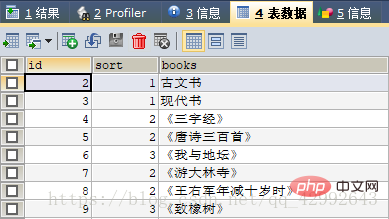
自连接查询结果: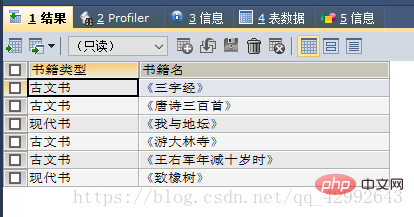
MySQL のトランザクション、ビュー、インデックス、バックアップとリカバリ
1. トランザクション
トランザクションとは、一連のデータ操作を 1 つにまとめて一元管理することを指します。
作成リクエストをすべてのコマンドと一緒にシステムに送信またはキャンセルします。
トランザクションのプロパティ: アトミック性、一貫性、分離性、耐久性。
myISA ストレージ エンジンはトランザクションをサポートしていません。
自動トランザクション送信をオフにする: set autocommit=0;
(1) トランザクションの開始: begin/starttransaction;
(2) トランザクションの送信: commit;
(3) Rollback/トランザクションを元に戻す: rollback;
自動送信を再開する: set autocommit=1;
結果セットを次のように設定しますか? ?エンコード形式の表示: 名前を設定しますか? ? ;
2. ビュー
ビューは、データベース内の 1 つ以上のテーブルのデータを表示する方法です。ビューは、1 つ以上のテーブルの行または列のサブセットとして作成された仮想テーブルです。ビューはクエリ内のテーブル フィルターとして機能します。
(1) ビューの作成: create view ビュー名 as
インデックスの作成:
create [インデックス タイプ] インデックス テーブル名 (インデックスを作成する列) のインデックス名;
または、テーブルの作成時に列の後に追加します インデックス タイプ。
またはテーブルを変更します alter table table name addindex インデックス名 (インデックス列);
インデックスの削除: インデックスのインデックス名を削除;
インデックスの表示: テーブル名からインデックスを表示;
4データベースのバックアップとリカバリ
1. mysqldump コマンドを使用してデータベースをバックアップします
mysqldump -u -p データベース名>バックアップ データベースの場所と名前;
テーブル データのエクスポート テキスト ファイルへのエクスポート
select *from table name whereクエリ条件を outfile バックアップ データベースの場所と名前に;
2. mysql コマンドを使用してデータベースを復元します (最初に新しいデータベースを作成します)
mysql -u -p 新しく作成したデータベース名データベースを復元するソース コマンド
ソース データベース バックアップ ファイル;
新しいユーザーの作成
#ローカル ユーザーの作成
CREATE USER `user`@`localhost` IDENTIFIED BY ' 123123';
#ユーザーは、ワイルドカード %
CREATE USER `user2`@`123%` IDENTIFIED BY '123123';
を使用して、任意のリモート ホストにログインできます。 #ユーザーにすべての権限を許可します
#GRANT ALL ON mysql.`user` TO `user2`@`123%`;##作成したユーザーを許可します
#GRANT SELECT ,INSERT ON mysql.`user` TO `user2`@` 123%`; #ユーザー作成時の認可GRANT SELECT,INSERT ON mysql.`user` TO `user_2` @`123%` IDENTIFIED BY '123123';#ユーザー user2 を削除します (削除ステートメントを使用する場合は、データベースのグローバル権限または選択権限が必要です)DROP USER `user2`@` 123%`;DROP USER `user_2`@` 123%`;DROP USER `user`@`localhost`;##mysqladmin はスーパー ユーザー user2 を変更しますアカウントのパスワード (mysqladmin コマンドは cmd で使用され、スーパー ユーザーのパスワードのみ変更できます)
mysqladmin -u root -p PASSWORD "123456";
##現在のログイン ユーザーのパスワードを変更しますSET PASSWORD =PASSWORD("123456"); #他のユーザーのパスワードを変更するSET PASSWORD FOR `user2`@`123%`=PASSWORD("123456") ;推奨学習:
mysql ビデオ チュートリアル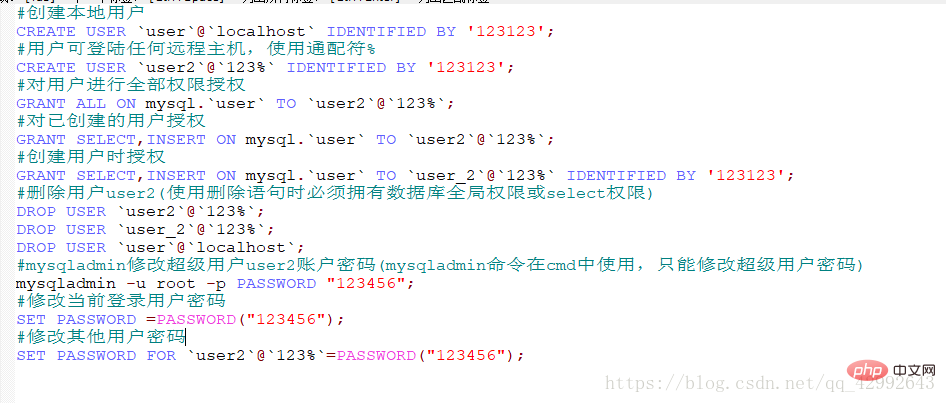
以上がMySQL データベース コマンドの爆発的なコレクション (概要の共有)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undress AI Tool
脱衣画像を無料で

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)



 MySQLにすべてのデータベースを表示する方法
Aug 08, 2025 am 09:50 AM
MySQLにすべてのデータベースを表示する方法
Aug 08, 2025 am 09:50 AM
MySQLにすべてのデータベースを表示するには、ShowDataBaseコマンドを使用する必要があります。 1.MySQLサーバーにログインした後、ShowDatabaseを実行できます。現在のユーザーがアクセスする許可があるすべてのデータベースをリストするコマンド。 2。information_schema、mysql、performance_schema、sysなどのシステムデータベースはデフォルトで存在しますが、許可が不十分なユーザーはそれを見ることができない場合があります。 3. selectschema_namefrominformation_schema.schemataを介してデータベースをクエリしてフィルタリングすることもできます。たとえば、システムデータベースを除外して、ユーザーが作成したデータベースのみを表示します。必ず使用してください
 MySQLの既存のテーブルに主キーを追加する方法は?
Aug 12, 2025 am 04:11 AM
MySQLの既存のテーブルに主キーを追加する方法は?
Aug 12, 2025 am 04:11 AM
既存のテーブルにプライマリキーを追加するには、AddPrimaryKey句を使用してAlterTableステートメントを使用してください。 1.ターゲット列にヌル値も重複もなく、notnullと定義されていることを確認してください。 2.単一列のプライマリキー構文は、変更可能なテーブル名AddPrimaryKey(列名)です。 3.マルチカラムの組み合わせプライマリキー構文は、変更可能なテーブル名AddPrimaryKeyです(列1、列2)。 4.列がnullを許可する場合、最初に変更を実行してnotnullを設定する必要があります。 5.各テーブルには1つの主キーのみがあり、追加する前に古いプライマリキーを削除する必要があります。 6.自分で増やす必要がある場合は、Modifyを使用してAuto_incrementを設定できます。操作前にデータを確認してください
 一般的なMySQL接続エラーのトラブルシューティング方法は?
Aug 08, 2025 am 06:44 AM
一般的なMySQL接続エラーのトラブルシューティング方法は?
Aug 08, 2025 am 06:44 AM
MySQLサービスが実行されているかどうかを確認して、sudosystemctlstatusmysqlを使用して確認および開始します。 2.リモート接続を許可してサービスを再起動するために、バインドアドレスが0.0.0.0に設定されていることを確認してください。 3. 3306ポートが開いているかどうかを確認し、ポートを許可するファイアウォールルールを確認して構成します。 4。「アクセス」エラーの場合、ユーザー名、パスワード、ホスト名を確認し、mysqlにログインしてmysql.userテーブルをクエリしてアクセス許可を確認する必要があります。必要に応じて、 'your_user'@'%'を使用するなど、ユーザーを作成または更新して承認します。 5. caching_sha2_passwordにより認証が失われた場合
 MySQLのデータベースをバックアップする方法
Aug 11, 2025 am 10:40 AM
MySQLのデータベースをバックアップする方法
Aug 11, 2025 am 10:40 AM
MySQLDUMPを使用することは、MySQLデータベースをバックアップする最も一般的で効果的な方法です。テーブル構造とデータを含むSQLスクリプトを生成できます。 1.基本的な構文は、mysqldump-u [ユーザー名] -p [データベース名]> backup_file.sqlです。実行後、パスワードを入力してバックアップファイルを生成します。 2。-DATABASESオプションを使用して複数のデータベースをバックアップします:mysqldump-uroot-p--databasedb1db2> multive_dbs_backup.sql。 3.すべてのデータベースをバックアップしてください-all-database:mysqldump-uroot-p
 MySQL支援PHPアプリケーションのデータベースインデックス作成戦略(B-Tree、フルテキストなど)を説明します。
Aug 13, 2025 pm 02:57 PM
MySQL支援PHPアプリケーションのデータベースインデックス作成戦略(B-Tree、フルテキストなど)を説明します。
Aug 13, 2025 pm 02:57 PM
b-TreeindexeSareBestformostphpapplications、astheisupportequalityandrangequeries、sorting、andareidealforumnsuseduseduseduseduseduseduseduseds; ororderbyclauses;
 MySQLのすべての組合と組合の違いは何ですか?
Aug 14, 2025 pm 05:25 PM
MySQLのすべての組合と組合の違いは何ですか?
Aug 14, 2025 pm 05:25 PM
UnionRemovesDulisionallkeepsallowsincludingDuplicates;
 mysqlのgroup_concatセパレーターを変更する方法
Aug 22, 2025 am 10:58 AM
mysqlのgroup_concatセパレーターを変更する方法
Aug 22, 2025 am 10:58 AM
Group_concat()関数のセパレーターキーワードを使用して、セパレーターをカスタマイズできます。 1.セパレーターを使用して、セパレーターなどのカスタムセパレーターを指定します。 'セパレーターは、セミコロンとプラススペースに変更できます。 2.一般的な例には、パイプ文字 '|'、スペース ''、ラインブレイク文字 '\ n'、またはカスタム文字列 ' - >'をセパレーターとして使用することが含まれます。 3.セパレーターは文字列リテラルまたは式である必要があり、結果の長さはgroup_concat_max_len変数によって制限されていることに注意してください。 4。セパレーターはオプションです
 MySQLでテーブルをロックする方法
Aug 15, 2025 am 04:04 AM
MySQLでテーブルをロックする方法
Aug 15, 2025 am 04:04 AM
テーブルは、ロックテーブルを使用して手動でロックできます。読み取りロックにより、複数のセッションが読み取ることができますが、書き込むことはできません。 Write Lockは、現在のセッションの排他的な読み取りおよび書き込み許可を提供し、他のセッションは読み書きできません。 2。ロックは現在の接続のみです。 StartTransactionおよびその他のコマンドの実行は、暗黙的にロックをリリースします。ロック後、ロックされたテーブルのみにアクセスできます。 3. Myisamテーブルのメンテナンスやデータバックアップなどの特定のシナリオでのみ使用します。 INNODBは、パフォーマンスの問題を回避するための... forupdateなどのトランザクションおよび行レベルのロックを使用することを優先する必要があります。 4。操作が完了した後、ロックテーブルを明示的にリリースする必要があります。そうしないと、リソースの閉塞が発生する可能性があります。
