


この記事では、count()、union()、および group by ステートメントについて説明し、MySQL の知識ポイント (さまざまな count() の使用法、union 実行プロセス、group by ステートメント) を補足します。

count() は、返される結果セットの集計関数です。 , 1行ずつ判断し、count関数のパラメータがNULLでなければ累積値に1を加算し、それ以外の場合は加算しません。最後に、累積値が返されます。 [関連する推奨事項: mysql ビデオ チュートリアル ]
1. count (主キー ID) の場合、InnoDB エンジンはテーブル全体を走査し、各行の ID 値を取り出して返します。サーバー層へ。サーバー層は ID を取得した後、それを空にすることはできないと判断し、行
2 ごとにそれを蓄積します。count(1) の場合、InnoDB エンジンはテーブル全体を走査しますが、値は取得しません。サーバー層は返された各行に数値 1 を入れます。空にすることはできないと判断され、行ごとに
3 が累積されます。カウント (フィールド) については、このフィールドが not null として定義されている場合、このフィールドを読み取りますレコードから一行ずつ取り出してnullになり得ないと判断して一行ずつ蓄積していくが、フィールド定義でnullが許されていれば実行時にnullでもよいと判断して値を取り出す必要がある。さて、
4 を蓄積するのは null ではありません。count(*) については、すべてのフィールドが取り出されるわけではありませんが、特別に最適化されます。値は取得されません。count(*) は明らかに null ではなく、行ごとに累積されます

create table t1(id int primary key, a int, b int, index(a));
CREATE DEFINER=`root`@`%` PROCEDURE `idata`()
BEGIN
declare i int;
set i=1;
while(i<=1000)do
insert into t1 values(i, i, i);
set i=i+1;
end while;
END(select 1000 as f) union (select id from t1 order by id desc limit 2);

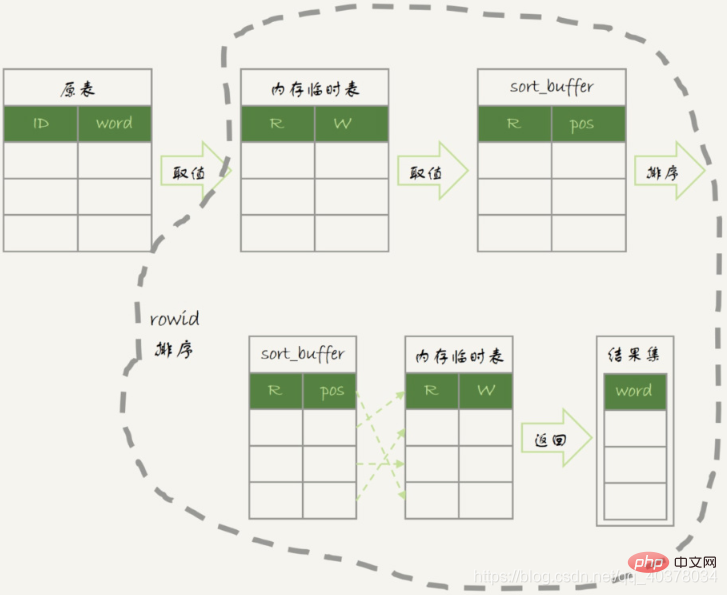
1. メモリ一時テーブルを作成します。この一時テーブルには整数フィールド f が 1 つだけあり、f は主キー フィールド
2 です。最初のサブクエリを実行して、値 1000
3 を取得します。2 番目のサブクエリを実行します:
最初の行 id=1000 を取得し、それを一時テーブルに挿入してみます。しかし、値 1000 は一時テーブルにすでに存在しているため、一意性制約に違反するため、挿入は失敗し、引き続き、union()、および group by ステートメントの詳細な説明)

3. group by ステートメントの詳細説明
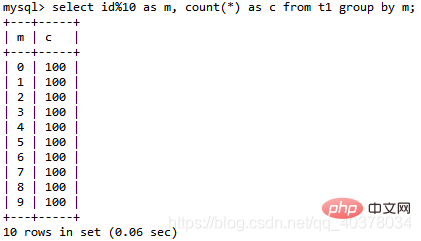
select id%10 as m, count(*) as c from t1 group by m;
[Extra] フィールドには、次の 3 つの情報が表示されます。
 Using Index。このステートメントがインデックスをカバーし、インデックス a を選択しました。テーブルに戻る必要はありません。
Using Index。このステートメントがインデックスをカバーし、インデックス a を選択しました。テーブルに戻る必要はありません。
として記録されます一時テーブルのキー x にレコード (x,1) を挿入します。
テーブル行に主キー x を持つ行がある場合、その行の c 値に 1 を加算します。
内存临时表排序流程图:
如果并不需要对结果进行排序,在SQL语句末尾增加order by null:
select id%10 as m, count(*) as c from t1 group by m order by null;
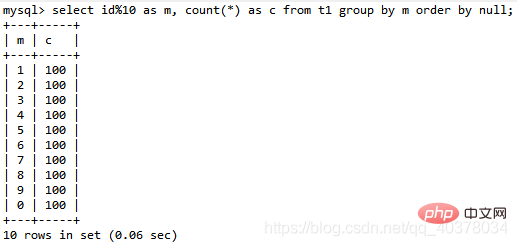
由于表t1中的id值是从1开始的,因此返回的结果集中第一行是id=1
这个例子里由于临时表只有10行,内存可以放得下,因此全程只使用了内存临时表。但是,内存临时表的大小是有限的,参数tmp_table_size就是控制整个内存大小的,默认是16M
set tmp_table_size=1024; select id%100 as m, count(*) as c from t1 group by m order by null limit 10;
把内存临时表的大小限制为最大1024字节,并把语句改成id%100,这样返回结果里有100行数据。但是,这时的内存临时表大小不够存下这100行数据,也就是说,执行过程中会发现内存临时表大小达到了上限。那么,这时候会把内存临时表转成磁盘临时表,磁盘临时表默认使用的引擎是InnoDB
group by的语义逻辑,是统计不同的值的个数。但是,由于每一行的id%100的结果是无序的,所以就需要有一个临时表来记录并统计结果。那么,如果扫描过程中可以保证出现的数据是有序的就可以了
假设,现在有一个类似下图的这么一个数据结构

如果可以确保输入的数据是有序的,那么计算group by的时候,就只需要从左到右,顺序扫描,依次累加。也就是下面这个流程:
按照这个逻辑执行的话,扫描到整个输入的数据结束,就可以拿到group by的结果,不需要临时表,也需要再额外排序
在MySQL5.7版本支持了generated column机制,用来实现列数据的关联更新。创建一个列z,在z列上创建一个索引
alter table t1 add column z int generated always as(id % 100), add index(z);
这样,索引z上的数据就是有序的了。group by语句就可以改成:
select z, count(*) as c from t1 group by z;

从这个Extra字段可以看到,这个语句的执行不再需要临时表,也不需要排序了
在group by语句中加入SQL_BIG_RESULT这个提示,就可以告诉优化器:这个语句涉及的数据量很大,直接用磁盘临时表。因为磁盘临时表是B+树存储,存储效率不如数组来得高。所以MySQL优化器直接用数组来存
select SQL_BIG_RESULT id%100 as m, count(*) as c from t1 group by m;
1.初始化sort_buffer,确定放入一个整型字段,记为m
2.扫描表t1的索引a,依次取出里面的id值,将id%100的值存入sort_buffer中
3.扫描完成后,对sort_buffer的字段m做排序(如果sort_buffer内存不够用,就会利用磁盘临时文件辅助排序)
4.排序完成后,就得到了一个有序数组
根据有序数组,得到数组里面的不同值,以及每个值的出现次数
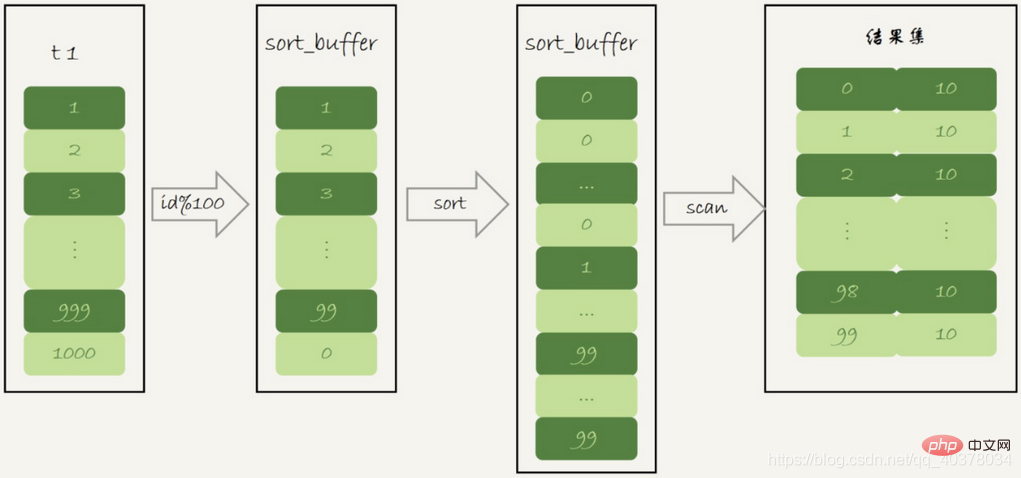
这个语句的执行没有再使用临时表,而是直接用了排序算法
更多编程相关知识,请访问:编程入门!!
以上がMySQL の count()、union()、および group by ステートメントの詳細な説明の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。














%E3%80%81union()%E3%80%81%E3%81%8A%E3%82%88%E3%81%B3%20group%20by%20%E3%82%B9%E3%83%86%E3%83%BC%E3%83%88%E3%83%A1%E3%83%B3%E3%83%88%E3%81%AE%E8%A9%B3%E7%B4%B0%E3%81%AA%E8%AA%AC%E6%98%8E)















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



