


単一テーブル クエリとは、1 つのテーブル内のデータをクエリすることを指します。その実行順序は、「from->where->group by->having->distinct->order by->limit-」です。 >選択してください。」

データベース操作における単一テーブル クエリとは、1 つのテーブル内のデータをクエリすることです。その詳細な構文は次のとおりです:
select distinct 字段1,字段2... from 表名 where 分组之前的过滤条件 group by 分组字段 having 分组之后的过滤条件 order by 排序字段 limit 显示的条数;
構文はこの順序ですが、実行順序は構文の順序に基づくのではなく、この順序になります。
どこから--->どこ--->グループ化--->持っている--->区別--->順序--->制限--- >select
なぜこのような実行順序になったのかについては、明言しませんし、明確に説明する自信もありません。初心者の場合は、この実行シーケンスを覚えておくだけで済みますが、詳細を知りたい場合は、Google にアクセスしてください。
単一テーブル クエリを理解する前に、まず従業員テーブルを作成します:
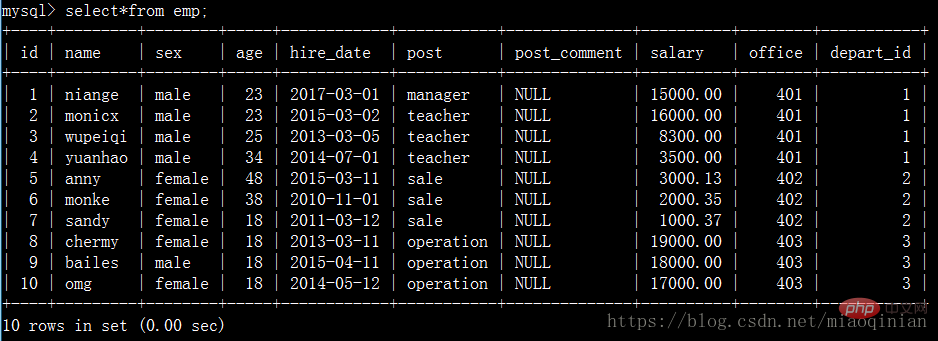
emp表: 员工id id int 姓名 emp_name varchar 性别 sex enum 年龄 age int 入职日期 hire_date date 岗位 post varchar 职位描述 post_comment varchar 薪水 salary double 办公室 office int 部门编号 depart_id int
テーブルの構築:
create table emp( id int not null unique auto_increment, name varchar(20) not null, sex enum('male','female') not null default 'male', age int(3) unsigned not null default 28, hire_date date not null, post varchar(50), post_comment varchar(100), salary double(15,2), office int, depart_id int );
データの挿入:
insert into emp(name,sex,age,hire_date,post,salary,office,depart_id) values ('niange','male',23,'20170301','manager',15000,401,1), ('monicx','male',23,'20150302','teacher',16000,401,1), ('wupeiqi','male',25,'20130305','teacher',8300,401,1), ('yuanhao','male',34,'20140701','teacher',3500,401,1), ('anny','female',48,'20150311','sale',3000.13,402,2), ('monke','female',38,'20101101','sale',2000.35,402,2), ('sandy','female',18,'20110312','sale',1000.37,402,2), ('chermy','female',18,'20130311','operation',19000,403,3), ('bailes','male',18,'20150411','operation',18000,403,3), ('omg','female',18,'20140512','operation',17000,403,3);
where 句で使用できます:
1. 比較演算子: >、<、>=、<=、<>、 !=。
2. 1 ~ 5 の間 値は 1 ~ 5 の間です。
3. in(1,3,8) の値は 1 または 3 または 8 です。
4. like 'monicx%'
% は任意の数の文字を表します
_ は 1 つの文字を表します
5. 論理演算子: 論理演算子は複数の条件で直接使用でき、 、 か否か。
6, 正規表現
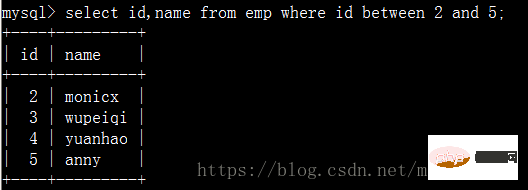
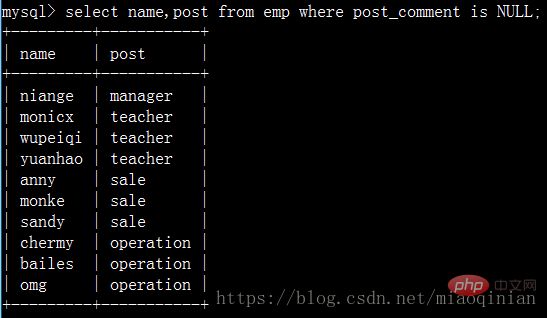
ID が 2 ~ 5 の従業員の名前を検索します:
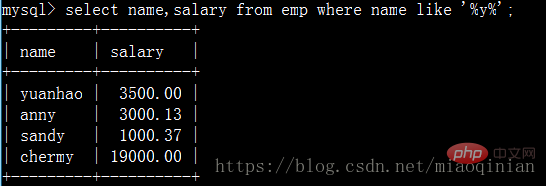
名前に文字 y が含まれる従業員の名前とその給与をクエリします。
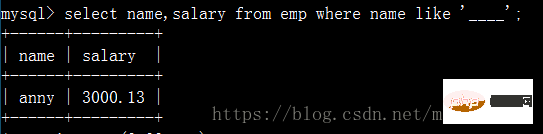
名前が 4 文字で構成される従業員の名前をクエリします。給与:

set global sql_mode="strict_trans_tables,only_full_group_by";
たとえば、各部門の最高給与を取得します。
例: 各部門の従業員数を取得します。
「every」という単語の後のフィールドがグループ化の基礎となります。
注: 任意のフィールドでグループ化できますが、投稿ごとにグループ化するなど、グループ化した後は、投稿フィールドのみを表示できます。
Aggregation (集まって 1 つのコンテンツを合成する)関数を使用する必要があります。
每个部门的最高工资 select post,max(salary) from emp group by post; 每个部门的最底工资 select post,min(salary) from emp group by post; 每个部门的平均工资 select post,avg(salary) from emp group by post; 每个部门的工资总合 select post,sum(salary) from emp group by post; 每个部门的总人数 select post,count(id) from emp group by post;
# #そして、このサブ使用法のようにすることもできます:
 次のコードを使用して自分で試すことができます:
次のコードを使用して自分で試すことができます:
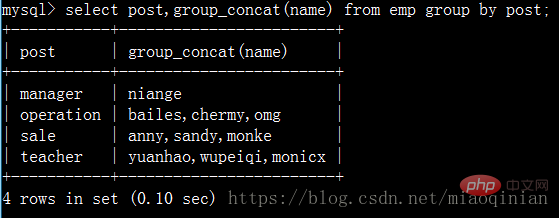
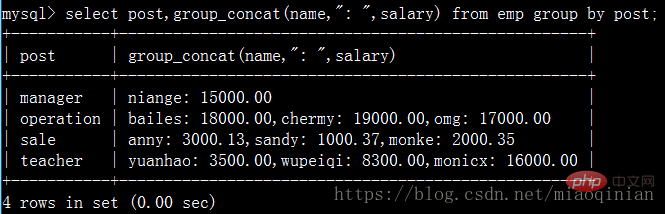
select post,group_concat(name) from emp group by post; select post,group_concat(name,"_NB") from emp group by post; select post,group_concat(name,": ",salary) from emp group by post; select post,group_concat(salary) from emp group by post;
賢明なクラスメートはこう言うでしょうグループ化せずに使用することもできます。いいえ!ただし、mysql は別の操作方法を提供します。コンキャットです。
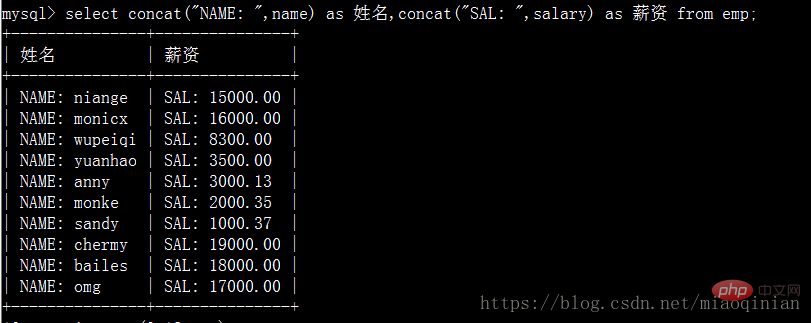
# 补充as语法
mysql> select emp.id,emp.name from emp as t1; # 报错
mysql> select t1.id,t1.name from emp as t1; 1. 查询岗位名以及岗位包含的所有员工名字
select post,group_concat(name) from emp group by post;
2. 查询岗位名以及各岗位内包含的员工个数
select post,count(id) from emp group by post;
3. 查询公司内男员工和女员工的个数
select sex,count(id) from emp group by sex;
4. 查询岗位名以及各岗位的平均薪资
select post,avg(salary) from emp group by post;
5. 查询岗位名以及各岗位的最高薪资
select post,max(salary) from emp group by post;
6. 查询岗位名以及各岗位的最低薪资
select post,min(salary) from emp group by post;
7. 查询男员工与男员工的平均薪资,女员工与女员工的平均薪资
select sex,avg(salary) from emp group by sex;
8、统计各部门年龄在30岁以上的员工平均工资
select post,avg(salary) from emp where age >= 30 group by post;having filter
where不能用聚合函数,但having是可以用聚合函数,这也是它们最大的区别。
统计各部门年龄在24岁以上的员工平均工资,并且保留平均工资大于4000的部门。
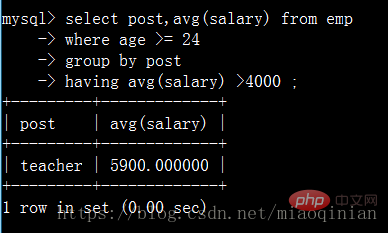
注意:having只能与 select 语句一起使用。
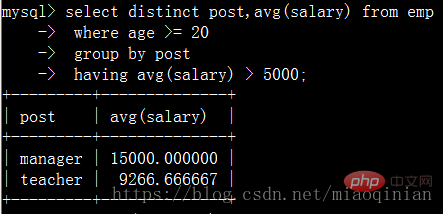
having通常在 group by 子句中使用。
如果不使用 group by子句,不会报错,但会出现以下的情况。

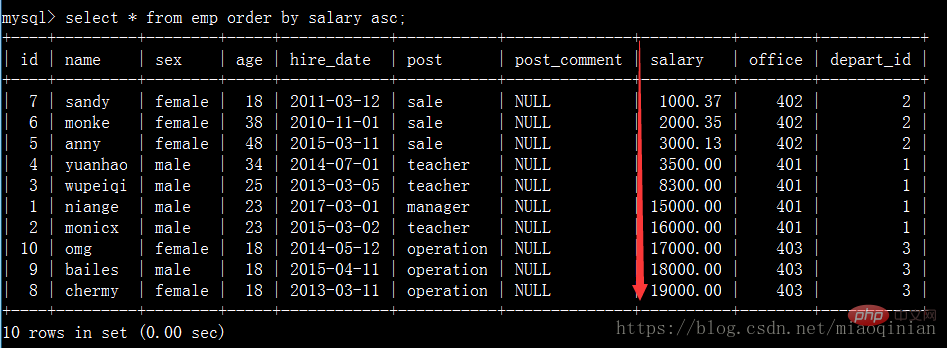
select * from emp order by salary asc; #默认升序排 select * from emp order by salary desc; #降序排 select * from emp order by age desc; #降序排 select * from emp order by age desc,salary asc; #先按照age降序排,再按照薪资升序排
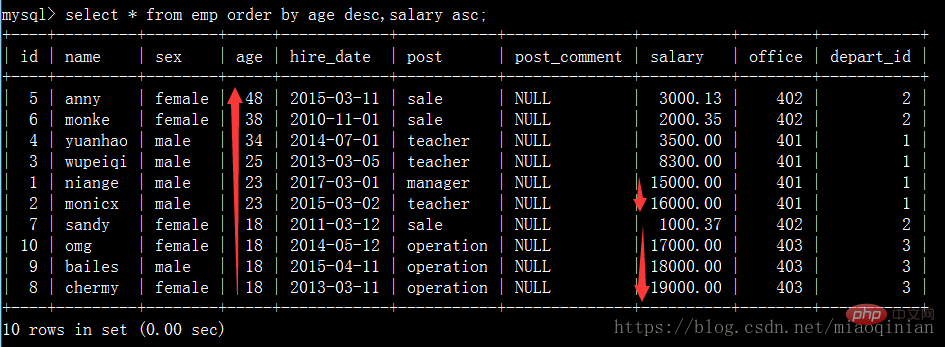

如查要获取工资最高的员工的信息,我们可以用order by和limit也可以做到。

如果查一个表数据量大的话可以用limit分页显示。
select * from emp limit 0,5;
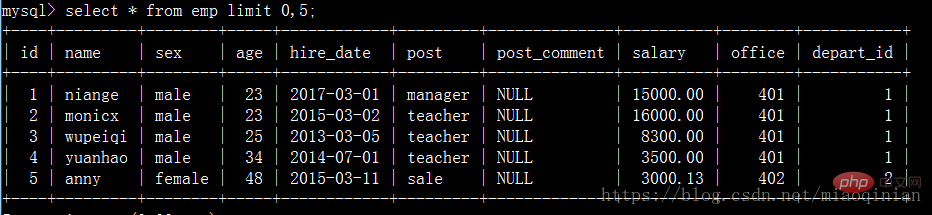
select * from emp limit 5,5;
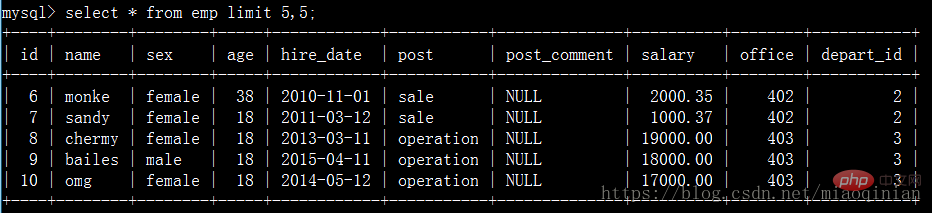
ps:看到这里如果上面的东西你都明白的话,单表查询你基本上已经熟悉它了。
以上が単一テーブルクエリとは何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



