


この記事では、秋採用の Java 面接でよくある質問の分析を紹介します。困っている友人は参考にしていただければ幸いです。
序文
ハゲ頭だけが強くなれる
Redisはまだ見守っています、今日は秋の採用活動を共有します私が見た(遭遇した)面接の質問(比較的一般的なもの)
0. 最後のキーワード
最後のキーワードについて簡単に説明します。 「final」という単語は修飾に使用できますか?
実際の面接でこの質問に遭遇しましたが、その時はうまく答えられませんでした。
#Final はクラス、メソッド、メンバー変数を変更できます#final がメンバー変数を変更する場合、次の 2 つの状況が発生します。
変更が参照型の場合、変数の参照は変更できませんが、参照によって表されるオブジェクトの内容は変数です。
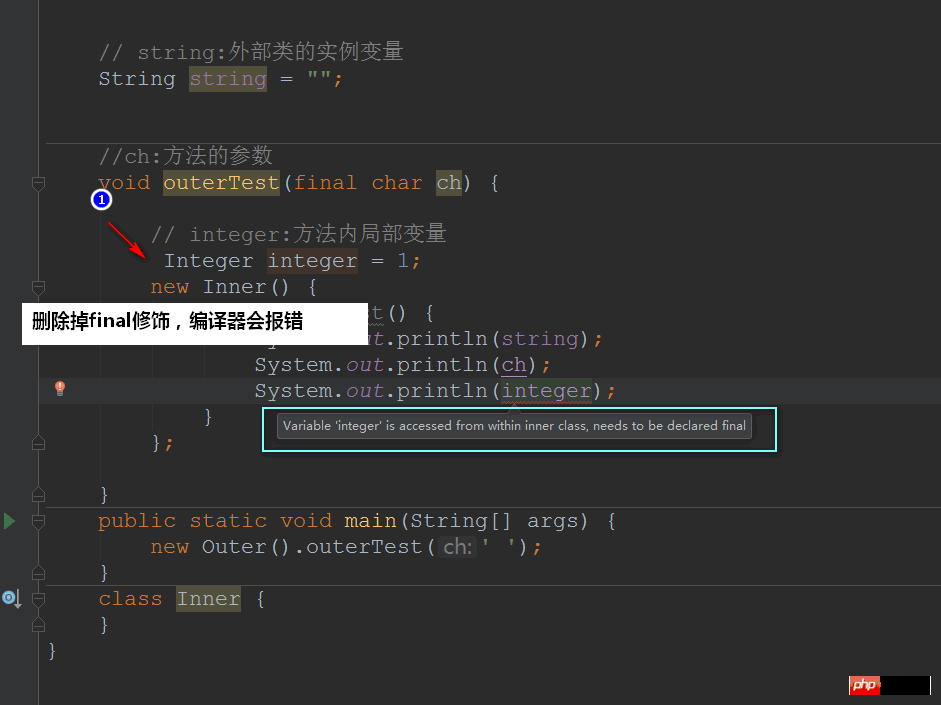
コンパイラでコードを記述するようなプログラミング経験はありますか?これを行うときは、特定のシナリオで変数を Final として宣言する必要があります。そうしないと、コンパイルが失敗します。なぜこのように設計されているのでしょうか? この状況は、匿名内部クラスが使用する変数を作成するときに発生することがあります:
外部クラス インスタンス変数
メソッドまたはスコープ内のローカル変数
メソッドのパラメータ
class Outer {
// string:外部类的实例变量
String string = "";
//ch:方法的参数
void outerTest(final char ch) {
// integer:方法内局部变量
final Integer integer = 1;
new Inner() {
void innerTest() {
System.out.println(string);
System.out.println(ch);
System.out.println(integer);
}
};
}
public static void main(String[] args) {
new Outer().outerTest(' ');
}
class Inner {
}
}次のことがわかります: メソッド内のローカル変数とメソッド パラメータまたは、スコープは、最後のキーワード
(jdk1.7 の下) を使用して#jdk1.8 コンパイル環境に切り替えるとコンパイルできます~
内部データと外部データの一貫性を維持するため、
Java はキャプチャの形式でのみクロージャを実装します。 -by-value (匿名) この関数は関数内で自由変数
を再コピーします。その後、関数の外と関数内に内部データと外部データの一貫性を実現するには、2 つの変数を変更しないでください
。 JDK8 より前では、final 変更を使用する必要がありましたが、JDK8 はよりスマートで、内部クラスは参照データを変更し、外部クラスは
同じデータを再度取得しますその後、匿名内部クラスの外部基本型変数の値を変更したり、外部参照変数のポインティングを変更しようとすると、表面上 すべてが成功したように見えますが、
は実際には外部変数参考資料:
1 char と varchar の違い
char は固定長、varchar は可変長です。 varchar:
元のストレージの場所がストレージのニーズを満たせない場合は、ストレージ エンジンに応じて追加の操作が必要になります。。 char的存储方式是:英文字符占1个字节,汉字占用2个字节;varchar的存储方式是:英文和汉字都占用2个字节,两者的存储数据都非unicode的字符数据。 char是固定长度,长度不够的情况下,用空格代替。varchar表示的是实际长度的数据类型 选用考量: 如果字段长度较短和字符间长度相近甚至是相同的长度,会采用char字符类型 二、多个线程顺序打印问题 原博主给出了4种方式,我认为信号量这种方式比较简单和容易理解,我这里粘贴一下(具体的可到原博主下学习).. 作者:cheergoivan 链接:https://www.jianshu.com/p/40078ed436b4 來源:简书 2018年9月14日18:15:36 yy笔试题就出了.. 三、生产者和消费者 在不少的面经都能看到它的身影哈~~~基本都是要求能够手写代码的。 其实逻辑并不难,概括起来就两句话: 如果生产者的队列满了(while循环判断是否满),则等待。如果生产者的队列没满,则生产数据并唤醒消费者进行消费。 如果消费者的队列空了(while循环判断是否空),则等待。如果消费者的队列没空,则消费数据并唤醒生产者进行生产。 基于原作者的代码,我修改了部分并给上我认为合适的注释(下面附上了原作者出处,感兴趣的同学可到原文学习) 生产者: 消费者: Main方法测试: 作者:我没有三颗心脏 链接:https://www.jianshu.com/p/3f0cd7af370d 來源:简书 另外,上面原文中也说了可以使用阻塞队列来实现消费者和生产者。这就不用我们手动去写 使用阻塞队列解决生产者-消费者问题:https://www.cnblogs.com/chenpi/p/5553325.html 四、算法[1] 解决方案: 使用一个min变量来记住最小值,每次push的时候,看看是否需要更新min。 如果被pop出去的是min,第二次pop的时候,只能遍历一下栈内元素,重新找到最小值。 总结:pop的时间复杂度是O(n),push是O(1),空间是O(1) 使用辅助栈来存储最小值。如果当前要push的值比辅助栈的min值要小,那在辅助栈push的值是最小值 总结:push和pop的时间复杂度都是O(1),空间是O(n)。典型以空间换时间的例子。 继续优化: 栈为空的时候,返回-1很可能会带来歧义(万一人家push进去的值就有-1呢?),这边我们可以使用Java Exception来进行优化 算法的空间优化:上面的代码我们可以发现:data栈和mins栈的元素个数总是相等的,mins栈中存储几乎都是最小的值(此部分是重复的!) 所以我们可以这样做:当push的时候,如果比min栈的值要小的,才放进mins栈。同理,当pop的时候,如果pop的值是mins的最小值,mins才出栈,否则mins不出栈! 上述做法可以一定避免mins辅助栈有相同的元素! 但是,如果一直push的值是最小值,那我们的mins辅助栈还是会有大量的重复元素,此时我们可以使用索引(mins辅助栈存储的是最小值索引,非具体的值)! 最终代码: 参考资料: 【インタビューサイト】最小値を取得できるスタックを実装するには? 著者: channingbreeze 出典: Internet Reconnaissance 5 マルチスレッドでの HashMap ご存知のとおり、HashMap はスレッドセーフなクラスではありません。しかし、面接中に「HashMap をマルチスレッド環境で使用するとどうなるのですか?」と質問されるかもしれません。 ? 結論: 操作により循環リンクリストが生成されます 1. SpringBoot は独立した Spring アプリケーションを作成できます )。 他のタスクをすぐに使用できるようにするための一連の依存関係パッケージを提供します。これには、プロジェクトの構築を高度にカプセル化する組み込みの「スターター POM」が含まれています。 ##、プロジェクト構築の構成を最大限に簡素化します。 7。 メモリを整理しますプロセスのガベージ コレクターは、大量のメモリ フラグメントを生成しません。 G1 Stop The World (STW) は、より制御しやすくなっています。G1 は、予測メカニズム G1 ガベージ コレクターの概要: https://javadoop.com/post/g1 適用範囲:データ ディクショナリの実装、データの重みの決定、またはセットの交差部分の検索に使用できます # 適用範囲: 検索エンジン、キーワード クエリ 適用範囲: 大量のデータ、多くの繰り返しが行われるが、小規模なデータ型はメモリに格納可能 分散処理mapreduce アプリケーションの範囲: 大量のデータですが、小さなデータ型をメモリに入れることができます 詳細については、原文を参照してください: 大規模なデータ処理に関するインタビューの質問 10 件と方法 10 件のまとめ: https://blog.csdn.net/v_JULY_v/article/details/6279498 9. べき等性 9.1HTTP べき等性 昨日、私は一連の筆記試験問題、つまり従来の HTTP の の区別は役に立たない可能性があります。 (ただし、記事全体を読んだ後、 メソッドには、(エラーや有効期限の問題を除けば) N > 0 個の同一のリクエストの副作用が 1 つのリクエストの場合と同じであるという「冪等性」の特性もあります。 。 、つまり、リクエストは副作用がないとみなされます。 メソッド冪等性: は冪等で副作用はありません 、 PUT/DELETE 複数のリクエストにより、現時点では ですが、HTTP プロトコルの実際の使用方法は次のとおりです。インターネットには 2 つの異なる方法があります。1 つは 情報を確認すると、多くのブログで interfaces の冪等性について言及されていることがわかります。上記から、 ここまで述べてきましたが、冪等インターフェイスを設計する利点は何でしょうか? ? ? ? 非冪等性のデメリットの例を挙げてください: 3y 私は 1 年生のとき、体育の授業を受講しなければなりませんでしたが、学校の授業受講システムはひどいものでした(非常に高い遅延)。クラスを取得したかったので、10 個以上の Chrome タブを開いて取得しました (1 つの Chrome タブがクラッシュしても、別の Chrome タブはまだ利用可能でした)。卓球のボールかバドミントンのボールをつかみたいです。 クラスを受講する時間が来たら、受講したい卓球またはバドミントンを順番にクリックします。システムが適切に設計されておらず、リクエストが非冪等であり (またはトランザクションが適切に制御されておらず)、私の手の速度が十分に速く、ネットワークが十分に優れている場合は、卓球やバドミントンのレッスンをたくさん受けたかもしれません。 (これは不合理です。1 人が選択できるコースは 1 つだけですが、私は複数または繰り返しのコースを取得しました) モールに関係するアプリケーション シナリオは次のとおりです。ユーザーが複数の重複注文を行った 副作用を持つことを意味するためです。 (データベース内の複数の重複データ)。 インターネット上の一部のブロガーも、繰り返しの送信を解決するためのいくつかの一般的な解決策を共有しました。 ---->冪等インターフェイスを実装する手段 #API インターフェイスの非冪等の問題と Redis を使用した単純な分散ロックの実装 https://blog.csdn.net/rariki/article/details/50783819 最後に 以上が秋採用の Java 面接でよくある質問のいくつかの分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。三个线程分别打印A,B,C,要求这三个线程一起运行,打印n次,输出形如“ABCABCABC....”的字符串。
public class PrintABCUsingSemaphore {
private int times;
private Semaphore semaphoreA = new Semaphore(1);
private Semaphore semaphoreB = new Semaphore(0);
private Semaphore semaphoreC = new Semaphore(0);
public PrintABCUsingSemaphore(int times) {
this.times = times;
}
public static void main(String[] args) {
PrintABCUsingSemaphore printABC = new PrintABCUsingSemaphore(10);
// 非静态方法引用 x::toString 和() -> x.toString() 是等价的!
new Thread(printABC::printA).start();
new Thread(printABC::printB).start();
new Thread(printABC::printC).start();
/*new Thread(() -> printABC.printA()).start();
new Thread(() -> printABC.printB()).start();
new Thread(() -> printABC.printC()).start();
*/
}
public void printA() {
try {
print("A", semaphoreA, semaphoreB);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void printB() {
try {
print("B", semaphoreB, semaphoreC);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void printC() {
try {
print("C", semaphoreC, semaphoreA);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
private void print(String name, Semaphore current, Semaphore next)
throws InterruptedException {
for (int i = 0; i < times; i++) {
current.acquire();
System.out.print(name);
next.release();
}
}
}ログイン後にコピーimport java.util.Random;
import java.util.Vector;
import java.util.concurrent.atomic.AtomicInteger;
public class Producer implements Runnable {
// true--->生产者一直执行,false--->停掉生产者
private volatile boolean isRunning = true;
// 公共资源
private final Vector sharedQueue;
// 公共资源的最大数量
private final int SIZE;
// 生产数据
private static AtomicInteger count = new AtomicInteger();
public Producer(Vector sharedQueue, int SIZE) {
this.sharedQueue = sharedQueue;
this.SIZE = SIZE;
}
@Override
public void run() {
int data;
Random r = new Random();
System.out.println("start producer id = " + Thread.currentThread().getId());
try {
while (isRunning) {
// 模拟延迟
Thread.sleep(r.nextInt(1000));
// 当队列满时阻塞等待
while (sharedQueue.size() == SIZE) {
synchronized (sharedQueue) {
System.out.println("Queue is full, producer " + Thread.currentThread().getId()
+ " is waiting, size:" + sharedQueue.size());
sharedQueue.wait();
}
}
// 队列不满时持续创造新元素
synchronized (sharedQueue) {
// 生产数据
data = count.incrementAndGet();
sharedQueue.add(data);
System.out.println("producer create data:" + data + ", size:" + sharedQueue.size());
sharedQueue.notifyAll();
}
}
} catch (InterruptedException e) {
e.printStackTrace();
Thread.currentThread().interrupted();
}
}
public void stop() {
isRunning = false;
}
}ログイン後にコピーimport java.util.Random;
import java.util.Vector;
public class Consumer implements Runnable {
// 公共资源
private final Vector sharedQueue;
public Consumer(Vector sharedQueue) {
this.sharedQueue = sharedQueue;
}
@Override
public void run() {
Random r = new Random();
System.out.println("start consumer id = " + Thread.currentThread().getId());
try {
while (true) {
// 模拟延迟
Thread.sleep(r.nextInt(1000));
// 当队列空时阻塞等待
while (sharedQueue.isEmpty()) {
synchronized (sharedQueue) {
System.out.println("Queue is empty, consumer " + Thread.currentThread().getId()
+ " is waiting, size:" + sharedQueue.size());
sharedQueue.wait();
}
}
// 队列不空时持续消费元素
synchronized (sharedQueue) {
System.out.println("consumer consume data:" + sharedQueue.remove(0) + ", size:" + sharedQueue.size());
sharedQueue.notifyAll();
}
}
} catch (InterruptedException e) {
e.printStackTrace();
Thread.currentThread().interrupt();
}
}
}ログイン後にコピーimport java.util.Vector;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Test2 {
public static void main(String[] args) throws InterruptedException {
// 1.构建内存缓冲区
Vector sharedQueue = new Vector();
int size = 4;
// 2.建立线程池和线程
ExecutorService service = Executors.newCachedThreadPool();
Producer prodThread1 = new Producer(sharedQueue, size);
Producer prodThread2 = new Producer(sharedQueue, size);
Producer prodThread3 = new Producer(sharedQueue, size);
Consumer consThread1 = new Consumer(sharedQueue);
Consumer consThread2 = new Consumer(sharedQueue);
Consumer consThread3 = new Consumer(sharedQueue);
service.execute(prodThread1);
service.execute(prodThread2);
service.execute(prodThread3);
service.execute(consThread1);
service.execute(consThread2);
service.execute(consThread3);
// 3.睡一会儿然后尝试停止生产者(结束循环)
Thread.sleep(10 * 1000);
prodThread1.stop();
prodThread2.stop();
prodThread3.stop();
// 4.再睡一会儿关闭线程池
Thread.sleep(3000);
// 5.shutdown()等待任务执行完才中断线程(因为消费者一直在运行的,所以会发现程序无法结束)
service.shutdown();
}
}ログイン後にコピーwait/notify的代码了,会简单一丢丢。可以参考:我现在需要实现一个栈,这个栈除了可以进行普通的push、pop操作以外,还可以进行getMin的操作,getMin方法被调用后,会返回当前栈的最小值,你会怎么做呢?你可以假设栈里面存的都是int整数
import java.util.ArrayList;
import java.util.List;
public class MinStack {
private List<Integer> data = new ArrayList<Integer>();
private List<Integer> mins = new ArrayList<Integer>();
public void push(int num) {
data.add(num);
if (mins.size() == 0) {
// 初始化mins
mins.add(num);
} else {
// 辅助栈mins每次push当时最小值
int min = getMin();
if (num >= min) {
mins.add(min);
} else {
mins.add(num);
}
}
}
public int pop() {
// 栈空,异常,返回-1
if (data.size() == 0) {
return -1;
}
// pop时两栈同步pop
mins.remove(mins.size() - 1);
return data.remove(data.size() - 1);
}
public int getMin() {
// 栈空,异常,返回-1
if (mins.size() == 0) {
return -1;
}
// 返回mins栈顶元素
return mins.get(mins.size() - 1);
}
}ログイン後にコピーimport java.util.ArrayList;
import java.util.List;
public class MinStack {
private List<Integer> data = new ArrayList<Integer>();
private List<Integer> mins = new ArrayList<Integer>();
public void push(int num) throws Exception {
data.add(num);
if(mins.size() == 0) {
// 初始化mins
mins.add(0);
} else {
// 辅助栈mins push最小值的索引
int min = getMin();
if (num < min) {
mins.add(data.size() - 1);
}
}
}
public int pop() throws Exception {
// 栈空,抛出异常
if(data.size() == 0) {
throw new Exception("栈为空");
}
// pop时先获取索引
int popIndex = data.size() - 1;
// 获取mins栈顶元素,它是最小值索引
int minIndex = mins.get(mins.size() - 1);
// 如果pop出去的索引就是最小值索引,mins才出栈
if(popIndex == minIndex) {
mins.remove(mins.size() - 1);
}
return data.remove(data.size() - 1);
}
public int getMin() throws Exception {
// 栈空,抛出异常
if(data.size() == 0) {
throw new Exception("栈为空");
}
// 获取mins栈顶元素,它是最小值索引
int minIndex = mins.get(mins.size() - 1);
return data.get(minIndex);
}
}ログイン後にコピー
jdk1.8 は循環チェーンの問題を解決しました (2 つのペアの宣言)ポインタの数と 2 つのリンク リストの維持)
フェイルファスト メカニズム。現在の HashMap を同時に削除/変更すると、ConcurrentModificationException 例外がスローされます HashMap スレッドのセキュリティ不安の現れについて話す: http://www.importnew.com/22011.html
## 6. Spring と Springboot の違い2. Spring の構成を簡素化します。 ##Spring その煩雑な設定により、かつては「設定地獄」と呼ばれていました。さまざまな XML や Annotation の設定は目まぐるしく、何か問題が発生した場合に原因を見つけるのが困難です。
Spring Boot プロジェクトは、面倒な構成の問題を解決し、構成よりも規約の実装を最大限に高めることです (
##G1 は
##G1 コレクターの設計目標は、CMS コレクターを置き換えることです。CMS と比較して、次の点でパフォーマンスが向上します。 CMS はマークアンドスイープ ガベージ コレクション アルゴリズムを使用するため、大量のメモリ フラグメントが生成される可能性があります。
大規模データの処理は、面接と筆記試験の両方で頻繁にテストされる知識ポイントでもあります。比較的一般的です。幸いなことに、私は次の記事を読み、大量のデータを解決するためのいくつかのアイデアを抜粋しました。
#ハッシュ
適用範囲: 素早い検索と削除のための基本的なデータ構造。通常、必要なデータの総量はメモリに格納できます。
bit-map適用範囲: データの検索、決定、削除を高速に行うことができます。一般的に、データ範囲は int
ヒープ 適用範囲: 最初の n は大量のデータに対して大きく、n は比較的小さく、ヒープをメモリに配置できます
#適用範囲: k 番目に大きい、中央値、非繰り返しまたは繰り返しの数値データベース インデックス
get/post の違いを受けました。今日再度検索してみたところ、以前の理解とは少し異なっていることがわかりました。 人が最初から Web 開発を行う場合、
を過度に一般化するという間違いを犯しました。HTTP プロトコル仕様から単純に言えば、前に要約した
GET/POST個人的に思う: インタビューで GET/POST の違いがある場合は、デフォルトで Web 開発シナリオで回答する方が良いです。これは面接官が望んでいることかもしれません 回答)参考:GET と POST の違いは何ですか?そして、なぜインターネット上のほとんどの答えが間違っているのか。 http://www.cnblogs.com/nankezhishi/archive/2012/06/09/getandpost.html
定義によれば、HTTP メソッドの冪等性は
であり、リソースに対する 1 つまたは複数のリクエストが同じ副作用を持つ必要があることを意味します「副作用」の意味について簡単に説明します。これは、リクエストを送信した後、
GET/POST/DELETE/PUT
リソース指向のアプリケーション層プロトコル たとえば、注文 ID 2 の注文を取得したいとします:
DELETE/PUTGET を使用して を複数回取得します。ID 2 のオーダー (リソース) は であり、変更されません# ##! http://localhost/order/2
#POST を使用して を複数回リクエストします。この ID は 2 です。順序 (リソース) は に 1 回だけ変更されます (副作用があります)。ただし、リクエストを複数回更新し続けると、注文 ID 2 の最終ステータスは同じになりますhttp://localhost/order
HTTP プロトコル自体は 3y という名前の複数のオーダーが作成される可能性があります 、このオーダー (リソース) は複数回変更されます、 リソースのステータスはリクエストされるたびに変更されます ! です。これは、HTTP をアプリケーション層プロトコルとして扱い、HTTP プロトコルのさまざまな規制をより忠実に遵守します ( は HTTP メソッド # を最大限に活用します) ##); もう 1 つの は SOA です。これは、HTTP をアプリケーション層プロトコルとして完全にはみなしませんが、HTTP プロトコルをトランスポート層プロトコルとして使用し、HTTP 層プロトコルの上に独自のアプリケーションを構築します参考資料:
HTTP 冪等性について http://www.cnblogs.com/weidagang2046/archive/2011/06/04/2063696.html#!comments
POST メソッドが非冪等であることもわかります。ただし、何らかの手段を使用して、POST メソッドのインターフェイスを冪等にすることができます。
#クラス取得インターフェイスが冪等であれば、この問題は発生しません。冪等性とは、リソースに対する複数のリクエストが同じ データベース バックグラウンドには最大でも 1 つのレコードしか存在しないため、複数のコースを取得することはできません。
繰り返しの送信を防ぐためです同期ロック (シングル スレッド、クラスター内で失敗する可能性があります)
分散システム インターフェイスの冪等性 http://blog.brucefeng.info/post/api-idempotent

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



