


この記事では主にクローラーを学ぶためのNodeJSの使い方と、クロールすることによる効果について説明しています。 NodeJSのソースコード解析がありますので、興味のある方はぜひやってみましょう。一緒に学びましょう。
1. 序文分析私たちは通常、クローラーを実装するために Python/.NET 言語を使用しますが、フロントエンド開発者として、当然 NodeJS に習熟する必要があります。 NodeJS 言語を使用して、恥ずかしいもの百科のクローラーを実装してみましょう。また、この記事で使用されているコードの一部は es6 構文です。
このクローラの実装に必要な依存ライブラリは以下の通りです。
リクエスト: get メソッドまたは post メソッドを使用して、Web ページのソース コードを取得します。 Cheerio: Web ページのソース コードを解析し、必要なデータを取得します。
この記事では、まずクローラーに必要な依存関係ライブラリとその使用法を紹介し、次にこれらの依存関係ライブラリを使用して、恥ずかしいこと百科事典用の Web クローラーを実装します。
2. request ライブラリ request は、非常に強力で使いやすい軽量の http ライブラリです。これを使用して HTTP リクエストを実装でき、HTTP 認証、カスタム リクエスト ヘッダーなどをサポートします。以下に、リクエスト ライブラリの関数の一部を紹介します。
次のように request モジュールをインストールします。
npm install request
request をインストールしたら、request を使用して Baidu Web ページをリクエストできるようになります。
const req = require('request');
req('http://www.baidu.com', (error, response, body) => {
if (!error && response.statusCode == 200) {
console.log(body)
}
})
options パラメーターが設定されていない場合、リクエスト メソッドはデフォルトで get リクエストになります。私が request オブジェクトを使用する具体的な方法は次のとおりです。
req.get({
url: 'http://www.baidu.com'
},(err, res, body) => {
if (!err && res.statusCode == 200) {
console.log(body)
}
});
ただし、多くの場合、 URL。一般に、リクエスト ヘッダーと Web ページのエンコードを考慮する必要があります。
Web ページのリクエスト ヘッダーと Web ページのエンコーディング
以下では、Web ページのリクエスト ヘッダーを追加し、リクエスト時に正しいエンコーディングを設定する方法について説明します。
req.get({
url : url,
headers: {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36",
"Host" : "www.zhihu.com",
"Upgrade-Insecure-Requests" : "1"
},
encoding : 'utf-8'
}, (err, res, body)=>{
if(!err)
console.log(body);
})
options パラメータを設定し、headers 属性を追加してリクエスト ヘッダーを設定し、 encoding 属性を追加してエンコーディングを設定します。ウェブページ 。 encoding: null の場合、get リクエストによって取得されるコンテンツは Buffer オブジェクト、つまりボディが Buffer オブジェクトであることに注意してください。
上記で紹介した機能は以下のニーズを満たすのに十分ですheaders 属性即可实现请求头的设置;添加 encoding 属性即可设置网页的编码。需要注意的是,若 encoding:null ,那么 get 请求所获取的内容则是一个 Buffer 对象,即 body 是一个 Buffer 对象。
上面介绍的功能足矣满足后面的所需了
3. cheerio 库
cheerio 是一款服务器端的 Jquery,以轻、快、简单易学等特点被开发者喜爱。有 Jquery 的基础后再来学习 cheerio 库非常轻松。它能够快速定位到网页中的元素,其规则和 Jquery 定位元素的方法是一样的;它也能以一种非常方便的形式修改 html 中的元素内容,以及获取它们的数据。下面主要针对 cheerio 快速定位网页中的元素,以及获取它们的内容进行介绍。
首先安装 cheerio 库
npm install cheerio
下面先给出一段代码,再对代码进行解释 cheerio 库的用法。对博客园首页进行分析,然后提取每一页中文章的标题。
首先对博客园首页进行分析。如下图:
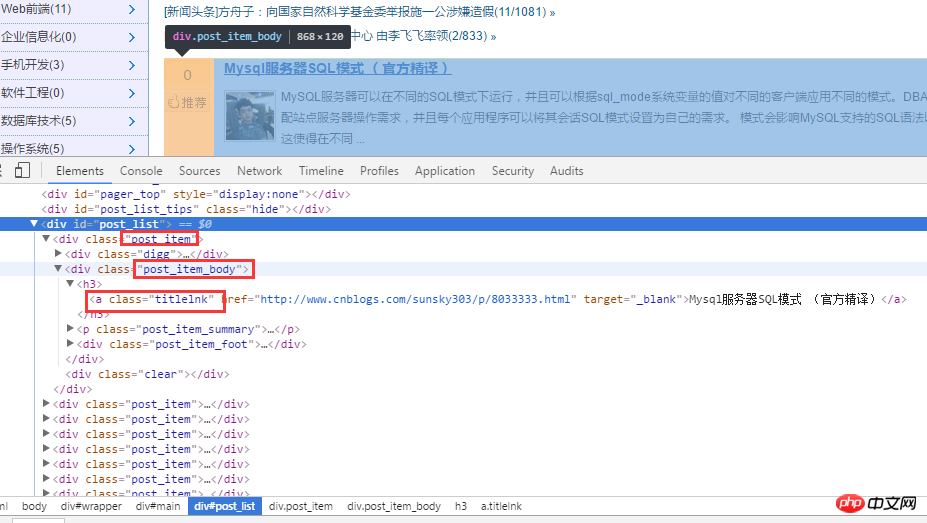
对 html 源代码进行分析后,首先通过 .post_item 获取所有标题,接着对每一个 .post_item 进行分析,使用 a.titlelnk
3. Cheerio ライブラリ
まずcheerioライブラリをインストールします
const req = require('request');
const cheerio = require('cheerio');
req.get({
url: 'https://www.cnblogs.com/'
}, (err, res, body) => {
if (!err && res.statusCode == 200) {
let cnblogHtmlStr = body;
let $ = cheerio.load(cnblogHtmlStr);
$('.post_item').each((index, ele) => {
let title = $(ele).find('a.titlelnk');
let titleText = title.text();
let titletUrl = title.attr('href');
console.log(titleText, titletUrl);
});
}
});
以下は、最初にコードを示し、その後cheerioライブラリの使い方を説明します。ブログパークのトップページを解析し、各ページの記事タイトルを抽出します。
まず、ブログパークのホームページを分析します。以下に示すように:
HTML ソース コードを分析した後、まず .post_item を通じてすべてのタイトルを取得し、次に各 .post_item を分析して a.titlelnk</ code> は各タイトルの a タグと一致します。以下はコードを通じて実装されます。 </p>🎜🎜🎜<div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:php;toolbar:false">let cnblogHtmlStr = body;
let $ = cheerio.load(cnblogHtmlStr);
let titles = $(&#39;.post_item&#39;).find(&#39;a.titlelnk&#39;);
titles.each((index, ele) => {
let titleText = $(ele).text();
let titletUrl = $(ele).attr(&#39;href&#39;);
console.log(titleText, titletUrl);</pre><div class="contentsignin">ログイン後にコピー</div></div>🎜🎜🎜🎜🎜🎜🎜 もちろん、cheerio ライブラリはチェーン呼び出しもサポートしています: 🎜🎜🎜🎜<div class="code" style="position:relative; padding:0px; margin:0px;"><div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:php;toolbar:false">//爬虫
const req = require(&#39;request&#39;);
function getHtml(url){
return new Promise((resolve, reject) => {
req.get({
url : url,
headers: {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
"Referer" : "https://www.qiushibaike.com/"
},
encoding : &#39;utf-8&#39;
}, (err, res, body)=>{
if(err) reject(err);
else resolve(body);
})
});
}
exports.getHtml = getHtml;</pre><div class="contentsignin">ログイン後にコピー</div></div><div class="contentsignin">ログイン後にコピー</div></div>🎜🎜🎜🎜🎜🎜🎜 上記のコードは非常に優れています。シンプルないいえ、これ以上言葉で説明するつもりはありません。以下に、より重要だと思われる点をいくつかまとめます。 🎜<p>使用 <code>find() 方法获取的节点集合 A,若再次以 A 集合中的元素为根节点定位它的子节点以及获取子元素的内容与属性,需对 A 集合中的子元素进行 $(A[i]) 包装,如上面的$(ele) 一样。在上面代码中使用 $(ele) ,其实还可以使用 $(this) 但是由于我使用的是 es6 的箭头函数,因此改变了 each 方法中回调函数的 this 指针,因此,我使用 $(ele); cheerio 库也支持链式调用,如上面的 $('.post_item').find('a.titlelnk') ,需要注意的是,cheerio 对象 A 调用方法 find(),如果 A 是一个集合,那么 A 集合中的每一个子元素都调用 find() 方法,并放回一个结果结合。如果 A 调用 text() ,那么 A 集合中的每一个子元素都调用 text() 并返回一个字符串,该字符串是所有子元素内容的合并(直接合并,没有分隔符)。
最后在总结一些我比较常用的方法。
first() last() children([selector]): 该方法和 find 类似,只不过该方法只搜索子节点,而 find 搜索整个后代节点。
4. 糗事百科爬虫
通过上面对 request 和 cheerio 类库的介绍,下面利用这两个类库对糗事百科的页面进行爬取。
1、在项目目录中,新建 httpHelper.js 文件,通过 url 获取糗事百科的网页源码,代码如下:
//爬虫
const req = require('request');
function getHtml(url){
return new Promise((resolve, reject) => {
req.get({
url : url,
headers: {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
"Referer" : "https://www.qiushibaike.com/"
},
encoding : 'utf-8'
}, (err, res, body)=>{
if(err) reject(err);
else resolve(body);
})
});
}
exports.getHtml = getHtml;2、在项目目录中,新建一个 Splider.js 文件,分析糗事百科的网页代码,提取自己需要的信息,并且建立一个逻辑通过更改 url 的 id 来爬取不同页面的数据。
const cheerio = require('cheerio');
const httpHelper = require('./httpHelper');
function getQBJok(htmlStr){
let $ = cheerio.load(htmlStr);
let jokList = $('#content-left').children('p');
let rst = [];
jokList.each((i, item)=>{
let node = $(item);
let titleNode = node.find('h2');
let title = titleNode ? titleNode.text().trim() : '匿名用户';
let content = node.find('.content span').text().trim();
let likeNumber = node.find('i[class=number]').text().trim();
rst.push({
title : title,
content : content,
likeNumber : likeNumber
});
});
return rst;
}
async function splider(index = 1){
let url = `https://www.qiushibaike.com/8hr/page/${index}/`;
let htmlStr = await httpHelper.getHtml(url);
let rst = getQBJok(htmlStr);
return rst;
}
splider(1);在获取糗事百科网页信息的时候,首先在浏览器中对源码进行分析,定位到自己所需要标签,然后提取标签的文本或者属性值,这样就完成了网页的解析。
Splider.js 文件入口是 splider 方法,首先根据传入该方法的 index 索引,构造糗事百科的 url,接着获取该 url 的网页源码,最后将获取的源码传入 getQBJok 方法,进行解析,本文只解析每条文本笑话的作者、内容以及喜欢个数。
直接运行 Splider.js 文件,即可爬取第一页的笑话信息。然后可以更改 splider 方法的参数,实现抓取不同页面的信息。
在上面已有代码的基础上,使用 koa 和 vue2.0 搭建一个浏览文本的页面,效果如下:

源码已上传到 github 上。下载地址:https://github.com/StartAction/SpliderQB ;
项目运行依赖 node v7.6.0 以上, 首先从 Github 上面克隆整个项目。
git clone https://github.com/StartAction/SpliderQB.git
克隆之后,进入项目目录,运行下面命令即可。
node app.js
5. 总结
通过实现一个完整的爬虫功能,加深自己对 Node 的理解,且实现的部分语言都是使用 es6 的语法,让自己加快对 es6 语法的学习进度。另外,在这次实现中,遇到了 Node 的异步控制的知识,本文是采用的是 async 和 await 关键字,也是我最喜欢的一种,然而在 Node 中,实现异步控制有好几种方式。关于具体的方式以及原理,有时间再进行总结。
相关推荐:
以上がNodeJS クローラー例の恥ずかしいこと事典_node.jsの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



