


この記事では、検索能力と生成能力を統合することで応答の精度を高める最先端のAI手法である検索総生成(RAG)について説明します。 RAGは、応答を生成する前に、知識ベースから最初に関連する現在の情報を最初に取得することにより、信頼できるコンテキストに関連する回答を提供するAIの能力を高めます。このディスカッションでは、効率的なデータ検索のためのベクトルデータベースの使用、類似性マッチングのための距離メトリックの重要性、およびRAGが幻覚や混乱のような一般的なAIの落とし穴を緩和する方法など、RAGワークフローを詳細にカバーしています。 RAGを設定および実装するための実用的な手順も提供されており、これはAIベースの知識検索を改善することを目的としたすべての人にとって包括的なガイドになります。
*この記事は、***データサイエンスブログソンの一部です。
RAGは、応答を生成する前に関連情報を取得することにより、回答の精度を向上させるAIメソッドです。トレーニングデータのみに依存している従来のAIとは異なり、RAGはデータベースまたは知識ソースを最新または特定の情報を検索します。この情報は、より正確で信頼できる答えの生成に通知します。 RAGアプローチは、検索モデルと生成モデルを組み合わせて、特にNLPタスクで生成されたコンテンツの品質と精度を高めます。
さらなる読み取り:知識集約型NLPタスクの検索された生成
RAGワークフローは、検索と生成の2つの主要な段階で構成されています。段階的なプロセスの概要を以下に示します。
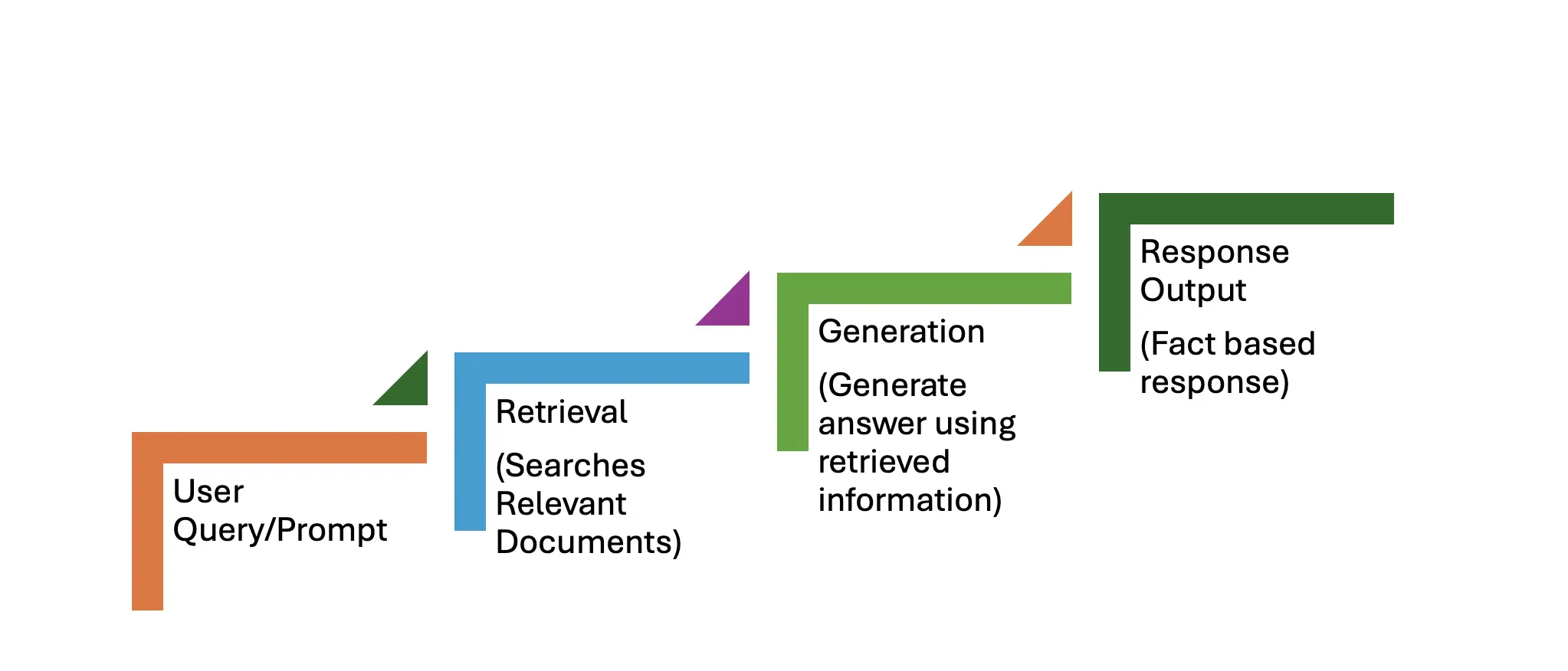
「量子コンピューティングの最新の進歩は何ですか?」などのユーザークエリ。プロンプトとして機能します。
このフェーズには3つのステップが含まれます。
このフェーズには3つのステップも含まれます。
システムは、純粋に生成されたモデルが生成できるものよりも優れている、事実上正確で最新の応答を返します。
RAGとの有無にかかわらずAIを比較すると、RAGの変換力が強調されます。従来のモデルは事前に訓練されたデータのみに依存していますが、RAGはリアルタイムの情報検索で応答を強化し、静的と動的なコンテキスト認識出力の間のギャップを埋めます。
| ぼろきれ | ぼろきれ |
|---|---|
| 外部ソースから現在の情報を取得します。 | 事前に訓練された(潜在的に時代遅れの)知識のみに依存しています。 |
| 特定のソリューションを提供します(たとえば、パッチバージョン、構成の変更)。 | 実用的な詳細がない曖昧で一般化された応答を生成します。 |
| 実際の文書で応答を接地することにより、幻覚のリスクを最小限に抑えます。 | 特に最近の情報に対する幻覚や不正確さのリスクが高くなります。 |
| 最新のベンダーアドバイスまたはセキュリティパッチが含まれています。 | 最近のアドバイザリーや更新を知らない場合があります。 |
| 内部(組織固有)と外部(パブリックデータベース)情報を組み合わせます。 | 新しいまたは組織固有の情報を取得できません。 |
ベクトルデータベースは、セマンティックの類似性に基づいて、RAGでの効率的かつ正確なドキュメントまたはデータ検索に重要です。正確な用語マッチングに依存するキーワードベースの検索とは異なり、ベクトルデータベースはテキストを高次元空間のベクトルとして表し、同様の意味を一緒にクラスタリングします。これにより、RAGシステムに非常に適しています。ベクトルデータベースはベクトル化されたドキュメントを保存し、AIモデルのより正確な情報検索を可能にします。
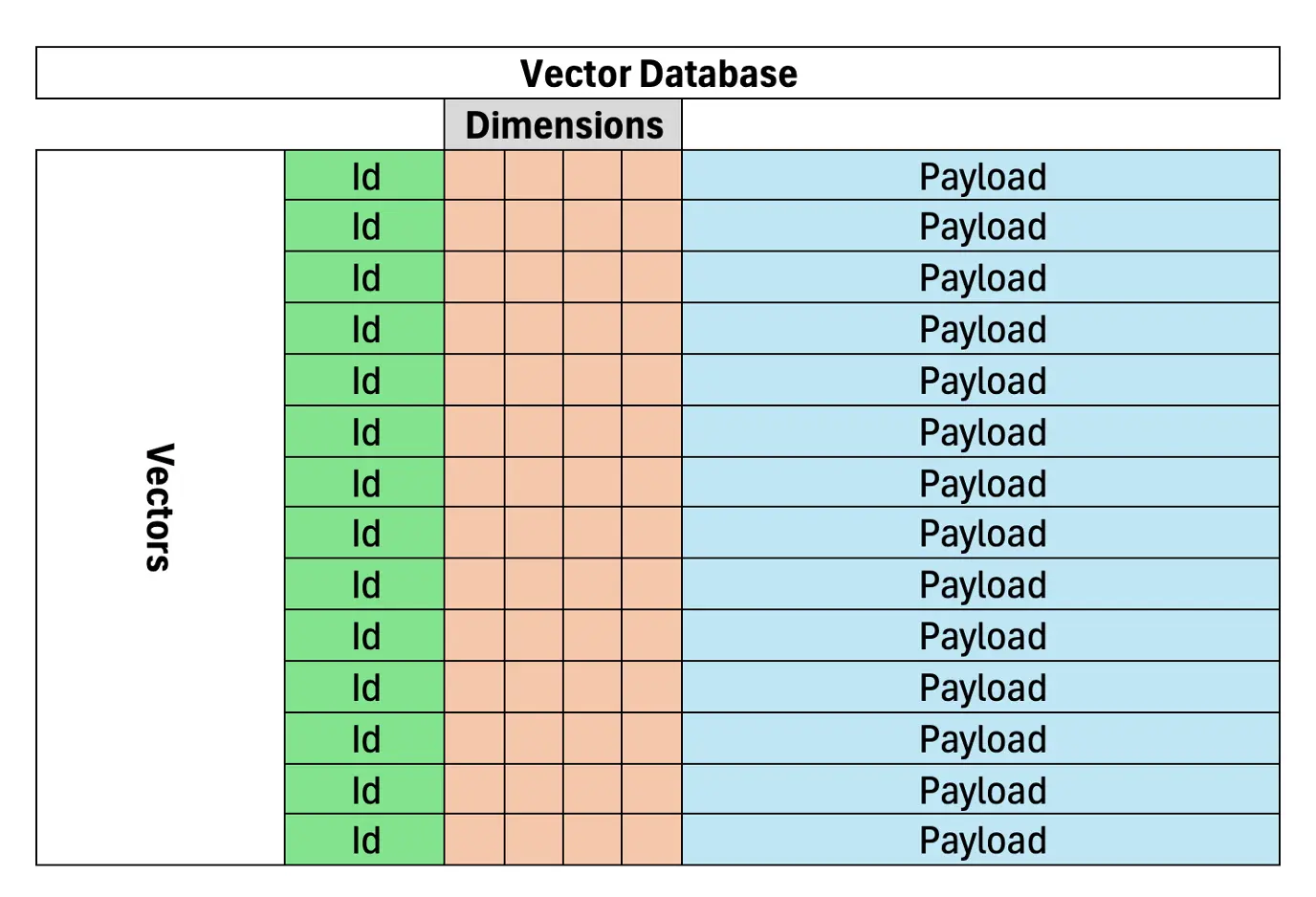
(残りのセクションは、元の情報と画像の配置を維持し、再構築と再構築の同様のパターンに従います。)
以上がAI幻覚の改善の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



