


Apache Luceneの力のロックを解除:包括的なガイド
ElasticSearchやSolrなどのトップ検索アプリケーションの背後にあるエンジンについて疑問に思ったことはありませんか?高性能Java検索ライブラリであるApache Luceneが答えです。このガイドは、検索工学を新しい人にとっても、ルーセンの基本的な理解を提供します。
学習目標:
(この記事はデータサイエンスブログソンの一部です。)
目次:
Apache Luceneとは何ですか?
ルーセンの力は、いくつかの重要な概念にあります。製品カタログの例を使用してそれらを調べてみましょう。
{
"Product_id": "1"、
「タイトル」:「ワイヤレスノイズキャンセルヘッドフォン」、
「ブランド」:「ボーズ」、
「カテゴリ」:[「電子機器」、「オーディオ」、「ヘッドフォン」]、
「価格」:300
}
{
「Product_id」: "2"、
「タイトル」:「Bluetoothマウス」、
「ブランド」:「ゼリー・コーム」、
「カテゴリ」:[「電子機器」、「コンピューターアクセサリ」、「マウス」]、
「価格」:30
}
{
「Product_id」: "3"、
「タイトル」:「ワイヤレスキーボード」、
「ブランド」:「iClever」、
「カテゴリ」:[「電子機器」、「コンピューターアクセサリ」、「キーボード」]、
「価格」:40
}ドキュメント:ルーセンの基本ユニット。各製品エントリはドキュメントで、ドキュメントIDで一意に識別されます。
フィールド:ドキュメント内の各属性(例: product_id 、 title 、 brand )。
用語:検索単位。 Lucene Preprocessesテキストは、用語を作成します(例:「Wireless」、「Headphones」)。
| ドキュメントID | 条項 |
|---|---|
| 1 | タイトル:ワイヤレス、ノイズ、キャンセル、ヘッドフォン。ブランド: Bose;カテゴリ:電子機器、オーディオ、ヘッドフォン |
| 2 | タイトル: Bluetooth、マウス。ブランド:ゼリー、櫛。カテゴリ:電子機器、コンピューター、アクセサリー |
| 3 | タイトル:ワイヤレス、キーボード。ブランド: ICLEVER;カテゴリ:電子機器、コンピューター、アクセサリー |

セグメント:インデックスは複数のセグメントに分割でき、それぞれが自己完結型インデックスとして機能します。セグメント全体の検索は通常、シーケンシャルです。
スコアリング: Luceneは、TF-IDF(およびBM25などの他の方法などの方法を使用して、ドキュメントの関連性をランク付けします。
用語頻度(TF):ドキュメントに用語が表示される頻度。




Lucene検索アプリケーションコンポーネント
ルーセンは2つの主要な部分で構成されています。
IndexWriter ):インデックスドキュメント、テキスト処理(トークン化など)の実行、および逆インデックスの作成。 
IndexSearcher ):クエリオブジェクトを使用して検索を実行します。 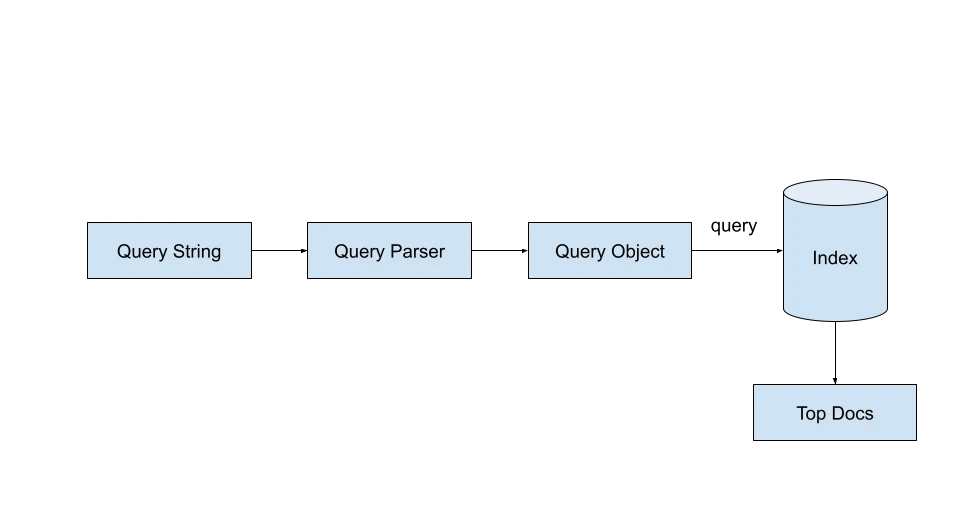
サポートされているルーセンクエリタイプ
ルーセンはさまざまなクエリタイプを提供しています:
用語クエリ:特定の用語を含むドキュメントと一致します。 new TermQuery(new Term("brand", "jelly"))
ブールクエリ:ブールロジックを使用して他のクエリを組み合わせます。
範囲クエリ:指定された範囲内のフィールド値とドキュメントを一致させます。
フレーズクエリ:特定の一連のシーケンスを含むドキュメントと一致します。
関数クエリ:フィールドの値に基づいてドキュメントをスコアします。
シンプルなルーセン検索アプリケーションの構築
次のJavaコードは、単純なLuceneアプリケーションを示しています。
(インデクサーと検索者のコード例は、元の入力と同じままです)
結論
Apache Luceneは、高性能検索アプリケーションを構築するための強力なツールです。このガイドでは、基礎をカバーしており、より高度な検索ソリューションを作成できるようになりました。
重要なテイクアウト:
IndexWriterとIndexSearcherインデックス作成と検索に不可欠です。よくある質問
Q1。 LuceneはPythonをサポートしていますか? A.はい、ピルセンを介して。
Q2。どのオープンソース検索エンジンが利用できますか? A. solr、opensearch、meilisearchなど
Q3。 Luceneはセマンティックとベクトルの検索をサポートしていますか? A.はい、ベクトル寸法に制限があります(現在1024)。
Q4。 Luceneはどのような関連性のスコアリングアルゴリズムを使用していますか? A. TF-IDF、BM25など
Q5。複雑なルーセンクエリの例は何ですか? A.ファジークエリ、スパンクエリなど。
(注:画像は元の形式と位置で保持されます。)
以上がApache Luceneの紹介の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



