


Python を使用したオプション フローの視覚化: ステップバイステップ ガイド

進化し続ける金融の世界では、データを視覚化することで市場の傾向についてこれまでにない洞察を得ることができます。この記事では、Yahoo Finance の履歴データを使用して特定の株式のオプション フローを視覚化するという特定の財務分析タスクに Python を活用する方法を検討します。オプション データを取得して処理し、コールおよびプット オプションのフローを示す散布図を生成するコード スニペットを使用します。詳細を見ていきましょう。
はじめる
私たちの目標は、特定の株式のオプション データを分析し、散布図で視覚化することです。この例では、株式ティッカー LLY (Eli Lilly and Company) を使用します。コード スニペットは次のことを実現します:
- 指定された株式の最新のオプション データを取得します。
- データをフィルタリングしてクリーンアップします。
- コールおよびプットのオプションを経時的に表す散布図を作成します。
段階的な内訳
1. ライブラリのインポート
まず、必要なライブラリをインポートする必要があります。
import yfinance as yf import os from datetime import datetime, timedelta import matplotlib.pyplot as plt import pandas as pd
- yfinance は、過去の株価データを取得するために使用されます。
- os はディレクトリとファイルの操作を処理します。
- datetime と timedelta は日付を管理するためのものです。
- matplotlib.pyplot は視覚化を作成するためのものです。
- pandas はデータ操作と分析用です。
2. ディレクトリとファイルのセットアップ
データを保存する出力ディレクトリとファイルを設定します。
output_directory = 'output' os.makedirs(output_directory, exist_ok=True) output_file = os.path.join(output_directory, 'output.data')
ここでは、出力ディレクトリが存在することを確認し、データ ファイルのパスを指定します。
3. オプション データの取得と処理
ティッカー LLY のオプション データを取得するには、yfinance を使用します。
ticker = 'LLY' days = 21 populate_data = 'Y' # Set 'N' to use existing file, 'Y' to create new file
populate_data が「Y」に設定されている場合、コードは新しいオプション データをフェッチします。 「N」の場合、既存のデータ ファイルが使用されます。
データの取得と処理がどのように行われるかは次のとおりです:
if populate_data == 'Y':
stock = yf.Ticker(ticker)
options_dates = stock.options
today = datetime.now()
fourteen_days_later = today + timedelta(days)
with open(output_file, 'w') as file:
for date in options_dates:
date_dt = datetime.strptime(date, '%Y-%m-%d')
if today <= date_dt <= fourteen_days_later:
calls = stock.option_chain(date).calls
puts = stock.option_chain(date).puts
for _, row in calls.iterrows():
if not filter_volume(row['volume']):
file.write(f"Call,{date},{row['strike']},{row['volume']}\n")
for _, row in puts.iterrows():
if not filter_volume(row['volume']):
file.write(f"Put,{date},{row['strike']},{row['volume']}\n")
print(f"Data has been written to {output_file}")
このコードは、コールおよびプットのオプション データをフェッチし、不要なボリューム データを含む行を除外して、ファイルに書き込みます。
4. 視覚化のためのデータのクリーニングと準備
次に、データを読み取り、クリーンアップします。
data = pd.read_csv(output_file, names=['Type', 'Last_Trade_Date', 'Strike', 'Volume']) data.dropna(inplace=True) data['Last_Trade_Date'] = pd.to_datetime(data['Last_Trade_Date']) data = data[data['Volume'].notna()]
データセットに NaN 値が含まれていないこと、および Last_Trade_Date が正しい日時形式であることを確認します。
5. 散布図の作成
散布図を作成する準備ができました:
extra_days_before = 5
extra_days_after = 5
min_date = data['Last_Trade_Date'].min() - timedelta(days=extra_days_before)
max_date = data['Last_Trade_Date'].max() + timedelta(days=extra_days_after)
plt.figure(figsize=(12, 8))
calls_data = data[data['Type'] == 'Call']
plt.scatter(calls_data['Last_Trade_Date'], calls_data['Strike'],
s=calls_data['Volume'], c='green', alpha=0.6, label='Call')
puts_data = data[data['Type'] == 'Put']
plt.scatter(puts_data['Last_Trade_Date'], puts_data['Strike'],
s=puts_data['Volume'], c='red', alpha=0.6, label='Put')
plt.xlabel('\nLast Trade Date')
plt.ylabel('Strike Price\n')
plt.title(f'Options Flow for {ticker} ({days} days)\n', fontsize=16)
plt.xticks(rotation=45, ha='right')
plt.gca().xaxis.set_major_formatter(plt.matplotlib.dates.DateFormatter('%Y-%m-%d'))
plt.xlim(min_date, max_date)
plt.subplots_adjust(bottom=0.2)
plt.grid(True)
plt.text(0.5, 0.5, f'{ticker}', color='gray', fontsize=80, alpha=0.5,
ha='center', va='center', rotation=15, transform=plt.gca().transAxes)
plt.text(0.95, 0.95, 'medium.com/@dmitry.romanoff', color='gray', fontsize=20, alpha=0.5,
ha='right', va='top', transform=plt.gca().transAxes)
plt.text(0.05, 0.05, 'medium.com/@dmitry.romanoff', color='gray', fontsize=20, alpha=0.5,
ha='left', va='bottom', transform=plt.gca().transAxes)
plot_file = os.path.join(output_directory, 'options_scatter_plot.png')
plt.savefig(plot_file)
print(f"Scatter plot has been saved to {plot_file}")
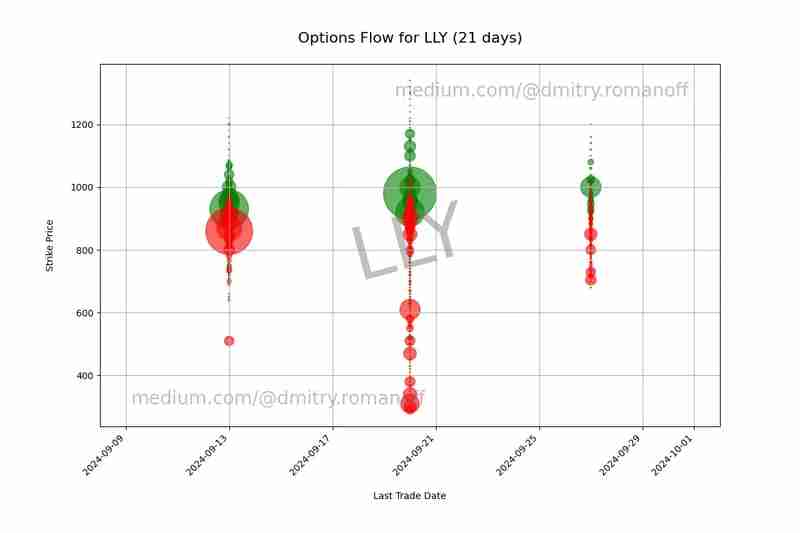
このセグメントでは、Y 軸に権利行使価格、X 軸に取引日をとったコール オプションとプット オプションの散布図が作成されます。ポイントのサイズは取引量を表し、緑色はコールを、赤色はプットを示します。また、ブランド化を目的として透かしを追加し、プロットをファイルに保存します。
結論
オプション データを視覚化すると、トレーダーやアナリストが市場センチメントや取引活動を理解するのに役立ちます。このガイドでは、Python を使用してオプション データを取得、処理、視覚化する方法を説明しました。これらの手順に従うことで、このコードを任意の銘柄に適用し、そのオプション フローを分析して、市場トレンドに関する貴重な洞察を得ることができます。
特定のニーズに合わせてコードを自由に変更し、財務データを視覚化するさまざまな方法を検討してください。
以上がPython を使用したオプション フローの視覚化: ステップバイステップ ガイドの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undress AI Tool
脱衣画像を無料で

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)



 PythonでAPI認証を処理する方法
Jul 13, 2025 am 02:22 AM
PythonでAPI認証を処理する方法
Jul 13, 2025 am 02:22 AM
API認証を扱うための鍵は、認証方法を正しく理解して使用することです。 1。Apikeyは、通常、リクエストヘッダーまたはURLパラメーターに配置されている最も単純な認証方法です。 2。BasicAuthは、内部システムに適したBase64エンコード送信にユーザー名とパスワードを使用します。 3。OAUTH2は、最初にclient_idとclient_secretを介してトークンを取得し、次にリクエストヘッダーにbearertokenを持ち込む必要があります。 4。トークンの有効期限に対処するために、トークン管理クラスをカプセル化し、トークンを自動的に更新できます。要するに、文書に従って適切な方法を選択し、重要な情報を安全に保存することが重要です。
 関数のPython変数スコープ
Jul 12, 2025 am 02:49 AM
関数のPython変数スコープ
Jul 12, 2025 am 02:49 AM
Pythonでは、関数内で定義されている変数はローカル変数であり、関数内でのみ有効です。外部から定義されているのは、どこでも読むことができるグローバル変数です。 1。関数が実行されると、ローカル変数が破壊されます。 2。関数はグローバル変数にアクセスできますが、直接変更できないため、グローバルキーワードが必要です。 3.ネストされた関数で外部関数変数を変更する場合は、非ローカルキーワードを使用する必要があります。 4。同じ名前の変数は、異なるスコープで互いに影響を与えません。 5。グローバル変数を変更するときにグローバルを宣言する必要があります。それ以外の場合は、バウンドロカレラーロールエラーが発生します。これらのルールを理解することで、バグを回避し、より信頼性の高い機能を書くことができます。
 PythonでAPIをテストする方法
Jul 12, 2025 am 02:47 AM
PythonでAPIをテストする方法
Jul 12, 2025 am 02:47 AM
APIをテストするには、Pythonのリクエストライブラリを使用する必要があります。手順は、ライブラリのインストール、リクエストの送信、応答の確認、タイムアウトの設定、再試行です。まず、pipinstallRequestsを介してライブラリをインストールします。次に、requests.get()またはrequests.post()およびその他のメソッドを使用して、get requestsを送信または投稿します。次に、respons.status_codeとresponse.json()を確認して、返品結果が期待に準拠していることを確認します。最後に、タイムアウトパラメーターを追加してタイムアウト時間を設定し、再試行ライブラリを組み合わせて自動再生を実現して安定性を高めます。
 Python Fastapiチュートリアル
Jul 12, 2025 am 02:42 AM
Python Fastapiチュートリアル
Jul 12, 2025 am 02:42 AM
Pythonを使用して最新の効率的なAPIを作成するには、Fastapiをお勧めします。標準のPythonタイプのプロンプトに基づいており、優れたパフォーマンスでドキュメントを自動的に生成できます。 FastAPIおよびASGIサーバーUVICORNをインストールした後、インターフェイスコードを記述できます。ルートを定義し、処理機能を作成し、データを返すことにより、APIをすばやく構築できます。 Fastapiは、さまざまなHTTPメソッドをサポートし、自動的に生成されたSwaggeruiおよびRedocドキュメントシステムを提供します。 URLパラメーターはパス定義を介してキャプチャできますが、クエリパラメーターは、関数パラメーターのデフォルト値を設定することで実装できます。 Pydanticモデルの合理的な使用は、開発の効率と精度を改善するのに役立ちます。
 Pythonで大きなJSONファイルを解析する方法は?
Jul 13, 2025 am 01:46 AM
Pythonで大きなJSONファイルを解析する方法は?
Jul 13, 2025 am 01:46 AM
Pythonで大きなJSONファイルを効率的に処理する方法は? 1. IJSONライブラリを使用して、アイテムごとの解析を介してメモリオーバーフローをストリーミングして回避します。 2. JSonlines形式の場合は、行ごとに読み取り、json.loads()で処理できます。 3.または、大きなファイルを小さな部分に分割してから、個別に処理します。これらの方法は、メモリ制限の問題を効果的に解決し、さまざまなシナリオに適しています。
 タプルの上のループ用のPython
Jul 13, 2025 am 02:55 AM
タプルの上のループ用のPython
Jul 13, 2025 am 02:55 AM
Pythonでは、ループを使用してタプルを通過する方法には、要素を直接繰り返し、インデックスと要素を同時に取得し、ネストされたタプルを処理する方法が含まれます。 1。インデックスを管理せずに、for loopを直接使用して、各要素に順番に各要素にアクセスします。 2。enumerate()を使用して、同時にインデックスと値を取得します。デフォルトのインデックスは0で、開始パラメーターも指定できます。 3.ネストされたタプルはループで開梱できますが、サブタプル構造が一貫していることを確認する必要があります。さらに、タプルは不変であり、ループでコンテンツを変更することはできません。不要な値は\ _によって無視できます。エラーを避けるために、トラバースする前にタプルが空であるかどうかを確認することをお勧めします。
 Pythonクラスには複数のコンストラクターを持つことができますか?
Jul 15, 2025 am 02:54 AM
Pythonクラスには複数のコンストラクターを持つことができますか?
Jul 15, 2025 am 02:54 AM
はい、apythonclasscanhavemultipleconstructorsthroughtertechniques.1.Defaultargumentsionthodto __tododtoallowdodtoibleInitialization with varyingnumbersofparameters.2.declassmethodsasasaLternativeconstructorsoriable rerableible bulible clurecreatureati
 ループ範囲用のPython
Jul 14, 2025 am 02:47 AM
ループ範囲用のPython
Jul 14, 2025 am 02:47 AM
Pythonでは、range()関数を使用してforループを使用することは、ループの数を制御する一般的な方法です。 1.ループの数を知っている場合、またはインデックスごとに要素にアクセスする必要がある場合に使用します。 2。範囲(STOP)から0からSTOP-1、範囲(開始、停止)からSTOP-1、範囲(開始、停止)がステップサイズを追加します。 3.範囲には最終値が含まれておらず、Python 3のリストの代わりに反復可能なオブジェクトを返すことに注意してください。 4.リスト(range())を介してリストに変換し、ネガティブなステップサイズを逆順に使用できます。
