J'ai l'impression que cela ne peut pas être décrit clairement en une ou deux phrases.
Ce billet de blog auquel j'ai déjà fait référence, j'espère qu'il vous sera utile.
Permettez-moi de parler de ma compréhension personnelle.
scrapy utilise le python amélioré de collection.deque pour stocker le request à explorer. Comment deux ou plus Spider peuvent-ils partager ce deque ?
Les files d'attente à explorer ne peuvent pas être partagées et la distribution n'a aucun sens. scrapy-redis fournit une solution, remplacez collection.deque par une base de données redis, et plusieurs robots d'exploration stockent le redis à explorer à partir du même serveur request, afin que plusieurs spider puissent accéder au même Lire dans une base de données, afin que le principal problème de distribution soit résolu.
Remarque : ne remplace pas redis pour stocker request, scrapy peut être distribué directement
!
scrapy est directement lié à 待爬队列 est le planificateur Scheduler.
Référencer la structure de scrapy
Il est chargé de mettre en file d'attente les nouveaux request, de retirer le suivant request à explorer, etc. Par conséquent, après avoir remplacé Redis, d'autres composants doivent être modifiés.
Donc, ma compréhension personnelle est qu'il est relativement simple de déployer le même robot sur plusieurs machines, déploiement distribué redis, adresse de référence mon blog. Et ces tâches, y compris la déduplication d'URL, sont les fonctions du framework scrapy-redis déjà écrit.
L'adresse de référence est ici. Vous pouvez télécharger l'exemple pour voir l'implémentation spécifique. J'ai également travaillé là-dessus récemment scrapy-redis, et je mettrai à jour cette réponse lorsque je l'aurai déployée.
Si vous avez de nouveaux progrès, vous pouvez les partager avec nous.
@伟兴 Bonjour, j'ai vu ce commentaire le 15.10.11 Avez-vous des résultats maintenant ? Pouvez-vous recommander certains de vos blogs ? Merci~ Vous pouvez me contacter chenjian158978@gmail.com

















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




J'ai l'impression que cela ne peut pas être décrit clairement en une ou deux phrases.
Ce billet de blog auquel j'ai déjà fait référence, j'espère qu'il vous sera utile.
Permettez-moi de parler de ma compréhension personnelle.
scrapyutilise lepythonamélioré decollection.dequepour stocker lerequestà explorer. Comment deux ou plusSpiderpeuvent-ils partager cedeque?Les files d'attente à explorer ne peuvent pas être partagées et la distribution n'a aucun sens.
scrapy-redisfournit une solution, remplacezcollection.dequepar une base de donnéesredis, et plusieurs robots d'exploration stockent leredisà explorer à partir du même serveurrequest, afin que plusieursspiderpuissent accéder au même Lire dans une base de données, afin que le principal problème de distribution soit résolu.Remarque : ne remplace pas
!redispour stockerrequest,scrapypeut être distribué directementscrapyest directement lié à待爬队列est le planificateurScheduler.Référencer la structure de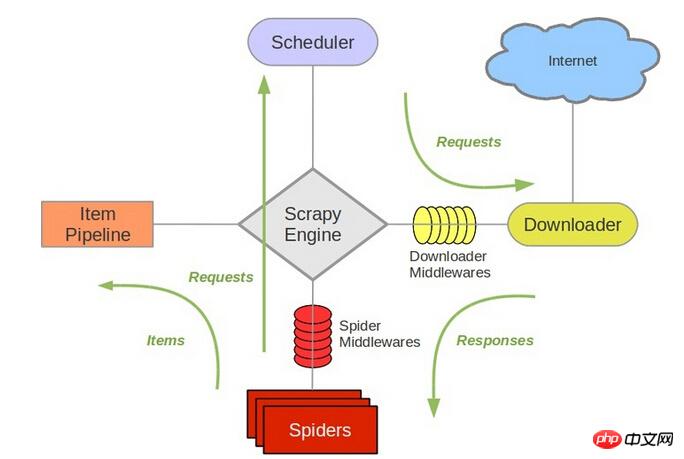
scrapyIl est chargé de mettre en file d'attente les nouveaux
request, de retirer le suivantrequestà explorer, etc. Par conséquent, après avoir remplacé Redis, d'autres composants doivent être modifiés.Donc, ma compréhension personnelle est qu'il est relativement simple de déployer le même robot sur plusieurs machines, déploiement distribué
redis, adresse de référencemon blog. Et ces tâches, y compris la déduplication d'URL, sont les fonctions du framework
scrapy-redisdéjà écrit.L'adresse de référence est ici. Vous pouvez télécharger l'exemple pour voir l'implémentation spécifique. J'ai également travaillé là-dessus récemment
scrapy-redis, et je mettrai à jour cette réponse lorsque je l'aurai déployée.Si vous avez de nouveaux progrès, vous pouvez les partager avec nous.
@伟兴 Bonjour, j'ai vu ce commentaire le 15.10.11 Avez-vous des résultats maintenant ?
Pouvez-vous recommander certains de vos blogs ? Merci~
Vous pouvez me contacter chenjian158978@gmail.com