

登陆的时候post了登陆信息,但是还是无法获取到登陆后的网页,只有在电脑浏览器上先登陆上,python程序才能获取到登陆后的页面。
这是不是因为验证码的原因?是不是可以通过cookies绕过验证码?
代码如下:
pythonimport requests header = { 'User-Agent': "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:34.0) Gecko/20100101 Firefox/34.0", 'Host': "www.zhihu.com", 'Referer': "http://www.zhihu.com/", 'X-Requested-With': "XMLHttpRequest" } payload = { 'email': "xxxxxxxxxxxx", 'password': "xxxxxxxxxx", 'rememberme': 'y', } s = requests.session() r = s.post('http://www.zhihu.com/login', data = payload, headers = header) print r.text rr = s.get('http://zhihu.com/login', headers = header) zhihu_home_page = rr.text print zhihu_home_page
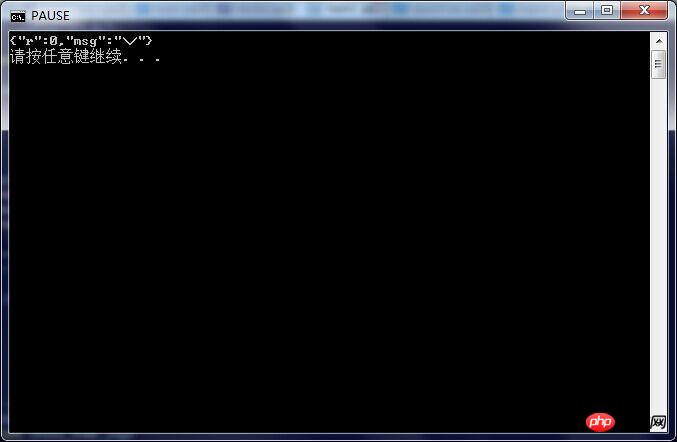
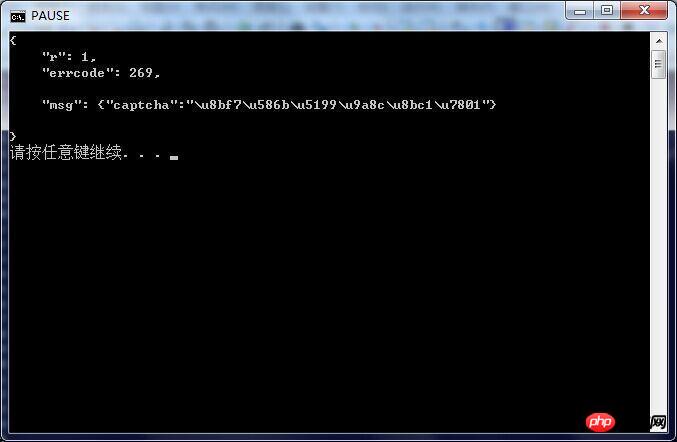
此外,分别是登陆成功和登陆失败后,POST 返回的 r.text 数据,这是什么意思啊……
大神求解救,这几天我就纠结这个问题了……















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




如果只是临时一次性抓取的话,可以手工打开浏览器登录,然后取cookies,复制到程序里去请求,user-agent最好跟你浏览器里的一致。
如果是在线实时抓取的话,必须突破验证码,这个难度大,没有试验过。或许有一些现成的库可以破解掉一些简单的验证码。
需要输入验证码。