现有问题如下表格:
怎么快速统计到匹配的结果有多少条记录呢?
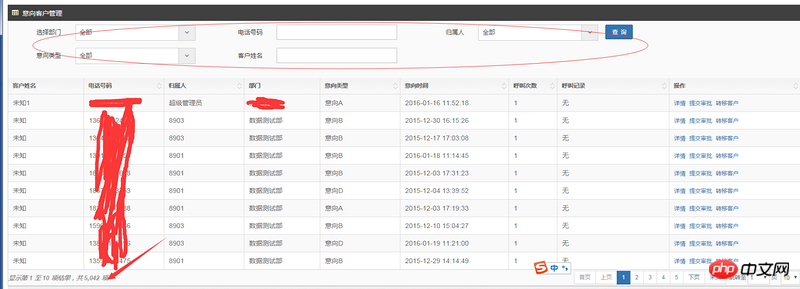
问题描述:因为分页的原因,我要知道总记录条数,统计的方式为常规方式,直接count后面加条件统计的。相关索引也已经加上。带入查询条件后,上面有查询条件,相关数值会发生变化,数据表格中的类容也会发生变化。后来发现,如果数据量比较大,查询的很多时间都浪费在查询总记录数上,因为加了相关索引,即使是查询数据,也会只显示固定的10条或者20条,时间不会太久,数据库使用的是MySql数据库,请问各位有没有遇到类似的问题,怎么快速统计到匹配的结果有多少条记录呢?
我看了这个,但是这个不能添加查询条件吧 http://www.jb51.net/article/60753.htm

















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




思路是避免实际检索全表 (只从索引得到结果, index-only scan)
首先count怎么写的?
count(*)和count(列)也不一样建立适当的索引, 必要时强制使用索引(select count() FORCE INDEX)
具体见http://dev.mysql.com/doc/refman/5.7/en/how-to-avoid-table-scan.html
如果用了条件去统计总行数会很慢的。
貌似没有很好的解决办法 数据不经常变动的话可以使用缓存
曾经也是因为分页需要统计总行数苦恼过
解决方法很笨 见笑了
因为筛选条件不是很多
所以是在这个表上添加了触发器并创建一个专门用来统计总行数的表
添加更新删除该表就会触发,分析条件后直接把统计表的相应字段累加
查询的时候直接读取统计表中的相应字段就可以 准确度没问题,性能没测过
但是该表后来十多万数据貌似也没出现慢查询
1.你是对的。你给的参考网址中的方式不适用于有条件的查询。
2.这种典型的应用确实需要用相同的条件count一次,然后再根据分页取相应的数据。你的做法是对的。
3.你已经增加相关索引,但是数据量大的时候还是会慢---你的索引可能没有起作用。需要探讨的问题是,你的索引为什么没有起作用,或,你的SQL要如何优化。
3.1 你的条件是5个,部门、归属人、意向类型 应该是单一值(理论上做多选更人性化)的精确查询;电话号码、客户姓名 应该是单一值的模糊查询。而且所有条件都可能是空白,空白或不选理论上代表“全部”。所以,你的SQL形成过程可能如下(伪码):
由此可见,SQL较复杂,而且如果是模糊查询一般(特殊情况可以)无法优化使用索引。
3个精确查询字段如果建立组合索引,也受到组合索引的字段顺序限制而影响使用效果。
所以,你的索引,可能没有起作用。。。可以查看一下查询计划,一般的数据库应该都有。
看是否用到了索引(在不同的条件下),还是全表扫描(full table scan)。
结论:你的索引没有起到作用,所以大数据量下速度还是慢
3.2 你的数据量到底有多大?到底有多慢?
3.3 处理性能问题最懒惰有效的方法:加硬件。
3.4 其实没有更多了。开发需要做的,把3.2里的内容搞清楚。其它找个DBA看看。多大的数据在什么样的环境上,容纳多大的并发及IO是个很复杂的事情,可以动硬件也可以架多台服务器搞主从/负载均衡/读写分离等(许多高在上的名词)。你如果了解,可以贴更多的数据上来。
3.5 WEB系统提高响应还可以通过缓存减少对DB的负载。
以上,供参考。