

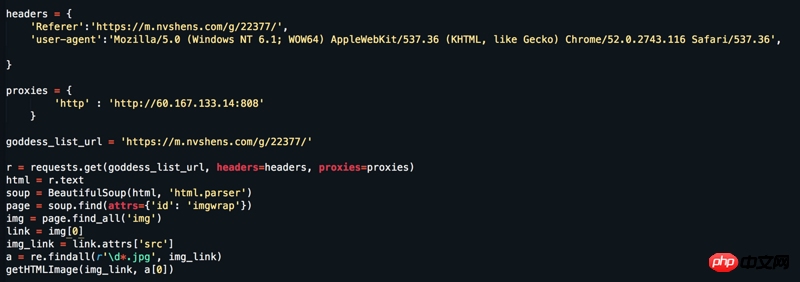
Site Web : https://www.nvshens.com/g/22377/. Ouvrez le site Web directement avec le navigateur puis faites un clic droit sur l'image pour la télécharger. Ensuite, l'image directement demandée par mon robot a été bloquée, et. puis j'ai changé les en-têtes et configuré un proxy IP, mais cela n'a toujours pas fonctionné. Mais en regardant la capture de paquets, il ne s’agit pas de données chargées dynamiquement ! ! ! Veuillez répondre = =















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




La fille est plutôt jolie.

Il peut en effet être ouvert par un clic droit, mais après actualisation, il devient une image hyperliée. Généralement, pour éviter les hotlinking, le serveur vérifiera si le
Referer字段,这就是为什么刷新后就不是原图的原因(刷新后Refererdans l'en-tête de la requête a changé).Avez-vous manqué des paramètres en capturant le paquet lors de la prise de la photo ?
Je regardais juste le contenu du site et j'ai presque oublié qu'il était officiel.
Vous pouvez suivre toutes les informations que vous avez demandées
Alors essayez-le
Référent Selon la conception de ce site Web, chaque page devrait être plus conforme au comportement de se faire passer pour un être humain, au lieu d'utiliser un seul référent
Ce qui suit est le code complet qui peut être exécuté pour capturer toutes les images à la page 18